👉 1주차 숙제 :
지니뮤직의 1-50위 곡의 정보를 스크래핑 해보세요.
- 필요한 패키지 임포트하기
- requests로 html 받아오기
- soup으로 요소들 select 해오기
- for문으로 필요한 요소 받아오기
- 이쁘게 가공하기
- 데이터테이블 만들기
1. 필요한 패키지 임포트하기
import requests
import pandas as pd
from bs4 import BeautifulSoup 2. requests로 html 받아오기
# 차단되는 것을 방지하기 위해 headers 설정해주기
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
# requests의 get 모듈을 통해 html 소스를 변수에 대입
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=D&ymd=20211103&hh=13&rtm=N&pg=1',headers=headers)3. soup으로 요소들 select 해오기
# html을 text형식으로 변수에 대입
soup = BeautifulSoup(data.text, 'html.parser')
# html에 있는 <tr>들을 변수에 리스트 형태로 저장
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')✋
.select는 찾은 모든 html을 리스트 형태로 반환하고
.select_one은 찾은 html 중 가장 첫 번째 html을 가져온다.
즉,.select뒤에[0]을 붙여 준 것이.select_one과 같은 기능을 한다.
이를 몰라서 2가지 포인트를 놓쳤다.
1. for문을 적용할 때, trs가 리스트형태인 줄 몰라서 이를 어떻게 적용해야할 지 몰랐다.
2. tr.select('').text : select는 리스트 형태로 text화 할 수가 없으므로 오류가 난다.
4. for문으로 필요한 요소 받아오기
trs에는 50개의 tr태그가 리스트형태로 저장되어 있다.
len(trs)
#result
50이를 for문을 이용하여 하나하나 받아서 그 안에 있는 순위, 곡명, 아티스트 정보들을 받아온다.
trs에 있는 요소에서 soup의 select 모듈을 이용해 필요한 것을 하나씩 가져온다. 일단 타이틀만 가져와보면
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for tr in trs:
title = tr.select_one('td.info > a.title.ellipsis')
print(title)
#result
하루만 더</a>
<a class="title ellipsis" href="#" onclick="fnPlaySong('92673418','1');return false;" title="재생">
사이렌 Remix (Feat. UNEDUCATED KID & Paul Blanco)</a>
<a class="title ellipsis" href="#" onclick="fnPlaySong('90077755','1');return false;" title="재생">
이제 나만 믿어요</a>
<a class="title ellipsis" href="#" onclick="fnPlaySong('93269771','1');return false;" title="재생">
...
보이는 것처럼 태그도 달려있고, 모양이 이쁘지는 않다.
태그도 떼고, 공백을 제거해야 한다.
👉 .text
태그 내의 텍스트를 추출한다.
.string
태그 내의 텍스트를 객체화하여 표현한다.
👉 strip()
- strip([chars]) : 인자로 전달된 문자를 String의 왼쪽과 오른쪽에서 제거합니다.
- lstrip([chars]) : 인자로 전달된 문자를 String의 왼쪽에서 제거합니다.
- rstrip([chars]) : 인자로 전달된 문자를 String의 오른쪽에서 제거합니다.
인자를 전달하지 않을 수도 있으며, 인자를 전달하지 않으면 String에서 공백을 제거합니다.
이를 이용하여 title을 보기 좋게 가져온다.
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for tr in trs:
title = tr.select_one('td.info > a.title.ellipsis').text.strip()
print(title)
#result
strawberry moon
Savage
문득
Stay
신호등
나비효과
다정히 내 이름을 부르면
OHAYO MY NIGHT
My Universe
Next Level
...순위를 받아올 때도 뒤에 많이 따라오는데 필요한 것만 받아오기 위해서 slicing을 이용한다.
