
시각지능 내용은 개인적인 공부를 위해서 정리하는 용도이다. 개인적으로 인터넷을 통해서 공부한 내용을 포함하여 POSTECH의 오태현 교수님의 시각지능 강의를 기반으로 정리할 것이다.
Introduction to machine intelligence and perceptron
Visual intelligence가 무엇인지 알기 위해서 machine intelligence와 machine perception이 무엇인지부터 알 필요가 있다. 가장 먼저 왜 visual intelligence가 중요하며 인공지능과 어떠한 연관성이 있는지 알아보고자 한다.
Artificial Intelligence
인공지능이 시작한 시기는 1950년도에 perceptron이라는 모델로부터 시작되었다. 인공지능은 오래된 역사를 가졌고, 정의를 살펴보면 machine의 지능을 다루는 컴퓨터 엔지니어링 분야를 이야기한다고 볼 수 있다. 그렇다면 여기서 machine intelligence는 사람같은 인지 능력을 구현하는 추론하고 계획을 세우고 학습을 하는 등의 능력을 가지는 것을 이야기한다. 즉, 사람과 같은 인지 능력을 만드는 것을 machine intelligence라고 한다. 여기서 지능은 상대적인 것이기에, 인공지능이 명확한 기준이라기 보다는 사람에 따른 상대적인 기준을 가지게 되는 것이다.
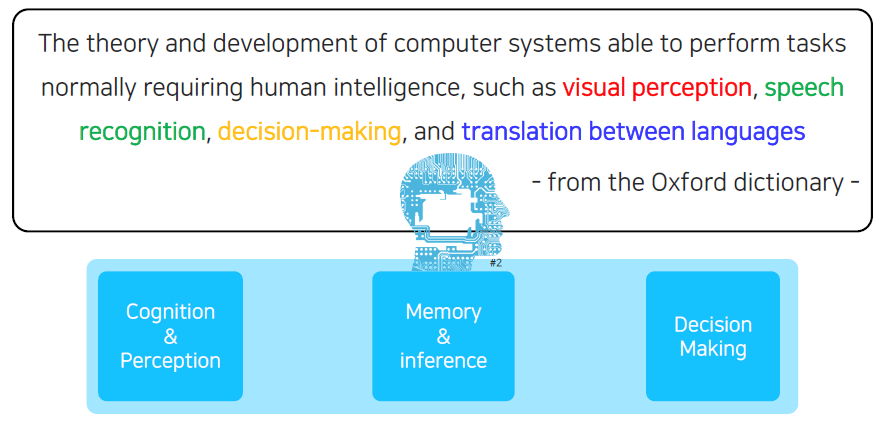 하지만 이는 정의가 모호할 수 있다. 그래서 Oxford dictionary에서는 컴퓨터 시스템을 개발하는 방법과 이론으로 사람의 지능이 필요한 task를 해결할 수 있다고 했으며, 여기에는 visual perceptron, speech recognition, decision making 등이 있다고 했다. 이 관점으로 보았을 때 지능을 cognition and perceptron, memory and inference, decision making과 같은 3가지 관점으로 나눌 수 있다.
하지만 이는 정의가 모호할 수 있다. 그래서 Oxford dictionary에서는 컴퓨터 시스템을 개발하는 방법과 이론으로 사람의 지능이 필요한 task를 해결할 수 있다고 했으며, 여기에는 visual perceptron, speech recognition, decision making 등이 있다고 했다. 이 관점으로 보았을 때 지능을 cognition and perceptron, memory and inference, decision making과 같은 3가지 관점으로 나눌 수 있다.
Perception
Machine intelligence를 만드는데 있어서 perception은 중요하며, input과 output data라고 이야기할 수 있다. 그리고 perception은 사람 기준으로 보았을 때 사람이 성장하면서 세상을 이해하고 배우게 되는데, 이때 세상과 상호작용 하는데 있어서 필요한 능력이 된다. 여기서 사람은 하나가 아닌 여러가지 정보들을 모아서 활용하게 된다.
