Overview
Spark란 대규모 데이터 처리를 위한 통합 분석 엔진 (인메모리 병렬 분산처리 엔진)
Hadoop 생태계에서 디스크 IO로 계산하던 Hadoop Map/Reduce 에서 낮은 처리율 단점을 극복하고자 인 메모리 기반인 Spark가 탄생하였음.
자주 쓰는 용어
- Executor: 일을 처리하는 워커
- Core: CPU 코어
- Memory: 메모리
- Partition: RDD, Dataset을 구성하고 있는 최소 단위 객체, Spark에서는 하나의 최소 연산이 Task인데 하나의 Task에서 하나의 Partition을 처리한다. (하나의 Task는 하나의 Core가 처리한다)
- core = partition = task
Spark Partition 종류
- Input Partition
- 파일을 읽을 때 생성하는 partition, 기본값은 128MB
- Output Partition
- 파일을 저장할 때 생성하는 partition, 기본값은 128MB
- Shuffle Partition
- 기본값 200
스파크 구조
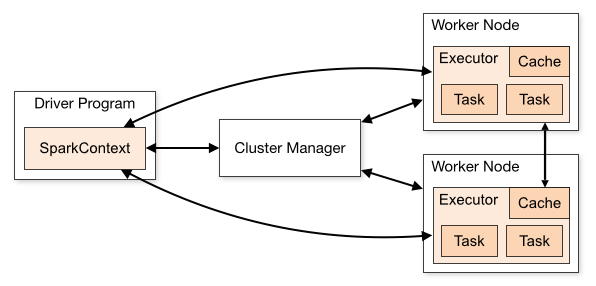
스파크 어플리케이션은 마스터-슬레이브 구조로 실행된다.
자원 관리는 스파크 컨텍스트가 진행하고 실제 일은 Executor가 한다.
SparkContext: Job을 submit하고 job을 task로 변환하고 Worker 간의 Task 실행을 조정하는 프로세스
Executor: 계산 작업을 수행하고 결과를 Driver에게 반환
- 여기서 자원관리는 요청 받은 리소스를 적절하게 node들의 Executor로 분배한다.
- 사용자는 executor와 core, memory를 설정할 수 있음
spark-submit --master yarn --deploy-mode cluster --executor-cores 4 --num-executors 12 --executor-memory 8g --driver-memory 1g balance_realtime.jar <여기서부터 소스코드 인자값>Spark Memory Management
Basic Concept
Executor는 워커 노드에서 실행되는 JVM 프로세스.
JVM 메모리 관리는 두가지로 나뉘는데 (On Heap Store, Off Heap Store)
- On-Heap (In-memory): Object가 JVM 힙에 할당되고 GC에 의해 바인딩
- Off-Heap (External-memory): Object는 직렬화에 의해 JVM 외부의 메모리에 할당되고 Application에 의해 관리되며 GC에 바인딩 되지 않음
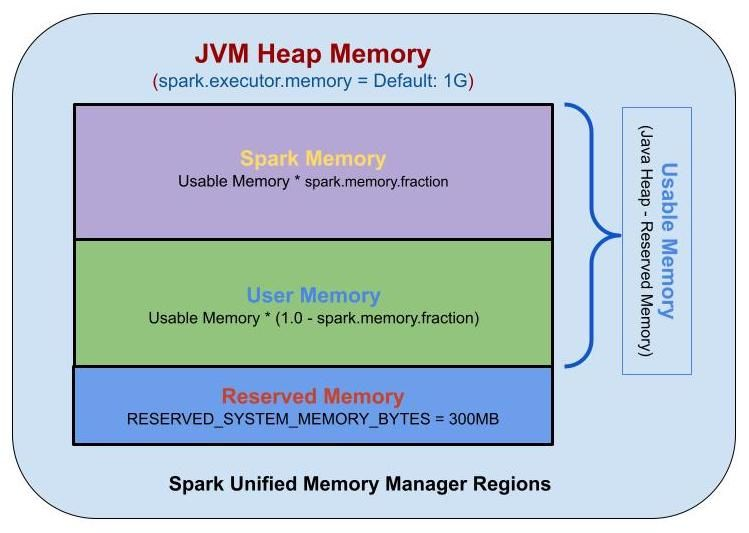
Unified Memory Manager (통합 메모리 관리)
spark 1.6 이상부터 정적 메모리 관리자를 대체하여 Dynamic 메모리를 할당한다.
