
글에 중간 중간에 첨부된 다이어그램은 스터디에서 사용하는 다이어그램을 캡처하였습니다.
쿠버네티스 모니터링 도구
메트릭 서버
쿠버네티스에서 기본적인 메트릭 집합을 지원한다. 메트릭 파드를 설치하면 사용자는 간단하게
kubectl top명령어로 현재 노드와 파드의 CPU, 메모리 사용량을 확인 할 수 있다.
# 공식 설치 가이드
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
kubectl top pod --sort-by memory # 메모리 사용량 순서
kubectl top pods --help 로 확인
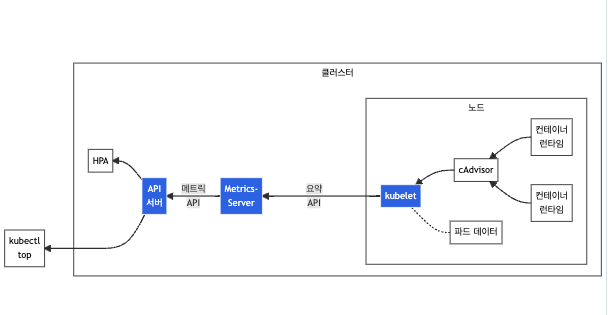
메트릭 서버는 사용자의 kubectl top 명령어를 API 서버에서 전달받아 개별 노드에 실행 중인 kubelet의 cAdvisor에 전달해서 현재 파드와 노드의 자원 사용량을 가져온다.
cAdvisor(Container Advisor)는 컨테이너와 노드의 CPU, 메모리, 네트워크, 파일 등에 대한 다양한 자원 사용량을 백그라운드에서 자동 수집한다.
프로메테우스 - 쿠버네티스 모니터링 시스템
쿠버네티스 환경은 모니터링 측면에서 기존의 가상 머신이나 베어메탈 환경과 어떻게 다른가?
- 서비스 디스커버리
- 쿠버네티스 환경에서 파드가 죽었다 다시 살아나는 것이 자유롭다. 새로운 파드는 자동으로 모니터링 대상으로 등록돼야 하고 사라진 파드는 모니터링 대상에서 역시 자동으로 제거돼야 한다. -> 모든 과정이 사람의 개입 없이 이루어져야 함
- 애플리케이션 중심 모니터링
- 기존의 모니터링 시스템에서도 애플리케이션은 모니터링의 중요한 요소이다. 쿠버네티스는 기본 단위인 파드 자체가 일종의 애플리케이션 프로세스이므로 기존의 가상 머신처럼 기본 단위가 시스템이 아닌 애플리케이션이므로 모니터링 역시 기본 관점을 애플리케이션으로 접근해야하고 파드뿐만 아니라 ConfigMap, Secret, Service 등 리소스 역시 모니터링의 중요한 요소이다.
쿠버네티스 환경의 모니터링 대상은?
- 노드와 컨테이너 자원 사용량 모니터링
- 일반 가상 머신 환경과 유사하게 노드와 컨테이너의 CPU, Memory, 네트워크, 스토리지 등 사용량에 관한 모니터링 필요
- 클러스터 모니터링
- 사용중인 쿠버네티스 오브젝트의 전체 수량 등 전반적인 현황과 파드의 재시작, 이벤트 메세지 등 장애와 관련된 모니터링 등 쿠버네티스 클러스터 전반에 관한 모니터링이 필요
- 애플리케이션 모니터링
- 쿠버네티스 내부적으로 사용하는 컨트롤 플레인 파드(etcd, apiserver, coredns) 뿐만 아니라 웹, 데이터베이스 등 개발자가 추가로 설치한 애플리케이션에 대한 모니터링 필요
쿠버네티스 모니터링 솔루션으로는 프로메테우스 등과 같은 오픈소스 솔루션과 데이터독, 뉴렐릭, 와탭 등 상용 솔루션으로 분류 할 수 있음.
-> 프로메테우스는 사실상의 쿠버네티스 환경의 모니터링 표준
( 뭐든 표준 따라가는게 좋다 git 브런치 전략이던 컨테이너 환경 이던.. )
프로메테우스의 특징
- 서비스 디스커버리
- pull 방식
- 다양한 애플리케이션 익스포터 제공
- 다양한 레이블 지원
- 자체 검색 언어인 PromQL 제공
- 시계열 데이터베이스(time-series database, TSDB) 사용
프로메테우스 스택 설치
프로메테우스 스택은 프로메테우스와 관련해서 모니터링에 필요한 여러 요소를 함께 제공하는 것을 의미

헬름 설치하려고 보니 이전에 설치했다고 뜬다. 언제 깔았지 🧐
# 파라미터 파일 생성
# 가시다님이 삽질 하지 않게 고대로 복붙 하라고 만들어주셨다. 우하하
cat <<EOT > ~/monitor-values.yaml
alertmanager:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- alertmanager.$KOPS_CLUSTER_NAME
paths:
- /*
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- grafana.$KOPS_CLUSTER_NAME
paths:
- /*
prometheus:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- prometheus.$KOPS_CLUSTER_NAME
paths:
- /*
prometheusSpec:
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
EOT생성한 monitor-values.yaml 토대로 helm 설치.
