(미)딥러닝 PART.CS231n 10강
RNN
구조
- 동작방법
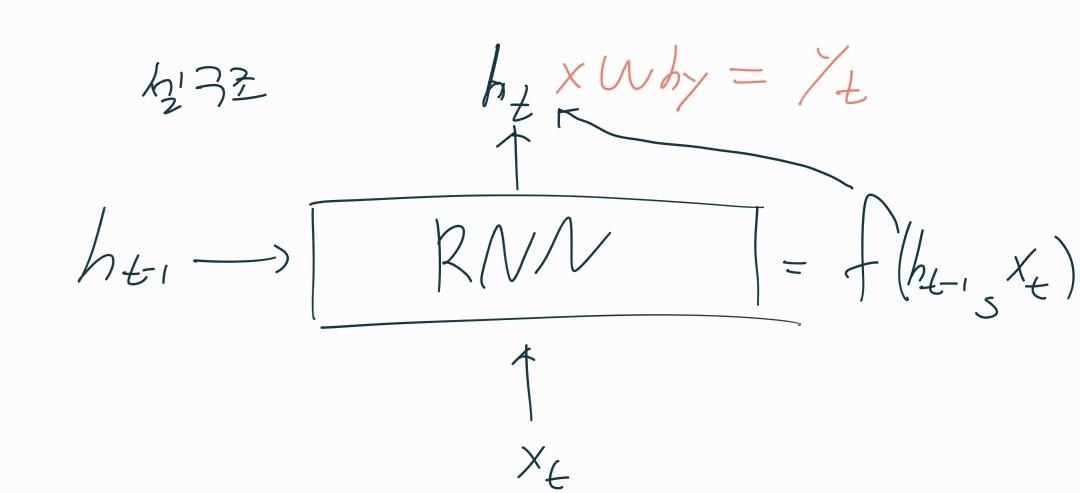
1. 히든 state의 재귀적인 반복
2. 출력 y를 가지려면 끝단에 FC레이어 존재
3. 매 스탭에서 동일한 가중치 행렬 W가 사용됨
4. 재귀적으로 피드백하는 것으로 h0는 초기상태로 0으로 초기화
5. 입력 -> ht-1, xt 2개/ 출력 -> 다음 상태 ht
학습
- cost함수 구하는 법
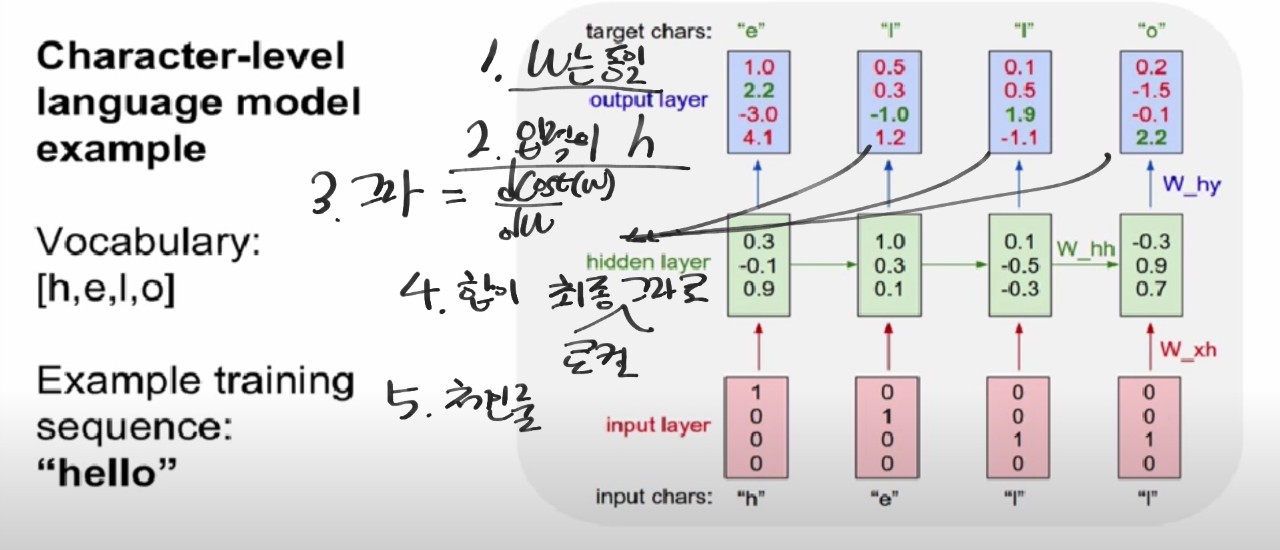
1. y는 h를 이용하여 만듬
