🤚 전체적인 진행과정과 실습, 일부 내용은 핸즈온 머신러닝(2판), 한빛미디어 를 참고했다. 이 장에서의 목표는 캘리포니아의 인구조사 데이터를 사용해 주택가격 모델을 만드는 것이다.
colab 실습 주소 : https://colab.research.google.com/github/rickiepark/handson-ml2/blob/master/02_end_to_end_machine_learning_project.ipynb
데이터 저장소
머신러닝을 배울 때는 인공적으로 만들어진 데이터셋이 아닌 실제 데이터로 실험해보는 것이 가장 좋다.
아래의 목록은 여러 분야에 걸친 공개된 데이터셋을 얻을 수 있는 홈페이지들이다.
- 유명한 공개 데이터 저장소
- UC Irvine 머신러닝 저장소 (http://archive.ics.uci.edu/ml/)
- Kaggle Dataset (http://www.kaggle.com/datasets)
- Amazon AWS Dataset (http://aws.amazon.com/ko/datasets)
- 메타 포털(공개데이터 저장소가 나열되어있음)
- 데이터포털 (http://dataportals.org/)
- 인기 있는 공개데이터 저장소가 나열되어 있는 다른 페이지
- Wiki Dic. (https://goo.gl/SJHN2k)
- Quora.com (https://www.quora.com/Where-can-I-find-large-datasets-open-to-the-public)
- Dataset Subreddit (http://www.reddit.com/r/datasets)
이 장에서는 데이터 실습으로 StatLib 저장소에 있는 캘리포니아 주택 가격 (California Housing Prices) 데이터셋을 사용할 예정이다. 1990년 캘리포니아 인구조사 데이터를 기반으로 하고 있다.
개발환경 세팅하기 💻
파이썬 설치
데이터를 가져오기 전에 먼저 파이썬이 설치되어 있어야 한다.
머신 러닝 실습을 하기 위해서는 많은 패키지가 필요하는데, 이를 일일히 설치하는 것보다는 필요한 패키지들을 모아놓은 파이썬 배포판 아나콘다를 설치하는 것을 권장한다. 👍
아나콘다는 Numpy, Pandas, Jupyter Notebook, IPython, scikit-learn, matplotlib, seaborn, nltk 등 이 책에서 사용할 대부분의 패키지를 전부 포함하고 있다.
설치가 되었다면 python --version을 실행시켜서 파이썬 버전이 제대로 나오는지 확인해본다.
pip, pip3, conda
pip는 파이썬으로 작성된 패키지 소프트웨어를 설치 · 관리하는 패키지 관리 시스템이다. 참고로 자바스크립트에서 npm이랑 거의 같다고 보면 된다. Python Package Index (PyPI)에서 많은 파이썬 패키지를 볼 수 있다. 파이썬 2.7.9 이후 버전과 파이썬 3.4 이후 버전은 pip를 기본적으로 포함한다.
pip의 주요 장점은 명령 줄 인터페이스에서의 쉬운 사용이다. 파이썬 소프트웨어 패키지를 한 번의 명령어 실행으로 설치할 수 있다.
pip install some-package-name패키지 제거 또한 쉽게 실행할 수 있다.
pip uninstall some-package-name근데 간혹 보다보면 pip도 있고 pip3도 있고 conda로도 패키지를 설치하기도 한다. 도대체 이들의 차이는 무엇일까? 🤔 정리해보면 아래와 같다.
- pip : anaconda3 에서 관리하고 있는 전역 pip
- pip2 : local 내에 깔린 pip2 (python2 버전)
- pip3 : local 내에 깔린 pip3 (python3 버전)
중요한 점은 일반적으로 원하는 패키지를 현재 환경에만 설치하기 위해, conda install 혹은 pip install 로 설치해야 한다. (둘 중 아무거나 쓰면 되는 거 됨)
저는 아나콘다만 설치해서 그런지 pip2, pip3는 버전이 뜨지 않는다.