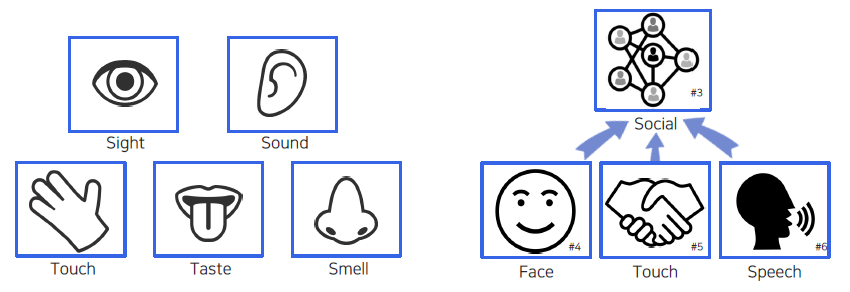 Perception을 보면 사람의 오감을 기본적으로 생각할 수 있으며, 요즘에는 이 외에도 social perceptron이라 하여 세상과 상호작용하면서 느끼는 것들도 생각해볼 수 있다.
Perception을 보면 사람의 오감을 기본적으로 생각할 수 있으며, 요즘에는 이 외에도 social perceptron이라 하여 세상과 상호작용하면서 느끼는 것들도 생각해볼 수 있다.
Visual perception (computer vision)
그렇다면 perception 중에서 visual perception이 중요한 이유에 대해서 생각해봐야 한다. Cambrian explosion이 발생하고 지구 상에 갑자기 개체 수가 엄청나게 증가하게 되었다. 이러한 사건이 발생하는 가설 중 하나로 시각의 발전을 이야기할 수 있다. 먹고 먹히는 관계 사이에서 시각이 발전함에 따라 회피 능력과 먹이를 찾는 능력 등이 발달하게 되었다는 가설이다. 그렇기 때문에 visual perceptron이 정말 중요하게 되었고, 흔히 백문이 불여일견이라고 한번 보는 것이 더 확실한 상황이 많을 것이다. 그리고 사람이 처리하는 정보 중에서 과반수가 시각 정보를 이용하는 것이다. 안전, 건상, 보안 등 모든 것이 시각 능력과 연관되어 있다.
우리는 visual perception을 다루기 위해서 input data로 image나 video를 사용하게 될 것이다. Visual perception의 종류로는 color perception, motion perception, 3d perception 등이 있다. Visual intelligence를 다른 말로 이야기하면 computer vision이다. 이제부터는 본격적으로 이 용어들이 무엇인지 알아보고자 한다.
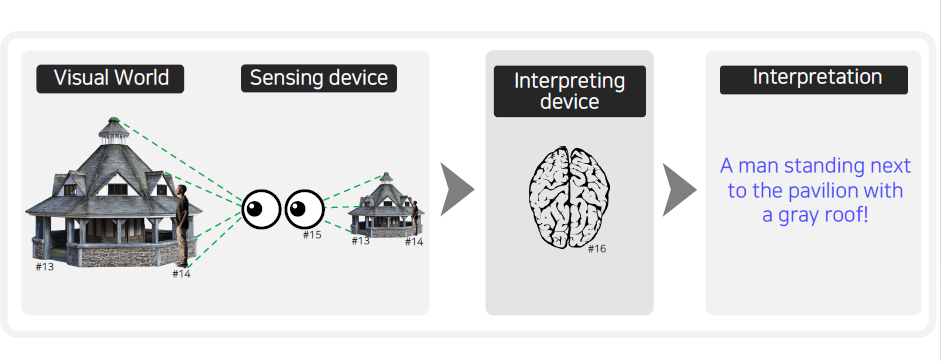 Computer vision에서는 input data가 visual data이다. 이러한 visual data는 우리가 살아가는 세상에서 얻어지게 된다. 이 세상을 사람의 눈으로 센싱을 하게 되면 이 정보가 뇌로 전달되게 된다. 뇌에서는 이 신호를 해석하게 된다. 사람이 세상을 보고 이해하는 이러한 과정이 computer vision에서 하는 것과 동일하다.
Computer vision에서는 input data가 visual data이다. 이러한 visual data는 우리가 살아가는 세상에서 얻어지게 된다. 이 세상을 사람의 눈으로 센싱을 하게 되면 이 정보가 뇌로 전달되게 된다. 뇌에서는 이 신호를 해석하게 된다. 사람이 세상을 보고 이해하는 이러한 과정이 computer vision에서 하는 것과 동일하다.