네임스페이스는 monitoring으로 명명한다.
참고로 운영 환경에서는 resource requests/limits 등의 추가 설정이 필요하다고 한다.
# 배포
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 45.7.1 \
--set prometheus.prometheusSpec.scrapeInterval='15s' --set prometheus.prometheusSpec.evaluationInterval='15s' \
-f monitor-values.yaml --namespace monitoring몇 초 뒤 설치 완료


새삼 다시 느끼는것이지만 helm 차트는 참 좋은 서비스 인 것 같다.
프로메테우스 아키텍처
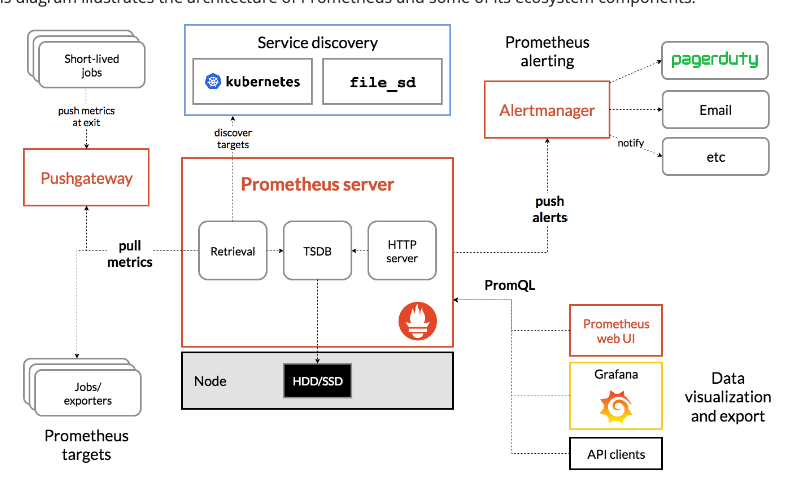
푸시 게이트웨이를 통해 측정항목을 스크랩 -> 이러쿵 저러쿵 해서 PromQL로 시각화 데이터를 보여주고 Push Alert로 알림을 보내준다

- 얼럿메니저: 사전에 정의한 정책 기반등으로 시스템 경고 메세지가 얼럿매니저로 전달되고 중복 제거, 메세지 그룹화 등 사후 처리 작업을 거쳐서 알림 전송
- 그라파나: 별도 시각화 솔루션
- 프로메테우스 파드: 기본적으로 스테이트풀셋(statefulset)으로 배포된다. 모니터링 대상이 되는 파드는 'exporter' 라는 별도의 사이드카 형식의 컨테이너로 모니터링 대상이 되는 메트릭을 노출. 해당 메트릭을 프로메테우스 파드는 풀(pull) 방식으로 가져와 내부의 시계열 데이터베이스 (TSDB)에 저장한다. 저장된 정보는 프로메테우스 웹 서버 또는 그라파나를 통해 그래프 형태로 조회할 수 있다.
- 노드 익스포터: 데몬셋으로 설치되어 모니터링 대상이 되는 전체 노드에 자동으로 설치된다.
모니터링
로컬로 임시 확인
프로메테우스 플랫폼을 포함한 대부분의 모니터링 시스템은 기본 설정으로 웹서버의 /metrics 엔드포인트 경로에 노출(expose) 한다. 프로메테우스는 노드 익스포터의 서비스 이름과 9100 포트를 사용해 접속한다.
port-forward 명령어를 사용하면 NodePort, LoadBalancer, Ingress 등으로 지정하지 않은 ClusterIP 타입의 서비스를 임시로 외부에서 접속하는 경우 사용할 수 있다.