가상환경
파이썬에는 또한 가상환경이라는 개념이 존재한다. 예를 들어 A프로젝트를 진행하는데는 a, b라는 라이브러리가 필요해서 설치했다고 해보자. 얼마 있다가 A프로젝트가 끝나서 B프로젝트를 시작하는데 이번에는 전혀 다른 c, d라는 라이브러리가 필요하는 상황이다.
결국 이렇게 계속 라이브러리를 설치하다보면 A프로젝트에서는 어떤 라이브러리가 필요했었는지, B프로젝트에서는 어떤 라이브러리가 필요했었는지 모르게 된다 😢
따라서 파이썬은 하나의 컴퓨터안에서도 가상으로 환경을 나눠서 서로 다른 개발환경을 갖도록 해주어 프로젝트간 충돌 및 기타 리스크를 최소화하는 기능을 제공한다.
codna 가상 환경 세팅하기
$ conda create --name(혹은 -n) <가상환경이름> <설치할 파이썬 버전>예시 : conda create -n py36 python=3.7.6
가상환경 목록 보기
$ conda info --envs가상환경 시작/종료
$ activate 가상환경이름
$ conda deactivate가상환경에 패키지 설치
// 방법1. 가상환경 생성과 동시에 패키지 설치
$ conda create -n 가상환경이름 python=버전 패키지이름
// 방법2. 가상환경을 활성화 시킨 후, 그 내부에서 pip install 실행
$ pip install 패키지 이름가상환경에 설치된 패키지 리스트
$ conda list // 현재 환경의 설치된 리스트
$ conda list -n 가상환경이름가상환경 제거
$ conda env remove -n 가상환경이름 --all--all 옵션을 사용해야 가상환경에 설치했던 모든 패키지들도 함께 제거됨
파이참 통합개발환경(IDE)
파이썬 개발에 가장 널리 사용되는 통합 개발 환경이다. Professional 버전과 Community 버전이 있는데 Community 버전은 무료로 사용할 수 있다.
PyCharm 특징
- 프로젝트별로 Python 버전 및 환경을 선택할 수 있다.
- 코드의 실행 결과를 바로 확인할 수 있다.
- 직관적인 UI를 제공하며 OS와 무관하게 사용 가능
PyCharm Setting
설치는 건너뛰고 세팅에 대해서만 설명하겠다.
File > Settings에 들어가면 세팅화면이 나온다. 그중에서 중요한것은 Project에서 Python Interpreter이다.
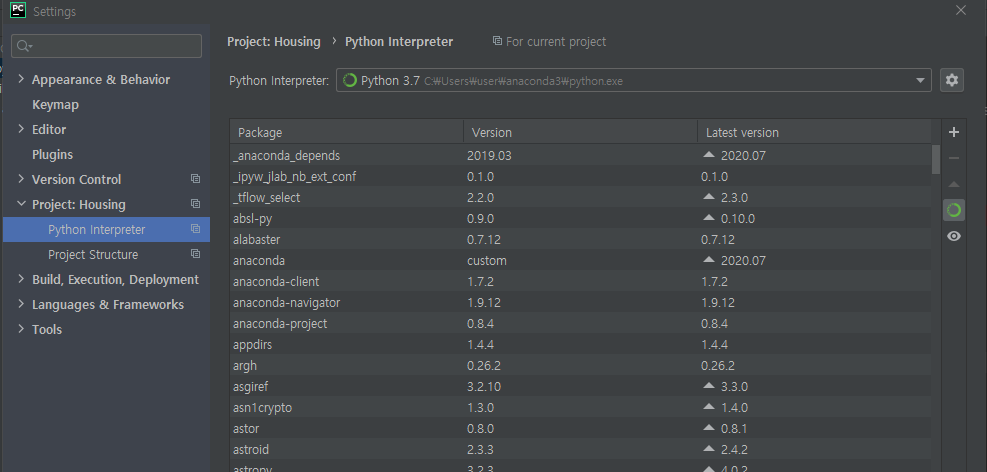
기본적으로는 아나콘다를 통해 설치한 Python을 인터프리터로 설정한 다음 파이썬 코드를 실행하면 동작합니다.