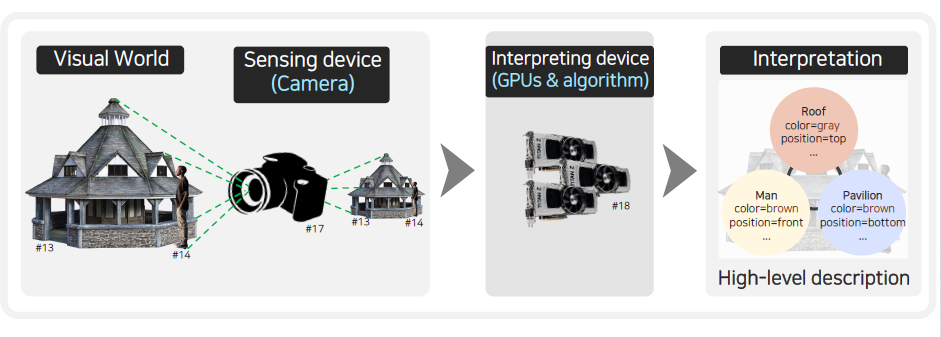 Computer vision에서 보면 사람의 눈이 카메라로 바뀌고, 사람의 뇌가 GPU나 우리가 구현한 알고리즘으로 바뀌게 된다. 이해는 컴퓨터가 이해하기 좋은 자료 구조를 활용해서 진행하게 된다. 우리는 이러한 전반적인 과정을 통해서 analysis를 하게 되고 만약 반대로 진행되게 된다면 synthesis를 하게되는 것이다. 여기서 analysis가 computer vision이라고 하면, high-level description으로부터 영상을 재구성하는 것을 또 다른 말로 computer graphics라고 한다.
Computer vision에서 보면 사람의 눈이 카메라로 바뀌고, 사람의 뇌가 GPU나 우리가 구현한 알고리즘으로 바뀌게 된다. 이해는 컴퓨터가 이해하기 좋은 자료 구조를 활용해서 진행하게 된다. 우리는 이러한 전반적인 과정을 통해서 analysis를 하게 되고 만약 반대로 진행되게 된다면 synthesis를 하게되는 것이다. 여기서 analysis가 computer vision이라고 하면, high-level description으로부터 영상을 재구성하는 것을 또 다른 말로 computer graphics라고 한다.
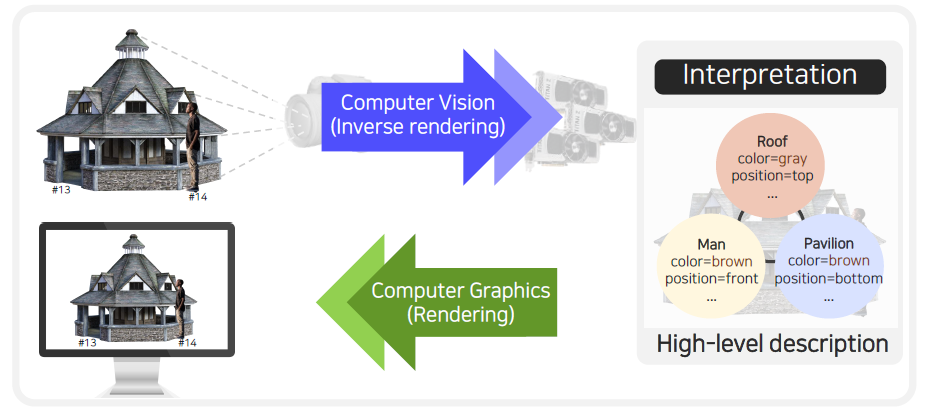 그래서 computer vision과 graphics는 서로 반대되는 개념이 된다.
그래서 computer vision과 graphics는 서로 반대되는 개념이 된다.
