📌 RAM의 특징과 종류
컴퓨터의 주기억장치의 종류에는 크게 RAM(Random Access Memory)과 ROM(Read Only Memory)이 있으며, '메모리'라는 용어는 RAM을 지칭하는 경우가 많다. RAM에는 실행할 프로그램의 명령어와 데이터가 저장되며, 전원을 끄면 날아가는 휘발성 저장 장치(volatile memory)이다.
RAM의 종류
RAM의 종류는 크게 DRAM, SRAM, SDRAM, DDR SDRAM이 있다.
○ DRAM (Dynamic RAM)
DRAM은 시간이 지나면 데이터가 점차 사라지는 RAM이다. 따라서 데이터의 소실을 막기 위해 일정 주기로 데이터를 재활성화 (다시 저장)해야 한다.
소비 전력이 비교적 낮고, 저렴하고, 집적도가 높아서 대용량으로 설계하기 용이해서, RAM에서 일반적으로 사용한다.
○ SRAM (Static RAM)
저장된 데이터가 변하지 않는 RAM이다. SRAM은 일반적으로 DRAM보다 속도가 더 빠르다.
그러나 소비 전력이 크고, 가격도 비싸며, 집적도가 낮다. 그래서 SRAM은 메모리가 아닌 '대용량으로 만들어질 필요는 없지만 속도가 빨라야하는 저장 장치'인 캐시 메모리에 주로 사용된다.
○ SDRAM (Synchronous Dynamic RAM)
SRAM와 DRAM의 합성어 같지만 SRAM과 관련은 없다.
클럭 신호화 동기화된(클럭 타이밍에 맞춰 CPU와 정보를 주고받을 수 있음), 발전된 형태의 DRAM이다.
○ DDR SDRAM (Double Data Rate SDRAM)
최근 가장 흔히 사용하는 RAM이다. DDR SDRAM은 대역폭을 넓혀 속도를 빠르게 만든 SDRAM이다. 대역폭이란 데이터를 주고받는 길의 너비를 의미한다.
즉, 한 클럭에 한 번씩 CPU와 데이터를 주고받을 수 있는 SDRAM에 비해 DDR SDRAM은 두 배의 대역폭으로 한 클럭당 두 번씩 CPU와 데이터를 주고받을 수 있다. (한 클럭 당 하나씩 데이터를 주고받는 SDRAM을 SDR SDRAM이라고도 한다.)
DDR3 SDRAM:DDR2 SDRAM보다 대역폭이 2배 넓고,SDR SDRAM보다 8배 넓다.DDR4 SDRAM:SDR SDRAM보다 대역폭이 16배 넓다. 최근에 흔히 사용하는 메모리이다.
📌 메모리의 주소 공간
○ 물리 주소 / 논리 주소
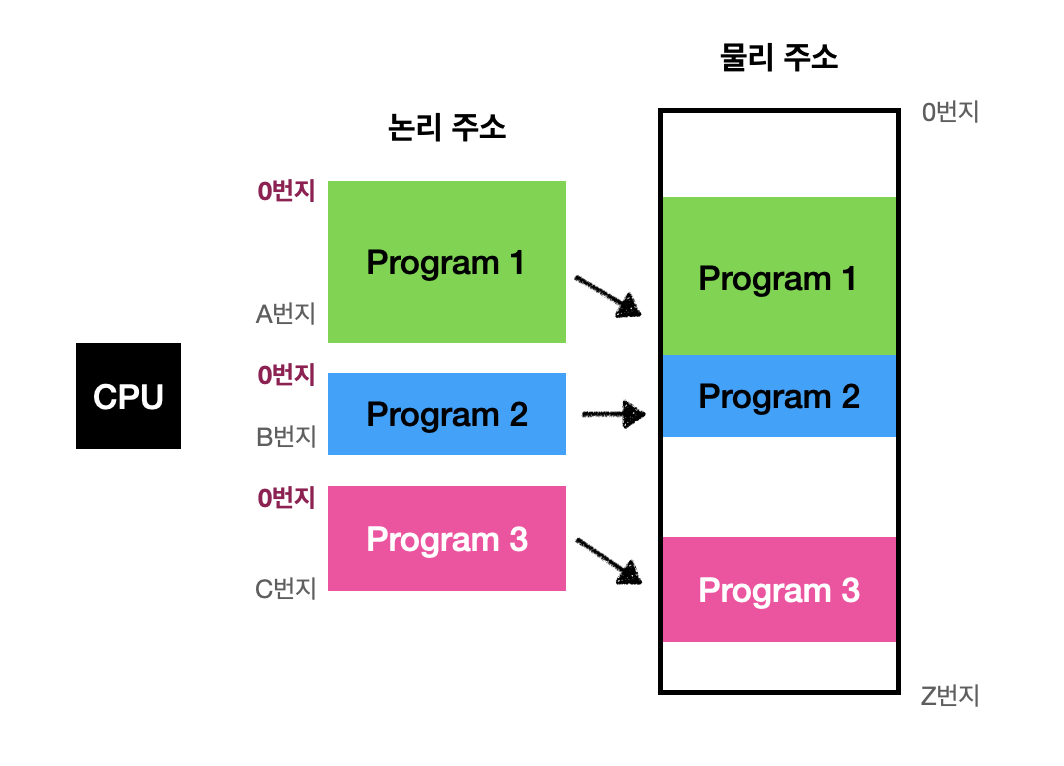
메모리에 저장된 정보의 위치는 주소로 나타낼 수 있으며 주소에는 물리 주소, 논리 주소 두 종류가 있다.