for tr in trs:
title = tr.select_one('td.info > a.title.ellipsis').text.strip()
rank = tr.select_one('td.number').text[0:2].strip()
artist = tr.select_one('td.info > a.artist.ellipsis').text
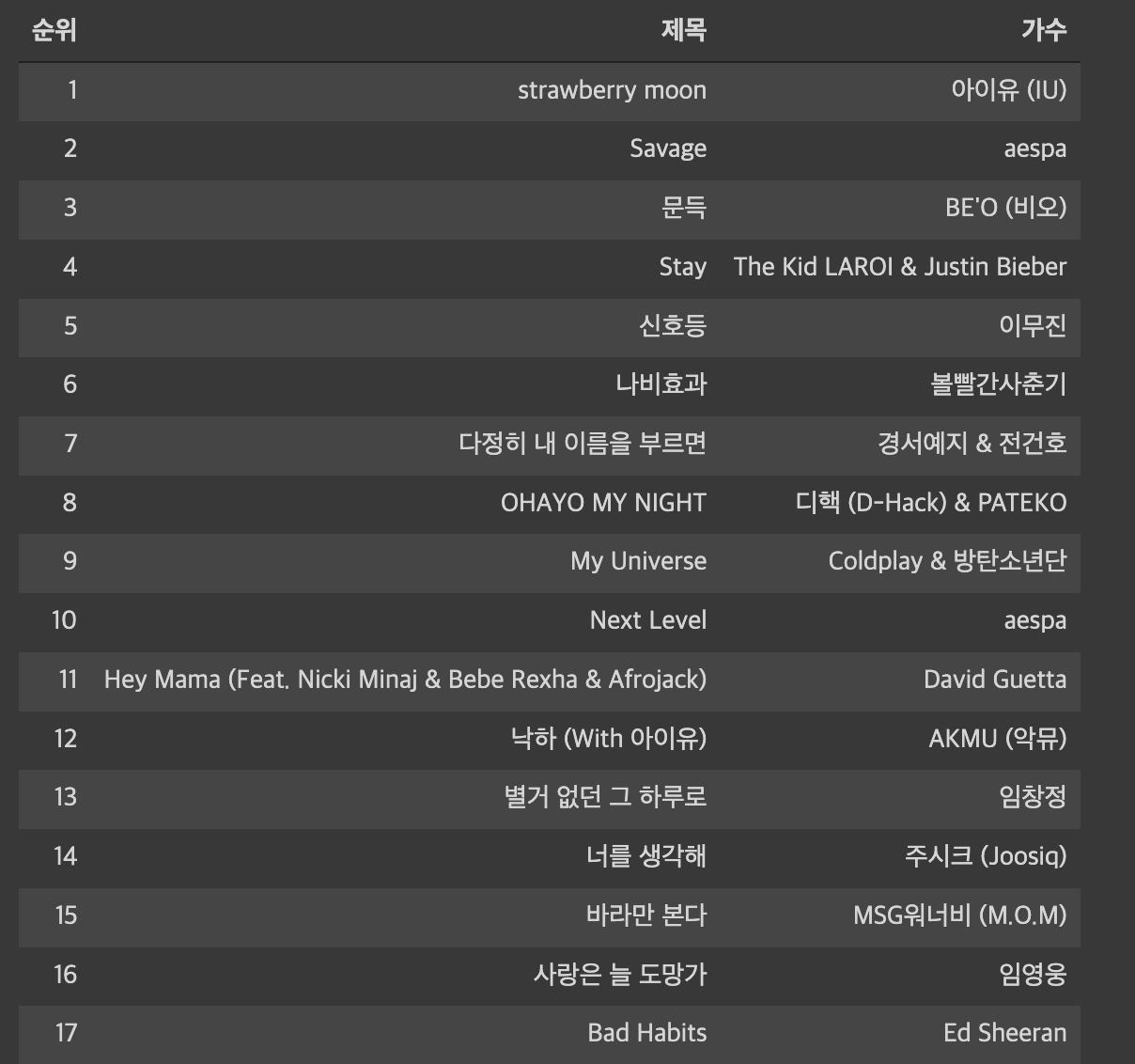
print(rank, title, artist)# result
1 strawberry moon 아이유 (IU)
2 Savage aespa
3 문득 BE'O (비오)
4 Stay The Kid LAROI & Justin Bieber
5 신호등 이무진
6 나비효과 볼빨간사춘기
7 다정히 내 이름을 부르면 경서예지 & 전건호
8 OHAYO MY NIGHT 디핵 (D-Hack) & PATEKO
9 My Universe Coldplay & 방탄소년단
10 Next Level aespa
11 Hey Mama (Feat. Nicki Minaj & Bebe Rexha & Afrojack) David Guetta
12 낙하 (With 아이유) AKMU (악뮤)
13 별거 없던 그 하루로 임창정
14 너를 생각해 주시크 (Joosiq)
15 바라만 본다 MSG워너비 (M.O.M)
16 사랑은 늘 도망가 임영웅
17 Bad Habits Ed Sheeran
18 나의 첫사랑 다비치
19 Weekend 태연 (TAEYEON)
20 Permission to Dance 방탄소년단
21 19금
Peaches (Feat. Daniel Caesar & Giveon) Justin Bieber
22 시간을 거슬러 (낮에 뜨는 달 X 케이윌) 케이윌 (K.Will)
23 고백 멜로망스 (MeloMance)
24 Butter 방탄소년단5. 이쁘게 가공하기
위에서 21위는 보면 갑자기 떨어져있는 것을 볼 수 있다.