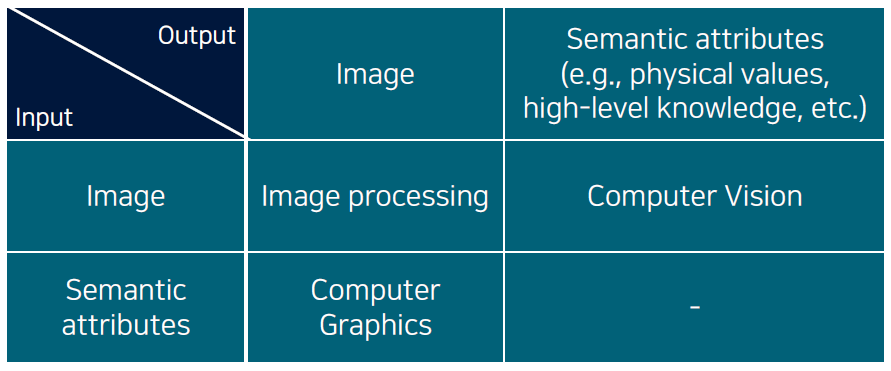 Computer vision과 graphics, 그리고 image processing이 대표적으로 visual data를 다루는 분야들이다. 이 셋의 차이는 input과 output이 무엇인지에 따라 서로 달라지게 된다. 최근 computer vision이라고 하면 visual data에 적용가능한 machine learning을 학습하게 된다. Data를 학습하여 특정 task에 사용하게 된다. 그렇기 때문에 computer vision을 machine learning의 하나의 큰 부분 집합으로 생각할 수 있다.
Computer vision과 graphics, 그리고 image processing이 대표적으로 visual data를 다루는 분야들이다. 이 셋의 차이는 input과 output이 무엇인지에 따라 서로 달라지게 된다. 최근 computer vision이라고 하면 visual data에 적용가능한 machine learning을 학습하게 된다. Data를 학습하여 특정 task에 사용하게 된다. 그렇기 때문에 computer vision을 machine learning의 하나의 큰 부분 집합으로 생각할 수 있다.
추가적으로 computer vision을 한다는 것은 결국 사람의 시각 지각 능력을 따라하는 것인데, 사실 사람의 시각 지각 능력 자체가 너무 불안정하다. 그래서 사람을 따라하는 것과 사람을 능가하는 것이라는 2가지 과제가 존재하게 된다. 사람을 따라하는 것만으로 충분히 잘한다고 이야기할 수도 있다. 하지만 어떠한 기능에 있어서는 사람을 능가하는 것도 생각해볼 수 있다. 이러한 trade-off를 보고 어떠한 부분에 초점을 맞출지도 생각해봐야 한다.
 위 사진을 보면 뭔가 부자연스러움을 느낄 수가 있다. 사람들은 어렸을 때 부터 똑바로 된 눈만 보았을 것이다. 그래서 사람의 지각 능력은 기존에 많이 봐왔던 패턴에 편향되어 있게 된다. 우리는 이러한 부분을 machine perception을 만드는데 포함할지 말지를 고민해봐야 한다. 무조건 이러한 편견을 제외시키는 것이 옳은 것은 아니다. 때로는 이러한 편견을 포함시켜야 할 때도 있을 것이다.
위 사진을 보면 뭔가 부자연스러움을 느낄 수가 있다. 사람들은 어렸을 때 부터 똑바로 된 눈만 보았을 것이다. 그래서 사람의 지각 능력은 기존에 많이 봐왔던 패턴에 편향되어 있게 된다. 우리는 이러한 부분을 machine perception을 만드는데 포함할지 말지를 고민해봐야 한다. 무조건 이러한 편견을 제외시키는 것이 옳은 것은 아니다. 때로는 이러한 편견을 포함시켜야 할 때도 있을 것이다.
Visual centric multi-modal perception
Visual data가 그저 visual data, visual perception으로만 중요한 것이 아니라 우리가 세상을 살아가는데 있어서 굉장히 다양한 지각 능력을 동시에 활용하게 된다. 눈으로 보고 귀로 듣고, 맛을 보고, 손으로 만지는 등의 형태로 세상과 상호작용하면서 배우게 된다. 우리는 이러한 multi-modal perception을 사용하는데 있어서 시각 정보를 중심으로 사용하게 되는 경우가 많다. 그래서 우리는 visual centric한 perception을 만드는 것이 정말 중요하다고 이야기할 수 있다.
사람이 현재 상황을 센싱하는 방법 중에서 굉장히 많은 경우가 multi-modal이다. 현재 시각이나 청각 등 data는 많은 발전이 있었지만, multi-modal을 이용한 data의 발전은 많이 되지 않았다. Vision을 기반으로 다른 것을 이해하고 어떠한 차이가 있는지 비교하는 것이 과학에서 많이 사용되는 방법일 것이다.