🔖 물리 주소 (physical address)
정보가 실제로 저장된 하드웨어상의 주소
🔖 논리 주소 (logical address)
CPU와 실행 중인 프로그램이 사용하며, 실행 중인 프로그램 각각에게 부여된 0번지부터 시작되는 주소이다.
→ 프로그램마다 같은 논리 주소가 있을 수 있다.
○ MMU
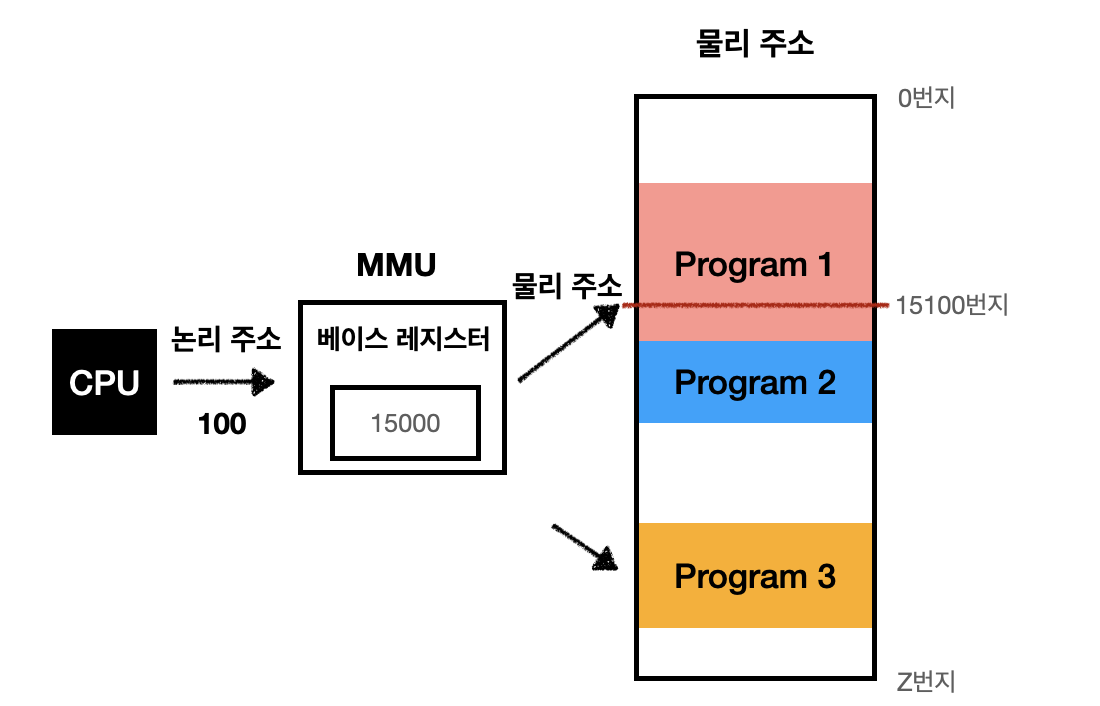
🔖 MMU (Memory Management Unit)
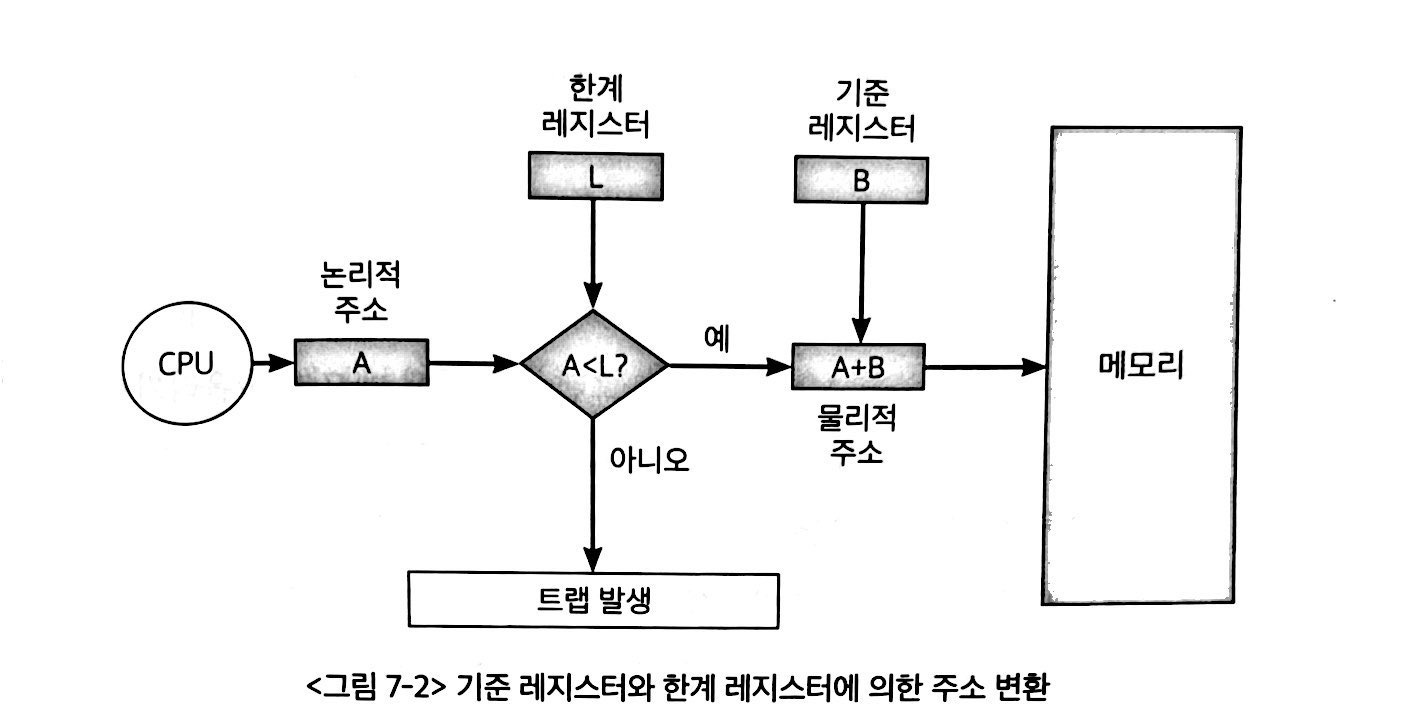
논리 주소와 물리 주소간으 변환은 CPU와 주소 버스 사이에 위치한메모리 관리 장치(MMU)에 의해 수행된다.
MMU는 CPU가 발생시킨 논리 주소에 베이스 레지스터의 값을 더하여 논리 주소를 물리 주소로 변환한다.
🔖 베이스 레지스터
프로그램의 가장 작은 물리주소, 즉 프로그램의 첫 물리 주소를 저장한다.
논리 주소는 베이스 레지스터에 저장된 첫 물리 주소로부터 떨어진 거리인 셈이다.
💡 물리 주소 = 베이스 레지스터값 + 논리 주소
○ 한계 레지스터
프로그램의 논리 주소 영역을 벗어나면 자신과 관련없는 프로그램에 영향을 미칠 수 있다. 다른 프로그램의 영역을 침범할 수 있는 명령어는 위험하기 때문에 논리 주소 범위를 벗어나는 명령어 실행을 방지하고 실행 중인 프로그램이 다른 프로그램에 영향을 받지 않도록 보호하는 역할을 한계 레지스터 (limit register)가 담당한다.