'19금'이 포함되면서 모양이 바뀌었다.

'19금'의 표시가 되어있는 html 형식을 보면 span 태그로 묶여있다. 따라서 제목이 있는 태그는 가져오되 span 태그를 제외하고 가져오는 방식을 사용한다.
title로 설정했던 값에서 span 태그를 찾아서 지우는 .find('span').decompose()를 추가하면 된다.
title = tr.select_one('td.info > a.title.ellipsis').find('span').decompose().text.strip()하지만, 이렇게 하면 span 태그가 포함되어 있지 않은 tr에서는 오류가 난다. 따라서 오류가 나면 처음에 정했던 방식으로 진행되는 try, except 예외처리기법을 사용한다.
for tr in trs:
rank = tr.select_one('td.number').text[0:2].strip()
artist = tr.select_one('td.info > a.artist.ellipsis').text.strip()
title_div = tr.select_one('td.info > a.title.ellipsis')
try:
title = title_div.find('span').decompose().text.strip()
except:
title = tr.select_one('td.info > a.title.ellipsis').text.strip()
print(rank, title, artist)
#result
1 strawberry moon 아이유 (IU)
2 Savage aespa
3 문득 BE'O (비오)
4 Stay The Kid LAROI & Justin Bieber
5 신호등 이무진
6 나비효과 볼빨간사춘기
7 다정히 내 이름을 부르면 경서예지 & 전건호
8 OHAYO MY NIGHT 디핵 (D-Hack) & PATEKO
9 My Universe Coldplay & 방탄소년단
10 Next Level aespa
11 Hey Mama (Feat. Nicki Minaj & Bebe Rexha & Afrojack) David Guetta
12 낙하 (With 아이유) AKMU (악뮤)
13 별거 없던 그 하루로 임창정
14 너를 생각해 주시크 (Joosiq)
15 바라만 본다 MSG워너비 (M.O.M)
16 사랑은 늘 도망가 임영웅
17 Bad Habits Ed Sheeran
18 나의 첫사랑 다비치
19 Weekend 태연 (TAEYEON)
20 Permission to Dance 방탄소년단
21 Peaches (Feat. Daniel Caesar & Giveon) Justin Bieber
22 시간을 거슬러 (낮에 뜨는 달 X 케이윌) 케이윌 (K.Will)이쁘게 나온다!
6. 데이터테이블 만들기 (최종 숙제)
import requests
import pandas as pd
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=D&ymd=20211103&hh=13&rtm=N&pg=1',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
title_list = []
artist_list = []
ranking = []
for tr in trs:
# title = tr.select_one('td.info > a.title.ellipsis').text.strip()
rank = tr.select_one('td.number').text[0:2].strip()
artist = tr.select_one('td.info > a.artist.ellipsis').text
title_div = tr.select_one('td.info > a.title.ellipsis')
try:
title = title_div.find('span').decompose().text.strip()
except:
title = tr.select_one('td.info > a.title.ellipsis').text.strip()
title_list.append(title)
artist_list.append(artist)
ranking.append(rank)
df = pd.DataFrame({'순위' : ranking, '제목' : title_list, '가수' : artist_list})
df.style.hide_index()
#result