Storage 및 Execution이 공유하는 통합 메모리 컨테이너로 메모리를 할당
Execution 메모리를 사용하지 않는 경우, Storage 메모리는 사용 가능한 모든 메모리를 휙득 할 수 있음
Reserved 메모리
시스템 용으로 예약된 메모리, Spark 내부 개체를 저장하는데 사용됨
spark-shell --executor-memory 300mUser Memory
사용자 정의 데이터 구조, Spark 내부 메타데이터, UDF, RDD 작업에 필요한 데이터를 저장하는데 사용되는 메모리
Spark Memory (Unified Memory)
Spark에서 관리하는 메모리 풀.
Spark 동작 (Lazy evaluation)
 ![]
![]
RDD (Resilient Distributed Dataset)
분산 데이터 셋, 스파크가 사용하는 핵심 데이터 모델로, 분산 저장된 요소들의 집합을 의미하며 병렬 처리 가능하며 장애가 발생 할 경우 스스로 복구 될 수 있는 내성을 가지고 있다.
Transformation(변환)
기존 RDD에서 새로운 RDD를 생성하는 function
distinct(), filter(), map(), sortBy(), join(), union()- Narrow Transformation 과 Wide Transformation 차이가 있는데 쉽게 말해 Narrow는 간단한 작업이라 데이터를 worker node와 교환하지 않는 것이고
Wide Transformation은 worker node와 데이터 교환(데이터 셔플링)이 이루어 지는 작업이다. - 데이터 셔플링은 비용이 많이 든다. (예시로 DB의 Sort Merge Join 처럼 동작)
Action(동작)
작업 수행
count(), collect(), max(), min()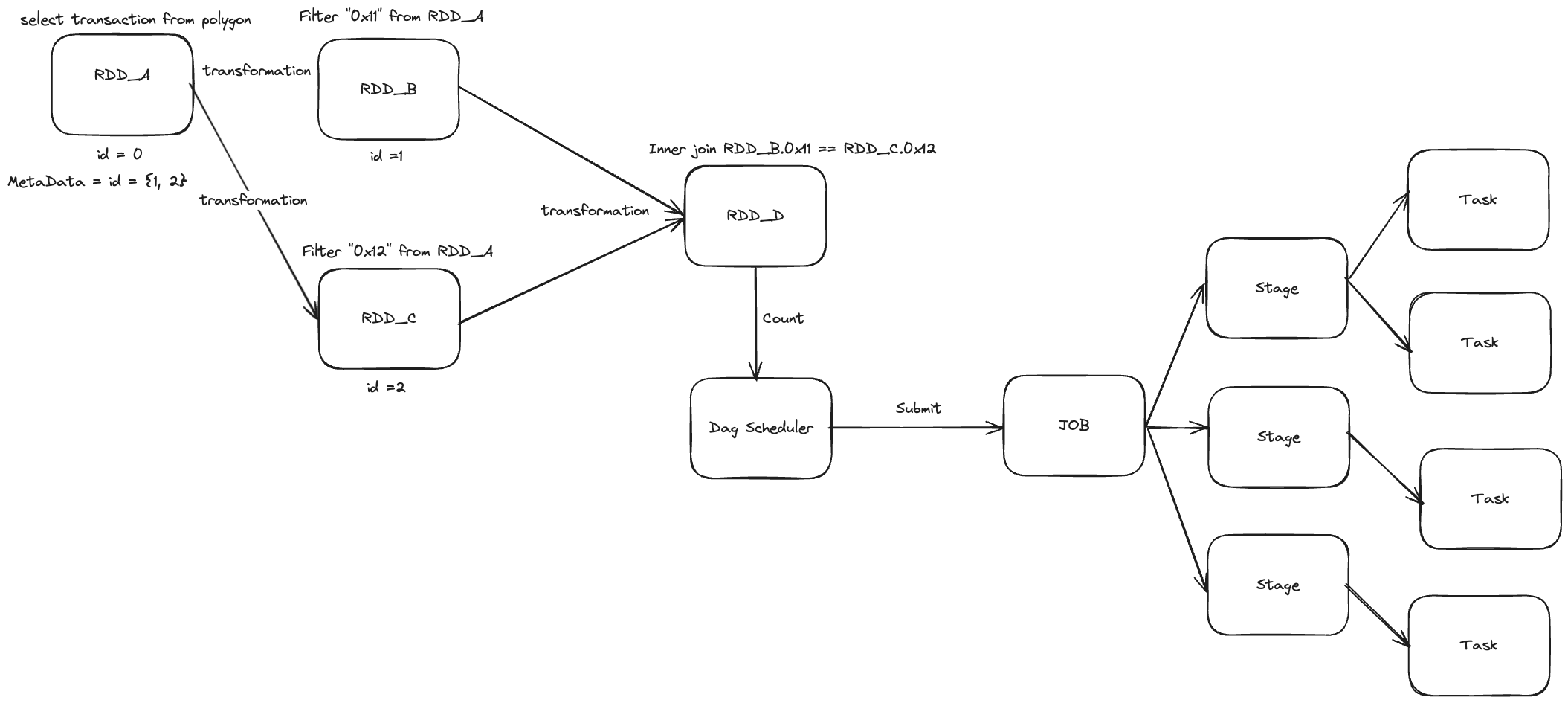
어떻게 보면 java ForkJoinPool과 형태가 유사하다. (분할 정복)
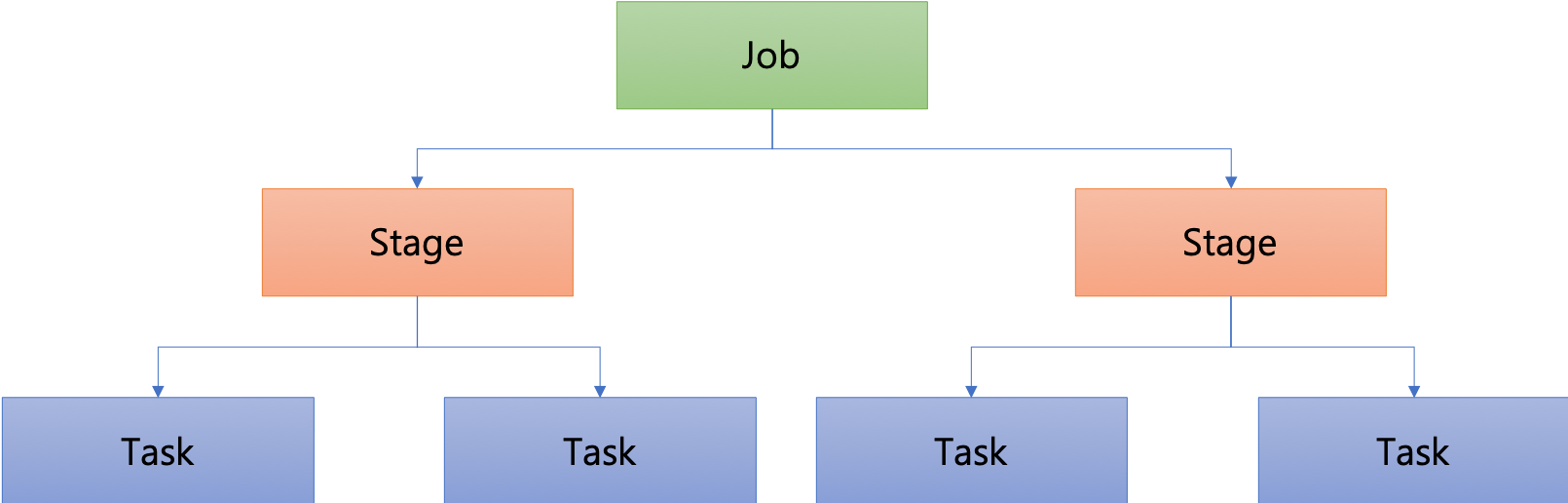
Spark 작업은 RDD를 활용하여 Transformation을 거쳐 가공한 후, 실제 작업은 Action을 통해 수행된다. RDD는 스스로 복구할 수 있는 내성을 갖추고 있으며, 이는 상위 유형에 대한 메타 데이터를 보유함으로써 가능하다.