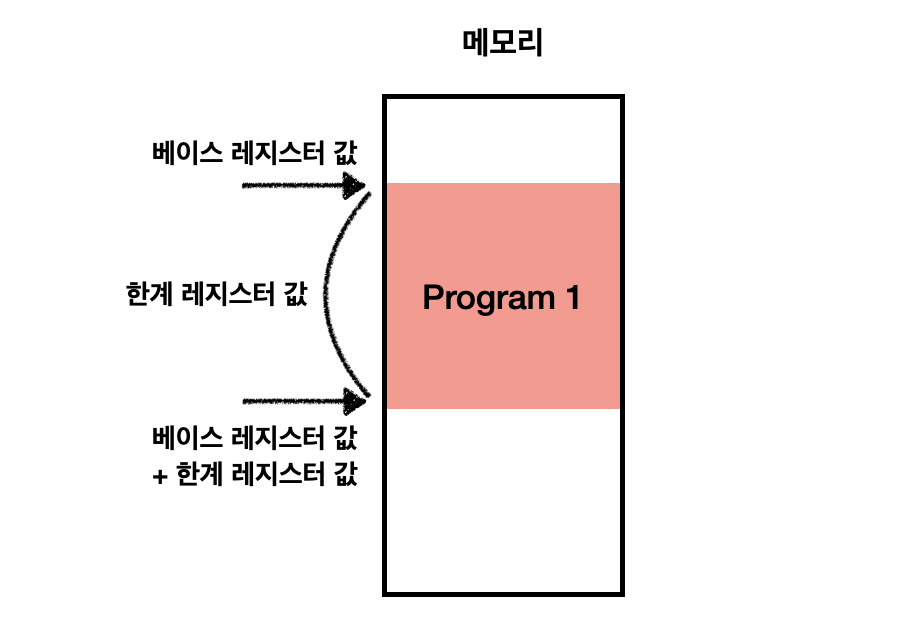
🔖 한계 레지스터
논리 주소의 최대 크기를 저장한다.
💡 베이스 레지스터 값 <= 물리 주소 < 베이스 레지스터 값 + 한계 레지스터 값
💡 논리 주소 < 한계 레지스터 값
CPU는 메모리에 접근하기 전에 논리 주소가 한계 레지스터보다 작은지 항상 검사하고, 이를 초과한다면 인터럽트 (트랩)을 발생시켜 실행을 중단한다.
이러한 방식으로 실행 중인 프로그램의 독립적인 실행 공간을 확보하고 하나의 프로그램이 다른 프로그램을 침범하지 못하게 보호할 수 있다.
📌 캐시메모리
CPU는 프로그램을 실행하는 과정에서 메모리에 저장된 데이터를 빈번하게 사용한다. 따라서 CPU가 연산하는 속도가 아무리 빨라도 메모리 접근 시간이 느리면 의미가 없다. 이를 극복하기 위한 저장장치가 캐시메모리이다.
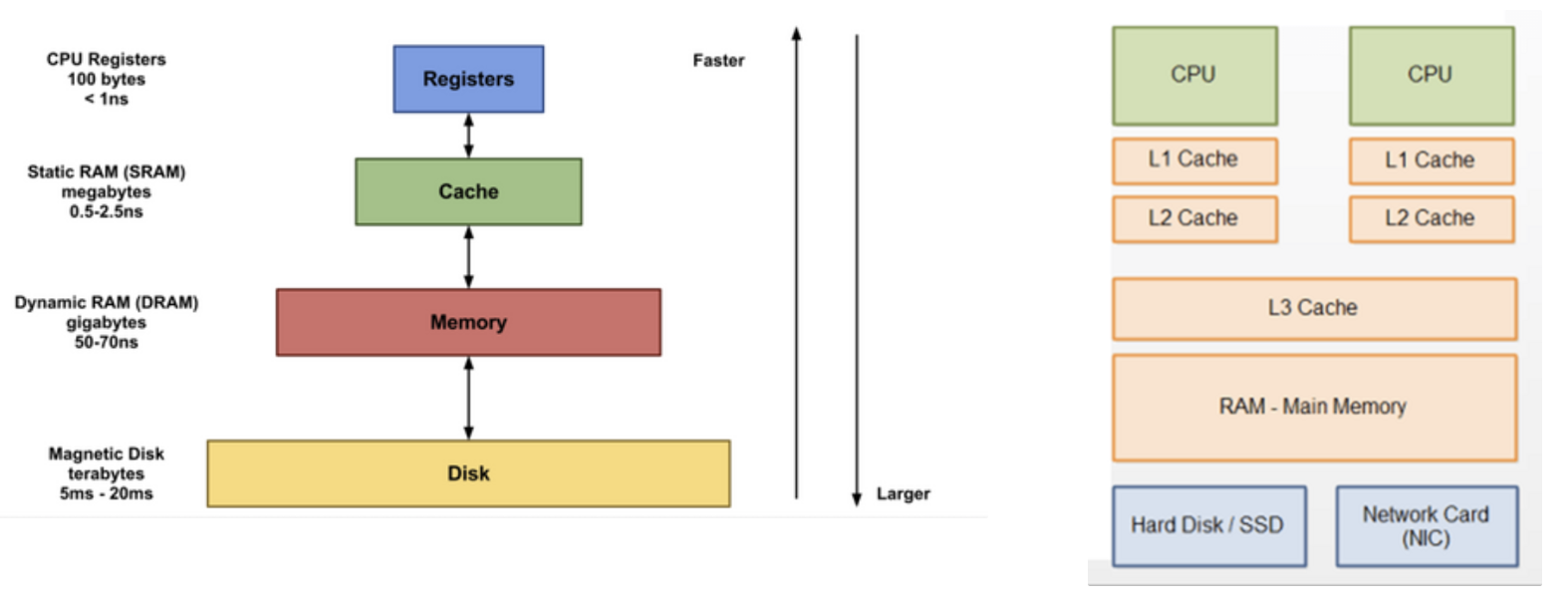
○ 저장 장치 계층 구조
저장 장치는 일반적으로 아래와 같은 명제를 따른다.
- CPU와 가까운 저장 장치는 빠르고, 멀리 있는 저장 장치는 느리다.
- 속도가 빠른 저장 장치는 저장 용량이 작고, 가격이 비싸다.
저장 장치는 'CPU에 얼마나 가까운가'를 기준으로 계층적으로 나타낼 수 있으며 이를 저장 장치 계층 구조 (memory hierachy)라고 한다.
○ 캐시 메모리
🔖 캐시 메모리
CPU와 메모리 사이에 위치하고, 레지스터보다 용량이 크고 메모리보다 빠른 SRAM 기반의 저장 장치이다.
