팀내 DB 운영 구성도 이해하기 1편 ➡️ MySQL 이중화 진화기 를 시청하고 내용을 정리합니다.
팀내 DB 운영 구성도 이해하기 2편 ➡️ 우리팀의 DB 이중화 구성도를 이해하고 정리합니다.
NHN CLOUD 데이터운영팀의 DB 운영 구성(이중화 등)을 이해하기 위해 작성한 글입니다. 먼저 노을 선임님의 MySQL 이중화 진화기 를 시청하고, 그 다음 우리팀의 DB 이중화 구성도를 이해한 다음 정리합니다.
목차
1. DB를 구성하는 방법
- DB 복제 구성
- DB 복제 구성 + VIP
2. 이중화 방안
- HW 이중화( shared Disk / Disk 복제 )
- DB MySQL Replication 이중화
-> MySQL Replication
-> MySQL Replication 이중화(MMM/MHA)3. DB 이중화를 사용하면서 겪은 고민
- VIP vs DNS
- DNS 사용의 단점
4. 질문
DB를 구성하는 방법
1) DB 복제구성
예를 들어 MySQL DB가 1대 있다고 가정해봅니다. 각각의 서버에서는 MySQL DB의 물리 IP인 192.168.10.1 을 바라봅니다.
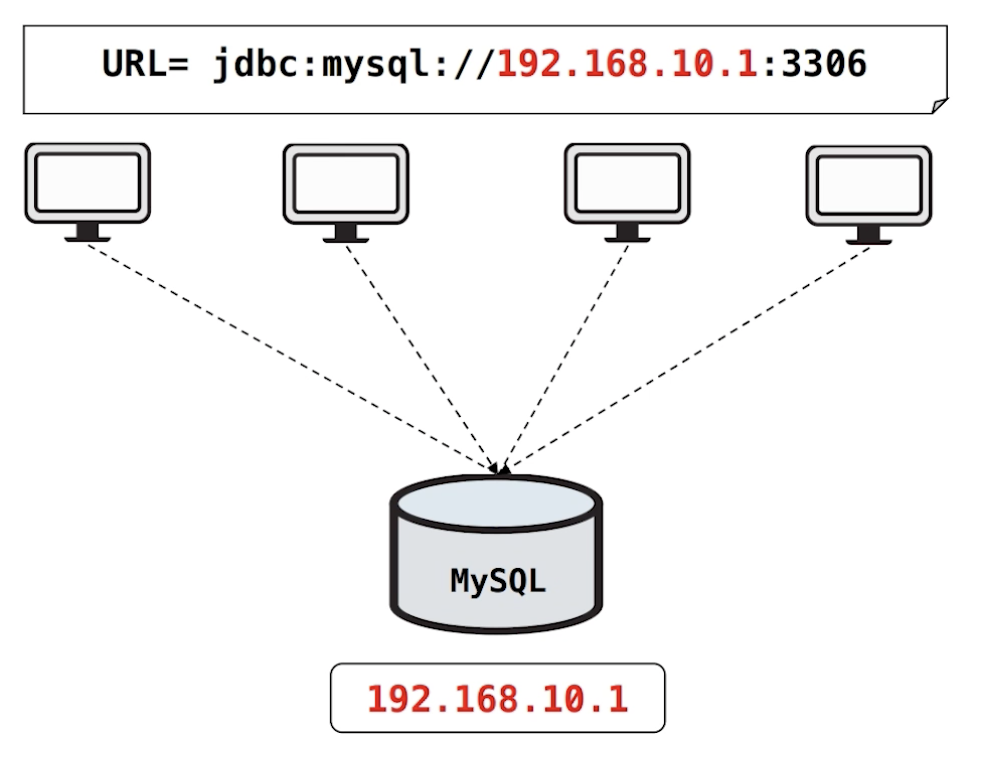
만약, HW 장애나 MySQL DB 문제로 접속이 되지 않는다면 서비스에 들어오는 데이터를 저장할 수 없고, 서비스에 저장되어있는 데이터를 읽어올 수 없기 때문에 DB 서버를 복구하는 시간동안 장애를 맞게 됩니다.
따라서 장애 시, 대체할 장비를 하나 더 추가하고 복제를 구성해야합니다.

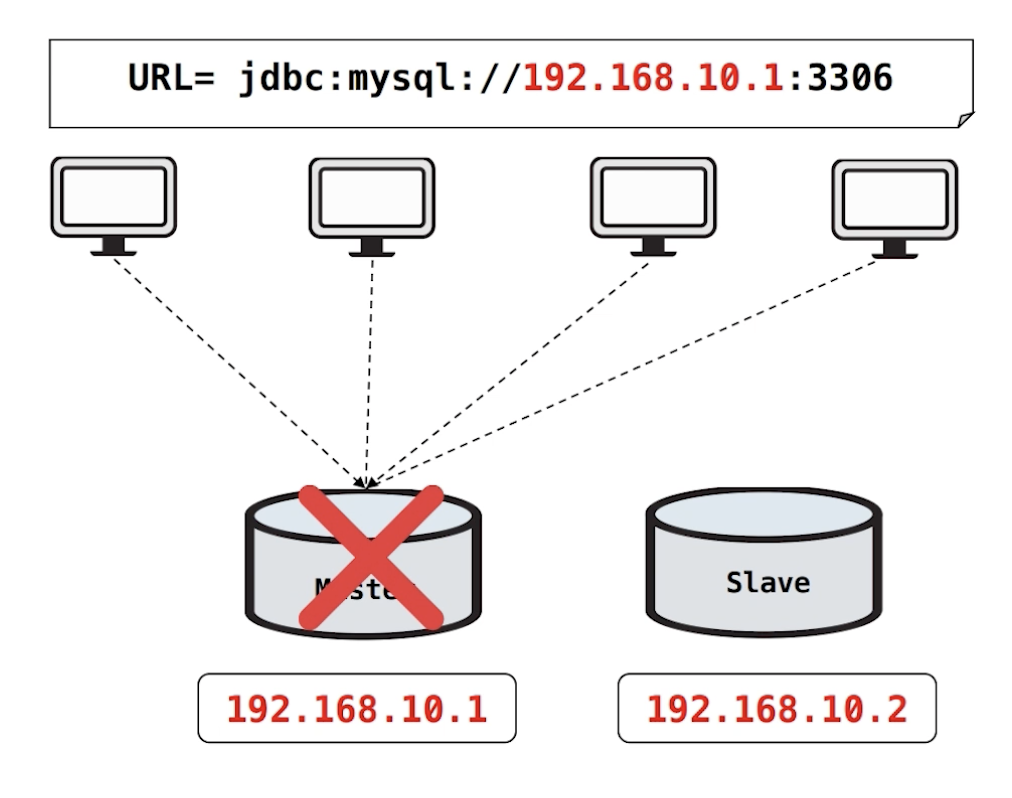
Master DB와 Slave DB를 구성하고, 각 서버는 Master DB의 물리 IP를 바라봅니다. 이때, 장애가 생기면 각 서버의 DB 커넥션 정보를 Mater의 물리 IP에서 Slave의 물리IP로 변경해서 배포해주면 Slave DB로 서비스를 운영할 수 있습니다.
HW 이중화는 Single DB를 사용할때보다 장애 복구 시간이 줄어들지만, 아직 시간이 한참 소요되는 방법입니다. 이 시간을 줄일 수 있도록 VIP를 추가하는 방법이 있습니다.
2) DB 복제구성 + VIP
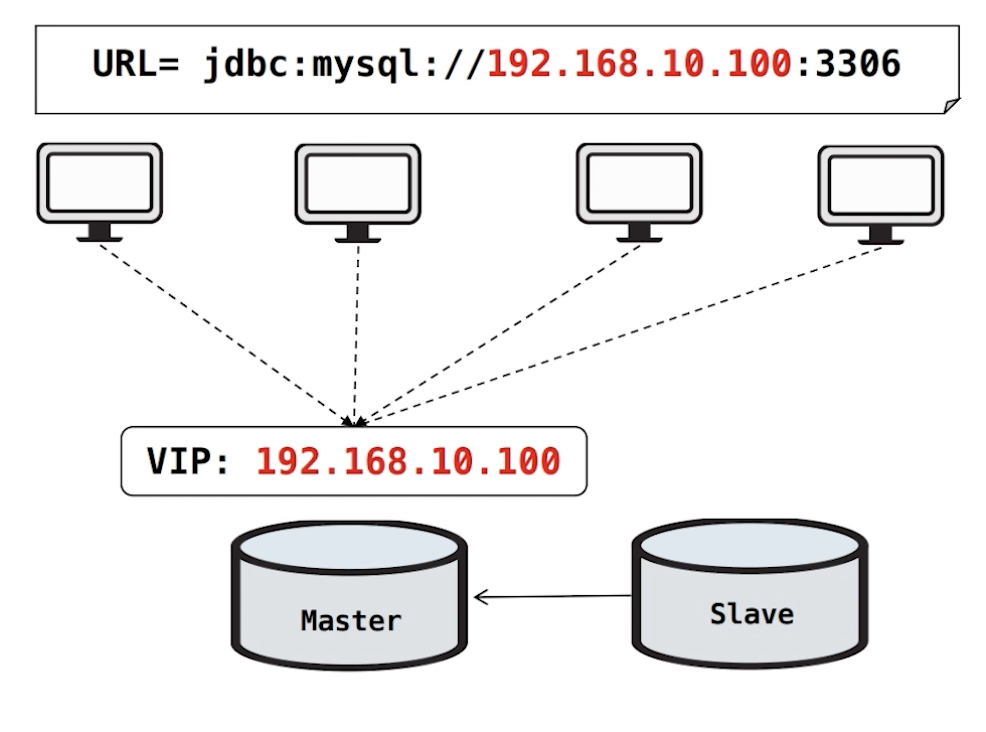
Master DB 앞단에 가상의 IP인 VIP 192.168.10.100을 추가해줍니다. 각 서버에서는 DB 커넥션 정보를 가져오기 위해 Master에 추가된 VIP를 바라보고 있습니다.
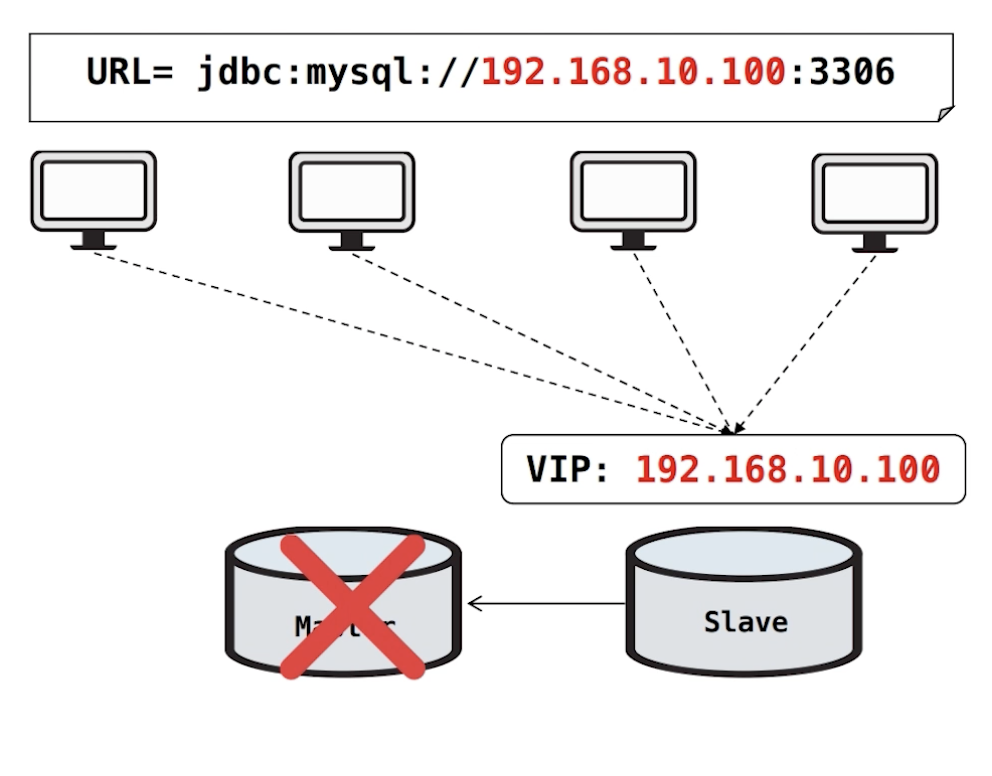
여기서 Master DB 장애가 났을 경우에, Master DB의 VIP를 제거하고 Slave DB에 VIP를 붙여줍니다. 이렇게 각 서버의 DB 커넥션이 Slave DB로 운영할 수 있게 진행해줍니다. 기존의 Master DB에 연결되어있던 커넥션들은 서버의 리커넥션 로직에 의해 변경된 VIP로 재접속 할 수 있게 됩니다.
현재 저희 팀에서 운영하고 있는 DB의 개수가 굉장히 많고, 업무시간 외에도 장애 대응이 필요합니다. 하이퍼바이저 1대가 장애가 나면 연결된 DB 여러개가 한꺼번에 떨어지기도 합니다. 따라서, 주기적으로 DB서버의 Health Check를 진행하고 장애 시 자동으로 FailOver를 진행하는 이중화 구성 방안이 필요했습니다.
