데이터 표준화란
데이터 표준화는 규칙을 정한 후 그것이 일관되게 적용되도록 이해관계자들을 강제하는 과정이다. 데이터 표준화 지침이나 규칙을 정한 후 오직 데이터적 관점에서 해당 규칙을 준수하도록 하는 과정이다. '데이터적 관점' 이라 하면 여러 가지 관점이 있을 수 있지만, '메타데이터 관리'로 칭하는 표준화는 구조 관점의 표준화에 집중한다. 반면, 데이터값에 대한 표준화는 데이터 코드화의 범주에 속한다.
속성 모델링은 데이터 표준화의 좋은 예시이다. 속성 모델링에서는 다음과 같은 사항을 결정한다.
- 관리하려는 값의 단위를 얼마나 세분화할 것인가?
- 값의 성격에 맞는 속성명은 무엇인가?
- 데이터 유형은 어떤 것으로 정의할까?
- 제약사항 설정(해당 속성에 들어올 수 없는 값)
요컨대, 속성 모델링이란 엔티티의 특징이나 본질적인 성질 등을 명세하기 위한 작업을 하는 것이라 볼 수 있다.
메타데이터란 데이터에 대한 데이터를 의미한다. 데이터를 담기 위한 그릇에 해당하는, '구조'에 해당한다. 엑셀 표의 첫 행은 그 아래 기입될 데이터에 대한 명세 역할을 담당하며 '데이터를 설명하기 위한 데이터'를 의미한다는 점에서 메타데이터이다. 일반적으로 데이터 표준화는 데이터 구조(모델) 안의 속성 수준에서 수행된다.
데이터 표준화의 목적
데이터 표준화의 핵심은 통일시켜 일관되게 사용하도록 하는 것이며, 데이터 표준화의 주된 대상은 데이터를 담는 최소 단위인 속성이다.
표준으로 제정된 것만을 사용하는 것, 즉 같은 의미를 다른 형태로 사용하지 않고, 다른 의미를 같은 형태로 쓰지 않는 것이다. 즉, 데이터 모델의 속성명으로 동음이의어와 이음동의어가 사용되는 경우를 최소화하는 것이다.
속성의 이음동의어, 동음이의어 양산 최소화하기
속성의 이음동의어, 동음이의어가 만들어지는 패턴이 몇 가지 있다. 이런 용어들은 표준의 품질을 떨어뜨리기 때문에 최대한 바로잡아야 한다.
패턴 1
이음동의어란 발음은 다르지만 뜻이 같은 말을 의미한다. 대표적으로는 다음과 같은 경우이다.
이메일주소, 전자우편주소, email주소, e-mail주소, 메일주소이음동의어가 이렇게나 양산되는 이유는, 단일 형태로 통일하지 않은 채 속성을 부르기 때문이다. 단어 표준화가 되지 않으면 용어 수준의 표준화는 의미가 없어진다. '이메일'을 표준 단어로 정했다면 '전자우편', 'email', '메일' 등은 모두 금칙어가 된다. 따라서 반드시 단일 형태의 표준 용어로 통일해야 한다.
패턴 2
또 다른 이음동의어 패턴은, 용어를 구성하는 단어의 조합 순서만 다른 형태이다. 복합어가 바로 이런 경우이다.
- 입금총금액, 총입금금액
- 최종등록일시, 등록최종일시
- 최초입금금액, 입금최초금액단어 순서만 다른 용어들은 동일한 정보 항목을 의미하는 이음동의어일 확률이 굉장히 높다. 따라서, 표준 용어 외의 형태를 금칙어로 등록하는 노력이 필요하다.
일반적으로 표준 용어는 표준 단어들의 조합으로 만들고, 그 영문명은 표준 단어의 영문 약어를 구분자와 결합해서 만든다. 용어의 영문명은 해당 용어를 속성으로 사용하는 컬럼의 이름이 된다. 예를 들면 표준 단어인 주간, 방문자, 수 의 영문 약어가 WKL, VST, NUM 이고 구분자가 '_'라면 주간 방문자 수의 영문명은 WKL_VST_NUM이 된다.
위와 같이 복합어를 표준 단어로 등록할 경우 이음 동의어가 양산될 개연성이 높다. 따라서 복합어는 아래의 세 가지 경우를 제외하고는 가급적 허용해서는 안 된다.
- 복합어가 개별 단어의 의미 합친 이상의 새로운 의미를 갖는 경우
- ex. '콜센터'는 고객을 위한 행정 시설이라는 고유 의미가 존재하므로, 별도 단어로 등록할 수 있다.
- ex. '고정금리'는 새로운 뜻이 없다. 따라서 단어로 등록될 수 없다.
- 복합어가 관용적으로 하나의 단어처럼 쓰이는 경우
- ex. 주민등록번호, 금융감독원, 한국데이터베이스진흥원 등
- 용어의 영문명이 지나치게 길어지는 경우
패턴 3
업무 의미와 데이터의 성격을 충실히 반영하지 못하는 경우가 있다. 애매한 속성명이 표준으로 사용되지 않도록 관리와 통제가 필요하다.