2. 그라디언트도 동일
- loss함수
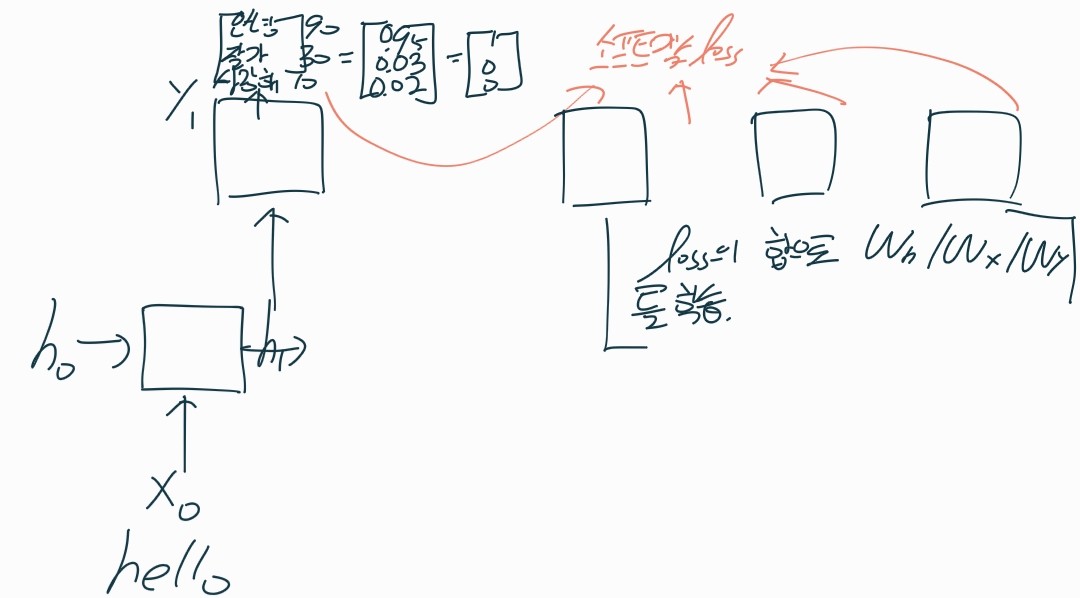
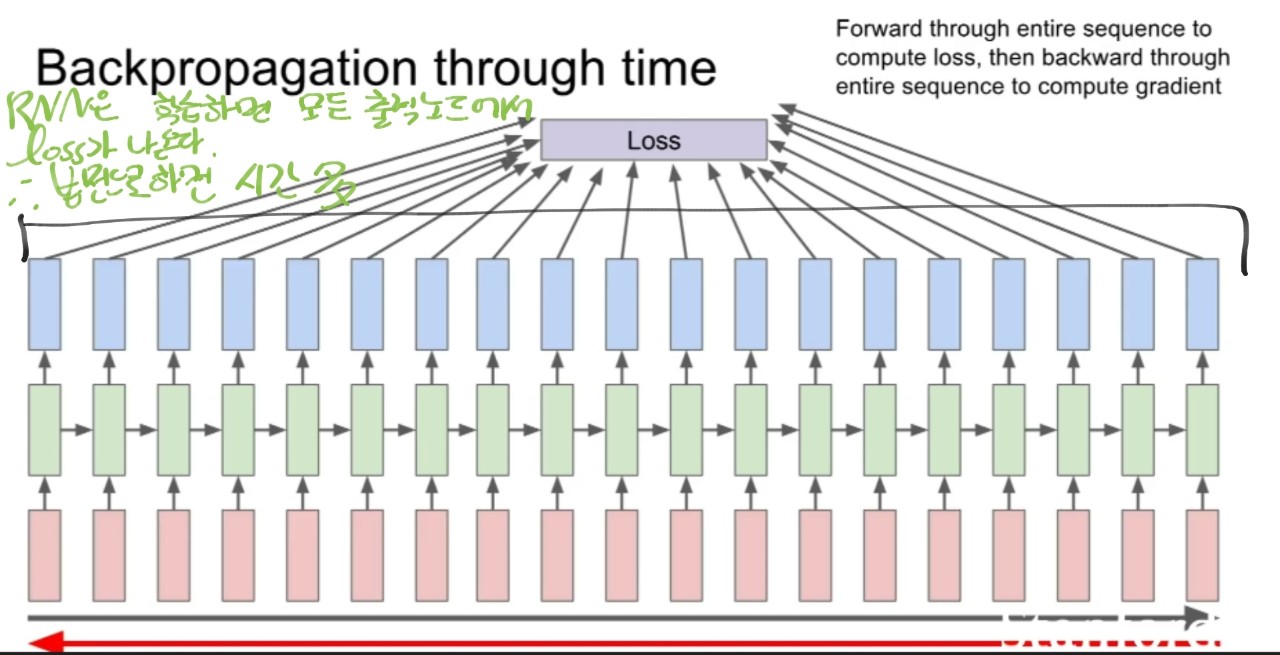
1. 매 타임스탭의 셀마다 y값이 출력됨
2. 따라서 매 스탭마다 loss가 생성됨
3. 데이터 입력 1개를 넣으면 loss가 하나가 나오고 모든 데이터를 거치면 나온 데이터 수만큼의 loss를 평균내어 최종 loss를 구하는데
-> 여기서는 하나의 입력을 넣었는데 여러개의 loss가 나온 거임
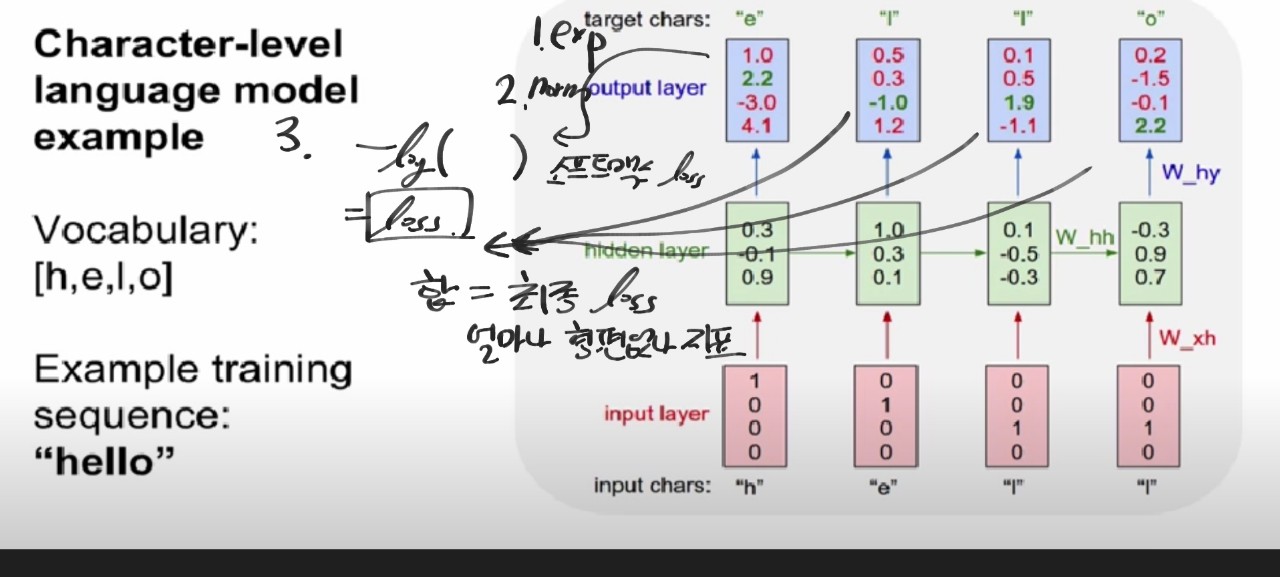
