코드란?
코드란, 있는 그대로 사용하기 불편한 정보를 약속된 형태로 압축한 간단한 기호 체계이다.
코드의 본질은 값의 분류, 범주화에 있다. 속성을 코드화하면 다음과 같은 효과가 있다.
- 속성을 코드화하면 그룹핑이 편리하여 집계가 용이해진다.
- 하나의 값을 표현하는 방법이 다양하므로, 집계할 때 문제가 생길 여지가 있다.
- 따라서 집계가 필요한 속성 데이터를 기호화하여 표준 코드로 관리하게 된다.
- 프로그램 소스 코드 수준에서 로직 분기를 위해 사용할 수 있다.
- 압축된 형태이므로 가독성을 높이고, 저장 공간의 효율성을 높일 수 있다.
- 서비스 화면 수준에서 데이터를 유형화하여 조회하는 데 사용할 수 있다.
코드인 것과 코드가 아닌 것
기호화한 것이라고 해서 모두 코드라고 볼 수는 없다. 코드인 것과 아닌 것을 판별하기 위해서는 식별자와 코드를 구분해야 한다.
식별자인 것
식별자는 엔티티의 개별 인스턴스를 유일하게 식별하는 방법을 제공하는 장치다. 기본 키(PK)가 이에 해당한다. 예를 들어 상품코드, 부서코드와 같은 것은 코드가 아닌 식별자 속성에 해당한다.
식별자 속성은 실제 업무 행위에 의해 값이 생성되는 경우가 많다.
코드인 것
코드는 오로지 릴레이션의 튜플들에 대한 특정 기준 중심의 분류로 사용되는 것을 의미한다. 집합의 개체가 생성되고 쌓이는 기준이 아니라 분류를 위한 도구인 것이다. 예를 들어 저축성, 보장성, 연금성, 이라는 범주로 분류하기 위한 보험상품유형 속성은 코드에 해당한다.
코드 속성은 전사 공통코드로 보통은 메타데이터 관리시스템에서 관리된다. 또한, 업무 행위에 의해 생성되기보다는 IT조직 내에서 자료사전으로 관리되는 것이 일반적이다.
이러한 맥락에서 식별자와 코드를 구분하기 위해, 엔티티나 테이블 속성의 명칭을 정할 때 식별자에는 ID나 번호를, 코드에는 코드를 붙이는 명명법을 따르면 명확히 구분할 수 있다.
공통코드의 관리
코드북(code book)은 공통코드를 관리하기 위한 일반적인 구조이다. 공통코드값 엔티티가 개별코드의 구체적인 값을 관리하는 형태이다.
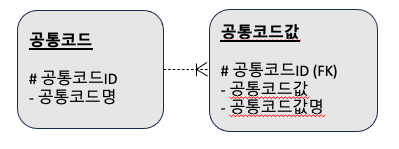
학교 데이터를 관리하는 예시를 들자면, 다음과 같은 공통코드 테이블이 나올 수 있다.
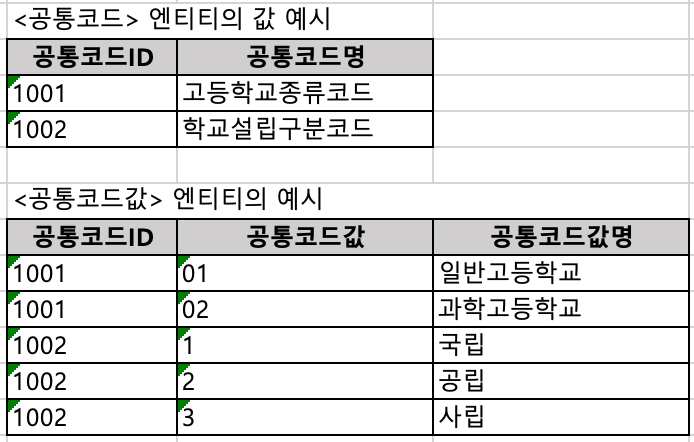
단, 위와 같이 무의미한 일련번호 인조 식별자를 쓸 경우 테이블의 코드 속성과 공통코드 테이블의 공통코드ID와의 연결고리가 없다는 약점이 존재한다.
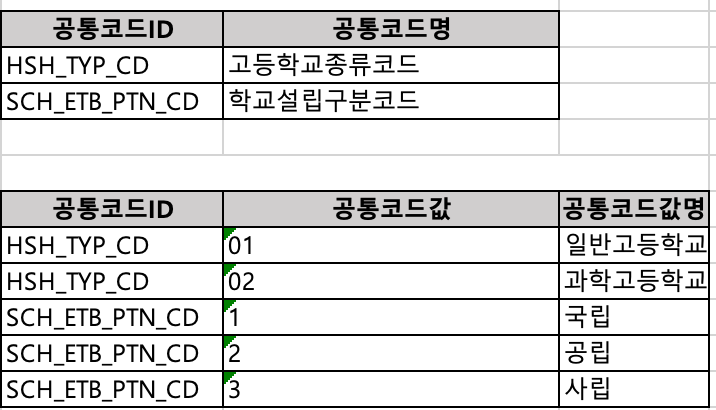
이를 보완하기 위해, 공통코드ID를 고유하게 관리되는 코드 속성의 컬럼명을 사용하면 코드 속성과 공통코드와를 논리적으로 연결할 수 있다.
코드 간 계층구조, 부분집합의 관리
계층구조 관리
전체집합과 부분집합을 계층구조로 관리하기 위해, 공통코드 엔티티에 재귀(recursive)관계를 추가할 수 있다.
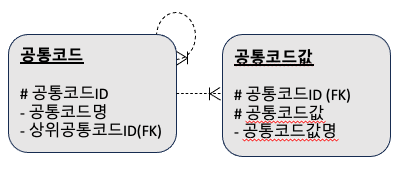

위 예시에서는 공통코드ID가 1001인 통합된 전체 집합이 존재하며, 이를 기반으로 필요한 코드의 부분집합은 별도로 등록한다. 이때 코드값 전체집합을 가리키는 상위공통코드ID를 관계로 지정하게 된다.
위 방법에도 몇 가지 문제가 있다.
- 관리하기가 쉽지 않다.
- 부분집합의 합이 전체집합이어야 하는데, 전체집합과 부분집합의 일관성이 깨질 위험이 높다.
- 최상위 코드 집합의 소유권이 애매할 수 있다.
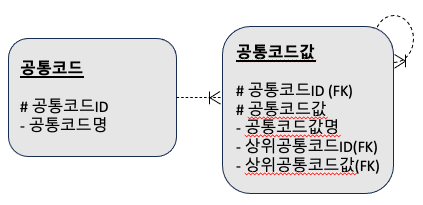
부분집합 관리
계층구조 관리 모델을 응용하여 코드의 부분집합을 관리할 수 있다. 코드값 수준에서 코드값 간의 계층 관계를 관리할 수 있는 모델이다.

결론: 코드 정의가 모델링에 주는 이점
적절한 추상화 수준으로 분류하고 정의한 코드를 기반으로 개발하면, 그렇지 않은 경우보다 생산성을 높일 수 있다. 따라서 코드 정의를 단순히 표준화 수준으로 취급하기보다는, 모델링의 중요한 과정으로 이해해야 한다.