이중화 방안
1) HW 이중화
1.1) Shared Disk 방식
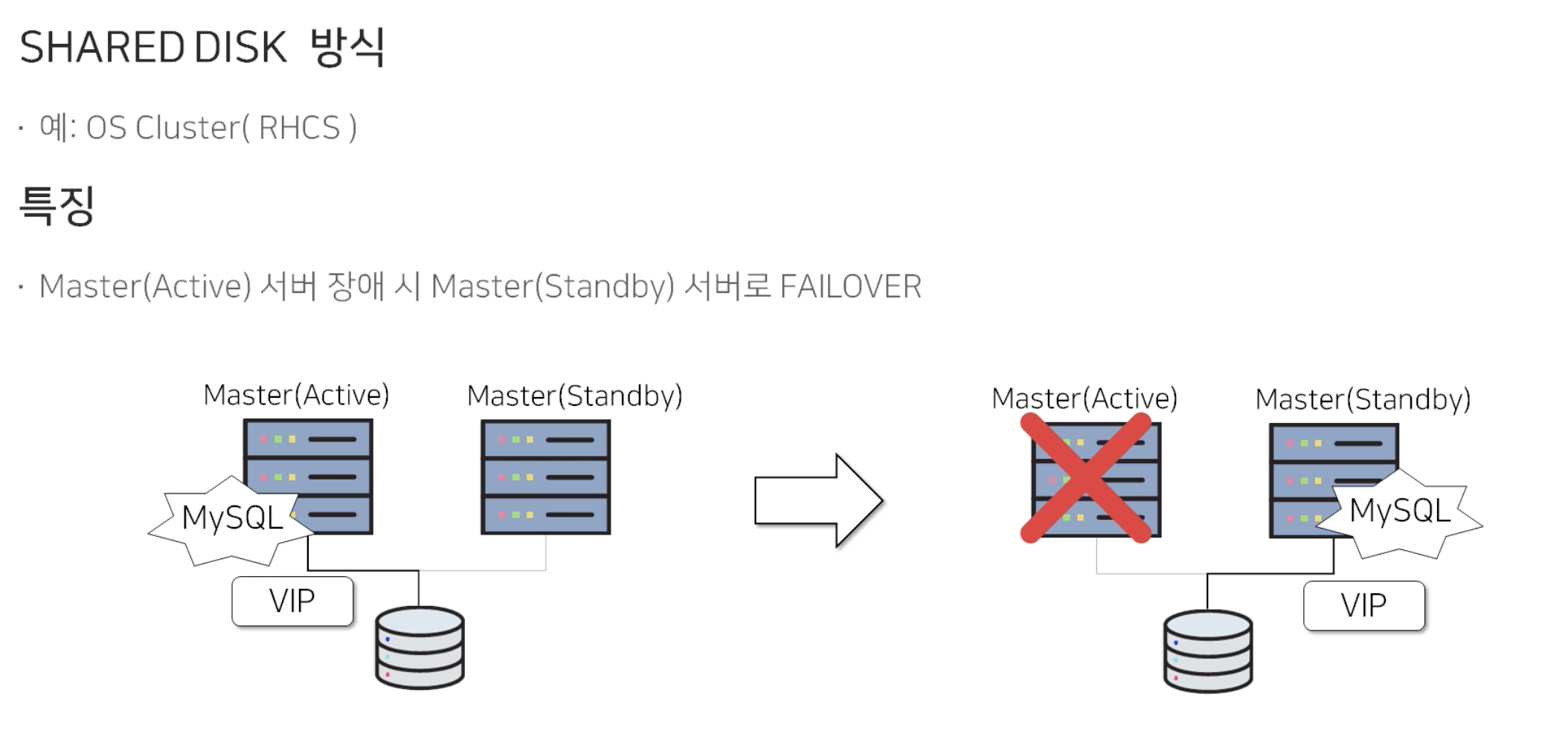
하나의 Disk를 공유하는 Master(Active)/Master(Standby) 로 구성되어 있습니다. 평상시에는 Master(Active)에서 Disk를 활성화하고 VIP를 서비스 합니다. 그리고 Master(Active)에서 장애가 날 경우, Master(Standby)로 Disk를 활성화하고 VIP를 서비스합니다. Master(Standby)는 평상시에는 사용하지 않고, Failover 용도로만 사용됩니다.
이 방식의 문제점은 고비용의 shared disk가 필요합니다. 비용적인 문제가 존재하기 때문에 실제로는 아래의 방식을 더 많이 사용하고 있습니다.
1.2) Disk 복제 방식
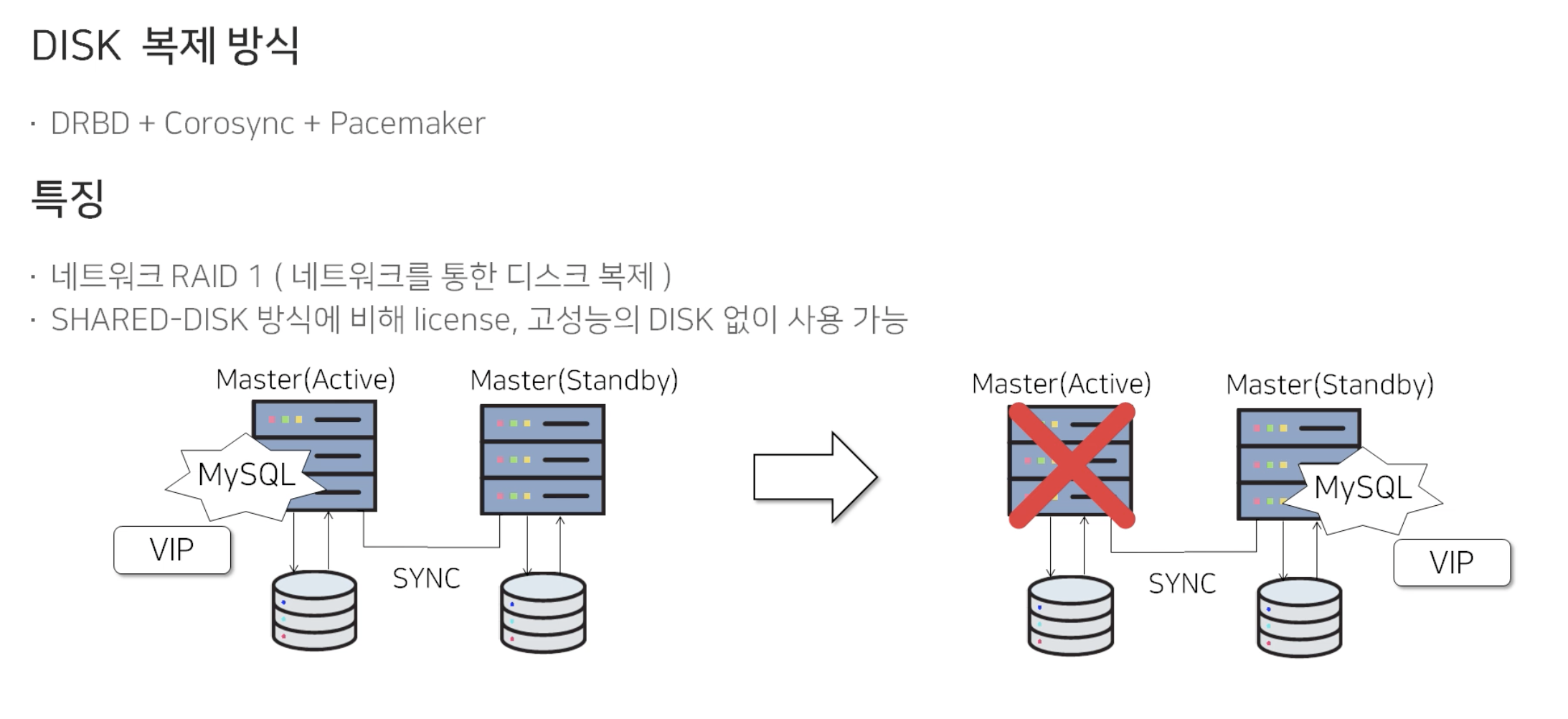
이 방식은 별도의 라이센스나 고비용의 Disk 필요없이 구성이 가능합니다. 추가로 오픈소스로 구성이 가능합니다. Shared Disk 방식과 동일하게 Master(Active)/Master(Standby)로 구성되어있지만, 다른점은 Disk 복제 방식은 동일한 Disk를 공유하는 것이 아니라 각각의 Disk를 바라보고 있습니다.
평상시에는 Master(Active) 서버에 MySQL DB를 띄우고 VIP를 서비스합니다. 평상시에 Master(Active)에서 변경된 데이터는 네트워크를 통해 Master(Standby) 쪽으로 Disk를 복제해서 같은 데이터를 가지게 됩니다.
장애가 생겼을 경우에는 Master(Standby)로 MySQL DB를 띄우고 VIP를 서비스합니다.
이 방식은 네트워크를 통해 Disk를 복제하는 것이 핵심입니다. 따라서 이 Disk 복제방식의 가장 큰 단점은 Network Latency에 의해 성능 영향을 받는 다는 것입니다.
HW 이중화 구성의 단점
Shared Disk 방식, Disk 복제 방식 은
- Standby 서버의 경우 Failover 시에만 사용가능
- 백업을 위한 추가 서버 필요
- 유지보수 및 장애 대응 힘듦 (HW level의 이중화 구성이기 때문에 OS 및 하드웨어에 대한 지식 필요)
2) DB MySQL Replication 이중화
DB MySQL Replication 이중화 이전에 MySQL Replication(복제) 이 어떻게 구성되어 있고 동작하는지를 알아봅니다.
2.1) MySQL Replication
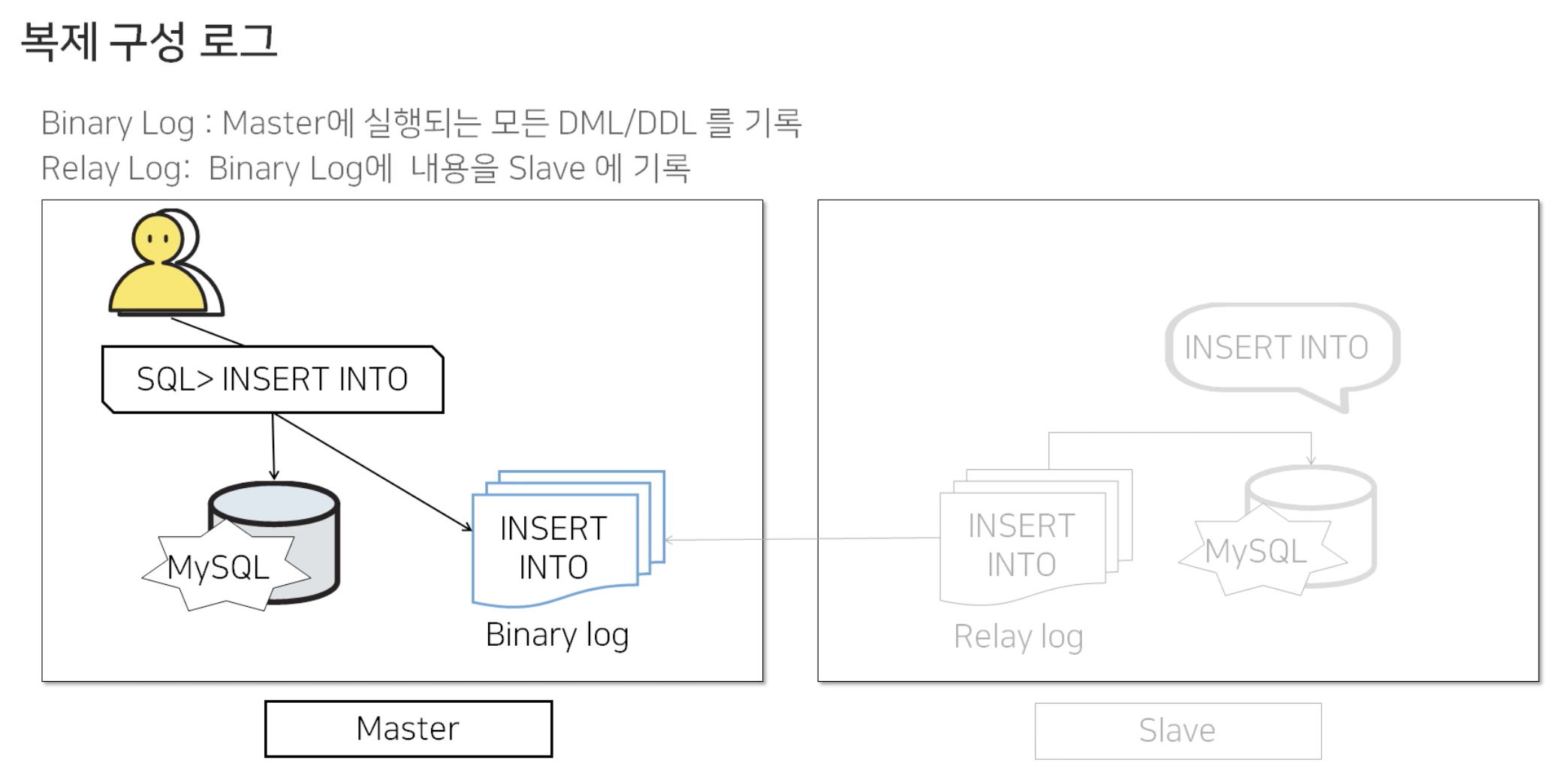
클라이언트가 쿼리를 실행하면
Master DB에서는 변경되는 insert/update/delete 등의 모든 DML/DDL을 Binary Log에 저장하고 MySQL DB에 실행됩니다.
Slave DB에서는 Binary Log를 감시하다가, 새로운 쿼리가 들어오게 되면 Relay Log로 가져오게 됩니다. 그리고 그 쿼리를 Slave DB에 실행함으로써 Master의 데이터가 Slave로 동일하게 적용되게 됩니다.
그렇다면, MySQL Replication의 일관성 보장은 어느정도일까요?