- 최종 loss 구하기
1.모든 타임 스탭마다 loss가 생성
2. 소프트맥스를 거치니 소프트맥스 크로스엔트로피 loss를 계산함
3. 모든 셀의 loss를 더해서 최종 loss를 생성
4. 그라디언트도 동일한 방식으로 최종 그라디언트를 구함
※ 순전파 : loss를 구하는 과정/ 역전파 : 그라디언트를 구하는 과정
자연어 처리
- test data를 사용
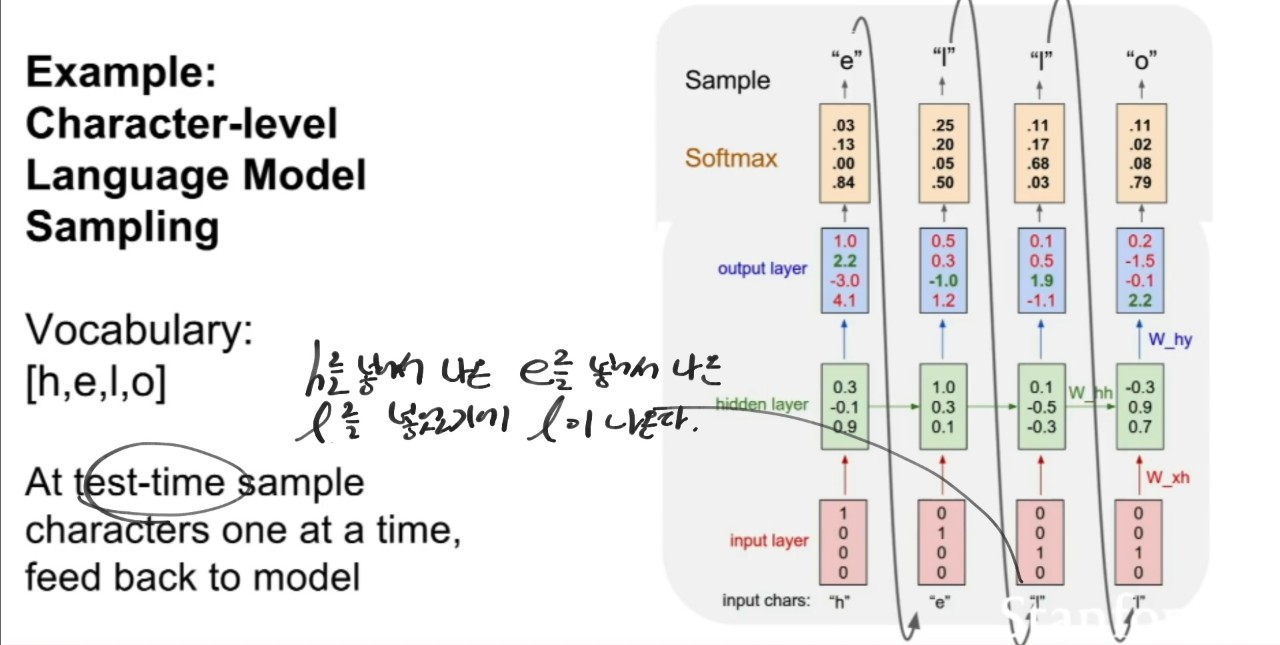
1. 입력으로 'h'하나를 학습된 모델에 넣음
2. 출력 'e'가 다음 타임 스탭의 입력으로 들어감
