이전 글에서 예고한 대로 '오늘 할 것'을 처리한다.
오늘 할 것
1.형태소 분석 후 [명사]/[형용사](이하 키워드) 만 추출하여 리스트 담기
2.최다 반복된 키워드를 10위까지 추출하기 (전체 영상에서)
3.영상 전체를 구간화 시키기 (5분할 or 10분할)
4. 구간 중 최다 반복 키워드 추출하기
이 글에선 2번까지 하다가 '형태소 분석기'를 조금더 공부할 필요가 있어서 다음글로 넘어간다
##1. pytube를 활용하여 CC로 저장된 정보를 리스트에 담았다
-리트스의 요소는 딕셔너리다
-각각의 자막정보를 순서, 시작 타임코드, 종료 타임코드, 자막을 인덱스로 한 딕셔너리에 담았다
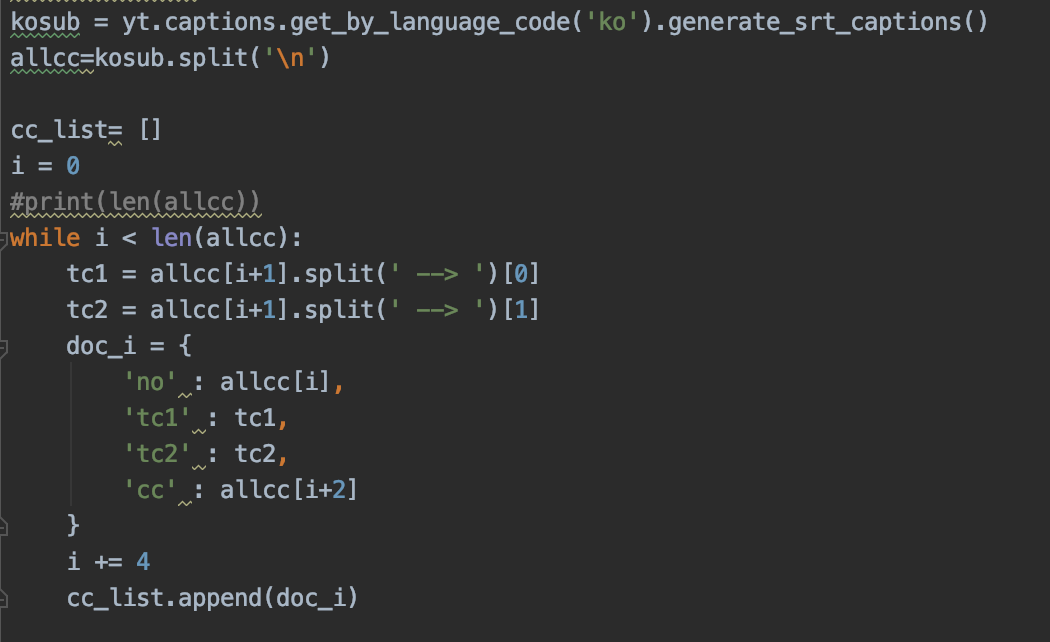
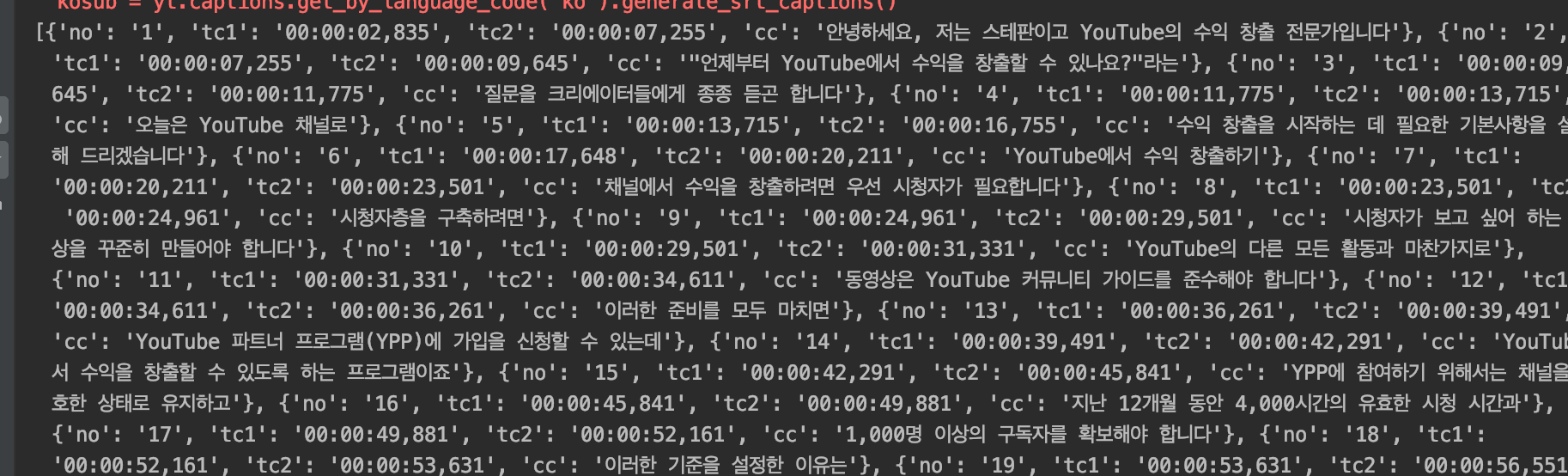
##2. 'cc'자막만 하나의 리스트 안에 넣어주었다