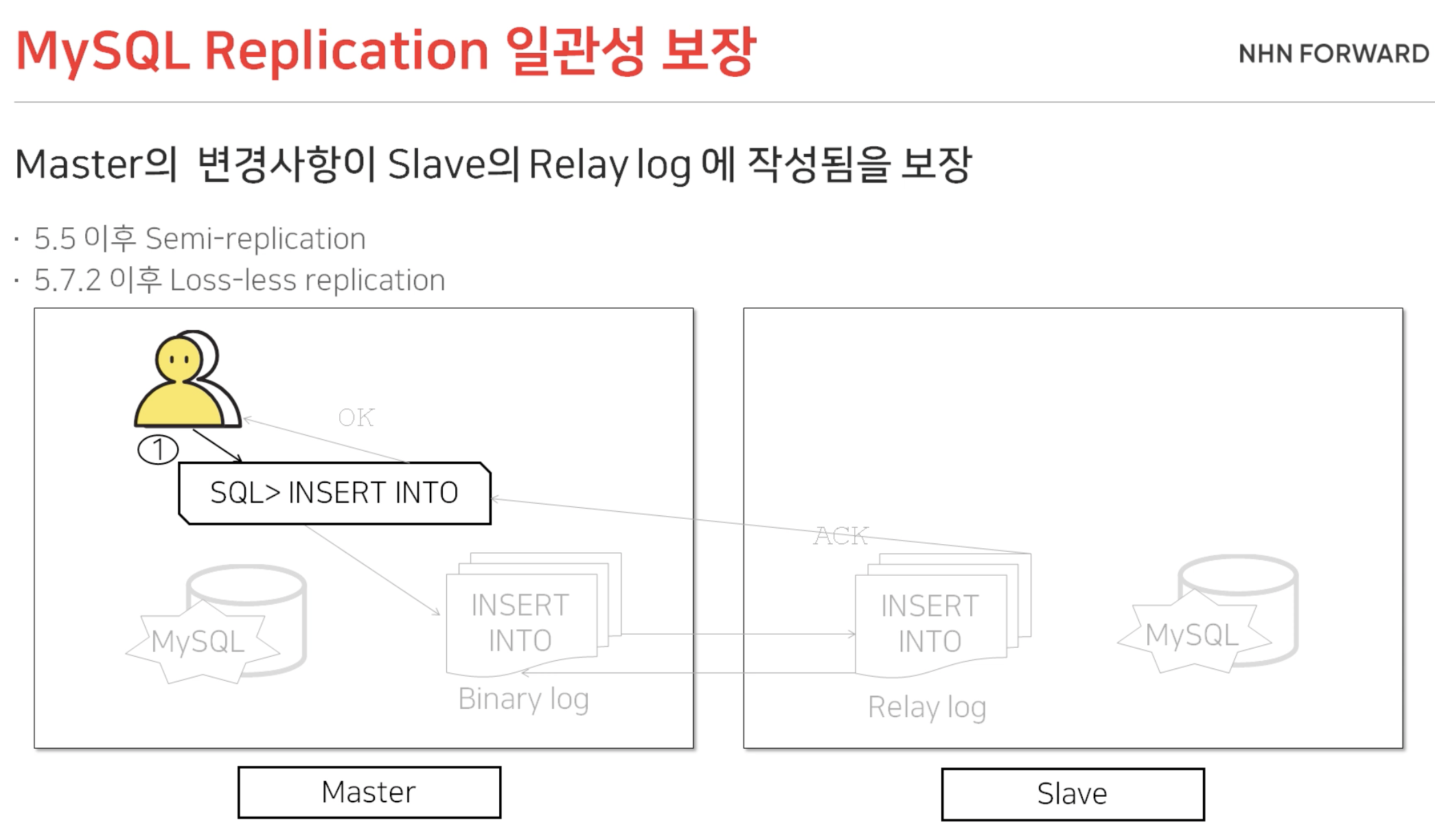
Master와 Slave가 데이터 Sync를 맞추는 과정에서, Master DB는 Slave DB가 Binary Log를 전달받았다는 것을 인정받기 위해 응답을 기다립니다. Slave DB는 Binary Log를 받아 Relay Log를 작성하고 Master DB에 응답을 보냅니다. 그리고 응답을 받은 Master DB는 최종적으로 클라이언트에게 OK를 리턴하게 됩니다.
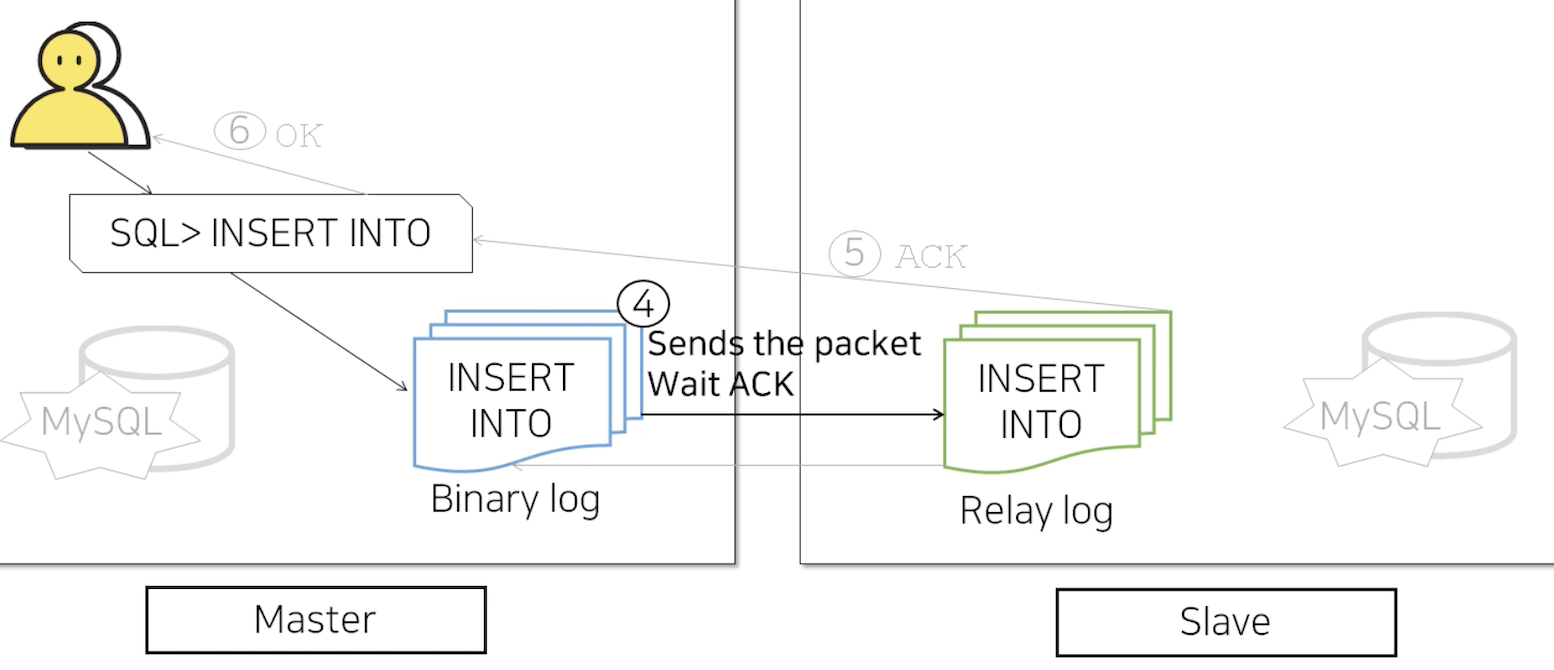
이렇게 MySQL Replication에서는 Master의 변경사항이 Slave의 Relay Log까지 작성됨을 보장하고 있습니다.
그렇다면, Slave가 여러대일때, MySQL Replication의 일관성 보장은 어느정도일까요?
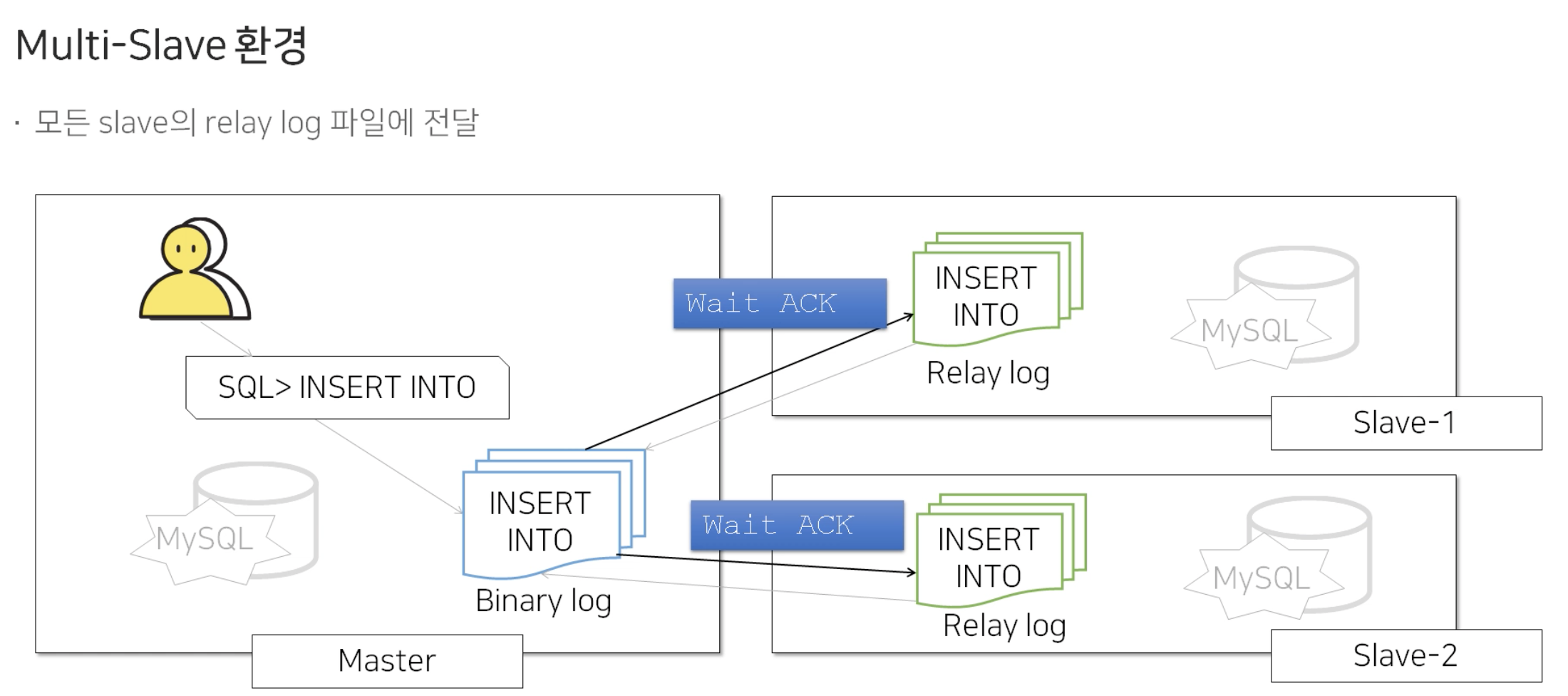
동일하게 모든 Slave DB 서버에 Binary Log를 보내주고 응답을 기다리는 형태입니다. 여기서 하나의 Slave DB에서라도 응답을 받게 되면 클라이언트에게 OK를 리턴하게 됩니다. 따라서 Slave가 여러대일때에는 Master의 변경사항이 하나의 Slave의 Relay Log까지 작성됨을 보장하고 있습니다.
2.2) MySQL Replication 이중화
지금까지 MySQL Replication의 구성에 대해 알아보았습니다. 이 개념을 가지고 MySQL Replication 이중화 종류에 대해서 알아보겠습니다.
1. MMM(Multi Master Replication Master) 구성
1) MMM 이란?
- perl 기반의 Auto failover open source
- DB 서버에서 agent를 실행하고 MMM Monitor에서 통신하는 방식으로 DB 서버 Healthcheck와 Failover를 실행
- NHN 에서 운영중인 대표적인 이중화 방안
2) MMM 구조
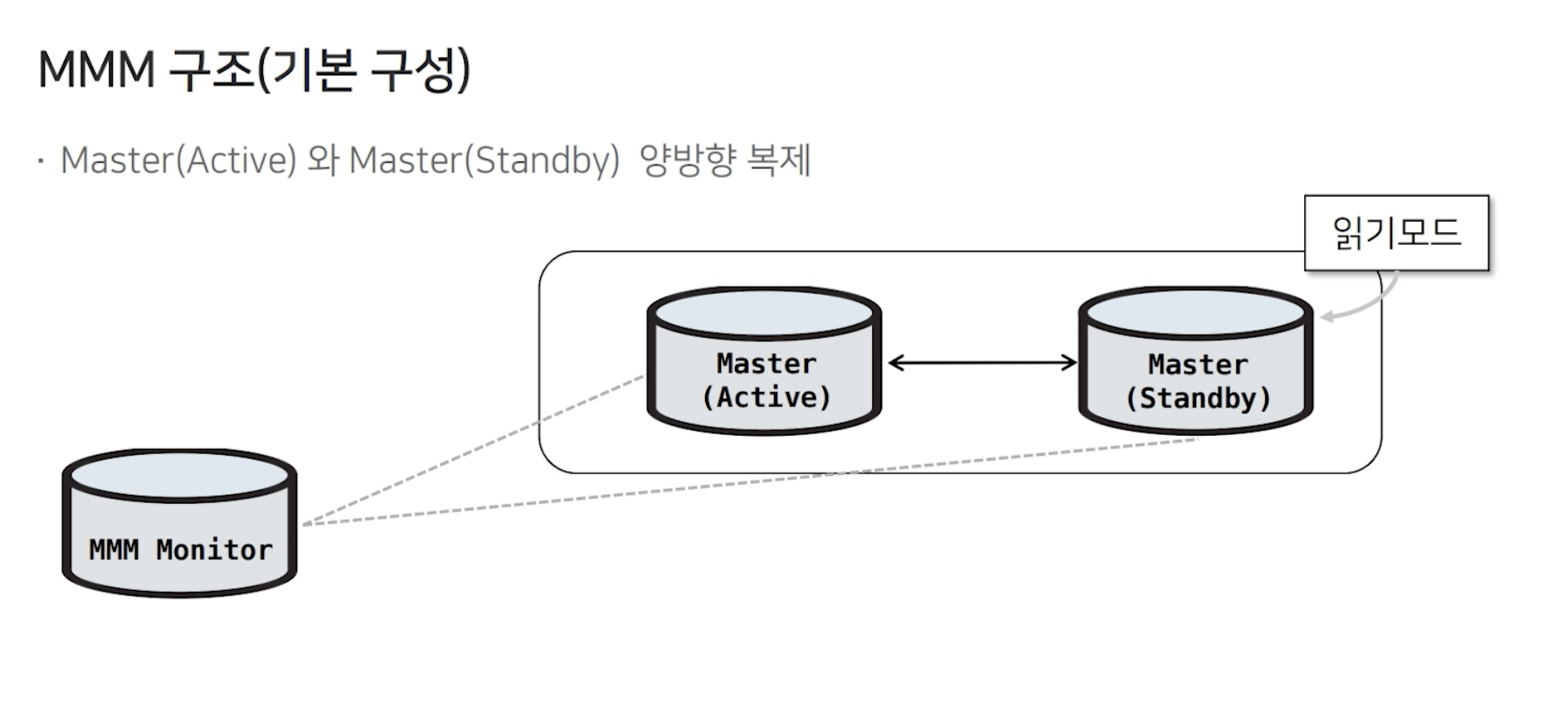
Master(Active)<->Master(Standby) 양방향 복제 형태이며, Master(Active)에서는 읽기/쓰기 가 가능하고, Master(Standby)에서는 읽기만 가능합니다.