3. 따라서 'h'를 아는 'e'로 'l'의 출력을 함
4. 따라서 'h'를 아는 'e'를 아는 'l'로 'l'의 출력을 함
5. 학습에서는 'h' 'e' 'l' 'l'을 넣고 ht의 ht+1의 입력으로 seq한 학습을 하고
/ 테스트에서는 학습된 히든 state들과 이전 출력의 다음 입력으로 seq한 예측을 할 수 있음
loss, 역전파
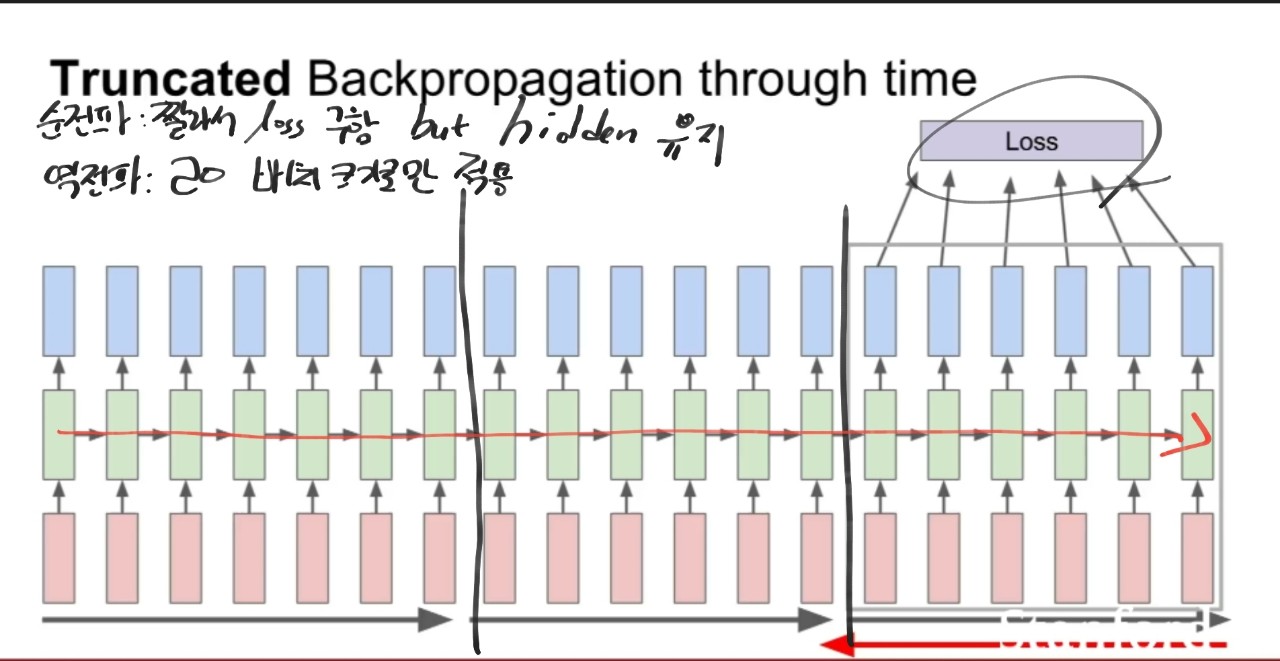
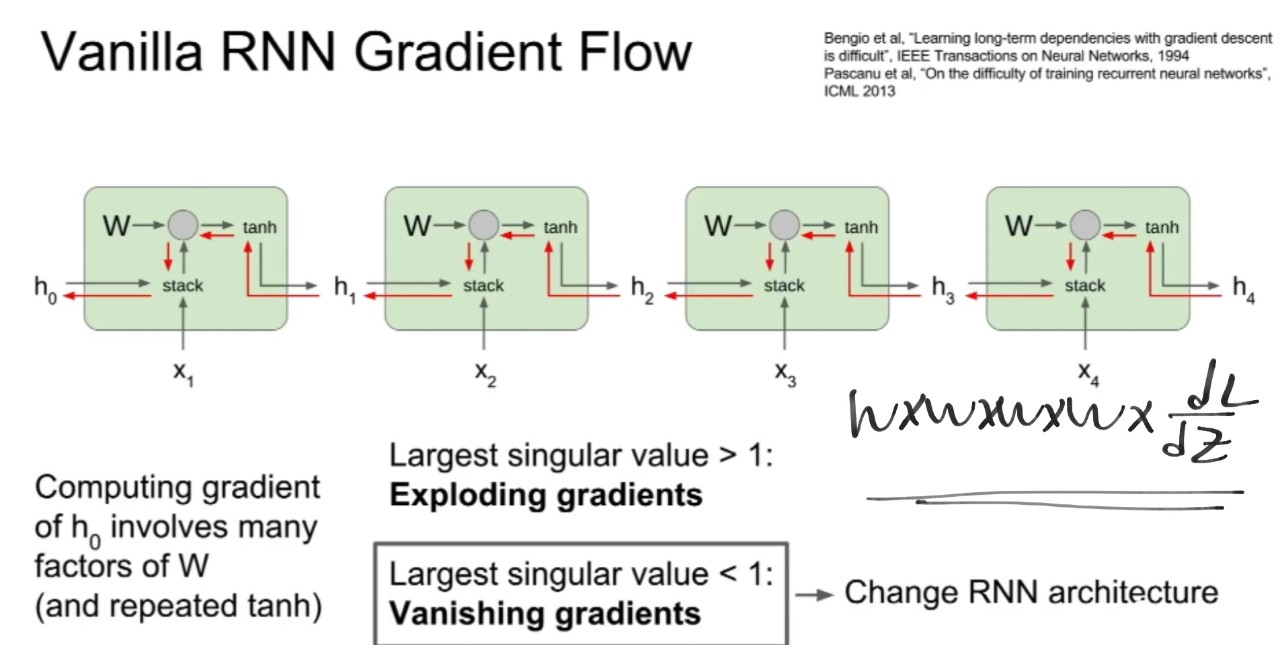
- 역전파 Through time
1. 시퀀스 스탭마다 출력값이 존재하여 loss를 더하여 최종 loss를 구하고 그라디언트도 마찬가지이다.
2 근데 이럴 경우 seq가 긴 경우 문제가 될 소지가 있다 -> 법전으로 하면 학습이 느리다.
- batch backprop
- 트레인 스탭을 100으로 자른다.
- 100스탭만 순전파하고 서브 seq의 loss를 계산하고 그라디언트 스탭을 진행한다.
- 순전파시 이전 배치에서 계산한 hidden state는 유지한다. -> 다음 배치에서 순전파를 계산할 때 이전 hidden을 사용한다
- 그라디언트 스탭(역전파)은 현재 배치에서만 진행된다.
※ 확률적 경사하강의 seq 데이터 버전이다.
