✋
데이터 분석이란?
"컴퓨터 도구를 효율적으로 이용하고, 적절한 통계학 방법을 사용하여 실제적인 문제에 답을 내리는 활동"
1주차 목표
1. HTML 문서의 개념에 대해서 이해한다.
2. 구글 Colab 사용방법을 익힌다.
3. 태그의 형식에 대해서 이해한다.
4. 크롤링의 위한 패키지 BeautifulSoup4의 사용법을 이해한다.
엑셀을 이용해 데이터분석을 맛보고, 본격적으로 파이썬 기초 문법과 웹 스크래핑 (크롤링) 하는 방법에 대해 배워봅시다!
✍️ 엑셀로 데이터분석 맛보기
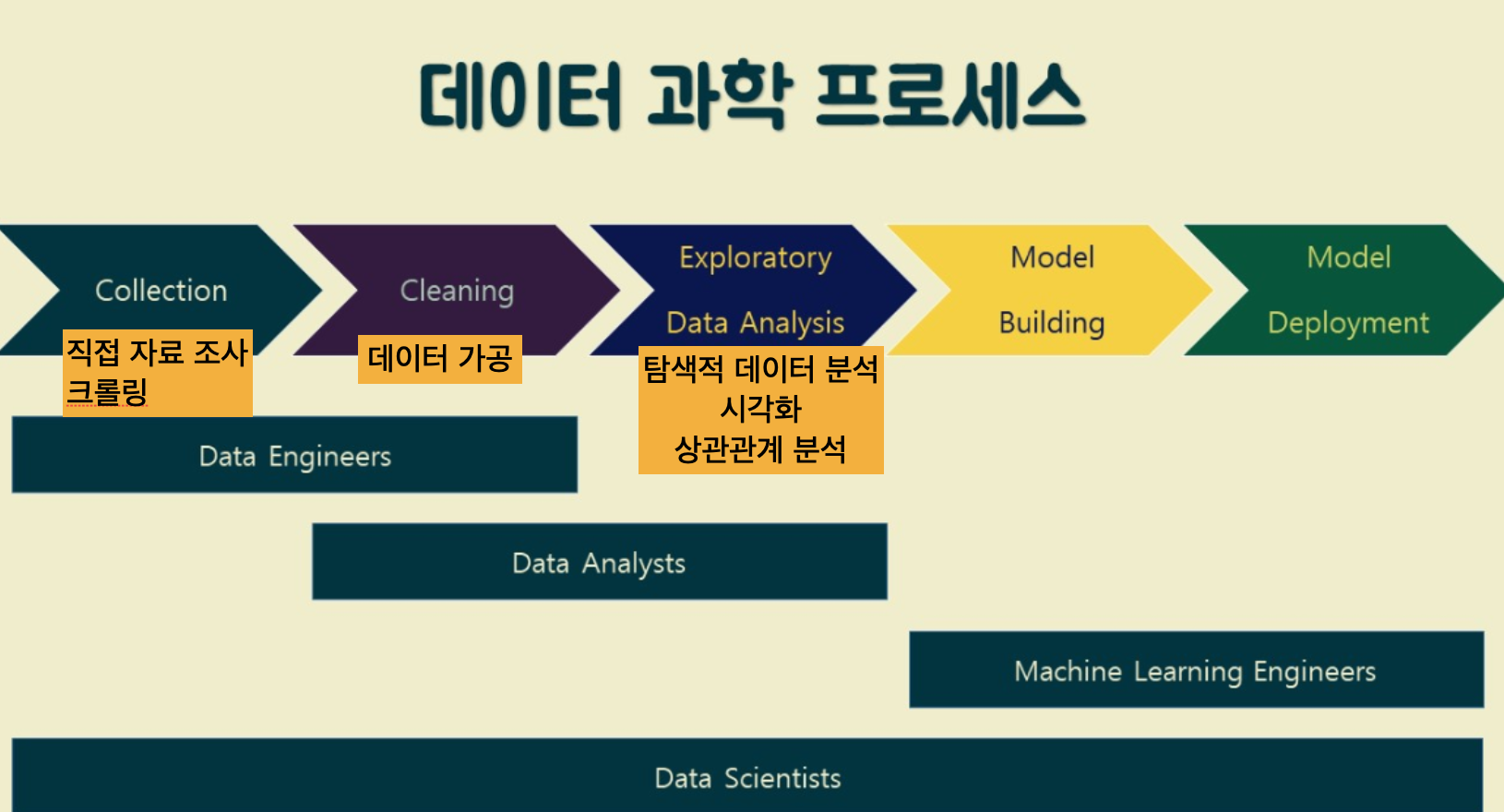
Collection
👉 Kaggle에서는 데이터 분석에 필요한 데이터셋을 제공하고 이걸로 competition을 하기도 한다!