# 마스터노드에 lynx 설치
ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME hostname
ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME sudo apt install lynx -y
# 노드의 9100번의 /metrics 접속 시 다양한 메트릭 정보를 확인할수 있음 : 마스터 이외에 워커노드도 확인 가능
ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME lynx -dump localhost:9100/metricslyns란 웹 내용을 콘솔로 찍어주는 것
얼럿매니저
# configmap 생성
apiVersion: v1
kind: Namespace
metadata:
name: kwatch
---
apiVersion: v1
kind: ConfigMap
metadata:
name: kwatch
namespace: kwatch
data:
config.yaml: |
alert:
slack:
webhook: '슬랙 웹훅 url'
#title:
#text:
pvcMonitor:
enabled: true
interval: 5
threshold: 70
# 잘못된 이미지 정보의 파드 배포
kubectl apply -f https://raw.githubusercontent.com/junghoon2/kube-books/main/ch05/nginx-error-pod.yml
kubectl get events -w
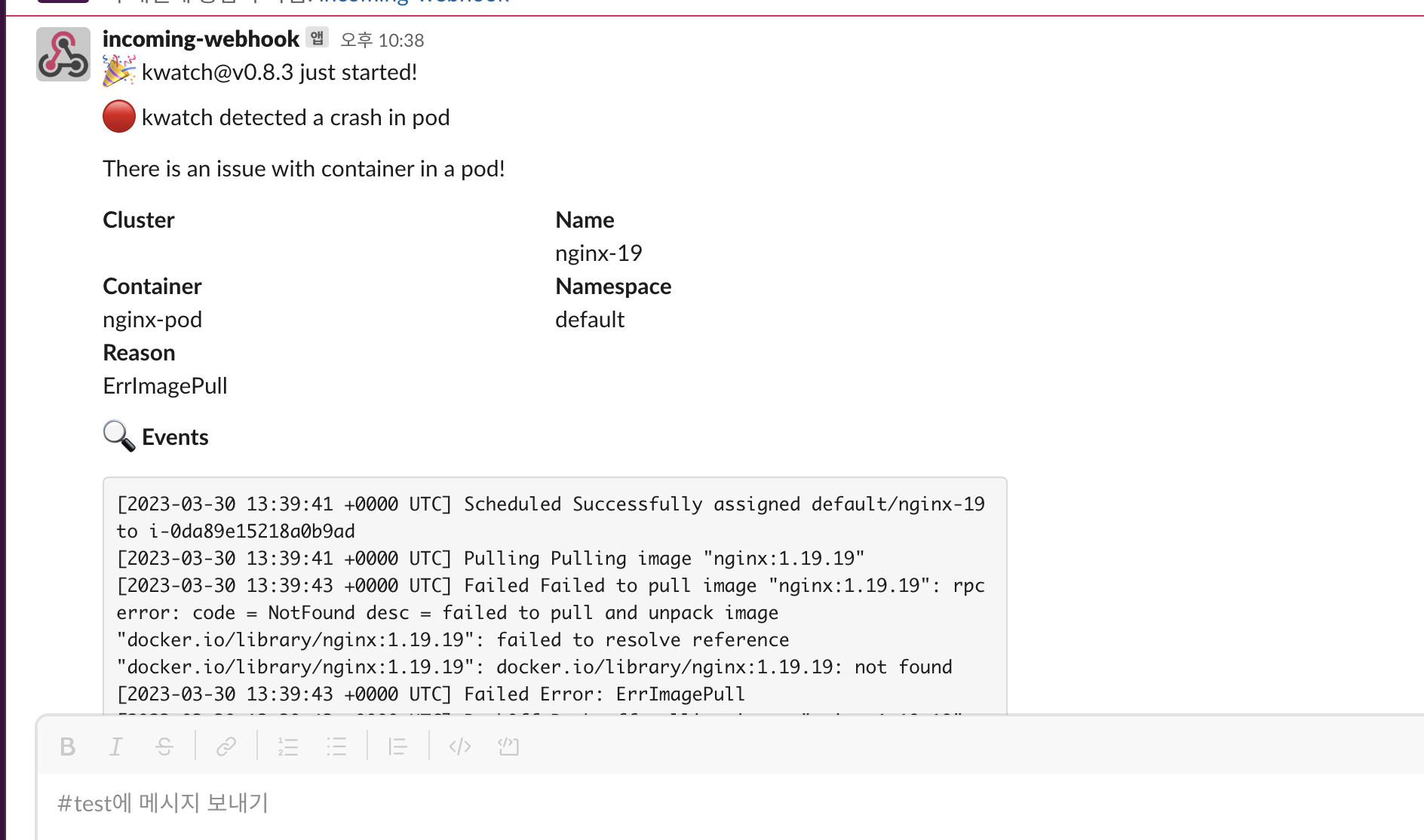
이미지를 배포하자마자 발생된 경고
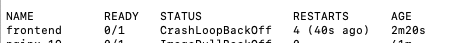
파드에 livenessProbe 설정 후 알림 발생 모니터링
-------
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: app
image: nginx
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 5
periodSeconds: 5

마치며
모니터링이 실무에서 가장 중요한 서비스가 아닐까 생각이 든다.
모니터링 서비스를 내 손으로 구축해본 좋은 경험이였다.