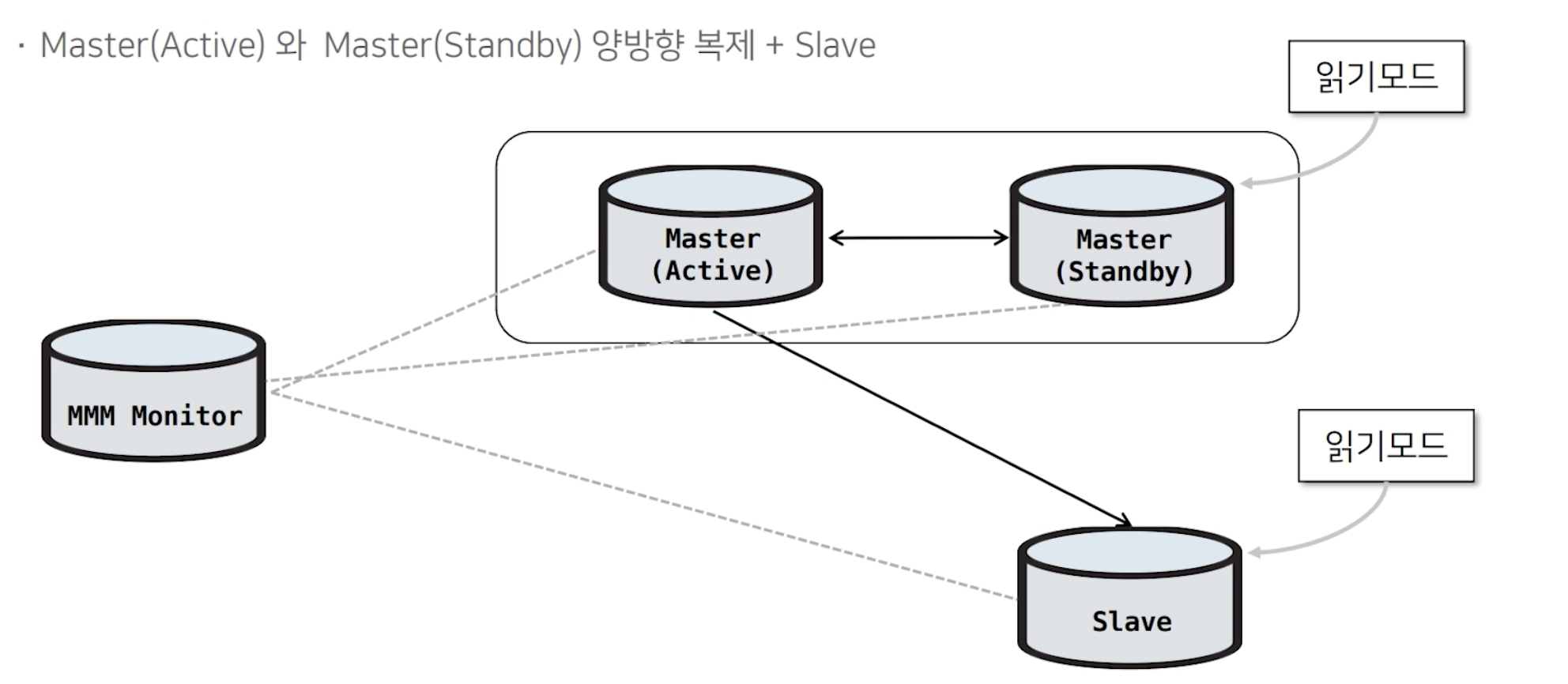
Slave가 추가되는 경우에서는 단방향 복제 서버가 하나씩 추가되는 형태라고 보면 됩니다. 이 Slave 역시 MMM Monitor에 의해 읽기 모드로 제한됩니다.
3) MMM Failover 과정
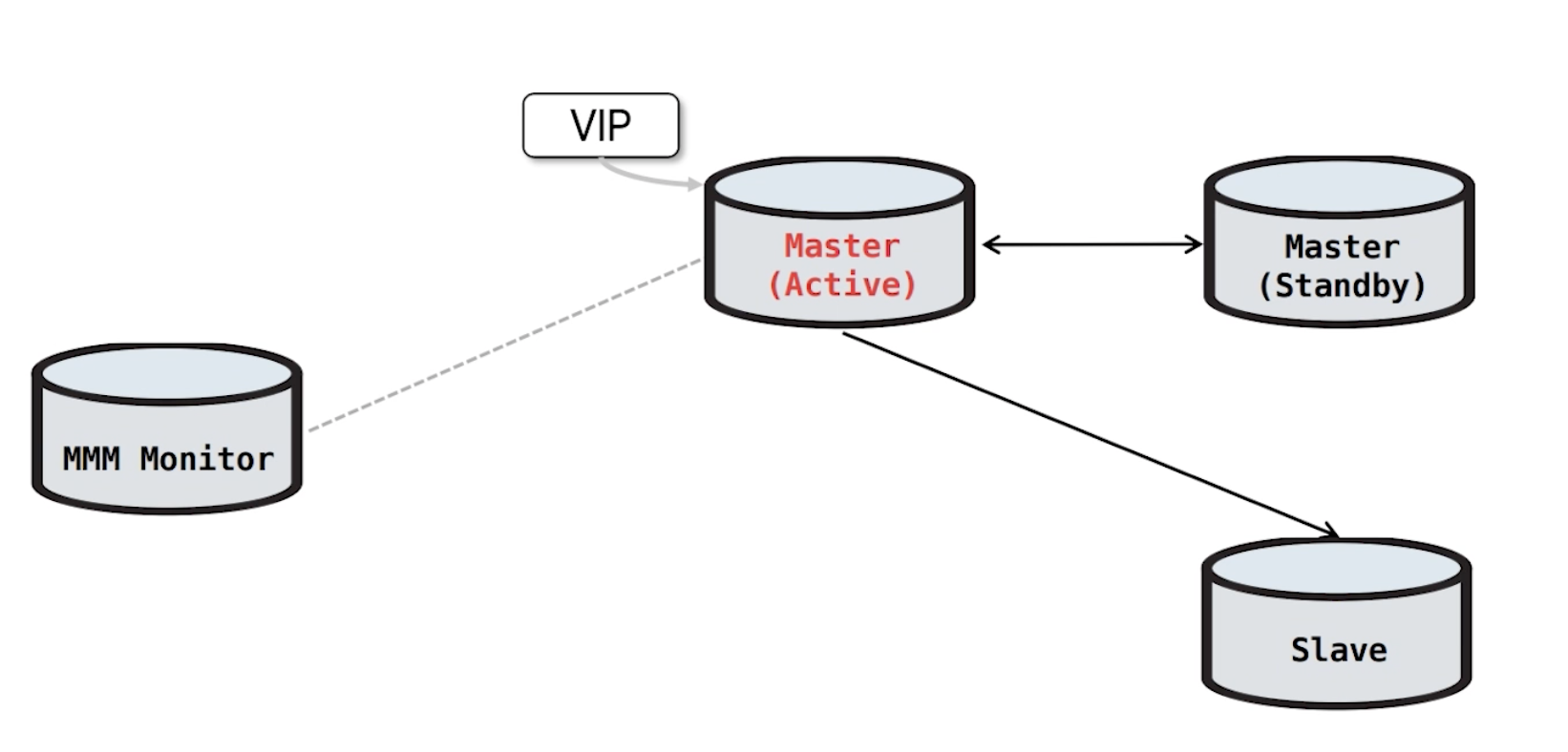
MMM Monitor에서 Master(Active)를 Health Check 하다가 접속이 되지 않으면 Failover를 시작합니다.
<MMM Failover 과정>
1) Master(Active)의 역할을 뺏는다.
1.1) Master(Active)의 데이터가 더이상 변경되지 않도록 읽기모드로 변경
1.2) Master(Active)에 붙어있던 Session을 모두 Kill
1.3) 신규 session이 들어오지 않도록 VIP 회수
2) Master(Standby)로 복제 재구성한다.
2.1) Master(Standby)&Slave 둘중 복제지연이 있는지 확인
2.2) 복제지연이 해소되거나 없는 경우 Master(Standby) 기준으로 복제 재구성
3) Master(Standby)를 신규 Master로 승격시키는 작업을 한다.
3.1) Master(Standby)의 읽기모드를 해제
3.2) 신규 session이 들어오도록 VIP 할당
4) Failover 완료MMM은 양방향복제를 하고 있기 때문에, MMM Failover 대상은 무조건 Master (Standby) 입니다. 이는 읽기모드의 slave가 몇대이든 상관없이 Master (Standby) 가 Failover 대상이 되도록 지정되어 있습니다.
4) MMM Failover 후속처리
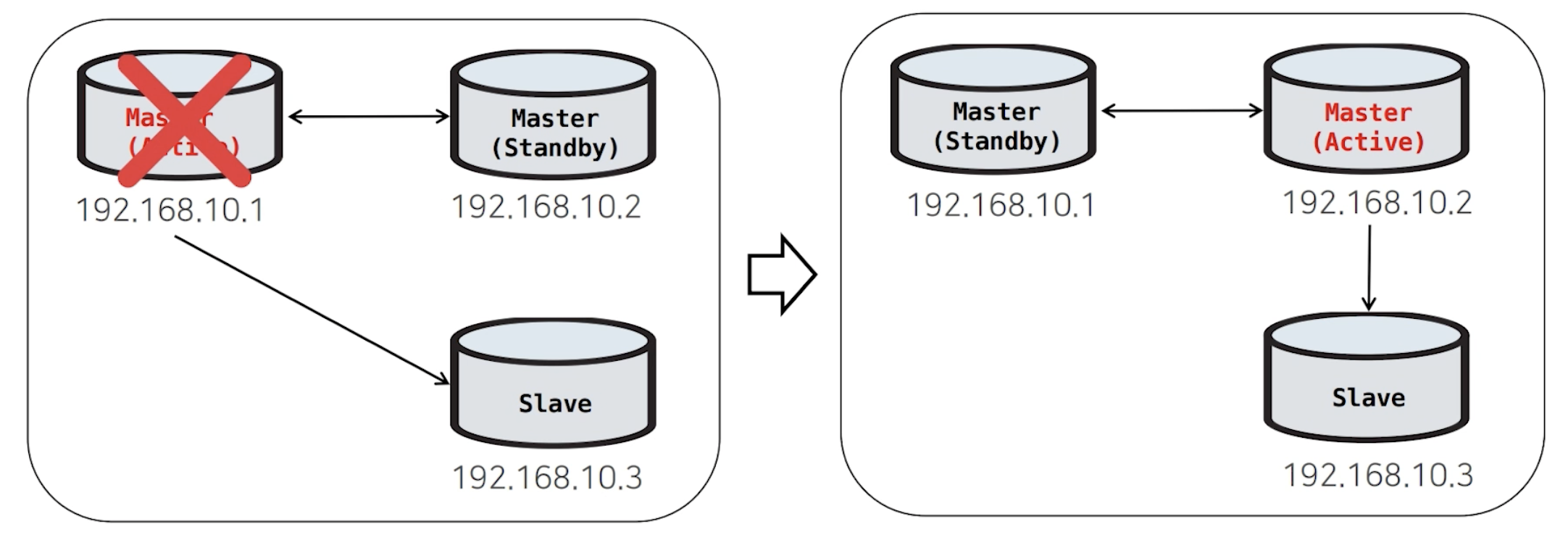
MMM 구조는 양방향 복제이기 때문에 Master(Active)가 장애가 나더라도 Master(Standby)는 복제가 깨지지 않고 신규 Master(Active)로 승격될 수 있습니다.
따라서 MMM 에서는 Failover 후속처리과정이 필요없습니다.
다만, Master(Standby)에서만 백업을 받고 있고 관리상의 이유로 Failback(Failover 에 따라 전환된 서버/시스템/네트워크를 장애 발생전으로 되돌리는 처리) 를 진행하고 있습니다.
참고로, MMM Failover의 이유로는 아래의 예시가 있습니다.
