Operating System Design Objectives
- I/O 장치는 프로세서와 메인 메모리의 속도를 따라잡을 수 없다. (효율성)
- 프로세서와 메인 메모리의 속도가 아무리 높아도 하드 디스크의 성능이 안 좋으면 실행 속도를 높일 수 없다.
- 모든 I/O 장치들을 일관된 방식으로 다루는 것이 바람직하다. (일반성)
Disk Performance Parameters
- Access Time = Seek time + Rotational delay
- Seek time: 원하는 데이터가 있는 트랙 위치까지 헤드를 움직이는 데 걸리는 시간
- 가장 시간이 오래 걸리는 작업으로 이것을 줄여야 한다.
- Rotational delay: 원하는 데이터가 있는 섹터까지 원판을 돌리는 데 걸리는 시간
- Seek time: 원하는 데이터가 있는 트랙 위치까지 헤드를 움직이는 데 걸리는 시간
- Transfer Time: 데이터를 읽는 데 걸리는 시간으로 줄일 수 없다.
Disk Scheduling Policies
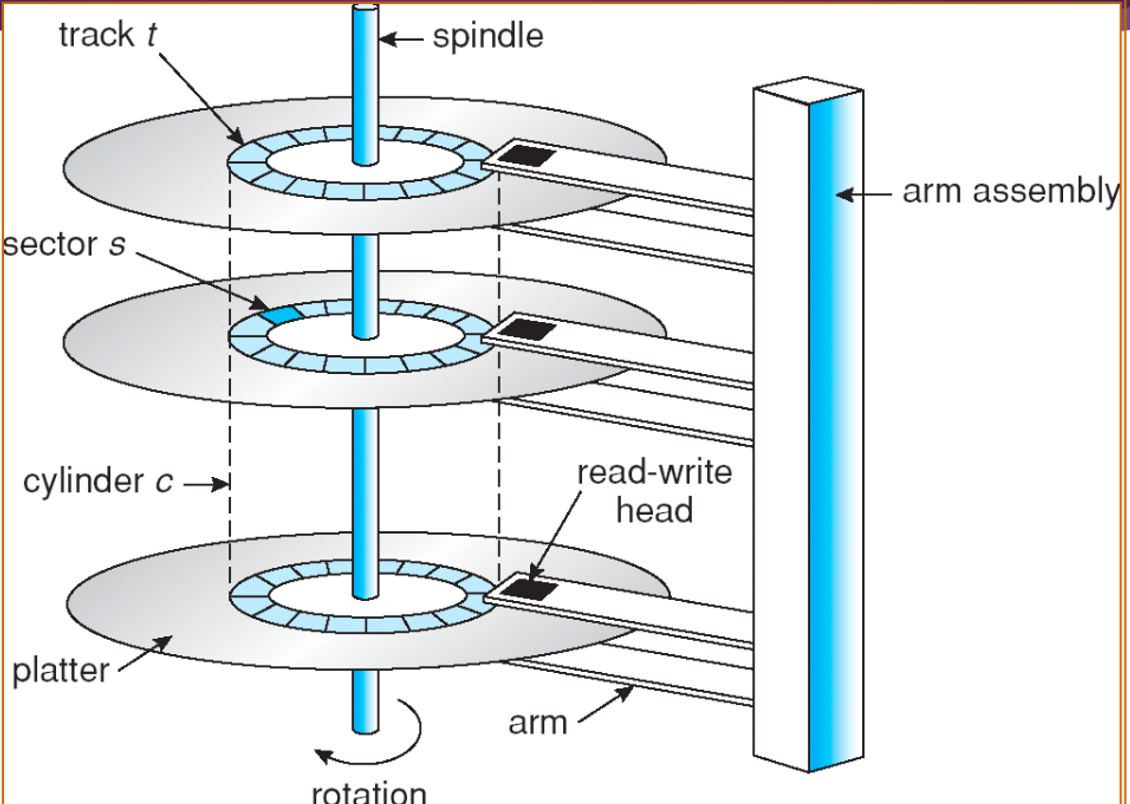
FIFO
- 요청 순서대로 처리한다.
- 모든 프로세스에게 공정하다.
- starvation 발생 가능성이 없다.
- 무작위로 처리하는 것과 같은(최악) 성능을 보인다.