Ways to build machine intelligence
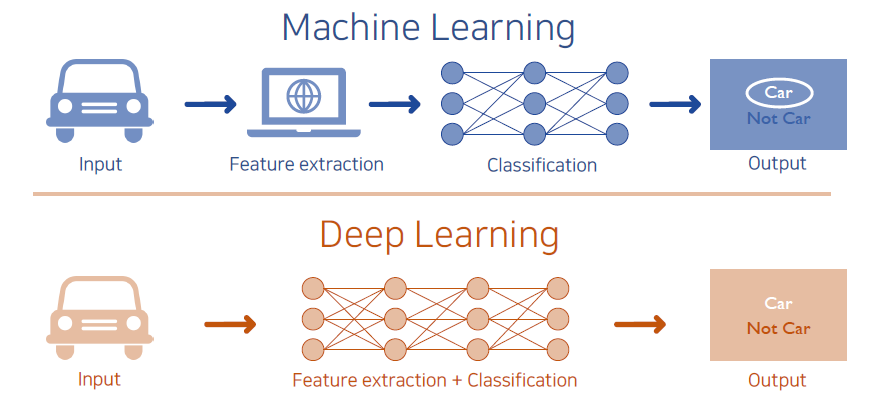 Machine intelligence, perception 능력을 어떻게 만드는지는 machine learning 기법을 이용하는지와 deep learning 기법을 이용하는지로 나눠질 것이다. 먼저 과거의 classic한 방법들을 보면 machine learning을 이용할지라도 input data를 machine learning이 사용하기 좋은 feature로 만들어줘야 한다. 이는 input data를 data scienctist들이 보고 사람이 잘 분석해서 어떠한 특징이 중요한지 판단하고 디자인하게 된다. 이렇게 디자인을 하고난 뒤에 간단한 알고리즘을 통해서 output을 출력하게 된다. 그렇기 때문에 feature extraction이 매우 중요한 과정이었다.
Machine intelligence, perception 능력을 어떻게 만드는지는 machine learning 기법을 이용하는지와 deep learning 기법을 이용하는지로 나눠질 것이다. 먼저 과거의 classic한 방법들을 보면 machine learning을 이용할지라도 input data를 machine learning이 사용하기 좋은 feature로 만들어줘야 한다. 이는 input data를 data scienctist들이 보고 사람이 잘 분석해서 어떠한 특징이 중요한지 판단하고 디자인하게 된다. 이렇게 디자인을 하고난 뒤에 간단한 알고리즘을 통해서 output을 출력하게 된다. 그렇기 때문에 feature extraction이 매우 중요한 과정이었다.
최근에는 deep learning을 통해서 input data를 넣어주기만 하면 neural network가 feature extraction 과정까지 진행해주게 된다. 과거하고 달라진 부분은 사람의 개입이 상대적으로 적어지게 되었다는 것이다. Deep learning 기법은 universal approximation으로 input과 output의 관계가 어떠할지라도 다 approximation할 수 있는 함수들의 class라고 생각할 수 있다.
What is an image?
Visual perception을 만들 때 input으로 사용되는 image가 무엇인지 알아보고자 한다. Image란 3D 세상에 있는 정보들을 2D 평면에 projection한 것이다. 2D 평면에는 projection을 해서 각 위치마다 3D 위치에 해당하는 밝기 정보들이 저장되게 된다.
요즘 스마트폰에는 좋은 성능의 카메라들이 달려있다. 그래서 예전에 비해 image를 취득하는 과정이 더 수월해졌다. 버튼 하나만 누르면 3D 세상이 디지털 정보로 저장되게 되는 것이다. 최근에는 디지털 카메라가 굉장히 트렌드이기 때문에 visual intelligence로 넘어가는데 더욱 data의 보급이 쉽게 이루어지게 되었다.