- 무거운 쿼리가 들어옴으로써 메모리 점유율이 높아져서 OS에 의해 KILL 되는 경우
- 하이퍼바이저 장애로 DB가 내려갔다 다시 올라올 경우
( 요때는 원래 Master(Active)였던 DB가 정상적으로 올라왔을 경우 Failover 대상이 됨 )
5) MMM Failover 시 복제가 깨지는 경우
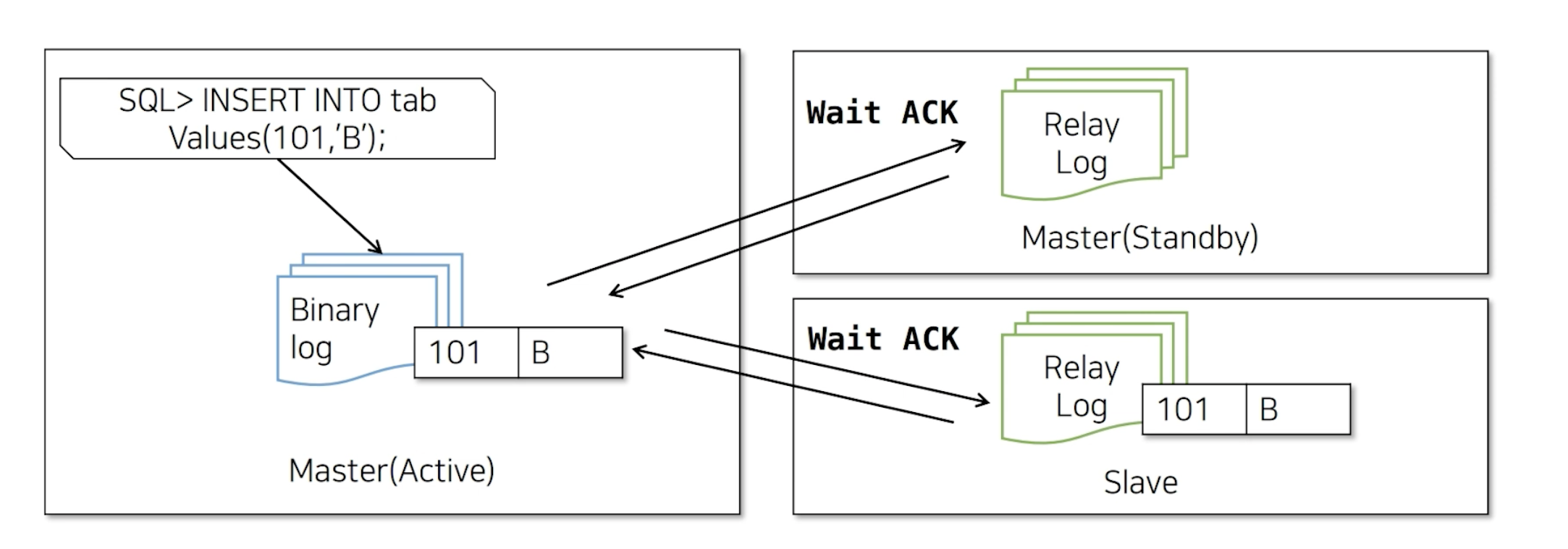
만약, Master(Active) 에 101-B 데이터가 들어오고 Slave에서만 이 데이터가 복제된 상태라고 가정합니다. Slave 데이터를 받았기 때문에 Master(Active)에 응답을 보내게 됩니다. 그런데 바로 이 과정에서 장애가 나게 된다면,
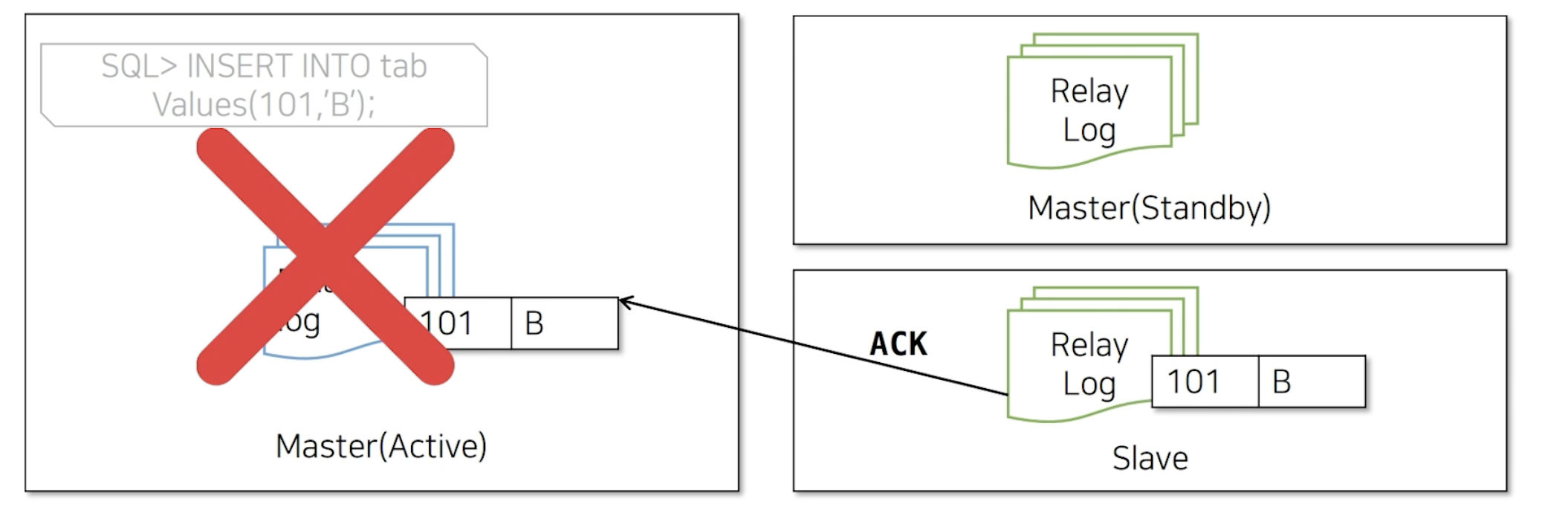
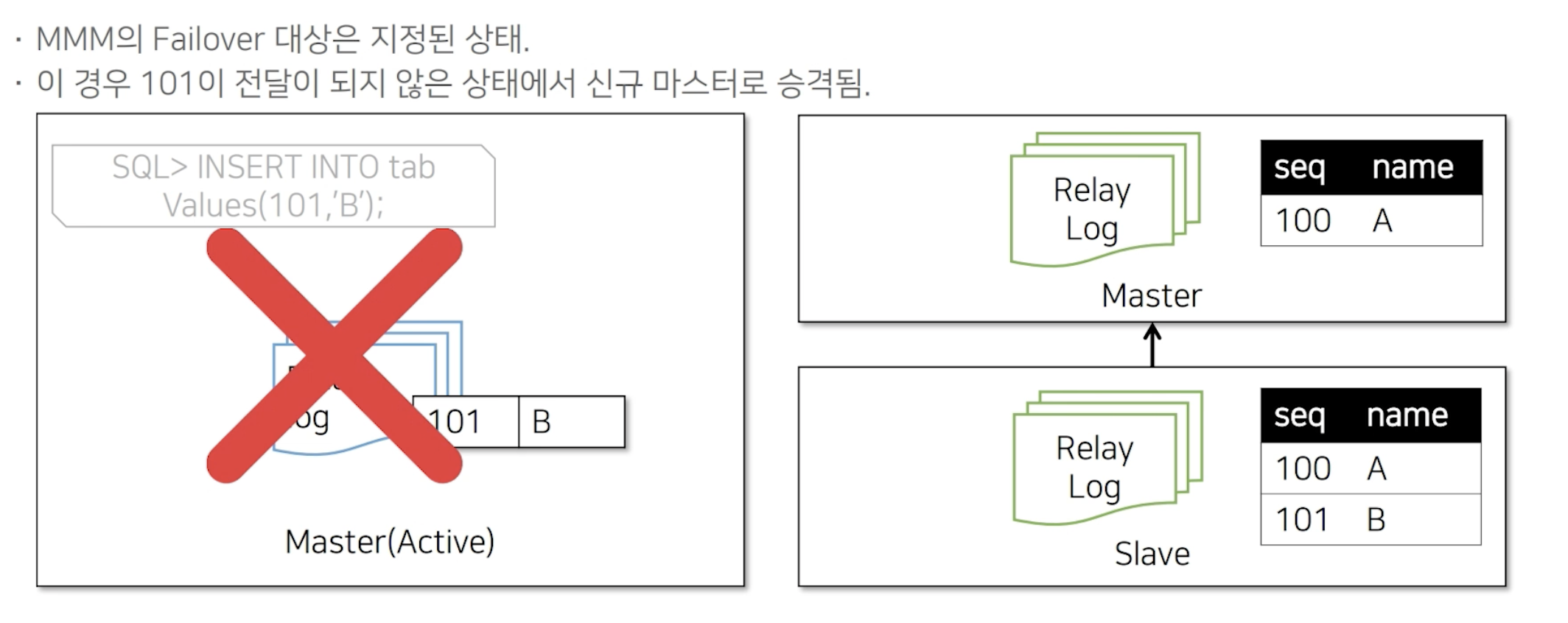
MMM Failover는 Master(Standby)로 지정되어 있기 때문에, 이 경우 101-B 데이터가 전달되지 않은 상태에서 신규 Master(Active)로 승격되게 됩니다. 그렇 다면 승격된 신규 Master(Active)는 유실된 101-B를 받게 되고 Master(Active)에 데이터가 들어왔기 때문에 복제로 인해 Slave로 다시 101-B 데이터가 들어가게 됩니다. 하지만 Slave에서는 이미 이 101-B 데이터가 존재하기 때문에 중복 키 오류로 복제가 깨지게 됩니다.
이렇게 MMM Multi Slave 구조에서는 미약하지만 복제 Crash 가능성이 존재합니다.
따라서, 이 대안으로 MHA 이중화 솔루션을 사용합니다.
2. MHA(Master High Availability) 구성
1) MHA 이란?
- perl 기반의 Auto failover open source
- MMM 보다 좀 더 많은 기능과 예외처리
- DB 서버에서 agent를 실행하지 않고, MHA Monitor에서 DB 서버로 명령어를 날리는 방식 (Agentless)
2) MHA 구조
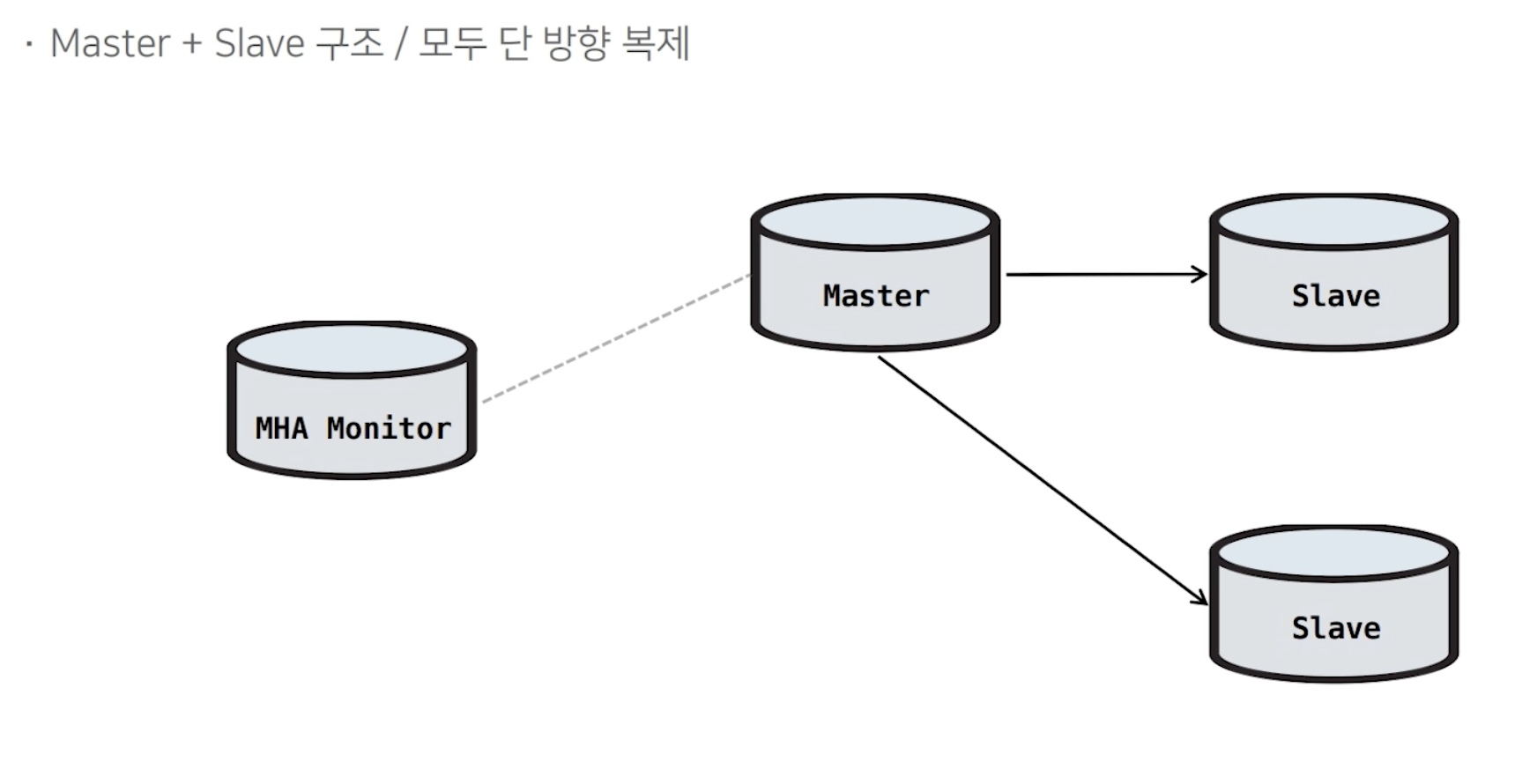
하나의 Master와 N대의 단방향 복제 Slave 형식입니다.
3) MHA Failover 과정 & 후속처리
MHA Monitor에서 Master(Active)를 Health Check 하다가 접속이 되지 않으면 Failover를 시작합니다.
<MHA Failover 과정>
1) MHA 모니터가 Master(Active) 장애 발생 시, 복제를 끊는다.
2) 나머지 Slave 들로 복제를 구성한다.
3) Failover 완료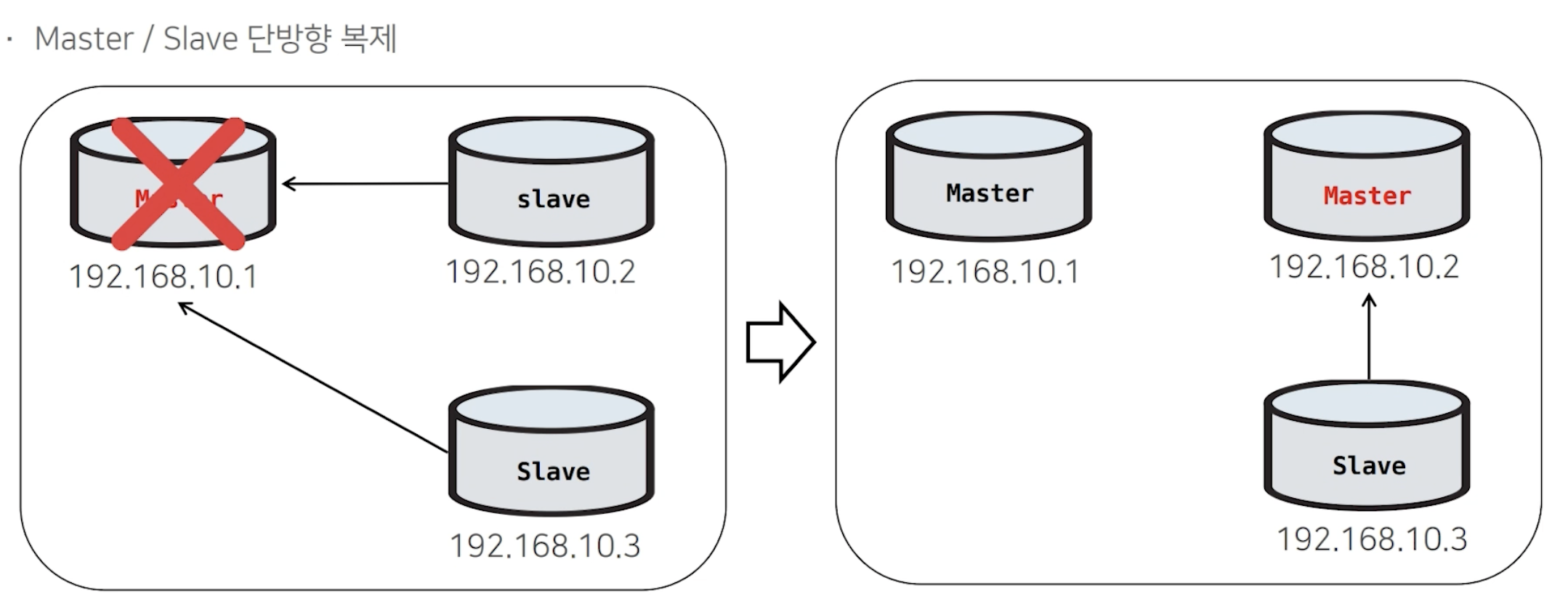
4) MHA Failover 대상
MMM은 Failover 대상이 MMM(Standby)로 지정되어 있었는데, MHA 구성에서는 Failover 대상이 고정되어있지 않습니다. 그렇다면 어떻게 Failover 대상을 선정할까요?