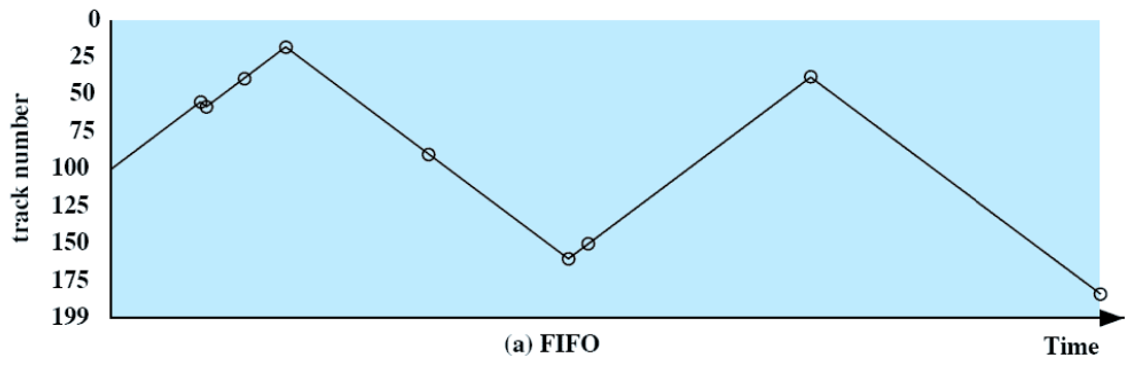
Shortest Service Time First
- 현재 위치에서 가장 짧은 seek time으로 처리할 수 있는 요청을 먼저 처리 한다.
- Optimal한 방식이다.
- 양 끝에 있는 요청들이 처리 되기 어려워, starvation 발생 가능성이 있다.
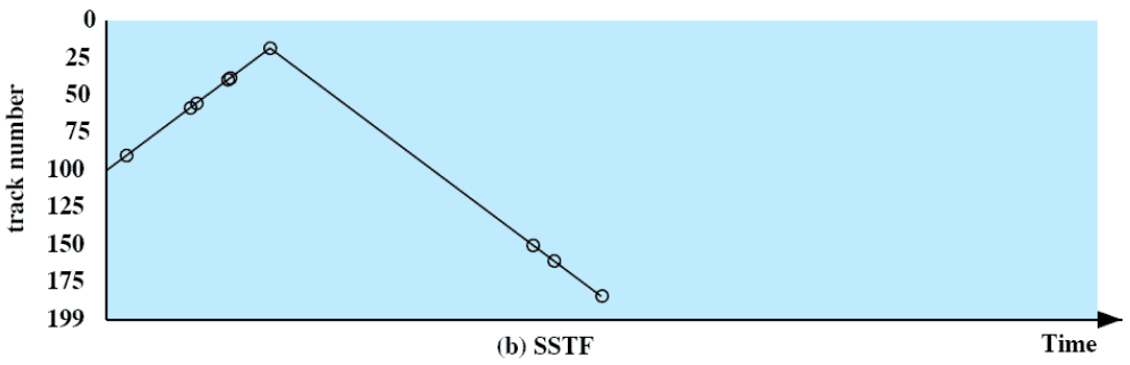
SCAN
- 헤드가 한 쪽 방향으로 움직이면서 만나는 요청들을 다 처리하고 방향을 바꿔서 반복한다.
- 트랙 끝까지 가는 것이 아닌 해당 방향의 마지막 요청 트랙까지만 간다.
- FIFO와 SSTF의 중간 성능을 가진다.
- 가능 방향에 새로운 요청들이 계속 들어오면 훨씬 전에 도착한 요청들이 굉장히 늦게 처리되는 문제가 발생할 수 있다.
- 0번 트랙을 처리 한 후 방향 바꿔서 지나자마자 0번 트랙에 요청이 들어오면 시간이 오래 걸린다.
N-step-SCAN
- 요청들을 N 크기의 큐(여러 개의 큐 가능)에 놓는다.
- 새로운 요청들은 가장 아래 쪽의 큐에 쌓여 나중에 처리된다.
- starvation 발생 가능성이 없다.
- N값에 따라서 성능이 달라질 수 있다.
FSCAN
- 2개의 큐만 사용한다.
- 하나의 큐에 있는 요청들을 처리하는 동안 도착하는 새로운 요청들은 나머지 다른 큐에 쌓인다.
- starvation 발생 가능성이 없다.
- N-step-SCAN보다 더 안전하다.
