결정트리, 간단하게 특징만 딱
0. 학습 참고자료
파이썬 머신러닝 완벽가이드 강의링크
1. 결정트리는 무엇인가
데이터에 있는 규칙을 학습을 통해 찾아내고 이를 Tree 기반의 분류 규칙을 만드는 것
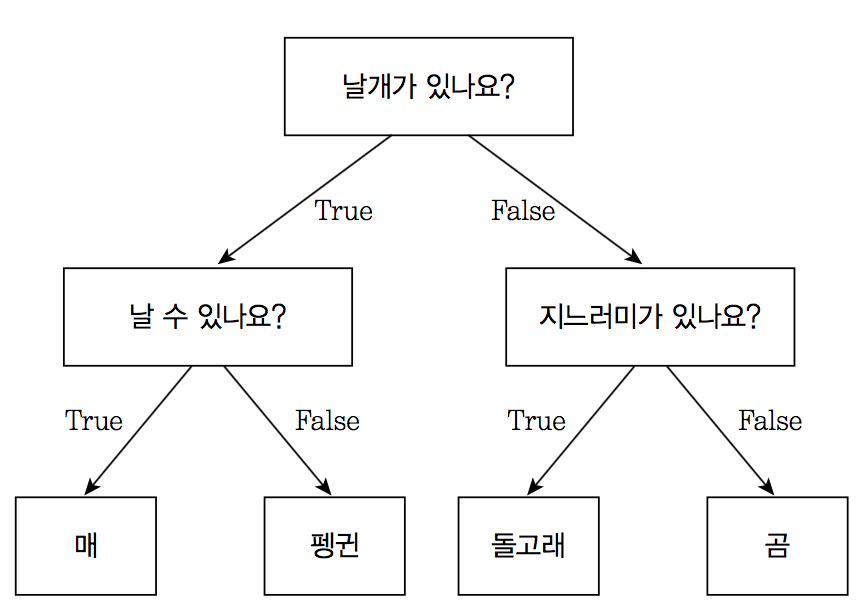
데이터의 어떤 기준을 바탕으로 규칙을 만들어야 가장 효율적인 분류가 될 것인가가 알고리즘의 성능에 크게 영향을 미침
2. 최적의 결정트리를 구성하기 위해서는
가능한 적은 결정기준으로 최대한 많고 균일한 데이터 세트를 구성할 수 있도록 분할하는 것이 필요
여기서 균일하다는 뜻은 예를 들면, 1과 2, 3으로 구성된 카드를 3개의 뭉치로 나눴다고 가정했을 때 특정 카드 뭉치에 1만 들어있고 2와 3은 들어있지 않았다고 했을 때 이 카드 뭉치는 "균일하다"라고 할 수 있음
결정트리는 정보 균일도가 높은 데이터 세트를 먼저 선택할 수 있도록 규칙을 만든다
2.1 균일도를 판단하는 기준
정보 이득 지수와 지니 계수를 활용해 기준을 마련한다
2.1.1 엔트로피와 정보 이득
주어진 데이터의 집합의 혼잡도를 의미하는 엔트로피라는 개념에서 균일하지 않은 데이터의 경우 엔트로피가 높다고 한다. 이 때 정보 이득 지수는 1에서 엔트로피 지수를 뺀 값으로 결정트리는 이 정보 이득 지수가 높은 속성을 기준으로 규칙을 생성하고 분할한다
2.1.2 지니 계수
이 지수는 0과 1사이의 값으로 구성되고 0으로 갈수록 균일하고 1로 갈수록 균일하지 않다. 위에서 언급한 엔트로피와 비교해보면 엔트로피가 높다는 것은 지니 계수가 높다는 뜻과 의미가 부합한다. 따라서 결정트리는 지니 계수가 낮은 속성을 기준으로 데이터를 분할한다는 것
3. 결정트리의 특징
3.1 장점
분류하는 알고리즘이 매우 직관적
3.2 단점
과적합 문제에 쉽게 영향을 받음
3.2.1 단점을 극복하기 위해서
하이퍼 파라미터 튜닝이 중요해진다. 대표적인 파라미터로는 max_features ,max_depth 등이 있다
4. 결정트리 학습 알고리즘에 쓰인 주요 파라미터 파악하기
모델을 생성하고 분류문제를 파악했을때 그 모델이 어떤 feature를 판단의 기준으로 주로 활용했는가를 알고싶으면 feature_importance_ 속성을 활용해 알 수 있다
정리
자주 프로젝트를 활용하지 않다보면 개념이 기억나지 않을 때가 많다. 이렇게 정리해두면 좀 나아지지 않을까