Bad VS Good
- 거래처 VS 거래처구분코드
- 추정소득 VS 추정연간총소득액
- 미래예상가치 VS 미래예상가치금액데이터 표준화가 안 되어있다면...
성능 저하
데이터 표준화의 목적은 단순히 용어의 통일과 일관성만이 아니다. 표준 미준수는 성능 저하와 시스템 장애의 직접적인 원인이 되기도 한다. 예를 들어, 오라클에서는 VARCHAR2(5)와 CHAR(5)가 다른 결과를 가져올 수 있다. CHAR는 고정 길이 타입으로, 정의된 길이 미만의 값이 들어오면 나머지는 공백으로 채운다. 즉, VARCHAR2(5)의 1234는 실제로 1234이지만, CHAR(5)의 1234는 실제로 1234()이 된다. 따라서 이 둘은 일치하지 않는, 서로 다른 값이 되어 JOIN이 불가해진다.
또 다른 예로는 numeric string과 INT의 차이이다. DBMS의 옵티마이저는 비교 대상 컬럼의 데이터 타입이 다르면 이를 일치시키기 위해 형변환을 수행한다. 값이 같아도 형변환이 되면 인덱스를 사용할 수 없기 때문에 Full table scan이 발생하여 SQL 수행 속도를 현저히 저하시킨다.
이와 같이, 정보 항목의 이름 뿐 아니라 정보 항목을 표현할 값의 형태도 반드시 표준화해야 한다.
데이터 통합의 어려움
만약 데이터 표준화가 제대로 되어있지 않아 데이터가 일관성 없이 산재되어 있다면, 통합에 상당히 애를 먹을 것이다.
고품질 표준 데이터 관리를 위한 각자의 역할
개발자
- 데이터 표준화의 중요성 인식
- 데이터 표준화 지침 숙지
- 메타데이터 신규 신청 시 이음동의어 존재 여부 확인
- 구체적이며 명확한 형태로 메타데이터 정의하기
표준화 담당자, DAT
- 금칙어, 유사어 관리
- 등록 요청된 메타데이터의 적정성 분석
- 이음동의어 확인
- 오류 패턴에 대한 개발자 가이드를 통한 조직 학습 유도
메타데이터 관리 시스템
- 동음이의어, 이음동의어가 자료 사전에 등록되는 것을 필터링할 수 있는 다양한 로직 적용
- 이음동의어를 구조적으로 분석할 수 있는 기능 제공
데이터 표준화는 한 번 물이 흐려지기 시작하면 회복이 불가능해진다. 따라서 모든 이해 관계자와 담당자는 표준을 사수하기 위해 사명감을 갖고 노력해야 한다.
또한, 방대한 표준을 사람이 일일이 확인, 통제하는 것은 불가능한 일이다. 따라서 메타데이터 시스템은 자료 관리를 위한 시스템에 그치지 말고, 표준 준수를 위한 다양한 정보를 제공하여 데이터 거버넌스의 중심이 되는 통제형 시스템이 되어야 한다.
표준 용어 구체화 수준은 어디까지 해야 할까
이름이 길다고 해서 무조건 명확하고 구체적인 정의가 되는 것은 아니다. 가독성은 오히려 떨어질 수도 있다. 따라서, 표준 용어 이름 짓기는 가능하면 구체적이되 간결하게 표현하는 것이 바람직하다. 상충되는 것처럼 느껴질지 모르는 이 일을 어떻게 할 수 있을까?
- 핵심 단어를 선별해서 조합하기
- 정보 항목의 특성과 업무 중요도에 따라 구체화 수준을 차등 관리하기
2번의 구체화 수준 차등 관리는 다음과 같은 가이드를 참고해 볼 수 있다.
(1) 구체화 수준의 정의와 예
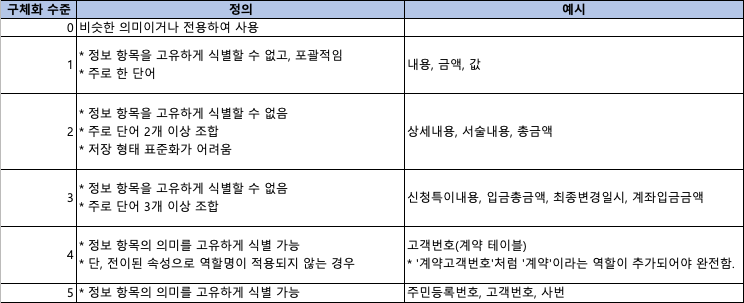
(2) 속성 유형별 적절한 구체화 수준

업무 식별자 속성은 정보 항목의 의미를 고유하게 식별할 수 있도록, 구체화 수준을 높여서 명명해야 한다. 반면 물리적인 관리와 통제 목적의 속성(ex. '최종변경일시' 등의 시스템 속성)은 명명 구체화에서 조금 너그러울 수 있다.