다이어그램
RNN
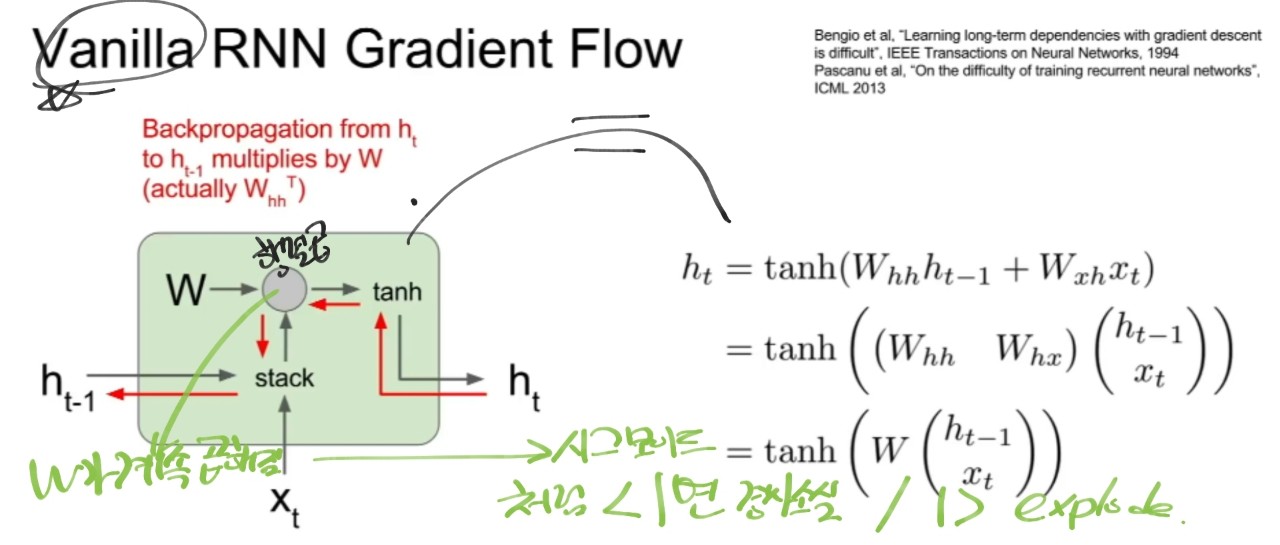
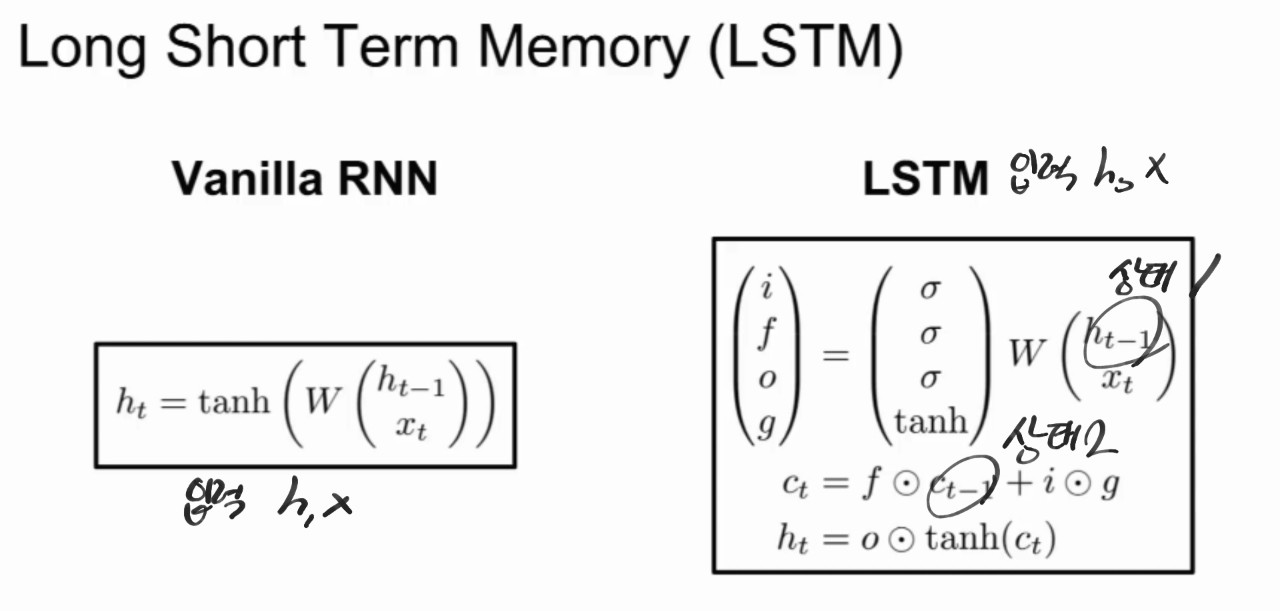