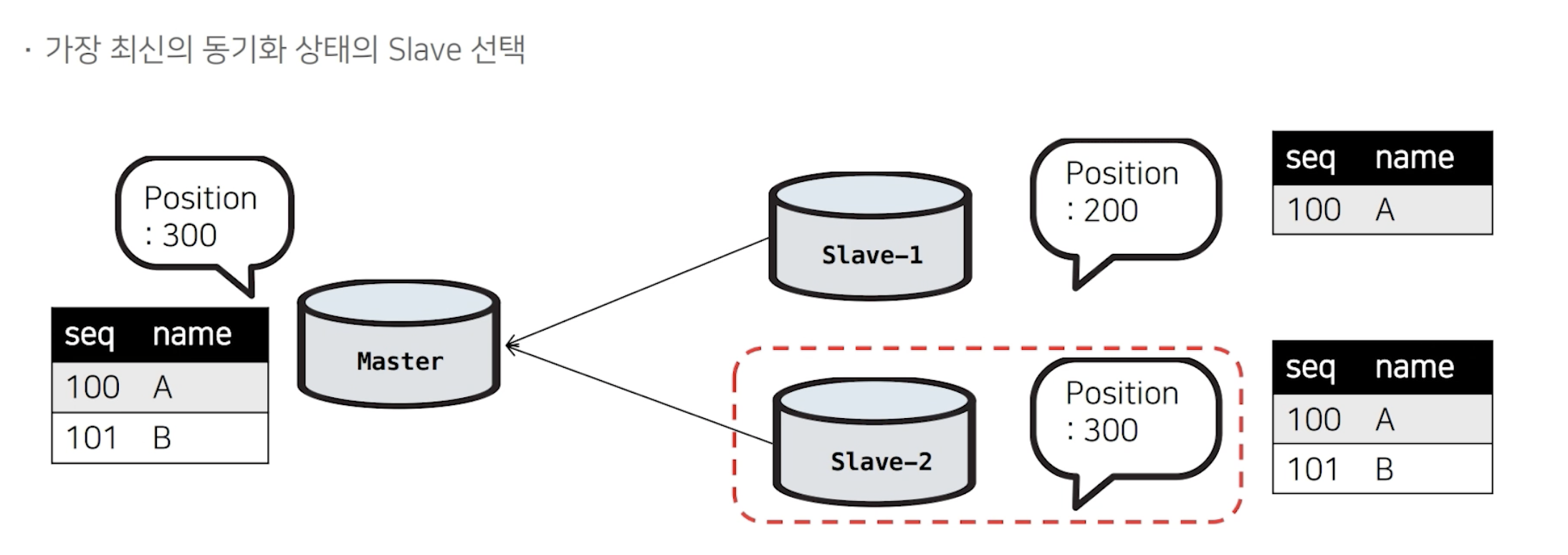
복제되는 DB 서버들을 확인해서 그 중 가장 최신 데이터를 가지고 있는 DB를 선택해서 신규 Master로 승격시킵니다. 위의 이미지에서 Master에는 101-B 데이터가 존재합니다. Master 장애 발생 시, slave-2에서는 101-B 가 존재, 즉 가장 최신의 데이터를 가지고 있기 때문에 신규 Master로 승격됩니다. 하지만 Slave-1에서는 101-B의 데이터가 유실되었기 때문에 복제깨짐 현상이 생길 수 있습니다.
MHA는 이 복제깨짐을 방지하기 위해서 별도의 절차를 거치게 됩니다.
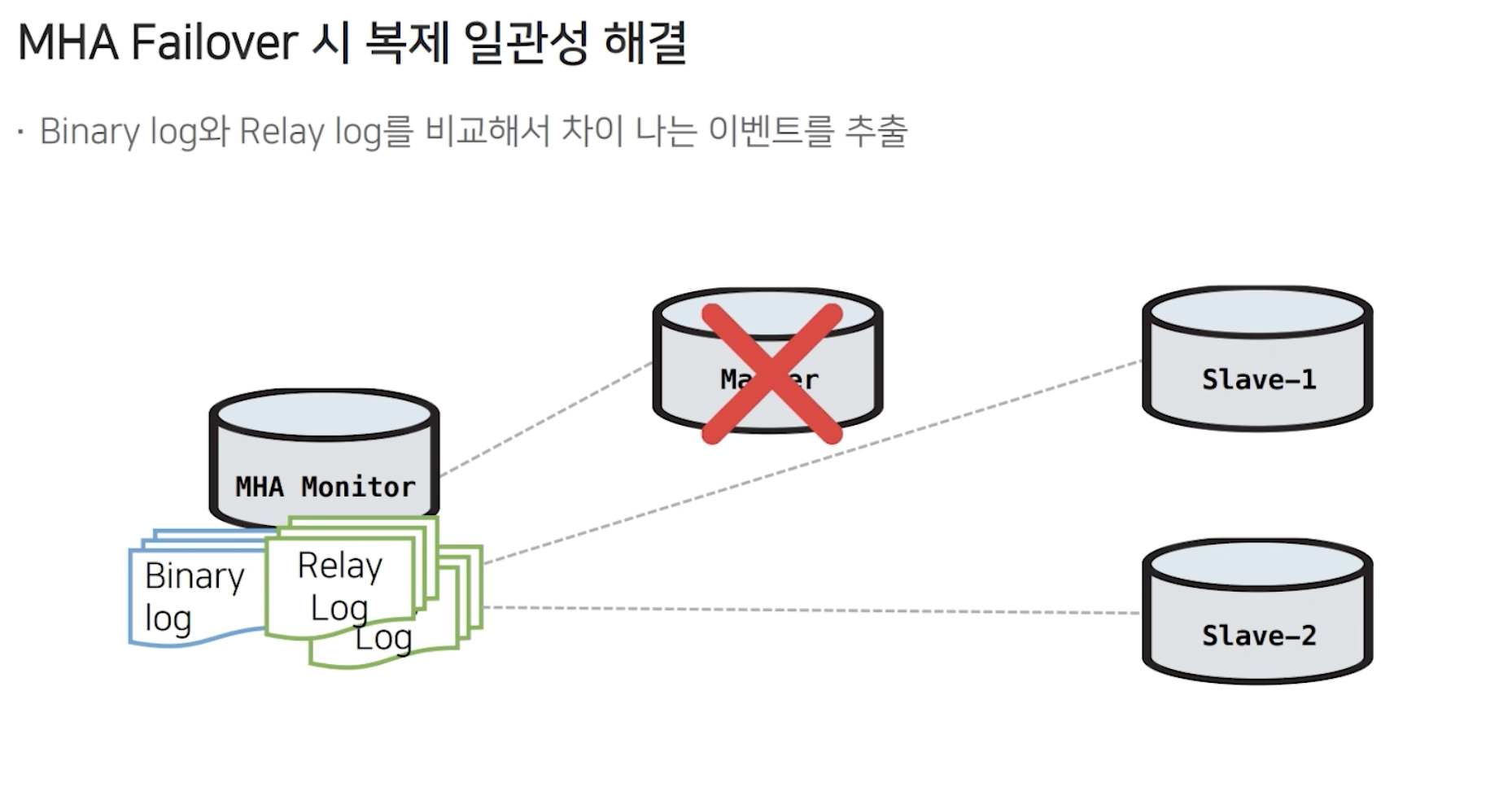
Failover 시, MHA Monitor는 Binary Log & Relay Log 를 가져와서 비교를 합니다. 이후 차이나는 이벤트를 추출합니다.
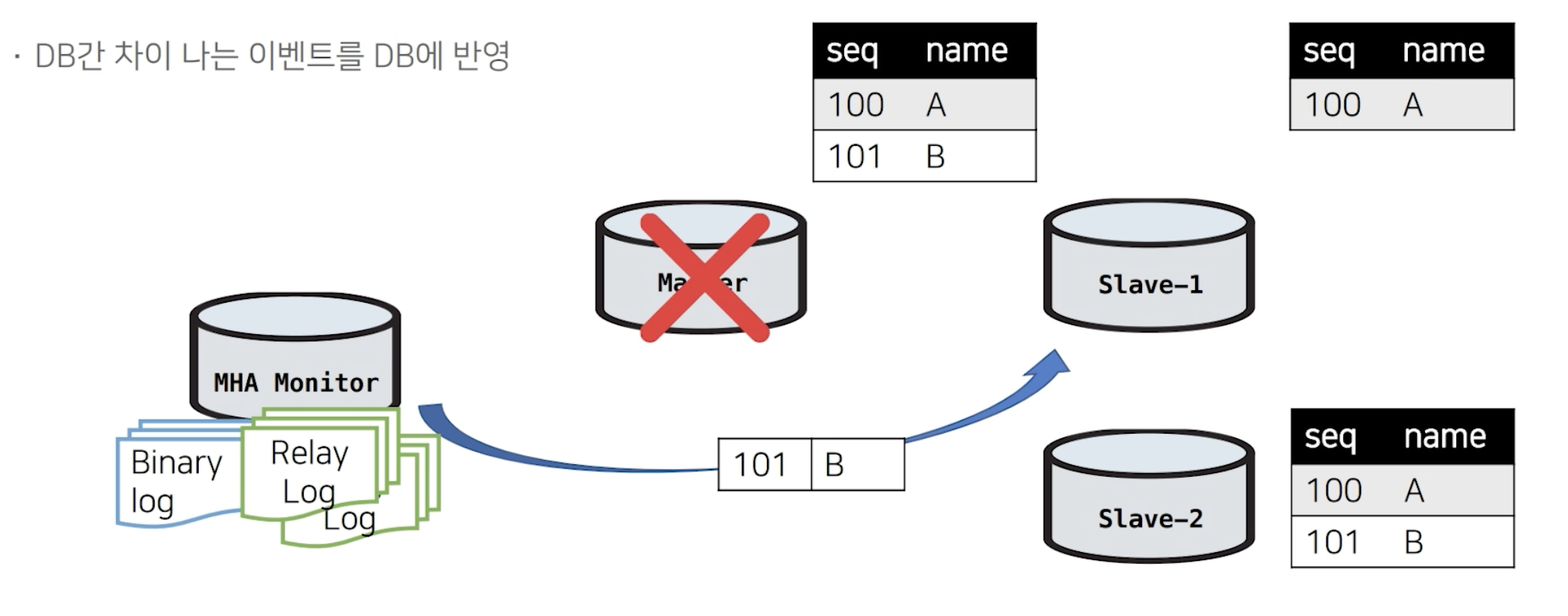
따라서 Slave-1 이 101-B 데이터가 유실되었기 때문에 차이나는 이벤트를 추출해서 Slave-1에 101-B 데이터를 적용해줍니다.
그 결과, DB간 복제 일관성을 유지할 수 있게 됩니다.
5) MHA 에서 필요한 기능(+이중화 운영 장애)
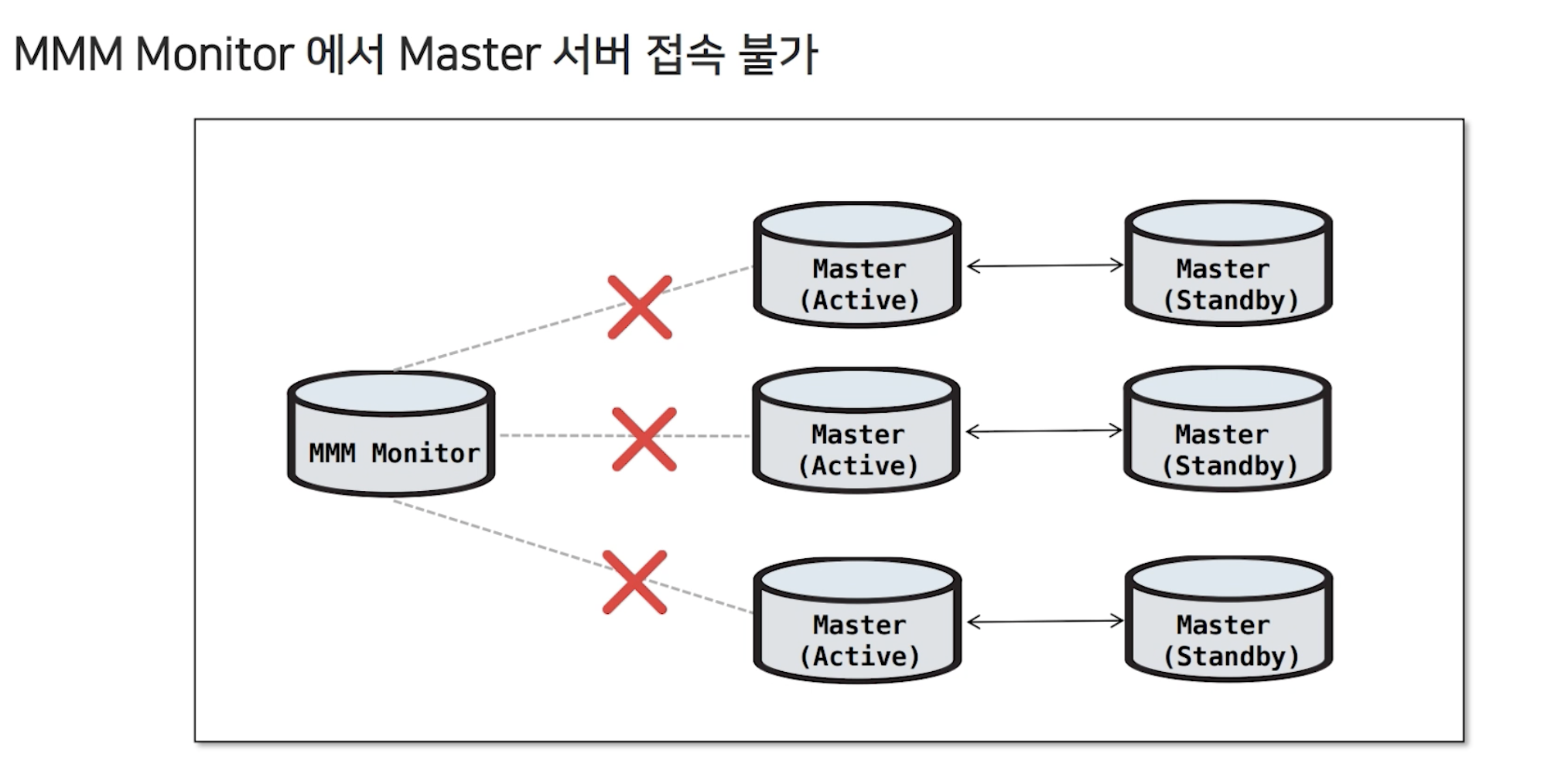
과거에 데이터운영팀이 겪었던 이중화 운영장애
네트워크 전면 장애로 인해 DB 서버에 접속할 수 없는 현상 발생 ▶️ 네트워크 장애 해결되면 해결될것으로 예상 ▶️ 네트워크 장애 해결되고 DB 서버에 접속 ▶️ 예상하지 못했던 결과 발생 ▶️ Master(Active)&Master(Standby) 가 잘 통신되고 있는데도 불구하고 장애가 발생되었다고 판단해 Failover를 실행
Failover 발생 과정은 앞쪽에 설명했던 것처럼 아래와 같습니다.
