String matching
백준 9253번에서
문제의 조건은 동일하다. 편의상 사용자가 출력한 문자열의 길이가 문제의 답과 동일하고, 답은 0보다 크다고 가정한다.이라는 조건이 있다. 따라서 세번째로 오는 문자열이 위의 두 문자열에 포함되는지 여부만 확인하면 된다.
백준 9253문제를 풀면서 contains()를 사용해서 통과를 하기는 했다. 그러나 더 빠른 방법을 찾다가 문자열에서 포함여부를 확인하는 알고리즘으로 KMP 알고리즘을 알게되었다. 그래서 contains()는 어떻게 구현되어 있는지 궁금해서 찾아보았다. (잘 짜여져있을 거라 기대했다..)
String 클래스의 contains()는 indexOf()를 이용한 것이었다.
public boolean contains(CharSequence s) {
return indexOf(s.toString()) >= 0;
}그리고 indexOf()의 메서드를 따라가면 StringLatin1 클래스의 indexOf() 메서드를 만난다.
@IntrinsicCandidate
public static int indexOf(byte[] value, int valueCount, byte[] str, int strCount, int fromIndex) {
byte first = str[0];
int max = (valueCount - strCount);
for (int i = fromIndex; i <= max; i++) {
// Look for first character.
if (value[i] != first) {
while (++i <= max && value[i] != first);
}
// Found first character, now look at the rest of value
if (i <= max) {
int j = i + 1;
int end = j + strCount - 1;
for (int k = 1; j < end && value[j] == str[k]; j++, k++);
if (j == end) {
// Found whole string.
return i;
}
}
}
return -1;
}별거없네..
KMP 알고리즘
- Knuth-Morris-Pratt 알고리즘
- 문자열 매칭 알고리즘
- 접두사와 접미사를 이용하여 매칭이 실패했을 때 일치했던 부분까지 되돌아가서 다시 검사하는 방식
- 일치하지 않는 문자가 나왔을 때 아래와 같이 점프할 수 있다.
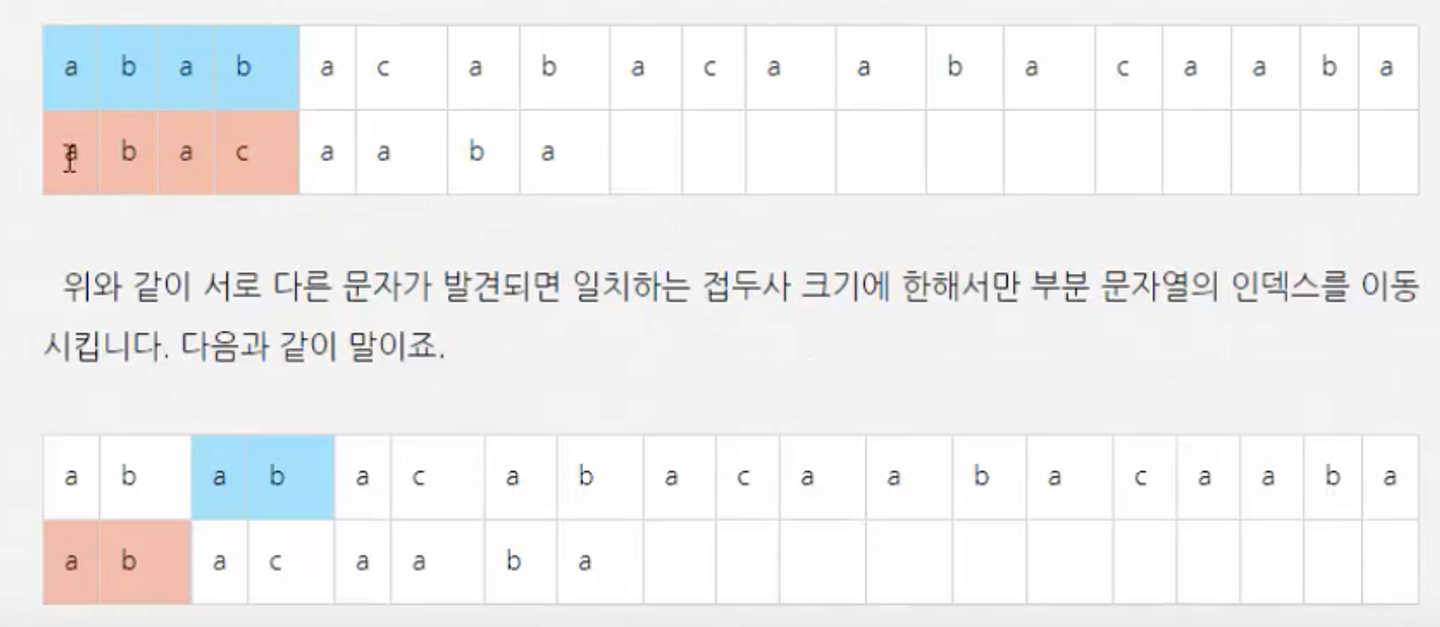
table 만들기
문자열을 하나씩 매칭하다가 다른 경우, 찾으려는 문자열에서 어느 인덱스로 돌아갈지 저장하는 table이다. KMP에서는 이를 참고해서 매칭을 더 빨리 할 수 있다.
static int[] makeTable(String str) {
int[] table = new int[str.length()];
int idx = 0;
for (**int i = 1**; i < table.length; i++) {
while (idx > 0 && str.charAt(i) != str.charAt(idx)) {
idx = table[idx - 1];
}
if (str.charAt(idx) == str.charAt(i)) {
table[i] = ++idx;
}
}
return table;
}최종 답안
import java.io.*;
import java.util.Arrays;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String A = br.readLine();
String B = br.readLine();
String answer = br.readLine();
int[] table = makeTable(answer);
String result = "NO";
if (KMP(A, answer, table) && KMP(B, answer, table)) {
