데이터베이스 규모 확장
수직적 확장(scale up)
기존 서버에 더 많은 혹은 고성능의 자원(CPU, RAM, 디스크 등)을 증설하는 방법이다. 고성능 데이터베이스 서버를 두면 단 한 대만으로도 많은 양의 데이터를 보관하고 처리할 수 있지만, 결국 몇 가지 약점이 있다.
- CPU, RAM은 무한 증설할 수 없다. 따라서 사용자가 계속 늘어나면, 한 대 서버로는 결국 감당하기 어렵다.
- SPOF(Single Point Of Failure)로 인한 위험성이 크다.
- 고성능 서버로 갈수록 비용이 많이 든다.
수평적 확장(sharding)
샤딩은 대규모 데이터베이스를 shard라 불리는 작은 단위로 분할하는 기술이다. 주로, 더 많은 서버를 추가(증설)함으로써 성능을 향상시킨다. 모든 샤드는 같은 스키마를 쓰지만, 샤드에 보관되는 데이터 사이에는 중복이 없다.
샤딩 전략을 구현할 때 가장 중요한 고려사항은 샤딩 키(sharding key = partition key)를 어떻게 정하느냐 하는 것이다. 즉 데이터가 어떻게 분산될지 정하는 컬럼을 무엇으로 하느냐가 중요하다는 것이다. 샤딩 키를 정할 때는 데이터를 고르게 분할할 수 있도록 하는 것이 가장 중요하다.
예를 들어, user_id를 샤딩 키로 지정했다면, user_id % 4의 값(0~3)에 따라 데이터가 보관되는 샤드를 정할 수 있다.
0이면 0번 샤드, 1이면 1번 샤드에 저장하는 식이다.샤딩은 데이터 샤딩 키를 통해 올바른 데이터베이스에 질의를 보내어 데이터 조회나 변경을 효율적으로 할 수 있다는 장점이 있지만, 시스템이 복잡해지고 새로운 문제가 생겨나기도 한다.
- 데이터 재 샤딩(resharding)
데이터가 너무 많아져서 하나의 샤드로는 더 이상 감당하기 어렵거나, 샤드 간 데이터 분포가 균등하지 못하여 어떤 샤드에 할당된 공간 소모가 다른 샤드에 비해 빨리 진행되는 상황을 샤드 소진 현상(shard exhaustion)이라고 부른다. 이떄는 데이터를 더 작은 단위로 한번 더 샤딩할 필요가 있다. 이를 해결하기 위해서는 샤드 키를 계산하는 함수를 변경하고 데이터를 재배치해야 한다.
- 유명인사(celebrity) 문제(= Hotspot Key)
특정 샤드에 질의가 집중되어 서버에 과부하가 걸리는 문제를 의미한다.
- 조인과 비정규화(join and denormalization)
한 번 데이터베이스를 쪼개고 나면, 여러 샤드에 걸친 데이터를 조인하기 힘들다. 이를 위해 데이터베이스를 비정규화하여 하나의 테이블에서 질의가 수행될 수 있도록 하는 방법도 있다.
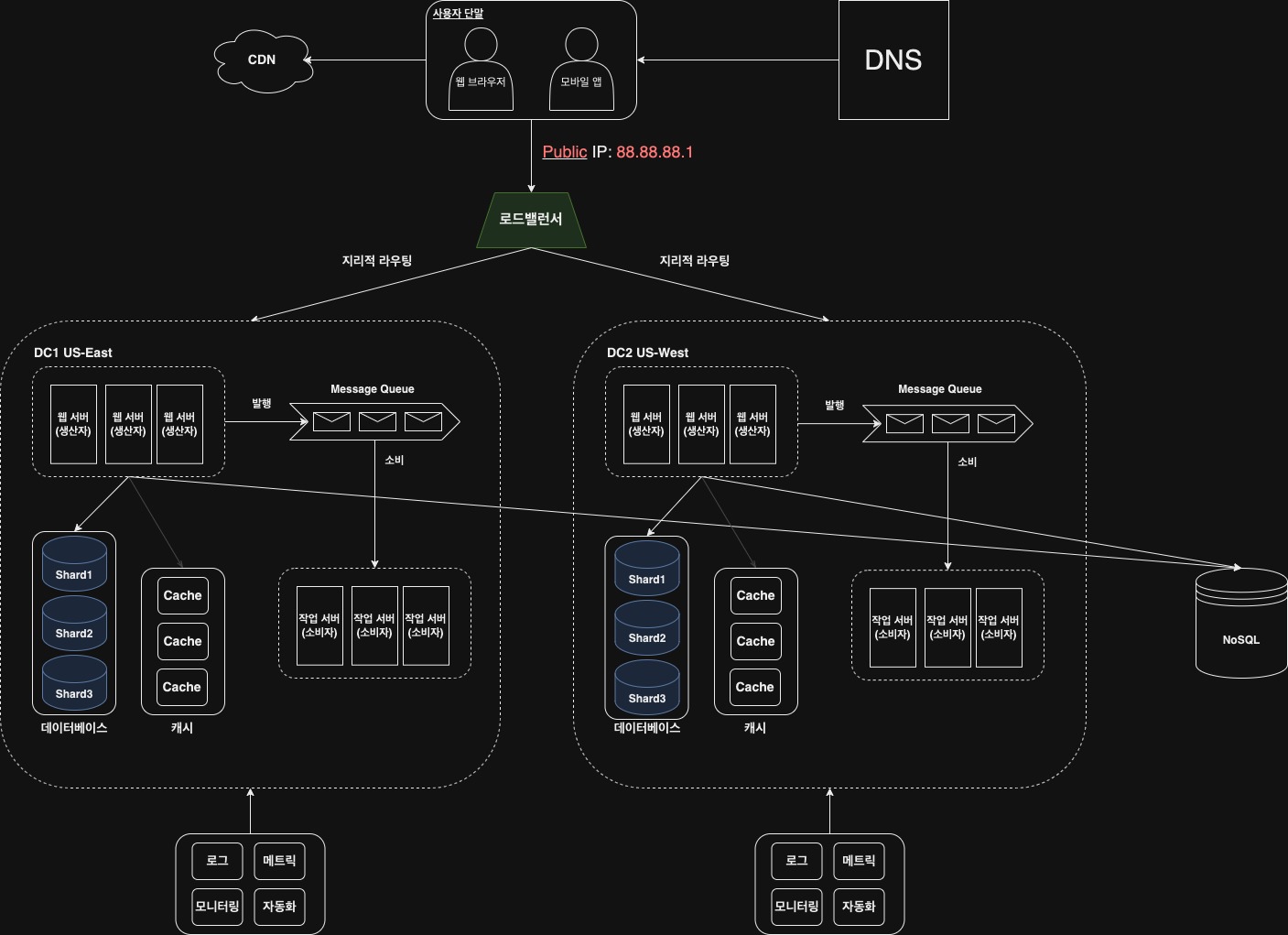
데이터베이스 샤딩을 적용한 아키텍처는 다음과 같다.

부족한 경험을 채우기 위한 나만의 기록 공간
좋은 글 감사합니다.