CSCAN
- 한 쪽 방향으로만 요청 처리를 하고 반대 방향으로는 처리하지 않는다.
- 요청이 어떤 트랙에 있던지 간에 처리되는 최대 시간이 동일해진다.
- 완벽하게 공정하고 예측 가능성이 높다.
- SCAN보다는 성능이 떨어진다.
Priority scheduling
- short batch job, interactive job들을 우선적으로 처리하는 방식이다.
- 어떤 트랙에 있던지 상관 없이 프로세스의 성질에 따라서 우선순위를 둔다.
Last-In-First-Out
- 큐에서 가장 마지막에 있는 요청을 먼저 처리하는 방식
- 마지막에 위치한 요청은 최근에 실행한 프로세스로 온 것일 것으로 locality에 의해 묶어서 처리하면 throughput을 높일 수 있을 것이다.
- starvation 발생 가능성이 높다.
RAID
Redundant Array of Independent Disks
- 여러 physical disk drive가 하나의 드라이브처럼 작동하는 디스크 시스템
- 데이터들을 여러 드라이브에 나눠서 저장하여 디스크 액세스 시간을 감소시킨다.
RAID 0

- 파일을 strip 단위로 나눠서 여러 디스크에 분산 배치한다.
- 데이터 읽는 속도가 굉장히 빨라진다.
- 하나의 디스크만 고장이 나도 온전한 파일을 만들 수 없다.
RAID 1 (mirrored)
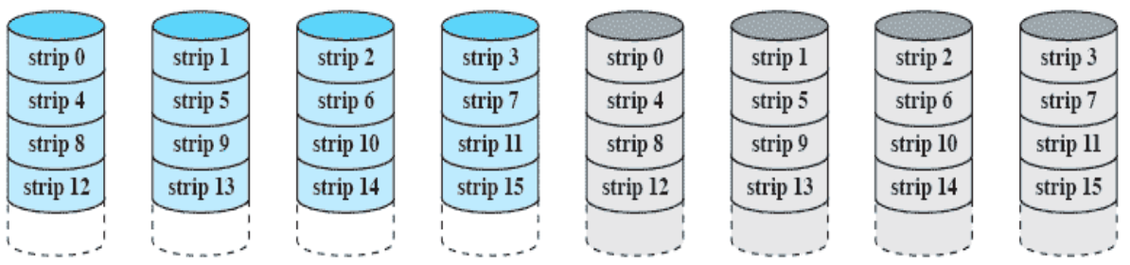
- 왼쪽 4개는 원본 데이터, 나머지 4개는 복사본 데이터
- 데이터를 읽을 때는 왼쪽에서 읽고, 쓸 때는 8개 모두에 쓴다.
- 하나의 디스크가 고장나면 미러링 된 디스크를 사용하면 된다.
- 성능은 4배 좋아졌지만 비용은 8배가 들어 비효율적이다.
RAID 2 (Hamming code)
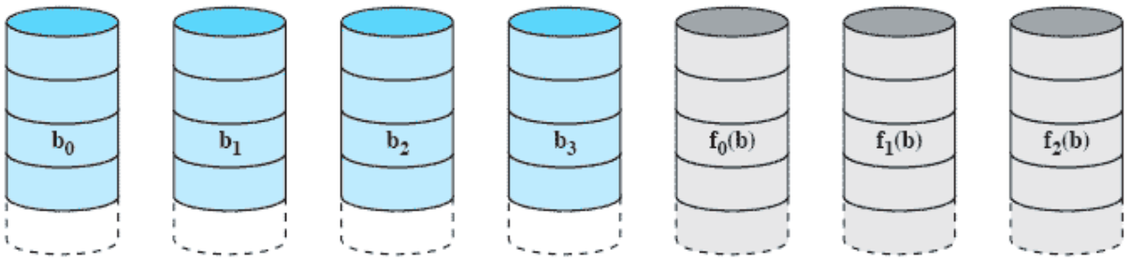
- 파일을 strip 단위가 아닌 bit 단위로 나누어서 디스크에 저장한다.
