정규화(Normalization)
- 관계형 데이터베이스의 설계에서 중복을 최소화하게 데이터를 구조화하는 프로세스를 의미한다.
- 정규화는 제1 정규화로부터 제6 정규화까지 총 6가지 단계가 있으나, 제4~6 정규화는 학술적 측면에서 많이 다뤄지며 산업적 관점에서는 제1~3 정규화까지만 지켜져도 이상적이다.
- 제1~3 정규화는 선택적으로 적용할 수 있는 것이 아니라 모두 만족되어야 하며, 1 - 2 - 3 순서대로 이루어져야 한다.
제1 정규화
Atomic columns
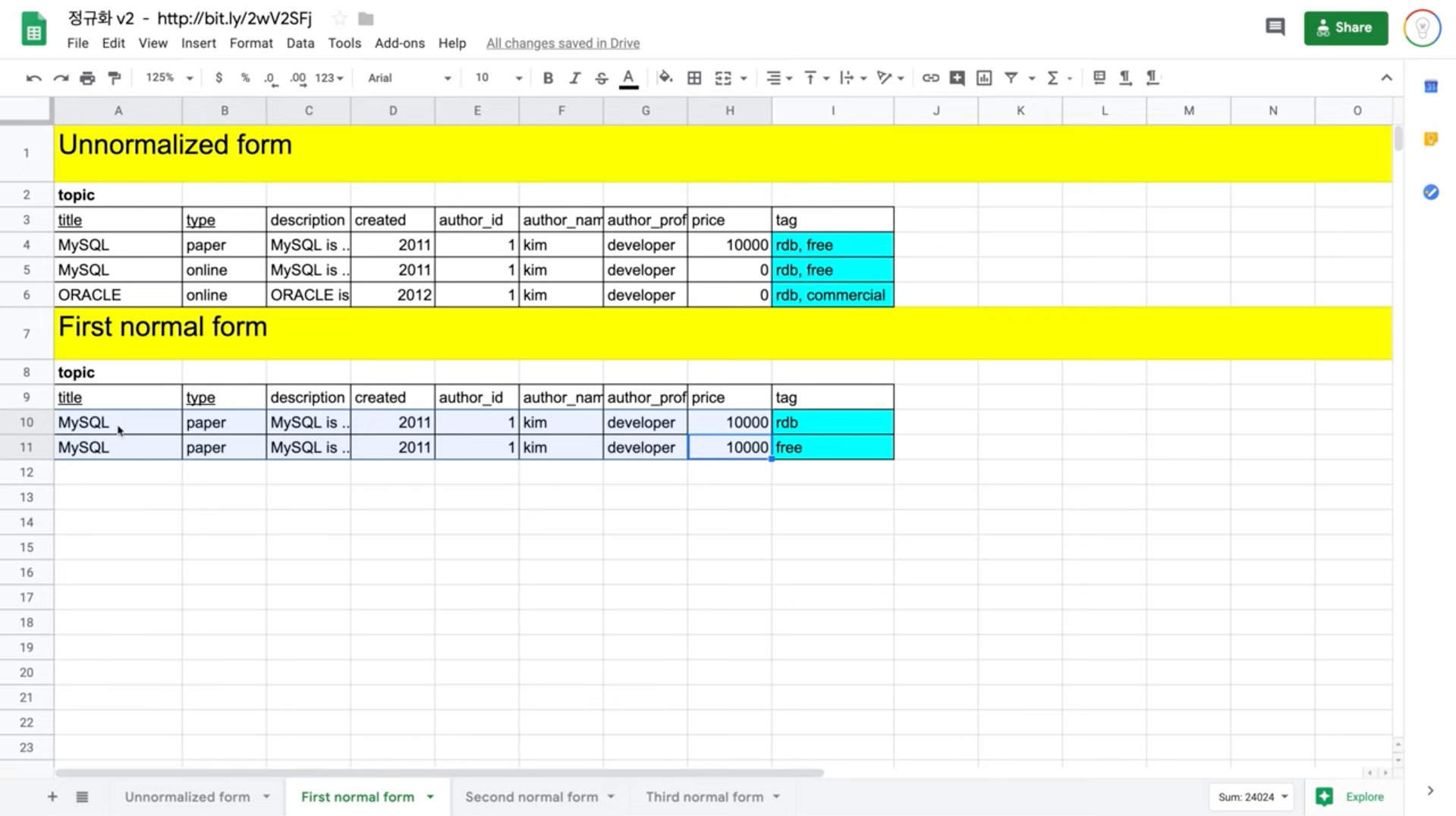
- 각 행, 컬럼의 값들이 하나하나가 원자적이어야 한다. 즉, 모든 행, 컬럼에는 값이 하나만 있어야 한다는 뜻이다.