- 특정 형태소만 리스트에 넣기 (체언)
체언, 수식어만 담기
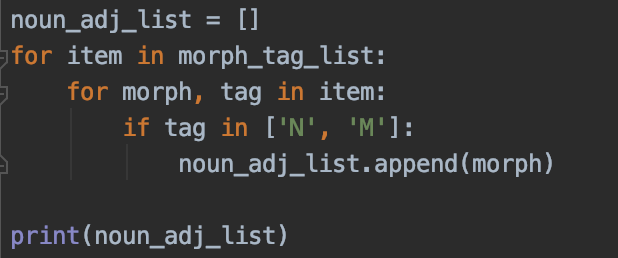
결과값
'드', '수' 등 키워드라 보기 어려운 것만 나옴
따라서 체언만(N)만 추출하기로 함
형태소 분석기를 한나눔 -> 트위터 / 코모란 / 미캡 으로 바꾸는 방법이 나을 수 있음 (이후에 진행하기로)

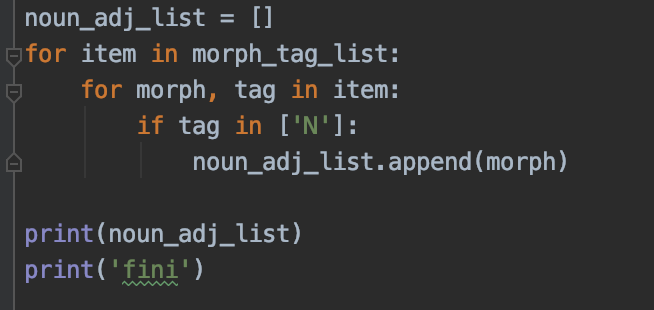
결과값
해보니 여전히 '수'가 많다. 이것은 키워드로 삼을 수 없기에 다른 방법을 찾아야한다.
또 '확인하세요'도 '확인'을 따로 추출하지 않음을 확인할 수 있다. 다른 형태소 분석기를 사용하기로 하고 일단 다음단계로 넘어간다.


##3. 최다반복어를 탑10까지 보여주기
collection에서 counter라는 라이브러리를 불러와서 하단 코드만 입력하면 잘 추출된다.
from collections import Counter
counts = Counter(noun_adj_list)
print(counts.most_common(10))
##4. 최선의 형태소 분석기 찾기 --> 다음글에서