result = "YES";
}
System.out.println(result);
}
static int[] makeTable(String str) {
int[] table = new int[str.length()];
int idx = 0;
for (int i = 1; i < table.length; i++) {
while (idx > 0 && str.charAt(i) != str.charAt(idx)) {
idx = table[idx - 1];
}
if (str.charAt(idx) == str.charAt(i)) {
table[i] = ++idx;
}
}
return table;
}
static boolean KMP (String parent, String target, int[] table) {
int idx = 0;
for (int i = 0; i < parent.length(); i++) {
while (idx > 0 && parent.charAt(i) != target.charAt(idx)){
idx = table[idx - 1];
}
if (parent.charAt(i) == target.charAt(idx)) {
if (idx == target.length()-1) {
return true;
} else {
idx++;
}
}
}
return false;
}
}Rabin-karp (Rolling-hash)
- 해싱을 이용해서 찾으려는 문자열과 sliding index로 어느 한 부분을 비교한다. 같은 문자열이라면 같은 해싱값을 가질 것이다. (하지만 혹시 모르니 한 번 더 체크를 하긴한다.)
Rabin fingerprint
아래와 같은 해싱함수를 이용한다. 왜냐하면 옆으로 옮겼을 때 모든 값을 다시 계산하지 않고 양 사이드 값만 빼고, 더해주면 되기 때문이다.
하지만 찾으려는 문자열의 크기가 크면 숫자가 너무 커져 모듈러를 적용해보려고 했는데 복잡해져서 보류하였다.

import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String A = br.readLine();
String B = br.readLine();
String answer = br.readLine();
String result = "NO";
if (rabin(A, answer) && rabin(B, answer)) {
result = "YES";
}
System.out.println(result);
}
static boolean rabin (String parent, String target) {
boolean result;
int tLen = target.length();
int power = 1;
int tHash = 0;
int pHash = 0;
for (int i = 1; i < tLen; i++) {
tHash += power * target.charAt(tLen - i);
pHash += power * parent.charAt(tLen - i);
power *= 2;
}
tHash += power * target.charAt(0);
pHash += power * parent.charAt(0);
for (int i = 0; i <= parent.length() - tLen; i++) {
if (i > 0) {
pHash -= power * parent.charAt(i-1);
pHash = pHash * 2 + parent.charAt(i + tLen - 1);
}
if (tHash == pHash) {
result = true;
for (int j = 0; j < tLen; j++) {
if (parent.charAt(i + j) != target.charAt(j)) {
result = false;
break;
}
}
if (result) return true;
}
}
return false;
}
}비교
Rabin이 조금 더 빠르다.
Rabin

KMP

훈이야 화이팅