- 오른쪽 3개의 디스크에는 해밍 코드를 저장한다.
 |
|---|
| - c0: 첫번째 비트가 1인 것끼리 exclusive OR |
| - c1: 두번째 비트가 1인 것끼리 exclusive OR |
| - c2: 세번째 비트가 1인 것끼리 exclusive OR |
| - 데이터 디스크가 많아질수록 필요한 코드 디스크의 개수 변화가 크지 않아 효율적이다. |
| - 1부터 N까지, 2의 거듭제곱의 개수가 n일 때 코드 디스크의 개수는 n개, 데이터 디스크의 개수는 N-n개이다. |
| - 일부 디스크가 고장나도 c값을 통해 데이터를 복구할 수 있다. 위의 예제에서는 수식이 3개이기 때문에 2개의 디스크가 고장나도 데이터 복구 가능하다. |
RAID 3 (bit-interleave parity)

- RAID 2와 동일하게 비트 단위로 데이터를 저장한다.
- 짝수 parity, 홀수 parity를 사용한다. (1의 개수를 짝수나 홀수로 맞추기)
- 디스크 하나가 고장 났을 때 다른 디스크의 비트와 parity bit를 통해 고장난 디스크의 있던 비트값을 알아낼 수 있다.
RAID 4 (block-level parity)
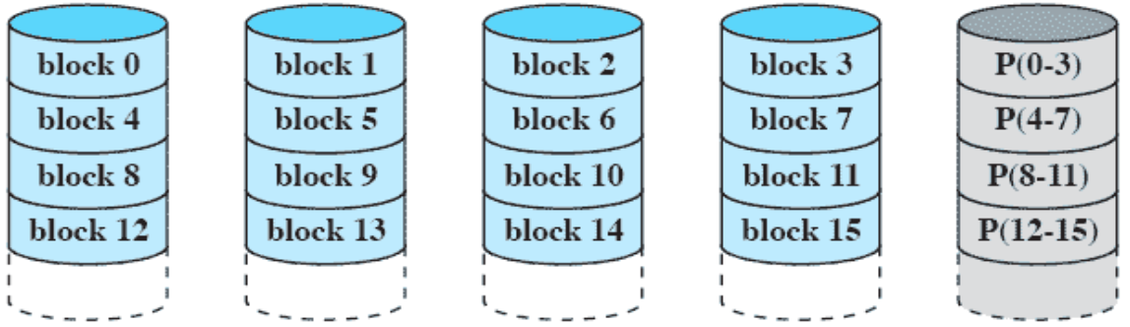
- 데이터를 block 단위로 나누어서 저장하고 block-level의 parity를 사용한다.
- 디스크에 저장된 데이터를 업데이트하면 parity 값도 수정해야하기 때문에 parity 디스크의 액세스 속도가 느려질 수 있고, 이는 디스크 성능의 bottleneck이 될 수 있다.
RAID 5 (block-level distributed parity)
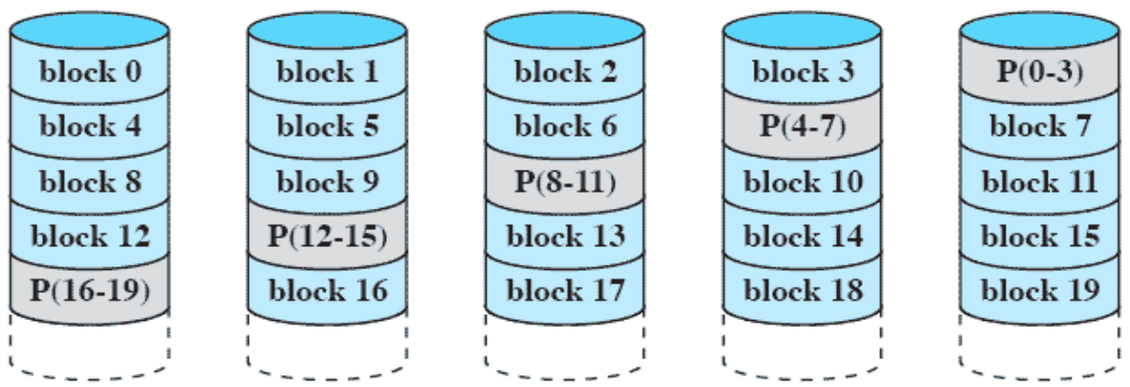
- parity 디스크를 하나로 정해서 사용하는 것이 아니라 여러 디스크에 나누어서 parity를 저장한다.
- write 작업이 여러 디스크에 분산돼서 실행되므로 전체적으로 실행 속도가 올라간다.
Disk Cache
- 하드 디스크에는 데이터가 블록 단위로 저장되어 있고, 한 블록 안의 일부 데이터가 필요할 때 그 블록 전체를 읽어 온다.