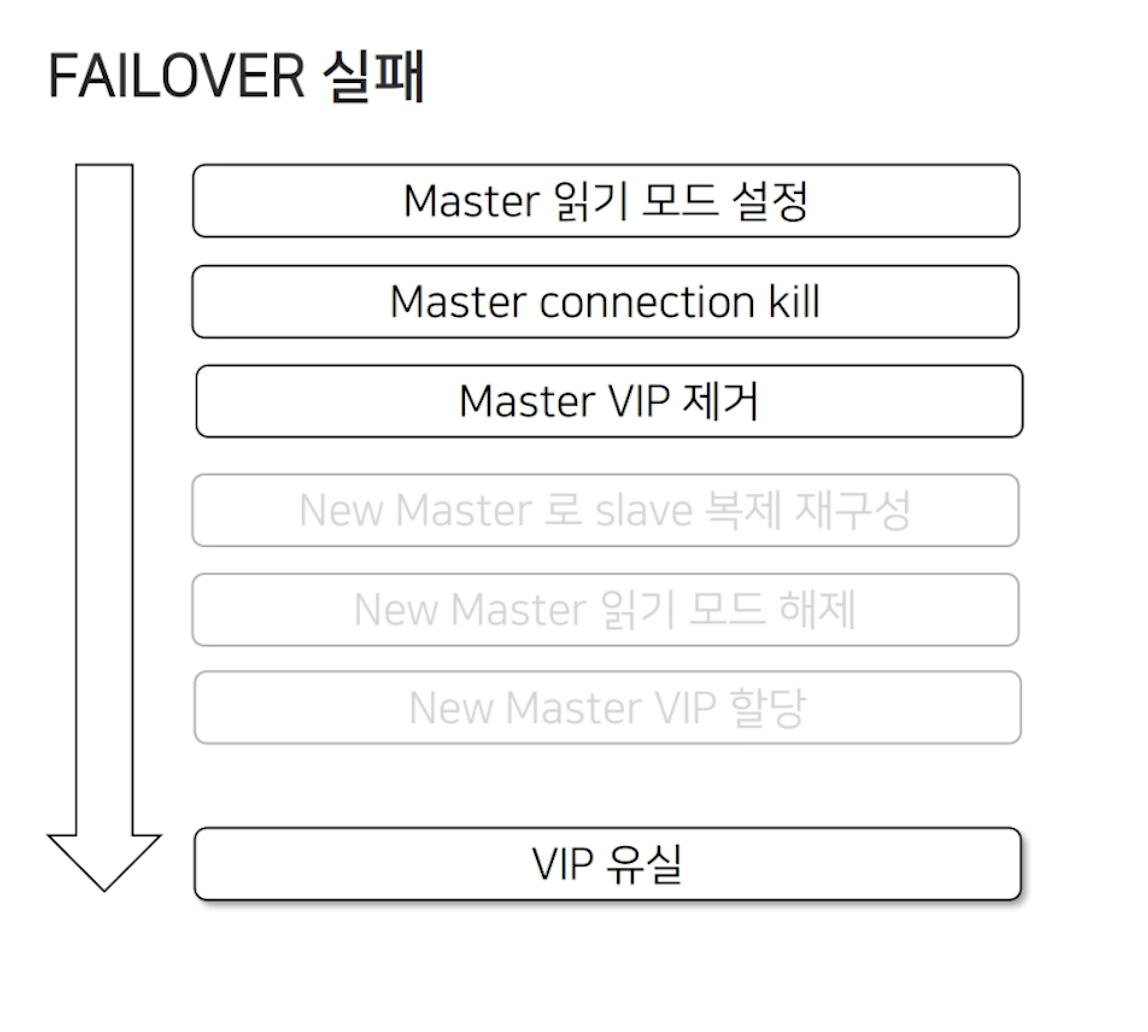
신규 Master에 접속이 되지 않아 VIP 가 유실되는 현상이 발생했습니다. 그 결과, Master(Active) & Master(Standby) 모두 VIP 가 유실되는 상황이 발생했습니다. 이 밖에도 agent가 hang이 걸리거나 VIP 중복 할당, 혹은 읽기모드가 해제되지 않는 등의 문제들이 발생했습니다. 추가적으로 복제깨짐 현상도 발생했습니다.
이렇게 네트워크 장애로 인해 DB 가 정상적임에도 불구하고 Failover가 발생했습니다. MHA 는 이를 방지하기 위해
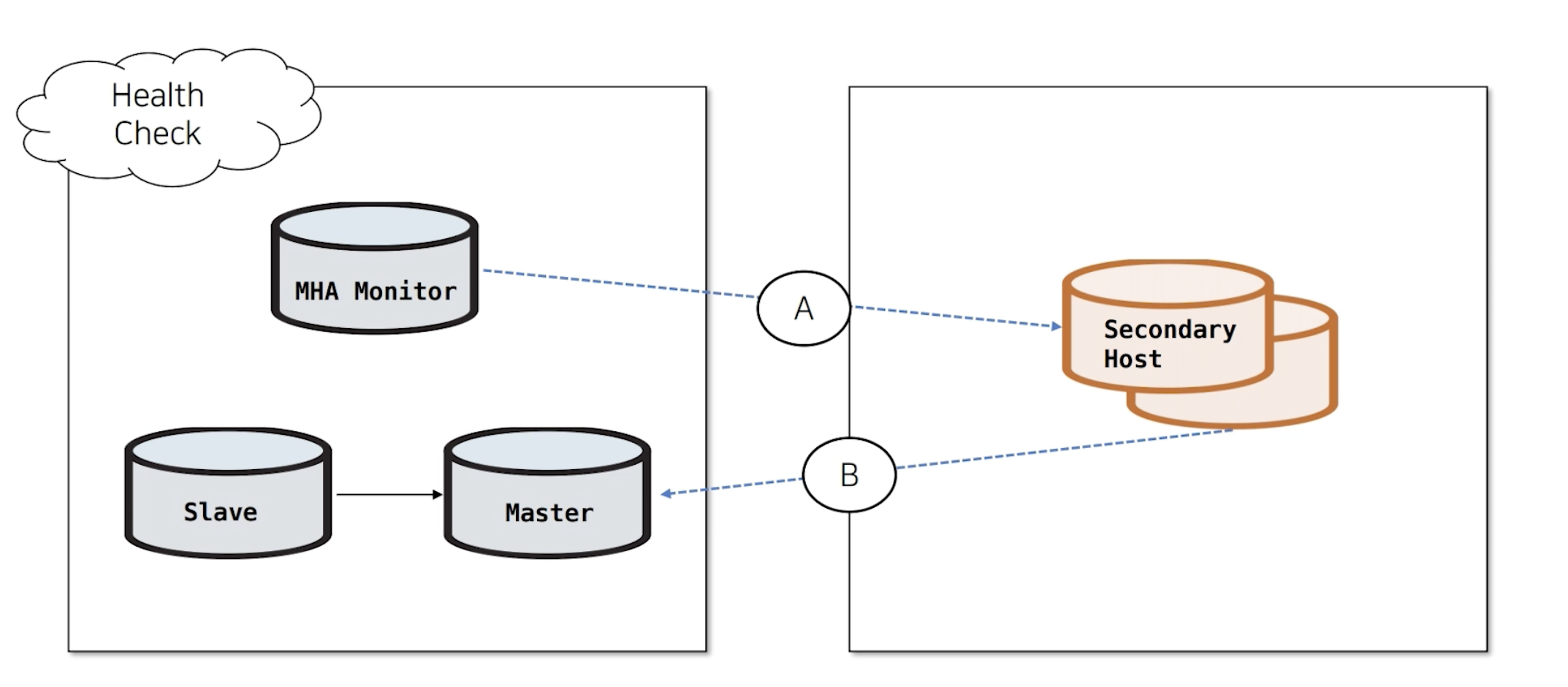
Secondary Check기능을 제공하고 있습니다.
먼저 우리가 사용하고 있는 DB 서버와 다른 네트워크의 서버를 지정합니다. 그 다른 네트워크의 서버를 Secondary Host라고 지정하겠습니다. A 구간과 B 구간의 통신을 확인해서실제 DB 서버에서 장애가 났는지네트워크 장애인지를 판단합니다.
항상 Secondary Check를 실행하는 것은 아니고 Master에 접속이 되지 않을때 MHA가 Failover를 실행할지의 여부를 판단하기 위해 Secondary Check를 실행하게 됩니다.
3가지 경우를 예시로 확인해보겠습니다.
위의 이미지와 같이 MHA Monitor에서 Master에 접속되지 않을때, A와 B 구간의 통신을 확인해서 DB 접속 장애임을 확인합니다. 그렇다면 Failover을 실행하게 됩니다.
하지만, 위의 이미지에서는 같이 MHA Monitor에서 Master에 접속되지 않을때, A와 B 구간의 통신을 확인해서 Secondary Host에서 DB 서버에 잘 접속됨을 확인합니다. DB 서버 문제가 아닌, MHA Monitor & Master 네트워크 장애임을 확인합니다. 그렇다면 Failover을 실행하지 않습니다.
위의 이미지와 같이 MHA Monitor에서 Master로 접속이 되지 않고 Secondary Host에도 접속이 되지 않기 때문에 왼쪽부분의 네트워크가 장애임을 판단합니다. 그렇다면 Failover을 실행하지 않습니다.
DB 이중화를 사용하면서 겪은 고민
VIP vs DNS
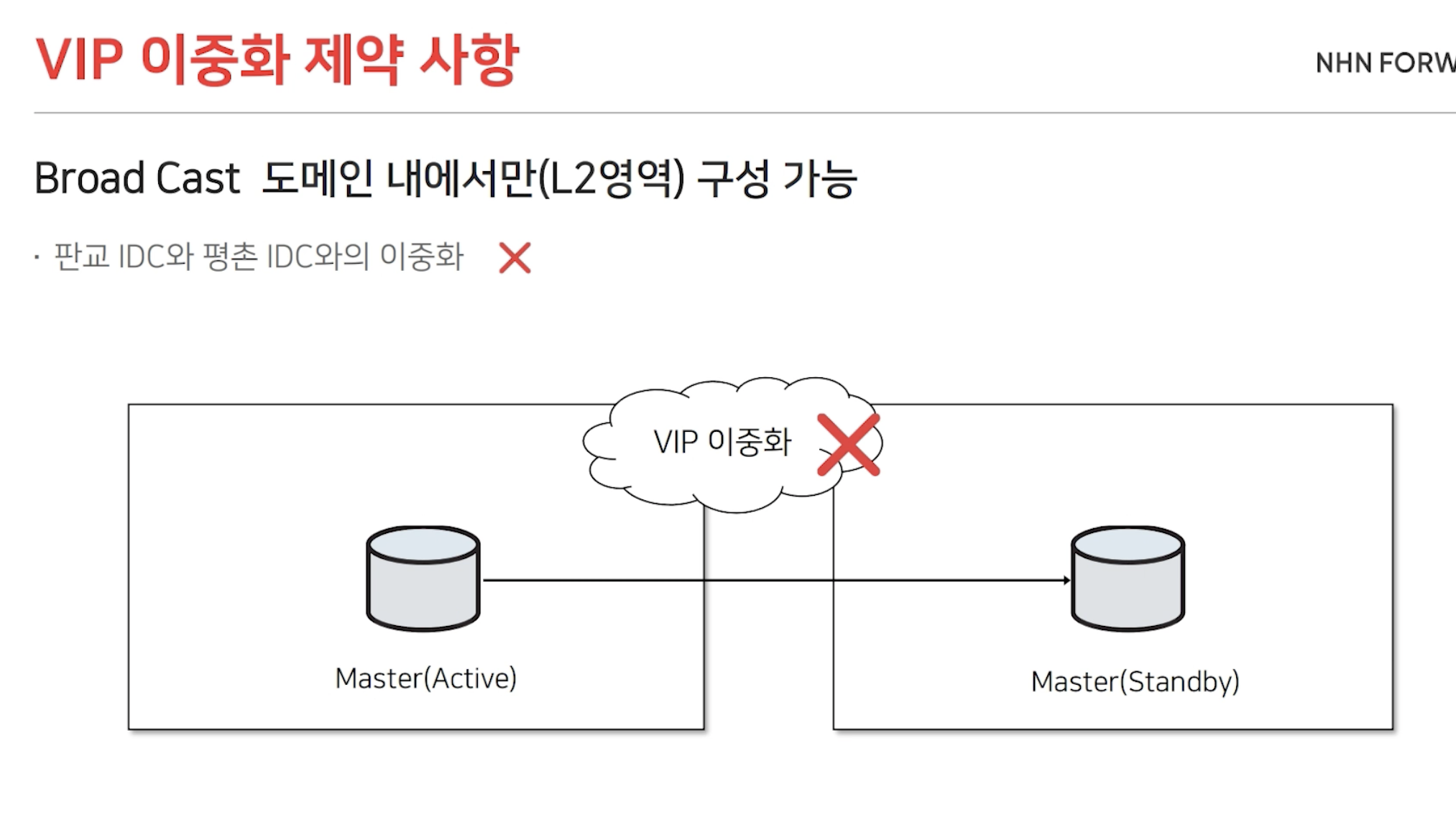
데이터 운영팀은 MMM + VIP 구성을 사용하고 있습니다. 하지만 이 구성은 Broad Cast 도메인 내에서만 구성 가능합니다. 따라서 다른 네트워크 대역에 이중화 구성이 가능하지 않았습니다. 따라서 DNS 도입을 고려하게 되었습니다.