Action이 이루어지기 전까지의 작업은 논리적 query plan만 만들고 실제로 메모리에 올리지 않는다.
Action이 이루어지면 DAG를 통해 작업들이 수행된다. 아래 예시를 보자
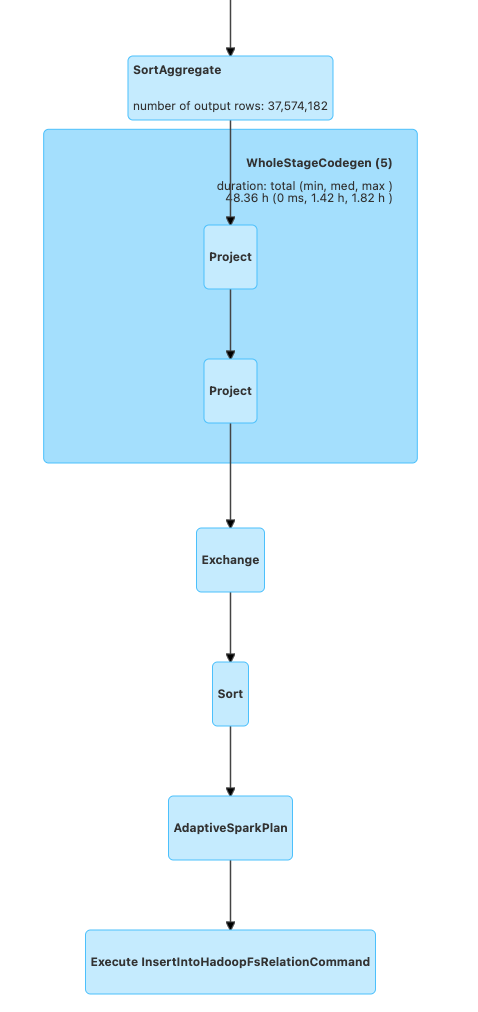
DAG의 일부분을 캡처
위는 DAG의 일부분을 캡처 하였다. 아래 실제로 Query plan을 보면 어떤 작업을 하는지 유추 할 수 있다.

하둡에 데이터를 저장하는 예시
밑에서 부터 보면 데이터 2개를 filter(transformation) 을 수행하고 Join을 수행한다.
이때 사용된 조인 전략은 SortMergeJoin이다. Spark도 결국 Query Engine이므로 어느 Join 전략과 비슷하다
여기서 데이터를 정렬 하는 과정이 필요하므로 Shuffle이 발생하고 이는 worker node에 있는 데이터를 섞는Wide Transformation 이다. 이 과정이 완료 된 후 hadoop에 저장 된다
Spark Fault Tolerance: Self Recovery
RDD에 대한 내결함성을 충족하기 위해 여러 노드간에 전체 데이터가 복제된다.
Spark Deep Dive
Spark Memory Management
스파크에서는 메모리 관리가 중요하다. Spark는 JVM으로 구동되므로 메모리 관리를 알아보기 위해 JVM에 대한 이해도가 필요하다.