- 하나의 행, 컬럼에 해당하는 데이터는 더 이상 쪼갤 수 없는 단위여야 한다.
 ⬆️ 생활코딩 강의영상 중 발췌
⬆️ 생활코딩 강의영상 중 발췌
- 위 예시의 Unnormalized form의 tag 컬럼에는 컴마(',')를 기준으로 2개 이상의 값들이 저장되고 있다. 컴마를 포함한 것이 하나의 값이라면 괜찮지만, 그렇지 않다면 아직 데이터를 쪼갤 수 있는 여지가 남아있다.
- 한편, 제1 정규화를 적용하면 First normal form과 같이 만들 수 있다. 다만, 아직 tag 필드를 제외한 나머지 필드에 중복이 발생한다는 점에서 부족한 해결책이다.
 ⬆️ 생활코딩 강의영상 중 발췌
⬆️ 생활코딩 강의영상 중 발췌
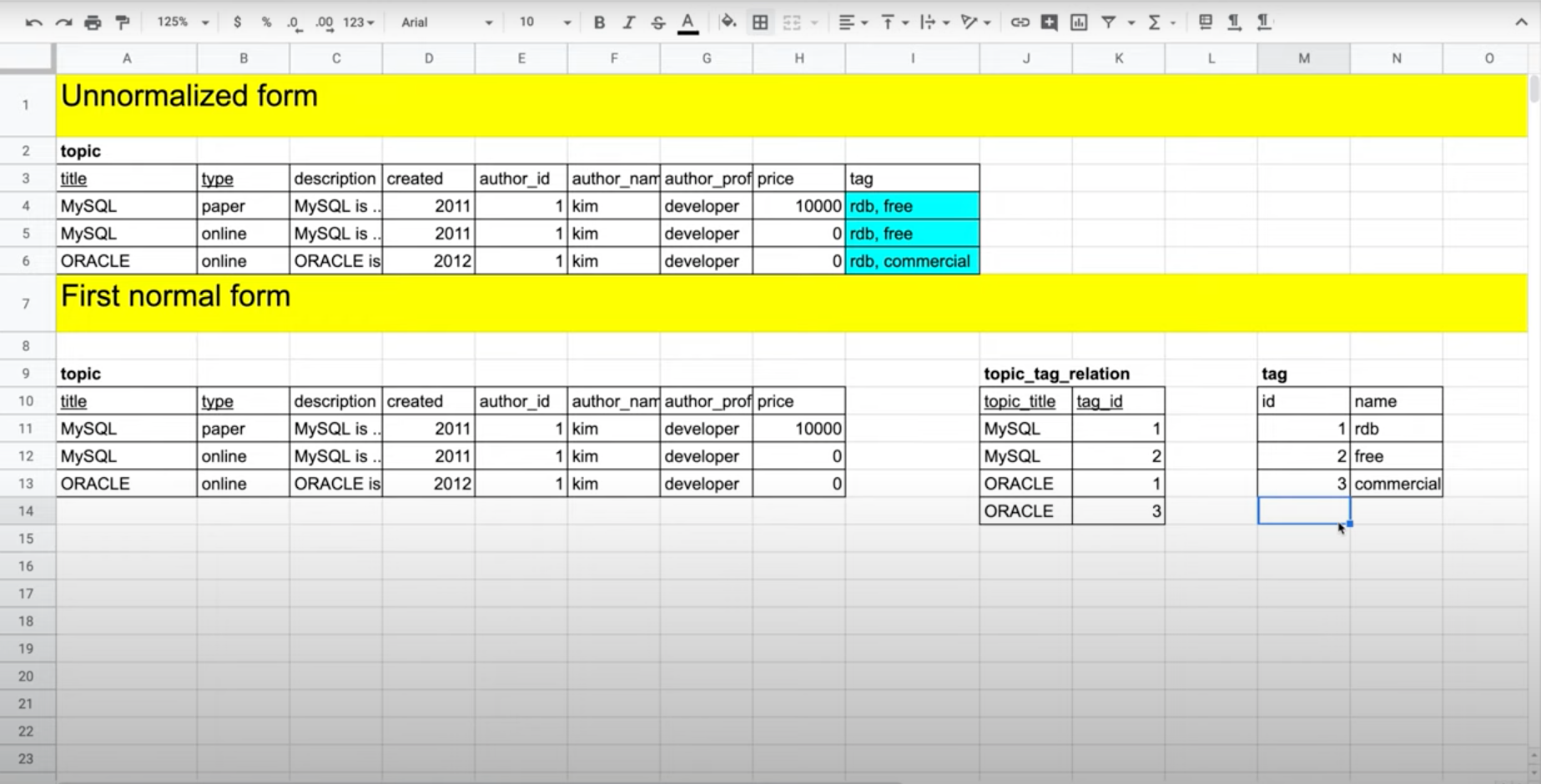
- 위와 같이 tag 테이블을 따로 생성 후, 이를 topic_tag_relation라는 mapping table을 이용해 topic 테이블과 연결하면 중복 없이 제1 정규화가 완성된다.
제2 정규화