- 메인 메모리 안의 디스크 캐시라는 공간에, 읽어온 블록을 저장해서 블록 안에 있는 다른 데이터들을 나중에 바로 사용할 수 있게 한다.
- 하드 디스크에 대한 요청이 있을 때 디스크 캐시를 우선적으로 확인하고 필요한 데이터가 있으면 바로 사용하고, 없으면 디스크에서 다시 읽어온다.
Least Recently Used
- 새로운 블록을 읽어오면 스택처럼 쌓는다.
- 가장 위에 있는 블록이 가장 최근에 사용한 블록이다.
- 스택 안에 필요한 블록이 있다면 다시 제일 위로 올린다.
- 스택이 가득 찬 상태에서 새로운 블록을 가져오면 가장 아래에 있는 블록을 버린다.
- 페이지 교체에서는 LRU가 가장 좋은 방법이었지만 디스크 캐시에서는 그렇게 좋은 성능을 보이지는 않는다.
Least Frequently Used
- 사용 횟수가 가장 적은 블록을 버리고, 가장 많은 블록을 남긴다.
- 블록마다 카운터 변수를 하나씩 둬서 몇 번 사용했는지 체크한다.
- 직전에 디스크 캐시로 올라온 블록의 사용 횟수는 1이므로 다음에 바로 버려지는 문제가 발생할 수 있다.
Frequency-based Replacement
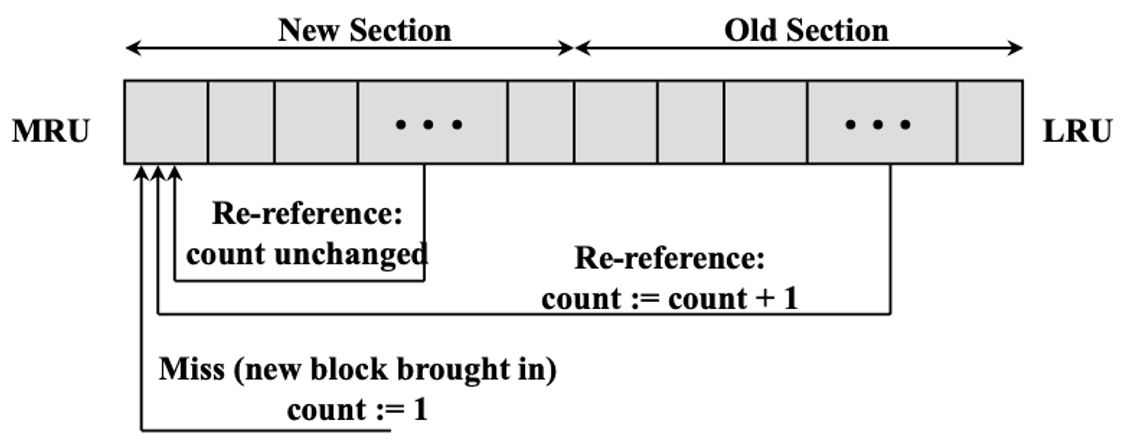
- LRU + LFU: 오랫동안 반복해서 사용되는 블록을 남긴다.
- 왼쪽: 가장 최근에 사용된 블록
- 오른쪽: 가장 오랫동안 사용되지 않은 블록
- 새로운 블록이 올라오면 count 값이 1인 상태로 top에 올라온다.
- New Section에 있다가 다시 사용되면 count값은 변하지 않고 top으로 올라간다.
- Old Section에 있다가 다시 사용되면 count값을 1 증가시키고 top으로 올라간다.
- Old Section 중에서 count 값이 가장 작은 블록을 버린다. 같은 블록이 있으면 스택의 bottom 쪽에 있는 블록을 버린다.
- New Section에 있는 상태에서 많이 사용되다가 (count 1) Old Section에 내려가면 다른 블록들에 비해 count 값이 작을 수 있기 때문에 내려가자마자 버려지는 상황이 발생할 수 있다.
Solution

- New Section에서 다시 사용될 때는 count값의 변화는 없지만, Middle Section과 Old Section에서 다시 사용될 때는 count값을 1 증가시킨다.
- 오랫동안 주기적으로 사용되는 블록들은 Middle Section과 New Section 사이를 오가면서 유지할 것이다.
- Old Section 중에서 count값이 가장 작은 블록을 버린다.

언젠간 iOS 개발자가 되겠지