IBM 문서 참고 자료
일반적으로 어플리케이션에서 java의 heap size는 RAM의 25%(그림에서 보이는 Java heap)
Java application을 실행하였을 때, 메모리 공간은 2가지 영역으로 나뉜다
- Native Heap (Off heap) JVM이 이 영역의 일부를 사용
- Java Heap (On heap)
Spark 에서 사용하는 메모리가 Java heap을 넘어가게 되면 Heap Space Error가 나올 것 이다.
일반적인 어플리케이션에서 heap space error가 나오기 쉽지 않다. 대용량 데이터를 처리하는 서버의 경우를 예시로 들자면 List 안에 많은 데이터가 담긴 경우 Long은 8바이트이므로 구동 머신(RAM)에 따라 max값은 계산할 수 있다. 또 다른 예시로 Garbage Collection이 제대로 동작하지 않는 경우 On-heap 메모리 부족이 발생하고 Full GC → Stop the world 가 발생할 것이다.
Spark도 마찬가지로 Garbage Collector가 작동한다. (Java 8 이므로 parallel GC)

RDD_A를 필터링하여 RDD_B를 생성하면 RDD_B는 더 이상 참조되지 않게 되어, RDD_A에 대한 Minor GC가 발생할 것이다. 그림에서 Task들의 GC time이 2초인데, Task의 증가는 Gc time의 속도 저하 요인 중 하나일 수 있다.
IBM 문서에 따르면, int, Interger등 객체 선언에 따른 메모리 오버헤드가 존재한다. Spark 개발진들은 이 오버헤드를 없애기 위해 Binary Data로 직접 연산할 수 있는 메모리 관리자 Unified Memory Manager를 도입했다.
Data Shuffle
Partition은 RDD를 구성하고 있는 최소 단위 객체이다. 각 Partition은 서로 다른 노드에서 분산 처리된다
위에서 말했듯 파티션의 개념은 core = partition = task 와 같다.
partition의 수를 늘리는 것은 Task 당 필요한 메모리를 줄이고 병렬화의 정도를 늘리는 것.
이처럼 작업을 제출하면 설정된 partition은 149개이고, Task는 총 149개가 예약된다. Executor는 128개가 담당하므로 Java 8 기준 Thread pool에서 관리하는 Fork Join Pool의 Task는 128개로 수행된다.
아래 예시를 통해 Partition 수를 통해 메모리 관리하는 법을 알 수 있다.
spark-submit --master yarn --deploy-mode cluster --executor-cores 4 --num-executors 64 --executor-memory 8g --driver-memory 1g ~~.jar <여기서부터 소스코드 인자값>Executor의 총 개수가 256개이며, 각 Executor는 8GB의 메모리를 할당받는다. 따라서 전체 시스템에서 총 예약된 메모리는 64 * 8 = 512GB가 된다.
만약 처리해야 할 데이터는 10억개로 추정되고, Partition의 수는 80개로 설정되었을 때 각 Partition은 처리할 데이터의 부분집합을 나타낸다.
실제로 필요한 Executor의 개수는 80개뿐이지만, 전체 시스템에서 예약된 메모리는 512GB로 크다. 이는 효율적인 자원 활용을 위해 고려되어야 하는 중요한 측면이다.
또한, 데이터를 정렬하는 Shuffle 연산이 수행될 경우 메모리 사용이 증가하게 된다. 이로 인해 1TB의 데이터에 대한 연산을 모두 메모리에서 처리하지 못하면 Disk에 Spill이 발생하게 되고, 이러한 상황이 계속되면 Heap Space Error가 발생할 수 있다.
따라서 core와 memory 예약하는 기능도 중요하지만 작업의 partition 숫자를 조절하는 것도 중요하다.
이에 대한 대안으로, Partition의 수를 임의로 3000개로 조정하면 각 Executor 당 필요한 데이터 양이 감소하게 됩다. 이를 통해 메모리 사용을 효율적으로 조절할 수 있다. 그림에서 나타난 것처럼 Partition 수를 늘리면 Executor 당 필요한 데이터 양이 감소하고, 따라서 더 효율적인 메모리 사용이 가능해진다.