No partial dependencies
- 테이블 상에 부분 종속성이 없어야 한다.
- (1) 한 테이블에서 컬럼이 PK가 아닌 다른 컬럼에 종속되는 경우가 없어야 한다.
- (2) PK를 구성하는 속성들 중 일부분에만 종속되는 경우가 있다.
- 부분 종속성이 나타나는 컬럼들은 별도의 테이블로 떼어내야 한다.
 ⬆️ 생활코딩 강의영상 중 발췌
⬆️ 생활코딩 강의영상 중 발췌
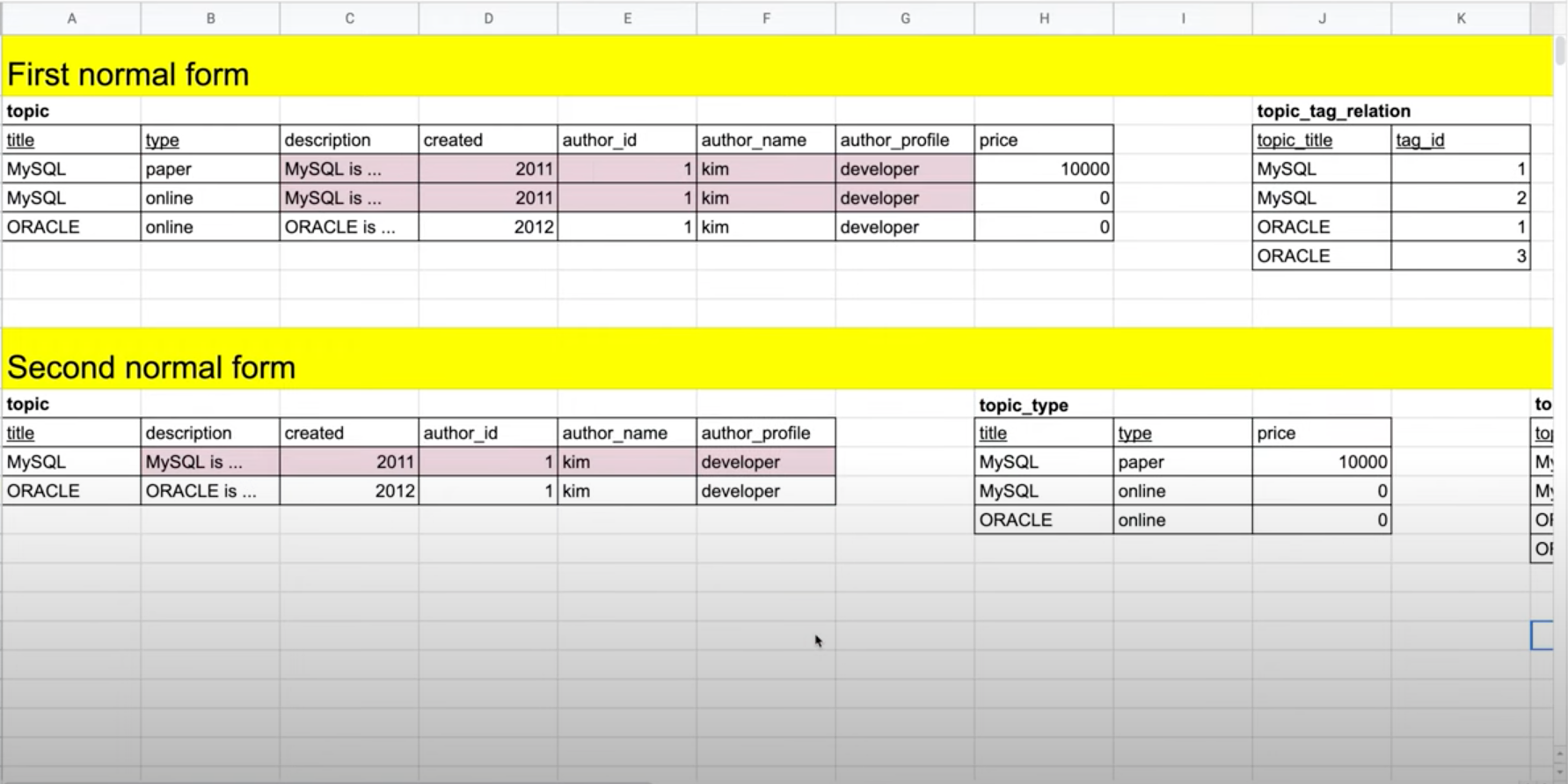
- 위 예시의 First normal form에서는 다음과 같은 부분 종속성이 나타난다.
- (1) description, created, author_id, author_name, author_profile은 title에 종속된다.
- (2) price는 title, type에 종속된다.
- First normal form에 제2 정규화를 적용하면 Second normal form과 같은 형태가 나온다. topic에는 title에 의존하는 컬럼들만 남긴 후, title과 type에 좌우되는 price는 topic_type이라는 별도의 테이블로 나눈다.