CPU가 매번 메모리에 왔다갔다 하는건 시간이 오래 걸리니, 메모리에서 CPU가 사용할 일부 데이터를 미리 캐시 메모리로 가져와서 활용한다. 캐시 메모리들은 CPU (core)와 가까운 순서대로 L1 (level1) 캐시, L2 캐시, L3 캐시가 있다. 일반적으로 L1 캐시와 L2 캐시는 코어 내부에, L3 캐시는 코어 외부에 위치해있다.
- 메모리 용량 : L1 < L2 < L3
- 속도 : L1 > L2 > L3
- 가격 : L1 > L2 > L3
- 검색 순서 : L1 > L2 > L3
멀티 코어 프로세서에서 주로 L1 캐시와 L2 캐시는 코어마다 고유한 캐시 메모리로 할당되고, L3 캐시는 여러 코어가 공유하는 형태로 사용된다.
🔖 분리형 캐시 (Split cache)
코어와 가장 가까운 L1 캐시는 조금이라도 접근 속도를 더 빠르게 하기 위해 명령어만을 저장하는 L1I 캐시와 데이터만을 저장하는 L1D 캐시로 분리하는 경우도 있다.
○ 참조 지역성 원리
캐시 메모리는 CPU가 사용할 법한 대상을 예측하여 저장한다. 따라서 가져온 뎅이터를 쓸 수도 있고 안 쓸 수도 있다.
- Cache hit : 예측한 데이터가 실제로 들어맞아 캐시 메모리의 데이터를 CPU가 활용한 경우
- Cache miss : 예측이 틀려 메모리에서 데이터를 직접 가져와야 하는 경우
- Cache hit ratio : 캐시가 히트되는 비율
hit / (hit + miss)
우리가 사용하는 컴퓨터의 캐시 적중률은 대략 85~95% 이상이다.
캐시메모리는 참조 지역성의 원리 (Locality of Reference, Principle of Locality)에 따라 가져올 데이터를 결정한다.
시간 지역성: 최근에 접근했던 메모리 공간에 다시 접근하는 경향이 있다.공간 지역성: 접근한 메모리 공간 근처를 접근하는 경향이 있다.
참고
혼자 공부하는 컴퓨터구조 + 운영체제