Travel of a photon - image formation
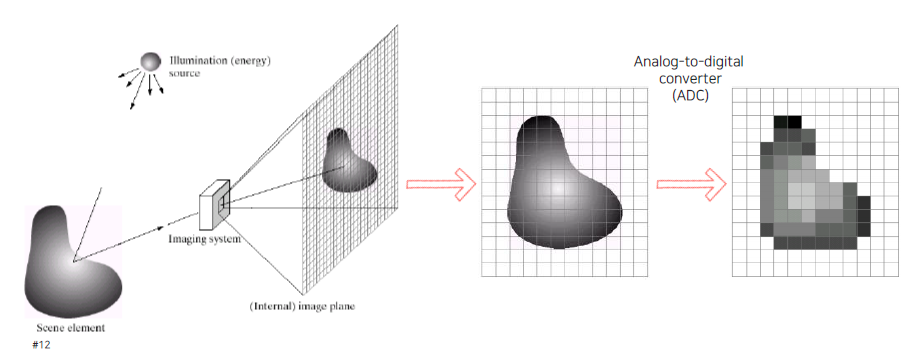 영상이 만들어지는 과정은 travel of a photon이라고 해서 광자 하나의 여행을 따져보면 쉽게 이해할 수 있을 것이다. 태양이나 조명으로부터 광자가 튀어나오게 되면, 이 광자가 물체에 부딪히게 된다. 일부 광자는 물체에 흡수하게 되고 일부는 튀어나오게 된다. 그래서 이렇게 튕겨나온 광자들이 카메라와 같은 imaging system에 부딪히게 된다. 그러면 광자들이 결국 image plane에 맺히게 되고, 평면을 통해서 어디서 광자가 왔는지 확인할 수 있다. 그리고 얼마나 많은 광자가 충돌했는지에 따라서 밝기를 결정하게 된다. 빛이 많이 부딪히는 곳에서는 높은 값이 측정되게 될 것이다. 그리고 이는 ADC를 통해서 아날로그 신호가 디지털 신호로 바뀌게 된다.
영상이 만들어지는 과정은 travel of a photon이라고 해서 광자 하나의 여행을 따져보면 쉽게 이해할 수 있을 것이다. 태양이나 조명으로부터 광자가 튀어나오게 되면, 이 광자가 물체에 부딪히게 된다. 일부 광자는 물체에 흡수하게 되고 일부는 튀어나오게 된다. 그래서 이렇게 튕겨나온 광자들이 카메라와 같은 imaging system에 부딪히게 된다. 그러면 광자들이 결국 image plane에 맺히게 되고, 평면을 통해서 어디서 광자가 왔는지 확인할 수 있다. 그리고 얼마나 많은 광자가 충돌했는지에 따라서 밝기를 결정하게 된다. 빛이 많이 부딪히는 곳에서는 높은 값이 측정되게 될 것이다. 그리고 이는 ADC를 통해서 아날로그 신호가 디지털 신호로 바뀌게 된다.
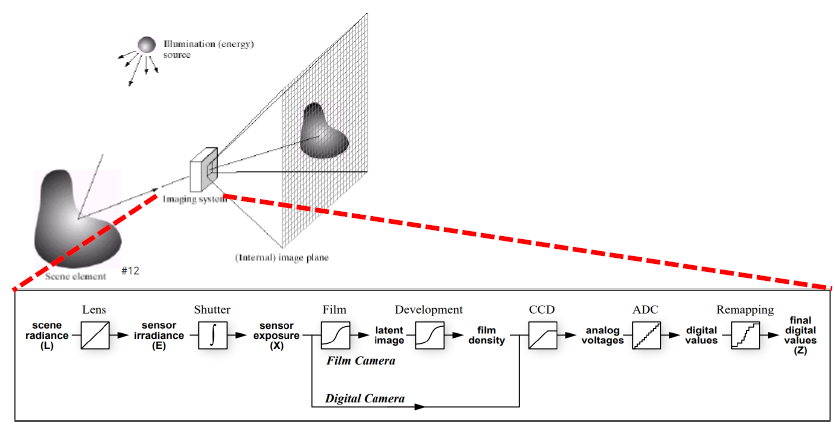 Imaging system을 좀 더 자세하게 살펴보면 특정 scene으로부터 빛이 들어오게 되면 이를 scene radiance라고 부르며 처음에는 렌즈를 통과하게 된다. 그리고 그 뒤에 달린 shutter를 이용해서 일정 단위 시간 동안 축적하게 된다. 단위 시간 동안 광자가 얼마나 축적되는지 확인하고, shutter를 잘 통과한 빛들은 디지털 카메라의 경우에는 CCD 센서에 부딪히게 된다. Image plane에 grid 하나마다 CCD 센서에 해당하게 되고, 센서의 빛의 양이 축적되어 아날로그 voltage 형태로 바뀌게 되고 ADC를 통해서 디지털 값으로 바꾸게 된다. 하지만 여기서 디지털 값을 바로 활용하게 되면 실제로 사람이 눈으로 보는 것과 다른 결과를 보게될 것이다. 사람의 시신경이 개수가 전부 다르기 때문에 사람이 보는 색에 잘 맞게하기 위해서 다시 mapping 과정을 진행하게 된다.