제3 정규화
No transitive dependencies
- 테이블 상에 이행적 종속성이 없어야 한다.
- 즉,
X -> Y이고Y -> Z일 때X -> Z를 만족한다면 이를 이행적 종속성이 있다고 한다.
 ⬆️ 생활코딩 강의영상 중 발췌
⬆️ 생활코딩 강의영상 중 발췌
-
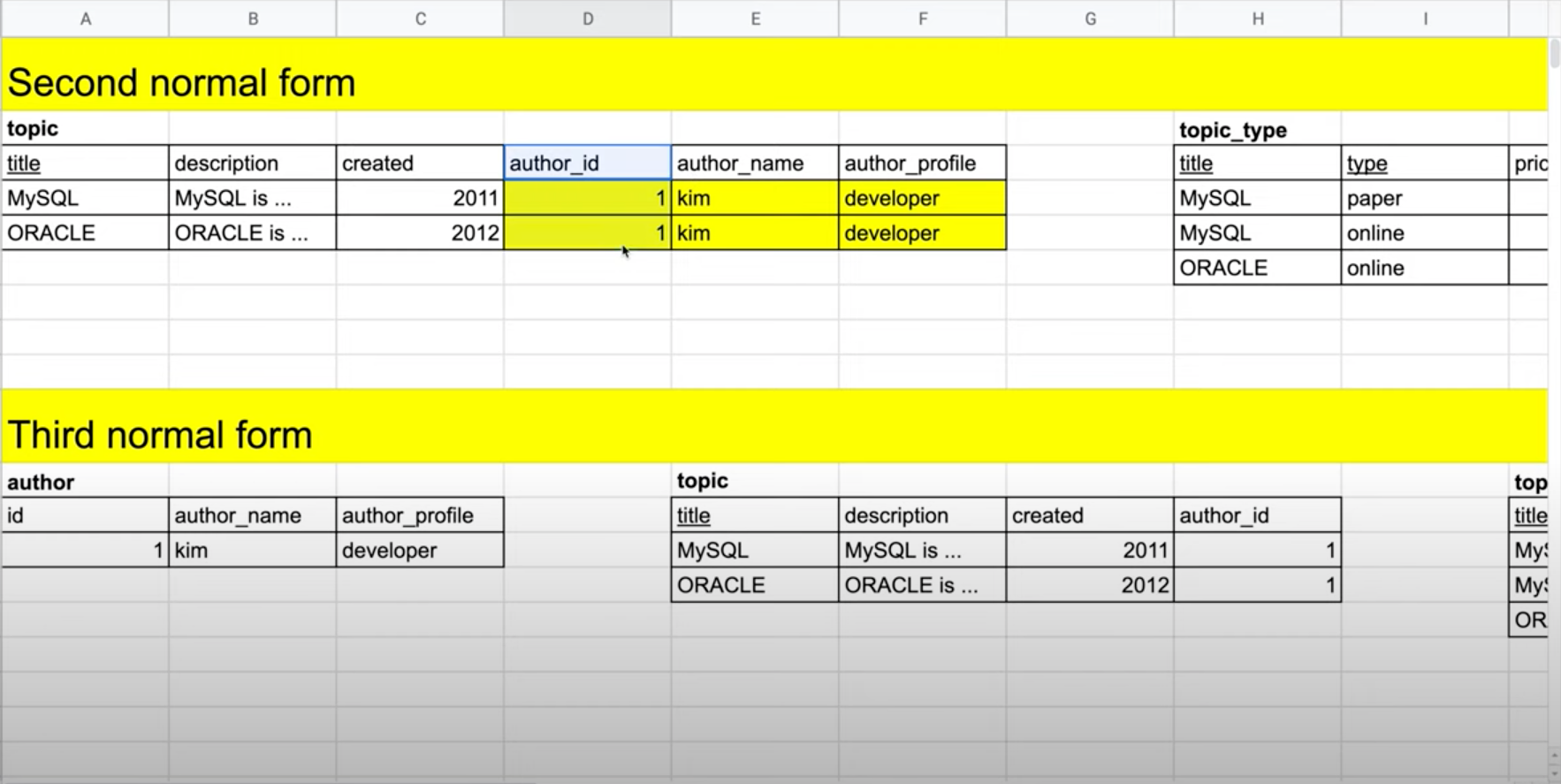
위 예시의 Second normal form의 topic 테이블에서는 다음과 같은 이행적 종속성이 나타난다.
- (1) author_id는 title에 의존한다.
- (2) author_name, author_profile은 author_id에 의존한다. 이로 인해 topic 테이블의 행에서 author_id, author_name, auth_profile에 해당하는 부분에 중복이 발생한다.
- 만약, author_id 없이 author_name, author_profile만 있다면 이행적 종속성을 발견하기 어려울 수도 있다. 하지만 이 컬럼들은 author라는 접두사를 가지고 있는데, 이러한 경우 별도의 엔티티로 독립시켜야 할 가능성이 높다. 이와 같이 성격이 같은 컬럼들에 중복이 나타나고 있다면, 암시적으로 식별자를 갖고 있다고 간주할 수 있다. 따라서 이러한 경우를 잘 점검하고 분리해야 한다.
-
Second normal form에 제3 정규화를 적용하면 Third normal form과 같은 형태가 나온다. topic 테이블에서 author_id에 종속되는 컬럼들은 별도의 테이블에 배치하고, author_id만 FK를 걸어 저장한다. 이때, author_id가 모두 값이 '1'이어서 중복이 되는 것처럼 보이지만, FK는 중복으로 간주하지 않는다.
* 이 내용은 생활코딩의 "관계형 데이터 모델링" 수업을 듣고 개인적인 공부를 위해 정리한 것입니다. 문제가 있다면, 지적해 주시면 감사하겠습니다!

부족한 경험을 채우기 위한 나만의 기록 공간