Cleaning
👉 구글 스프레드시트 에서 .csv 파일을 열 수 있다.
Exploratory Data Analysis
- 데이터 상관관계 분석
- 스프레드시트 - 부가기능 - 부가기능 설치하기 - 'analysis toopak' 설치
- 부가기능 - XLMiner Analysis ToolPak - Correlation
- 상관계수 : 변수들 간의 상관 정도 (인과관계와는 다르다.) 1에 가까울 수록 해당 변수가 증가할 때 다른 변수 (성적) 또한 함께 증가할 확률이 높고, -1에 가까울 수록 해당 변수가 증가할 때 다른 변수 (성적)은 감소할 확률이 높다.
엑셀의 한계
예측을 하고 싶을 때 회귀 분석을 사용할 수 있다.
이 과정에서 정확도를 높이기 위해 정규화, 이상치 탐지 등의 과정을 거치는데 엑셀에서는 지원하지 않는다.
엑셀에서도 예측을 위한 도구가 존재하기는 하지만, 선형 회귀 이외의 다른 종류의 회귀 분석을 지원하지 않는다는 단점이 있고, 정확도를 평가하는 수단에도 한계가 있다.
그렇기 때문에 더 높은 정확도의 예측 모델을 구현하기 위해서는 파이썬 등의 수단을 이용할 수 있다. 더 다양한 그래프를 통해 데이터를 분석하고, 더 다양한 머신러닝 알고리즘을 통해서 예측을 진행할 필요가 있다.
✍️ 구글 Colab과 익숙해지기
👉 Colab : 코랩은 인터넷과 구글 ID만 있다면 따로 개발 환경을 위한 셋팅을 하지 않고도 언제든 파이썬을 이용할 수 있다.
list에서 append, extend
list_1.append(155) #리스트에 155를 추가
list_1.extend(list_2) #list_1에 list_2를 추가
for문 (반복문) / if문 (조건문)
for문
1. for문 끝에 : (콜론) 을 붙여줘야 한다.
2. 반복해서 실행될 코드는 indentation 을 해주어야 한다. 탭 키를 한 번 누르거나 스페이스바 4번 누를 수 있는데, 요즘은 스페이스바를 누르는 추세이다.
for i in range(0, 5): # 맨 끝에 :(콜론)을 사용하였다.
print(i,'번 반복할게요~') # print 앞에 들여쓰기를 해주었다.0 번 반복할게요~
1 번 반복할게요~
2 번 반복할게요~
3 번 반복할게요~
4 번 반복할게요~비교연산자 : x < y, x > y, x ==y, x != y, x >= y, x <= y
if문
If <조건문>:
<수행할 문장1>
<수행할 문장2>
...
elif <조건문>:
<수행할 문장1>
<수행할 문장2>
...
elif <조건문>:
<수행할 문장1>
<수행할 문장2>
...
else: # else 뒤에는 조건문이 없어야 함!
<수행할 문장1>
<수행할 문장2>함수
def 함수이름(함수의 인자1, 함수의 인자2, ....):
수행할 코드
return 최종 결과✋ 클래스
- class 만들기 예시
class Monster():
hp = 100
mp = 10
def damage(self, attack):
self.hp = self.hp - attack
monster1 = Monster() #객체1
monster1.damage(120)
monster2 = Monster() #객체2
monster2.damage(90)- 클래스 (class) : 과자 틀
- 객체 (object) : 과자 틀에 의해서 만들어진 과자
클래스로 만든 객체는 객체마다 고유한 성격을 가진다는 특징이 있다. - 인스턴스 (instance) : 특정 객체가 어떤 클래스의 객체인지 관계 위주로 설명할 때 사용.