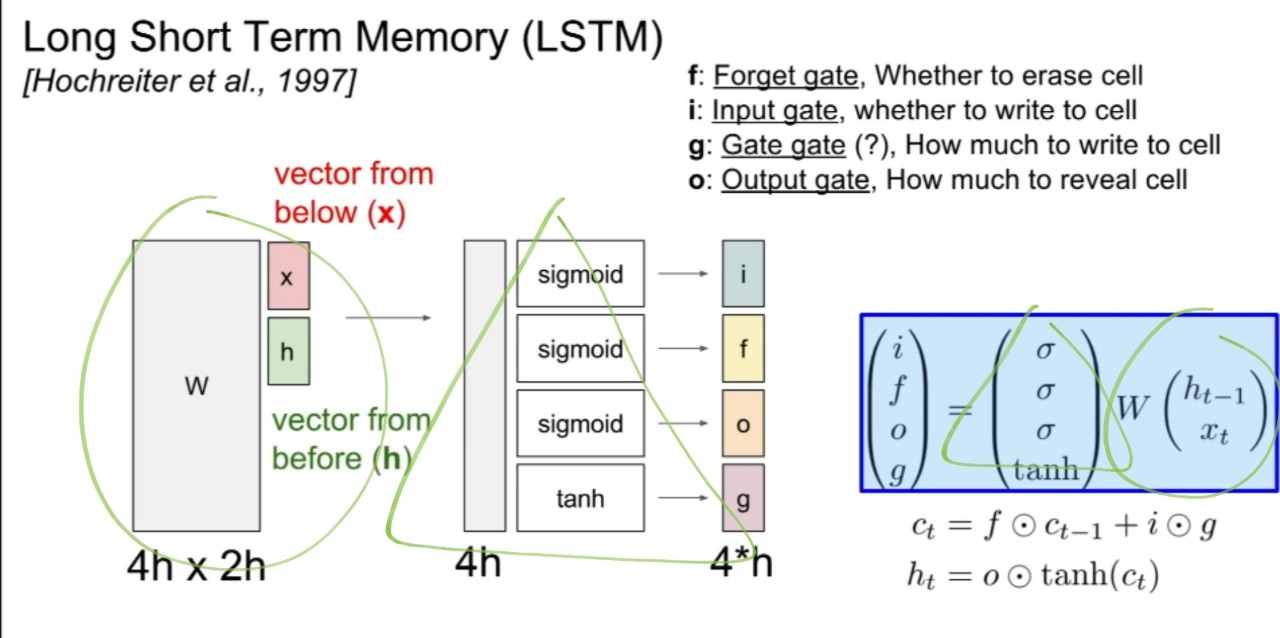
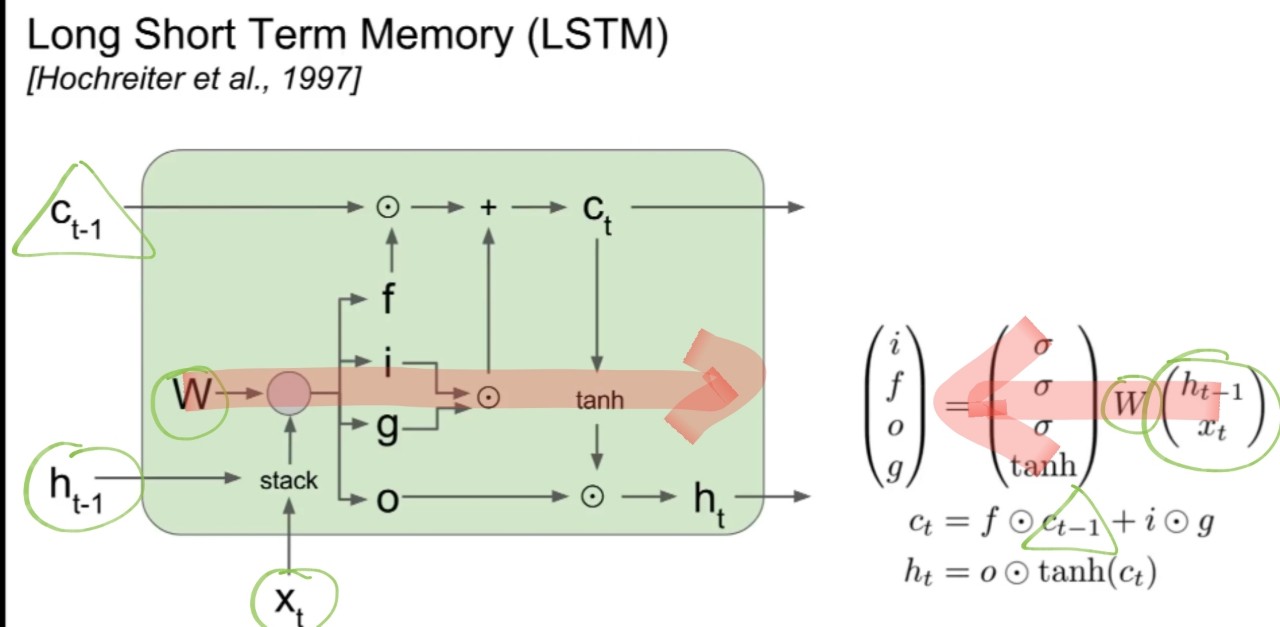