Imaging system을 좀 더 자세하게 살펴보면 특정 scene으로부터 빛이 들어오게 되면 이를 scene radiance라고 부르며 처음에는 렌즈를 통과하게 된다. 그리고 그 뒤에 달린 shutter를 이용해서 일정 단위 시간 동안 축적하게 된다. 단위 시간 동안 광자가 얼마나 축적되는지 확인하고, shutter를 잘 통과한 빛들은 디지털 카메라의 경우에는 CCD 센서에 부딪히게 된다. Image plane에 grid 하나마다 CCD 센서에 해당하게 되고, 센서의 빛의 양이 축적되어 아날로그 voltage 형태로 바뀌게 되고 ADC를 통해서 디지털 값으로 바꾸게 된다. 하지만 여기서 디지털 값을 바로 활용하게 되면 실제로 사람이 눈으로 보는 것과 다른 결과를 보게될 것이다. 사람의 시신경이 개수가 전부 다르기 때문에 사람이 보는 색에 잘 맞게하기 위해서 다시 mapping 과정을 진행하게 된다.
Thinking about an image as a function
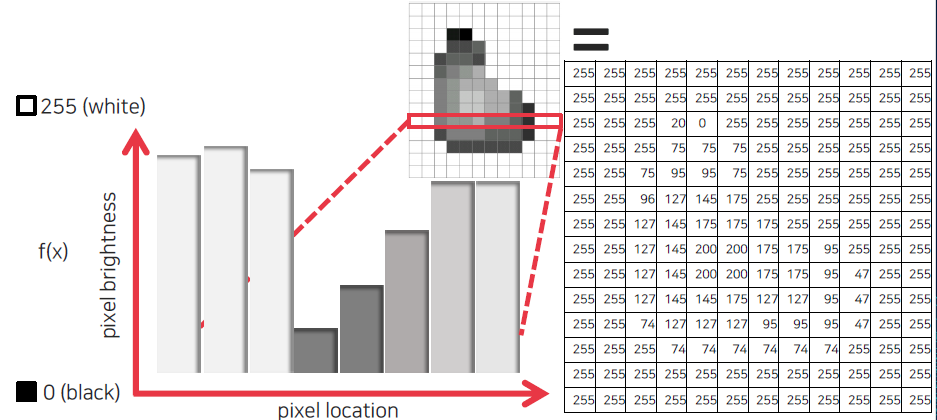 2D 값으로 정해진 값들에 대해서 자세하게 살펴보고자 한다. 일반적으로 gray scale의 경우 하나의 채널로 image가 구성되어 있고, 이는 8bit로 표현되기 때문에 0은 검은색, 255는 하얀색이 된다. 2D 형태의 image에서 저장된 값들을 밝기 값으로 전환할 수 있기에 위를 보면 하얀 공간이 전부 255로 채워진 것을 볼 수 있다. 일반적으로 8bit로 표현되지만 HDR image같은 경우에는 16bit를 가지게 된다. 이러한 표현은 0과 1 사이로 normalization을 하게 되면 밝기가 낮은 값은 아래에 형성되고 높은 값은 위에 형성되기 때문에 일종의 intensity 함수로 볼 수도 있게 된다.
2D 값으로 정해진 값들에 대해서 자세하게 살펴보고자 한다. 일반적으로 gray scale의 경우 하나의 채널로 image가 구성되어 있고, 이는 8bit로 표현되기 때문에 0은 검은색, 255는 하얀색이 된다. 2D 형태의 image에서 저장된 값들을 밝기 값으로 전환할 수 있기에 위를 보면 하얀 공간이 전부 255로 채워진 것을 볼 수 있다. 일반적으로 8bit로 표현되지만 HDR image같은 경우에는 16bit를 가지게 된다. 이러한 표현은 0과 1 사이로 normalization을 하게 되면 밝기가 낮은 값은 아래에 형성되고 높은 값은 위에 형성되기 때문에 일종의 intensity 함수로 볼 수도 있게 된다.