즉, "a는 인스턴스" 보다는 "a는 객체"라는 표현이 어울리며, "a는 Monster의 객체"보다는 "a는 Monster의 인스턴스"라는 표현이 어울린다. - 객체를 type 함수에 넣으면 다음과 같이 클래스의 객체임을 보여준다.
class FourCal:
pass
a = FourCal()
type(a)
__main__.FourCal-
매서드 (method) : 클래스 안에 구현된 함수
- 파이썬 매서드의 첫 번째 매개변수 이름은 관례적으로 self를 사용한다. 객체를 호출할 때 호출한 객체 자신이 전달되기 때문에 self를 사용한 것이다. 변수에는 self를 제외한 나머지 변수만 입력해도 된다.```python class Monster(): hp = 100 mp = 10 def damage(self, attack): self.hp = self.hp - attack ``` - 객체를 통해 클래스의 메서드를 호출하려면 도트(.) 연산자를 사용 ```python monster1.damage(100) ```클래스의 모든 부분을 이해할 필요는 없다.
객체를 위와 같은 방식으로 생성할 수 있고, 그 객체가 가진 함수를 (객체명).(함수명) 을 통해서 이용할 수 있다는 사실만 기억하고 넘어가면 된다.
앞으로 우리가 이용할 패키지, 모듈에서 제공하는 기능들을 위와 같은 방식으로 이용하게 될 것이다.
예외처리 - Try, except문
데이터를 가공할 때 자주 쓰이는 문법이다.
0으로 나누려고 하면 ZeroDivision 에러가 발생한다. 이때는 아래 코드를 작성하면 try해보고 에러가 발생하면 except 아래의 코드가 실행된다.
b = 0
try:
print(a/b)
except:
print('0으로는 나눌 수 없어요!')✍️ Pandas & DataFrame
패키지 (package)는 누군가가 이미 만들어놓은 함수, 클래스 덩어리를 말한다. 우리가 어떤 기능을 직접 구현하지 않더라도 바로바로 사용하라고 누군가가 이미 기능을 만들어 놓은 것이다. import 라는 명령어를 사용해서 가져오기만 하면 바로 사용할 수 있다.
판다스 (Pandas)는 파이썬 데이터 분석을 위한 필수 패키지 중 하나이다. 그 중 표 형태의 구조인 데이터 프레임은 주로 데이터를 읽어서 저장하고, 연산을 위해 많이 사용된다.
import pandas as pd위 코드로 import 해오며, 'pd.함수이름'과 같은 형식으로 판다스가 제공하는 함수 / 기능들을 사용할 수 있다.
데이터 프레임을 만드는 방법은 여러가지가 있으면 그 중 한 방법이다.
# df란 이름의 데이터프레임을 생성합니다.
items = {'code' : [101, 102, 103, 104, 105, 106, 107, 108],
'과목': ['수학', '영어', '국어', '체육', '미술', '사회', '도덕', '과학'],
'수강생':[15, 15, 10, 50, 20, 50, 70, 10],
'선생님': ['김민수','김현정','강수정', '이나리', '도민성', '강수진', '김진성', '오상배']}
df = pd.DataFrame(items)
df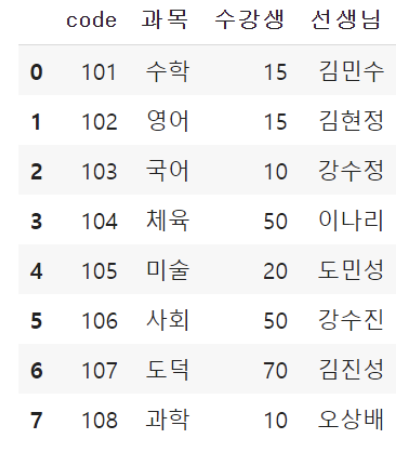
👉 사용할 수 있는 함수들
# head()를 하면 상위 5개의 행만 출력
df.head()
# tail()를 하면 하위 5개의 행만 출력
df.tail()
# sample(숫자)를 하면 랜덤으로 2개의 행만 출력
df.sample(2)
# 데이터프레임 2개를 연결
total_df = pd.concat([df, df2])
total_df
# 데이터프레임을 csv 파일로 저장
total_df.to_csv('data.csv', index=False)
# csv 파일을 읽어서 데이터프레임에 저장
new_df = pd.read_table('data.csv', sep=',')
# 열 제목을 붙이기
new_df = pd.read_table('data.csv', sep=',', names=['Index', 'Code', '과목', '수강생', '선생님'])
new_df