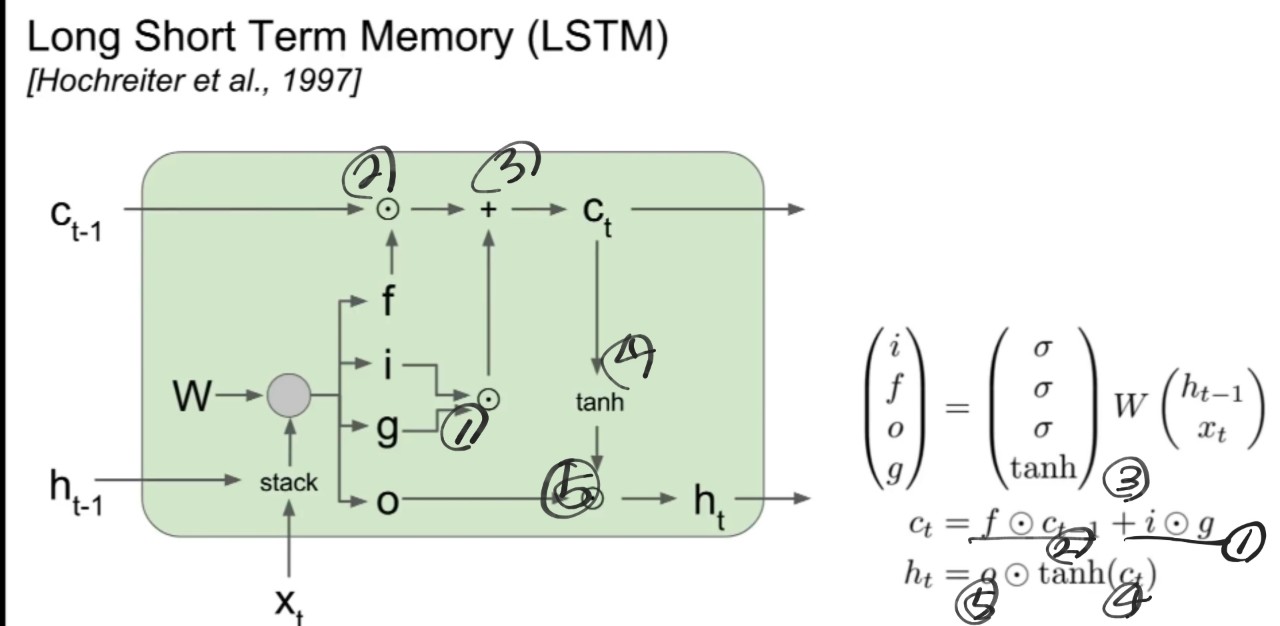
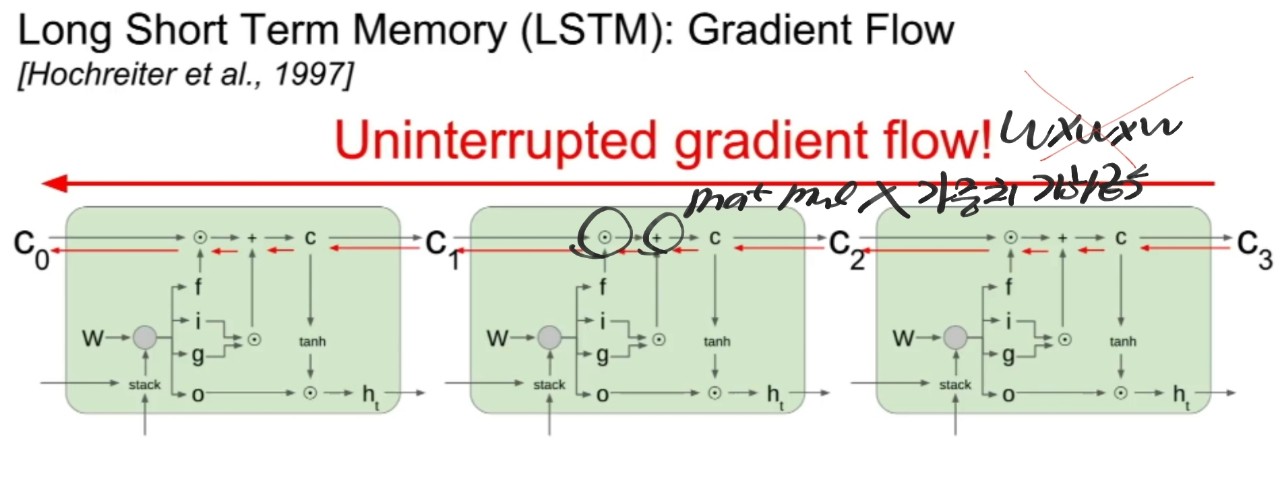
LSTM



돌아보면 후회 없기를 바라며