Color intensity
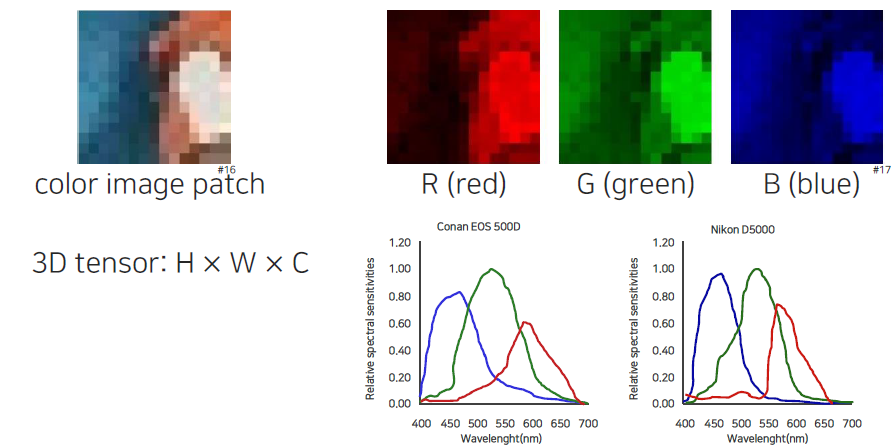 지금까지 gray scale에 대해서 이야기했지만, 일반적으로 주로 접하는 image는 color scale일 것이다. Color image는 gray 채널과 같은 것이 3개가 중첩되어 있다. 이는 각각 R, G, B 채널을 나타내어 각각이 8bit를 표현하게 된다.
지금까지 gray scale에 대해서 이야기했지만, 일반적으로 주로 접하는 image는 color scale일 것이다. Color image는 gray 채널과 같은 것이 3개가 중첩되어 있다. 이는 각각 R, G, B 채널을 나타내어 각각이 8bit를 표현하게 된다.
카메라마다 동일한 물체를 촬영하더라도 color 값이 다르게 표현된다. Color 값이 다르게 나오는 이유는 각 color 센서마다 sensitivity가 다르기 때문이다. Red나 Blue 채널의 spectrum은 굉장히 넓다. 위에서 각 카메라마다 color 값의 가중치가 서로 다른 것을 확인할 수 있다.
Bayer pattern
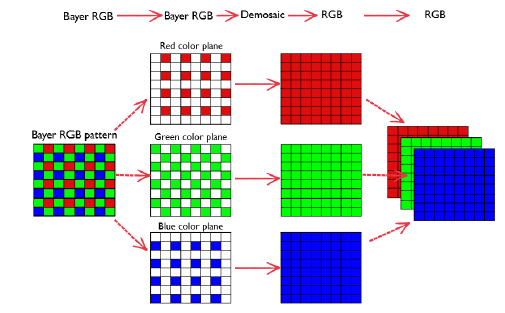 R, G, B color 값을 얻기 위해서 센서 위에 filter를 도포하게 된다. 그래서 각 채널 값에 가중치를 곱해주는 형태로 color 값을 측정하게 된다. 센서가 2D이기 때문에 filter를 도포하게 되면 하나의 color 밖에 얻지 못한다. 그래서 Bayer pattern을 통해서 센서를 배치하게 되고, 이를 통해서 3개의 color를 얻게 된다. 여기서 위를 보면 green 채널을 더 많이 배치한 것을 볼 수 있다. 실제를 비슷하게 반영하기 위해서 RGB 3채널인 이 홀수를 정사각형 형태로 구성하는 것이 좋기 때문에 green 채널을 한번더 사용한 것이다. 그리고 사람이 밝기를 인식하는 경우에도 green 채널이 중요하게 작용한다. 그래서 green 채널을 중심으로 Bayer pattern을 활용하게 된다.
R, G, B color 값을 얻기 위해서 센서 위에 filter를 도포하게 된다. 그래서 각 채널 값에 가중치를 곱해주는 형태로 color 값을 측정하게 된다. 센서가 2D이기 때문에 filter를 도포하게 되면 하나의 color 밖에 얻지 못한다. 그래서 Bayer pattern을 통해서 센서를 배치하게 되고, 이를 통해서 3개의 color를 얻게 된다. 여기서 위를 보면 green 채널을 더 많이 배치한 것을 볼 수 있다. 실제를 비슷하게 반영하기 위해서 RGB 3채널인 이 홀수를 정사각형 형태로 구성하는 것이 좋기 때문에 green 채널을 한번더 사용한 것이다. 그리고 사람이 밝기를 인식하는 경우에도 green 채널이 중요하게 작용한다. 그래서 green 채널을 중심으로 Bayer pattern을 활용하게 된다.