하지만 가상환경을 이용해보고 싶다면 어떻게 할까요? 일단 아래처럼 Show All을 클릭합니다.
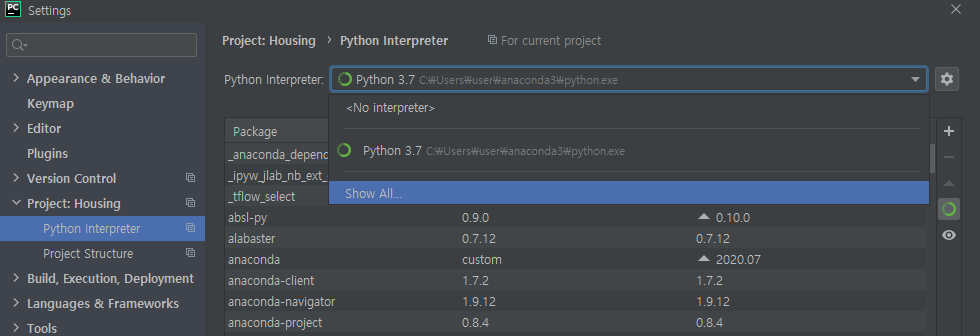
그다음에는 + 를 클릭하고, Conda Environment 클릭 후 Existing environment을 체크합니다.
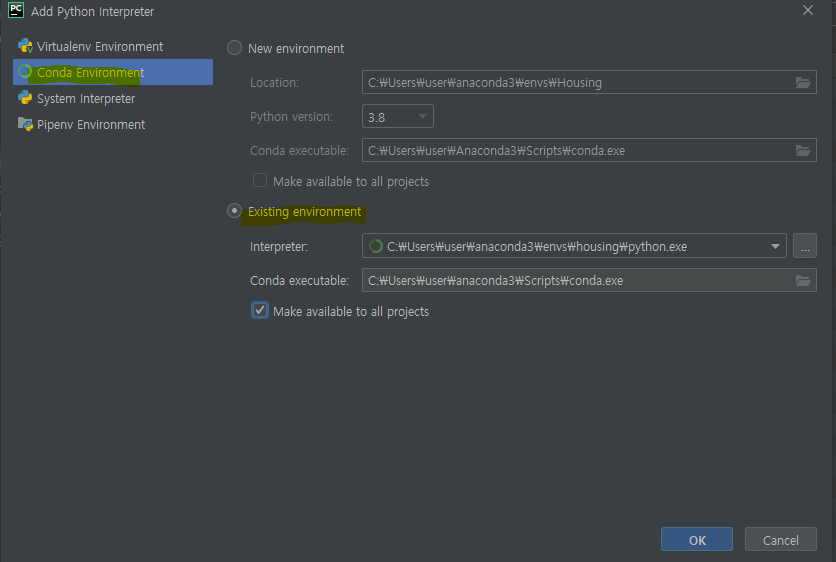
저희가 만든 가상환경 인터프리터를 찾아서 세팅해줍니다. 이때 경로는 아나콘다가 설치된 폴더의 envs\자신이 생성한 가상환경 이름\python.exe 입니다.
모든 프로젝트에 적용 클릭(후에 다른 환경을 사용하고 싶으면 프로젝트 내부에서 바꿀 수 있습니다).
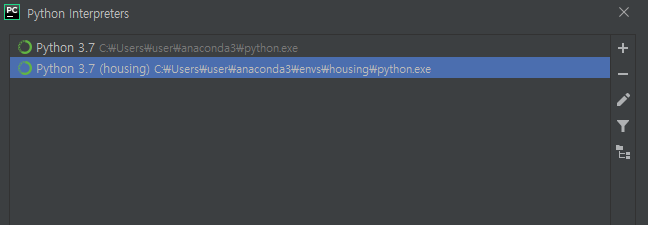
이렇게 세팅이 끝나면 파이썬 인터프리터가 기본말고도 가상환경 하나가 더 생기게 됩니다. 그리고 프로젝트 인터프리터를 이걸로 바꿔주면...