DNS를 사용하게 되면서,
- DNS의 도메인 IP를 변경함으로써 다른 네트워크의 이중화가 가능
- 따라서 평촌IDC & 판교IDC 다른 네트워크 간의 이중화(HA) 구성이 가능
- 또한, Cloud 환경의 ZONE 간의 이중화(HA) 구성이 가능
=> 현재 토클(Toast RDS 상품) 구성이DNS + MHA가 된 이유 - DNS를 사용하면, 위에 언급했던 장애(VIP 중복할당 및 유실) 가 날 가능성이 없어졌습니다.(
이유 : DNS는 UPDATE 방식)
노을선임님의 2019년도 발표 에서는 현재 오랜기간 MMM+VIP 로 운영중인 서비스 중 몇몇을 MHA+DNS 구성으로 적용하고 있다고 하셨습니다.
저희 데이터운영팀의
레거시 서비스는MMM + VIP
Toast RDS 서비스는MHA + DNS
임을 확인할 수 있습니다.
DNS를 사용하면 무엇이 달라지나요?
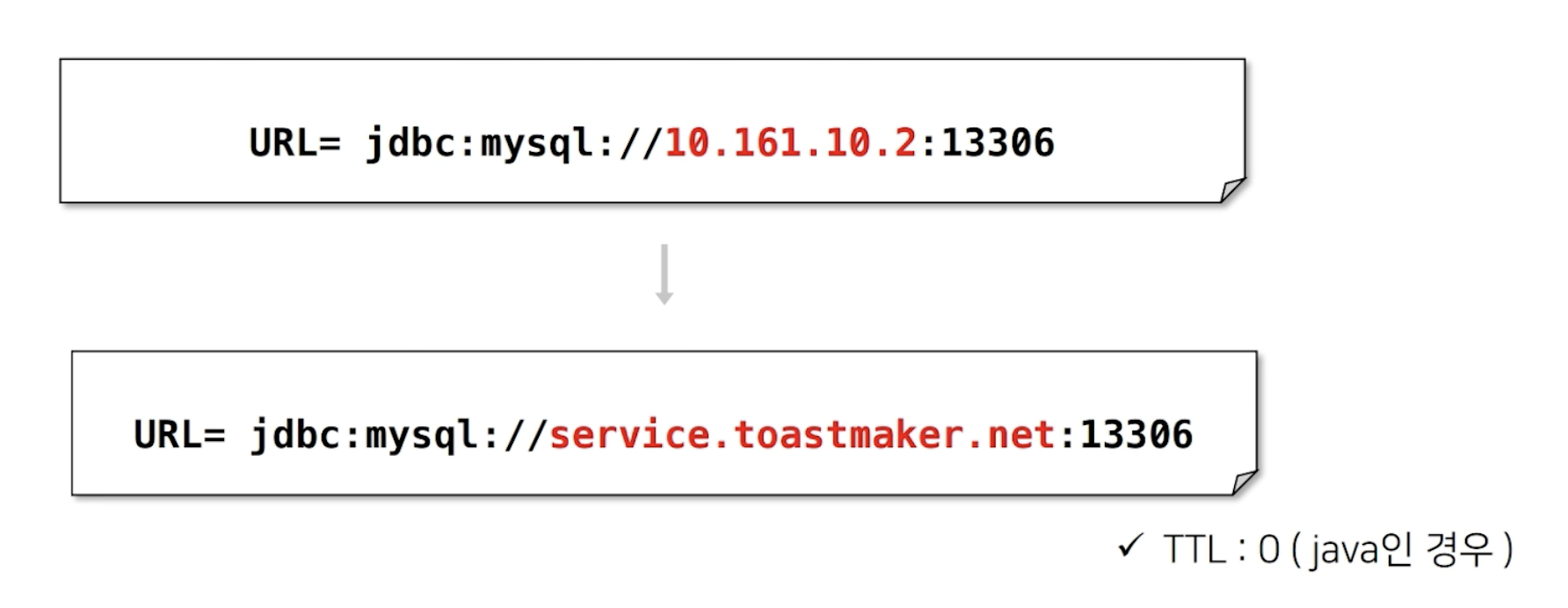
개발팀의 변경 사항 : 물리 IP => text로 된 DNS
DNS 사용의 단점
MMM+VIP의 경우 VIP를 추가하고 다른 서버들에게 IP가 변경되었다고 알리는 ARP 갱신이 0.01초로 빠르게 진행됩니다.
하지만 DNS를 사용했을 경우 일단 1. 캐싱 지연 가능성이 있고,2. DNS 변경 API 호출만 4~6초 정도 소요됩니다.
이렇게 시간이 조금 더 소요되는 것을 확인할 수 있습니다.
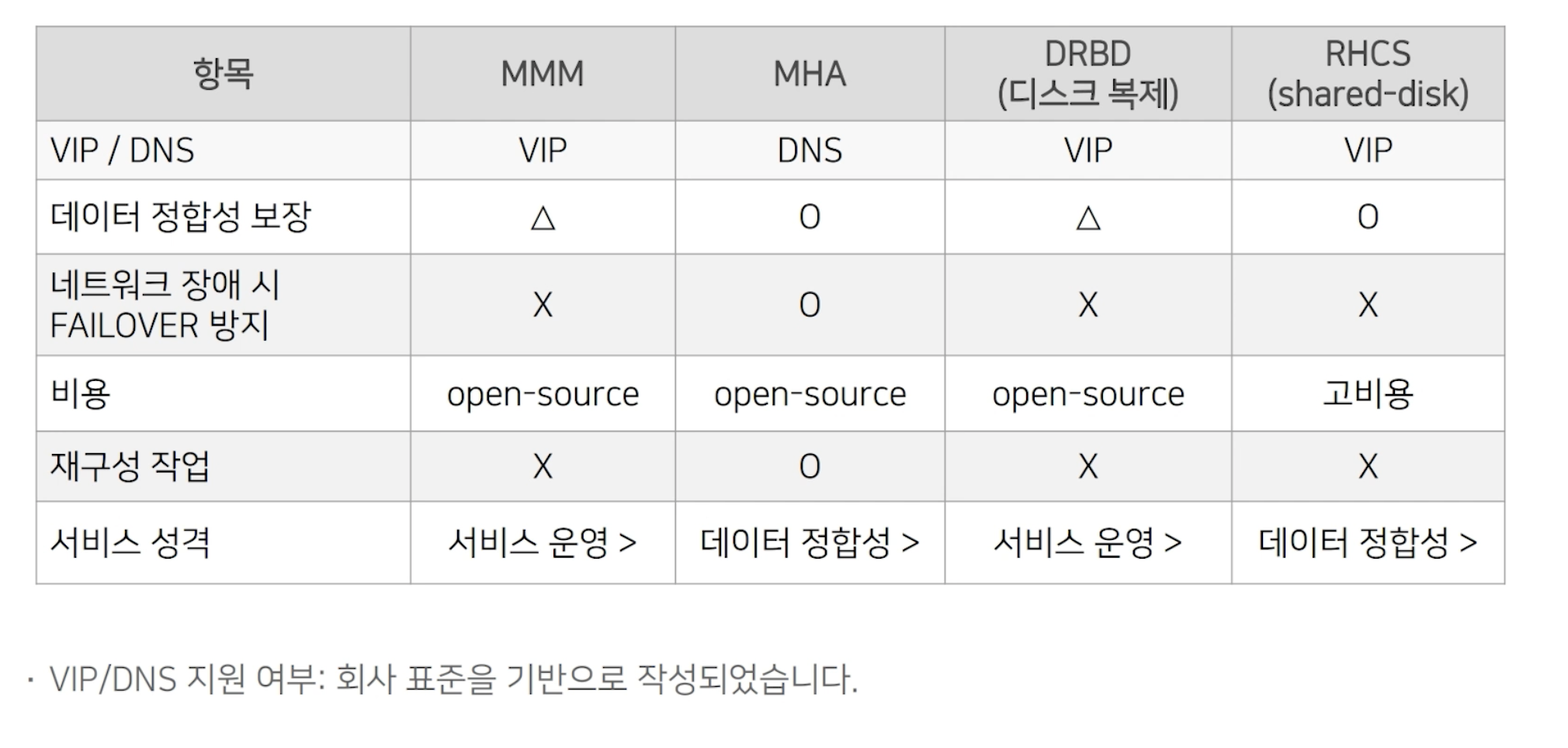
MySQL 이중화 비교 표
질문
1) MMM vs MHA 중 성능비교 및 선택은?
인턴기간 때, 네트워크 및 DB 이중화 리뷰를 진행한 적이 있습니다. 그때 MMM 과 MHA 를 비교했을 때 무엇이 성능이 더 좋을까? 라는 질문을 받았습니다.
그때에는 MMM보다 MHA가 성능이 좋을 것이다 라고 답변했습니다. 그 이유는 2개의 Master 서버는 성능이 떨어진다고 생각했고, 데이터정합성 면에서 복제 crash 가 생길 수 있는 MMM보다 MHA가 성능이 더 좋을 것이라고 생각했습니다.
혹시 MMM 보다 MHA가 성능이 좋은것이 맞나요? 그렇다면, 그 이유도 제가 생각한 이유가 맞을까요?
운영중인 레거시 서비스는 MMM, Toast for rds(토클) 서비스는 MHA 로 구성되어있다고 알고 있습니다. 그렇다면 서비스별로 이중화 구성을 구분되게 구성한 이유가 있을까요?
1) 질문의 답변
성능이 더 좋다 나쁘다를 따질 수는 없습니다. 각자의 장단점이 존재하고, mmm보다 mha가 최신버전이기 때문에 사용할 수 있는 기능이 좀 더 많다고 합니다.
- MMM 레거시 서비스는 그냥 네이버때부터 오래동안 사용해온것이기 때문에, 또 failover(?)(복구 작업관련)의 편리성을 위해서 계속 사용하고 있음
- MMM 레거시 서비스는 mmm monitor 따로 전용서버에 구성
(보통 mmm이든 mha는 디비서버가 아닌 monitor전용별도서버에 구성(기본))- Mha rds 상품은 사용자들이 편리하게 디비상품을 구성하고 db를 사용할 수 있게 하는 상품임 (직접 개발에 참여해서 쿼리 등 가이드 주고 하셨다고 합니다)
- Mha rds 상품은 monitor를 별도 구성하면 monitor서버도 과금에 책정돼서 요금을 줄이려고 candidate master 에 구성(사용자들의 비용감소)
-> monitor/master/slave 3개 있으면 비용이 너무 많이 나온다.
-> Master와 Candidate Master 두대로 구성. 서로 다른 AZ 에 생성된다.
-> Candidate Master에만 MHA Monitor 프로세스를 띄운다.
-> Console에는 Master 접속 정보만 보여주고, Candidate Master는 백업 및 faiover시에만 사용한다.
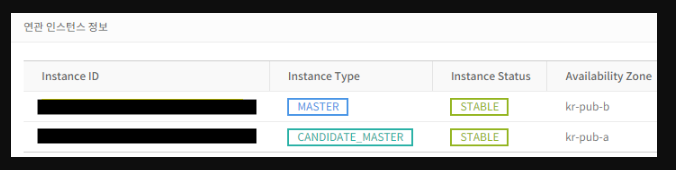
2) Candidate Master 는 어떤 DB를 말하는 건가요?
Toast for RDS 상품은 MHA 이중화 구성으로 이루어져 있다고 배웠습니다. MHA 구성은 MMM 구성과 달리 Failover 대상이 지정되어있지 않습니다. 복제되는 Slave DB 서버들을 확인해서 그 중 가장 최신 데이터를 가지고 있는 DB를 선택해서 신규 Master로 승격시킵니다.
NHN Toast - RDS for MySQL 개요 를 보면 Candidate Master란, "Candidate Master는 고가용성 기능을 사용했을 때, 장애를 대비해 Master와 서로 다른 Availability Zone에 만들어 놓은 장애 대비용 인스턴스입니다." 라고 설명되어 있습니다.
그렇다면, Slave DB 중 하나를 장애 대비용 인스턴스로 지정해서 Master와 서로 다른 가용공간에 위치시키고 실시간으로 복제를 진행하는 건가요?
아니면, MMM 과 같이 Master(Standby) 서버를 서로 다른 가용공간에 위치시키고 실시간으로 복제를 진행하는 건가요?
2) 질문의 답변
MHA rds 상품에서 Candidate master는 다른 가용성영역에 두는 지정 slave(master가 될수 있는)입니다. 그렇기 때문에 master 2대가 다 죽더라도 다른 slave가 master가 되는 일은 없습니다. mmm처럼 master 2대 다 지정인것이죠.(2대 다 죽으면 failover 발생 안함)
mmm 특성을 가지고 있는 mha 구성,,이라고 이해했습니다.

MMM 구성에 standby master를 read only 로 설정하면 MHA와 동일한 단방향 복제일텐데
굳이 양방향 복제라고 쓰여진 이유는
failover 이후 승격된 master (기존의 standby) 에서 과거 master ( 기존의 active) 로
복제되기때문에 양방향 복제라고 쓰여진 것인가요?
아니면 readonly 를 무시하고 양쪽에 write를 할 수 있어서 양방향 복제인것인가요?