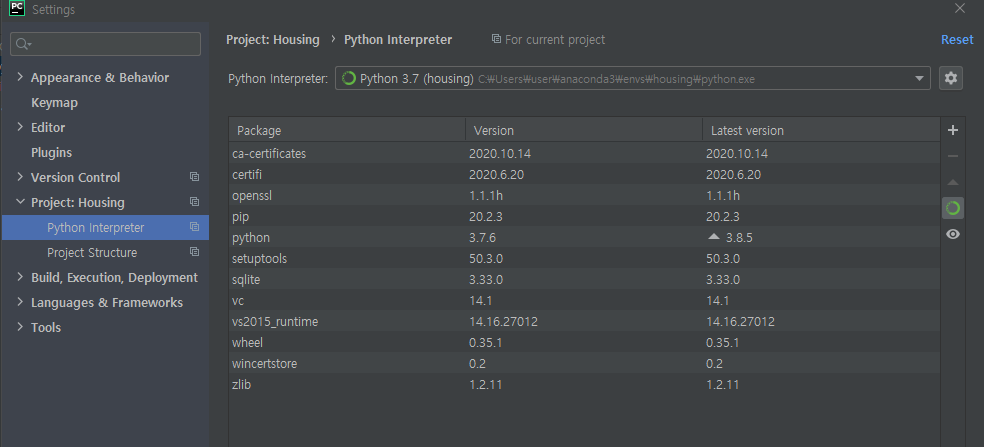
최종적으로 가상환경을 이용할 수 있다!! 💖
코랩(colab) 사용하기
위와 같이 로컬에서 개발환경을 세팅하기 귀찮거나 그렇게 할 수 없는 상황이라면 간단하게 코랩을 사용하면 된다.
사용법에 관해서 따로 velog에 정리해놨으니 찾아서 확인해보면 된다.
본격적으로 시작하기에 앞서
문제정의
우리가 하려고자 하는 문제와 목표가 무엇인지 먼저 정해보도록 하겠습니다. 🤔
- 목적 : 캘리포니아 인구조사 데이터를 사용해 캘리포니아의 주택가격 모델을 만든다.
- 문제 : 구역의 중간주택가격에 대한 예측을 전문가가 수동으로 추정한다면 복잡한 규칙과 비용, 시간이 많이 든다. 따라서 회사는 구역의 데이터를 기반으로 중간 주택 가격을 예측하는 모델을 훈련시키는 쪽이 유용하다고 판단할 수 있다.
그렇다면 이는 지도학습, 비지도학습, 강화 학습 중 무엇일까요? 🙋♂️
👉 레이블된 훈련샘플이 있으니 이는 정형적인 지도학습 작업이며, 또한 값을 예측해야 하므로 회귀문제입니다. 더 구체적으로는 예측에 사용할 특성이 여러개(구역의 인구수, 중간 소득 등)이므로 다중 회귀 문제입니다.
성능 측정 지표 선택
회귀 문제의 전형적인 성능 지표는 평균 제곱근 오차(root mean square error, RMSE)이다. 오차가 커질수록 이 값은 더욱 커지므로 예측에 얼마나 많은 오류가 있는지 가늠하게 해준다.
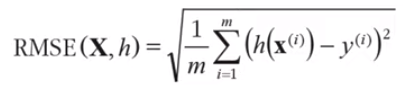
- 은 측정할 데이터셋에 있는 샘플 수
- 는 데이터셋에 있는 i번째 샘플의 전체 특성값 벡터
- 는 해당 샘플의 기대 출력값이다
- 는 데이터셋에 있는 모든 샘플의 모든 특성값을 포함하는 행렬이다. 샘플 하나가 하나의 행을 의미
- 는 시스템의 예측함수이며 가설이라고도 한다.
- 는 가설 h를 이용하여 일련의 샘플을 평가하는 비용함수

RMSE가 일반적으로 회귀문제에서 선호되는 방법이긴 하지만 다른 함수를 사용할 수도 있다. 예를 들어 이상치로 보이는 구역이 많다고 가정하면 평균 절대 오차(mean absolute error)를 고려해볼 수도 있을 것이다.
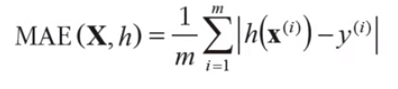
데이터 가져오기
데이터 실습으로 StatLib 저장소에 있는 캘리포니아 주택 가격 (California Housing Prices) 데이터셋을 가져와보도록 한 다음 마치도록 하겠다.
캐글에서 캘리포니아 housing prices CSV파일을 다운받는다. (🔎주소). 다운 받은 파일은 압축을 풀고 프로젝트 안에 datasets 폴더를 생성 후 여기로 옮겨준다.
한번 CSV 파일을 열어볼까?
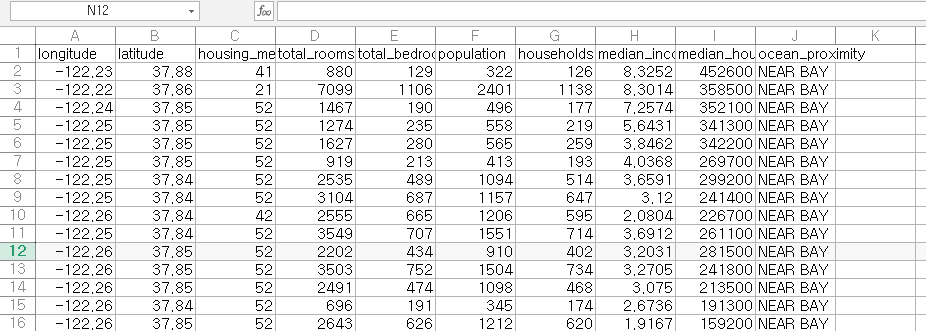
각 변수 설명에 대해 설명하자면 다음과 같다.
- longitude : 경도
- latitude : 위도
- housing_median_age : 주택 나이 (중앙값)
- total_rooms : 전체 방 수
- total_bedrooms : 전체 침실 수
- population : 인구
- households : 세대
- median_income : 소득(중앙값)
- median_house_value : 주택 가치(중앙값)
- ocean_proximity : 바다 근접도
판다스를 사용하여 데이터를 읽어와서 데이터프레임을 반환하는 간단한 함수를 만듭니다. 참고로 저는 윈도우를 쓰고 있다. 그리고 파이참을 쓰고 있죠. 그래서 책이랑 좀 다를수있다.
import pandas as pd
import os
HOUSING_PATH = os.path.join("datasets") # ./datasets 경로
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path, "housing.csv") # ./datasets/housing.csv
return pd.read_csv(csv_path) # pandas로 외부 파일 읽는 방법
housing = load_housing_data()
print(housing.head()) # 상위 5개만 출력
마침
오늘은 여기서 마치도록 하겠다. 다음시간에는 이어서 다운받은 데이터에 대해 더 알아보고 시각화하를 해서 분석해본다음, 훈련용과 테스트용으로 나눠보도록 하겠다.
References
- 핸즈온 머신러닝(2판) 도서
- 위키피디아 pip : https://ko.wikipedia.org/wiki/Pip_(%ED%8C%A8%ED%82%A4%EC%A7%80_%EA%B4%80%EB%A6%AC%EC%9E%90)
- pip3? pip? 및 conda 내 pip 정리 : https://dailyheumsi.tistory.com/33 ★★★★
- 아나콘다 가상환경 설정 및 PyQt5 설치 : https://bradbury.tistory.com/62 ★★★★
- 파이참(PyCharm) 설치 및 아나콘다 가상환경 적용 : https://bradbury.tistory.com/63 ★★★★★
- [ML] 머신러닝을 위한 데이터 가져오기 : https://stickie.tistory.com/51?category=746224
