
본 글은 Udemy에서 Node JS: Advanced Concepts 강의를 듣고 정리한 글입니다.
![]()
Improving Node Performance
이번시간에는 NodeJS 성능 향상 방법에 대해 알아본다. 향상 방법에는 크게 2가지가 있다.
- Use Node in 'Cluster' Mode : 클러스터 모드란 서버를 실행하는 NodeJS의 여러 복사본을 만들어서 실행하는 방식을 말한다. 그것은 일종의 다중 스레드 방식으로 만드는 것과 유사한 방식이다.
- Use Worker Threads : 우리의 앱 내부에서도 Worker Thread를 이용해서 많은 성능 작업을 하게 만든다. 즉 libuv를 사용해 쓰레드 풀을 사용하는 Worker Thread를 이용하는 방식
클러스터 모드에서 많은 무거운 계산을 처리할 수 있고 애플리케이션 성능을 향상시키기 위한 매우 잘 테스트된 절차이고 추천하는 방식이다. 워커 쓰레드 기술을 적용하여 성능을 향상시키려면 그 전에 클러스터 모드를 먼저 알아보고 익숙해졌을때 이 접근 방식을 확인하는 편이 좋다.
따라서 이번시간에는 첫번째 Cluster 에 대해 알아보도록 하겟다.
Express Setup
Express 모듈을 설치하고, 3000번 포트로 서버를 돌려보자.
const express = require('express');
const app = express();
app.get('/', (req, res) => {
res.send('Hi there');
});
app.listen(3000);이제 우리는 이 파일을 자주 변경할 것이다. 보통은 nodemon을 설치해 이 프로세스를 종료되지 않고 코드를 수정하면 바로 반영되게 할 것이다. 그러나 기본적으로 nodemon은 군집화(=클러스터링)에는 잘 작동하지 않는다. 그래서 우리는 nodemon을 사용하지 않을 것이다.
Blocking the Event Loop
이벤트 루프는 우리의 서버에 요청이 들어올때마다 그 안(Single Thread)에서 처리된다.
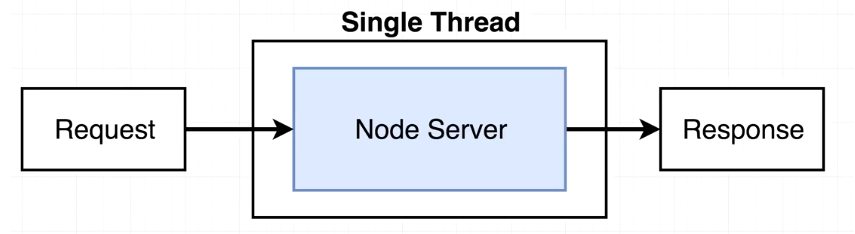
하지만 여기 들어오는 요청들이 처리시간이 많이 걸리는 작업이라면 어떻게 될까? 예를들어 다음과 같이 5초동안 blocking하면 어떨까? 결국에는 또 다른 일을 처리하지 못하는 사태가 벌어지게 된다.
const express = require('express');
const app = express();
function doWordk(duration) {
const start = Date.now();
// duration동안 while루프
while (Date.now() - start < duration) {
}
}
app.get('/', (req, res) => {
// 이 코드는 이벤트 루프에서 처리된다.
// 결국 또다른 req를 처리하지 못하며, 데이터베이스나 파일처리도 못할 것이다.
doWordk(5000);
res.send('Hi there');
});
app.listen(3000);사용자가 2명이라는 가정하에 브라우저 탭을 2개 띄어놓고 실행해보면 한개는 5s, 나머지 한개는 무려 10s가량 걸리게 된다.
Clustering in Theory
위 예제처럼 NodeJS가 일을 처리한다면 사용자 불만이 많을 것이다. 따라서 우리는 클러스터를 사용해서 우리의 한 컴퓨터안에 여러 노드 프로세스를 시작할 것이다.
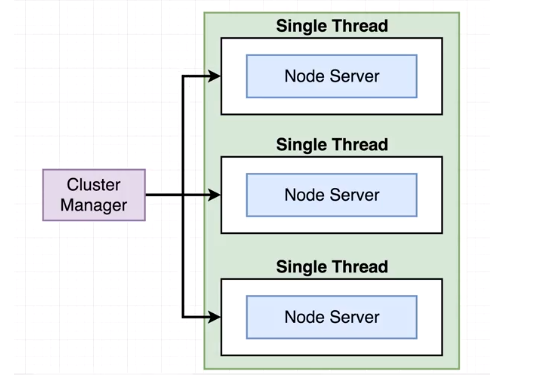
항상 하나의 상위 프로세스 또는 클러스터라고하는 하나의 과중한 프로세스가 있다. 클러스터는 동시에 컴퓨터에서 실행할 응용 프로그램 개별 인스턴스의 상태를 모니터링할 책임이 있다.
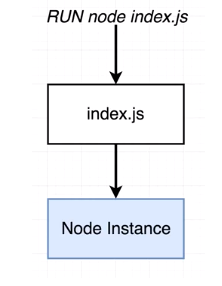
Not Clustering vs. Clustering
경우 1. Not Clustering
경우 2. Clustering
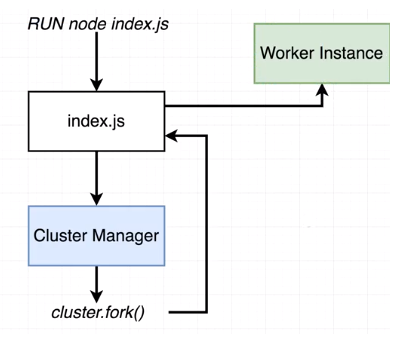
index.js를 실행했을때 첫번째 노드의 인스턴스는 클러스터 매니저가 된다. 클러스터 매니저는 fork라는 특정한 기능이 있는데 우리가 fork 기능을 호출하면 index.js 파일로 돌아가서 워커 인스턴스 작업이 시작된다. fork를 여러번 호출하면 워커 인스턴스가 여러개 생성될 것이다.
Clustering in Action
클러스터링을 하는 코드는 다음과 같다.
const cluster = require('cluster');
console.log(cluster.isMaster); // 처음에는 true, 두번째는 fals
if (cluster.isMaster) {
// cause index.js to be executed again but
// in child mode
cluster.fork();
cluster.fork();
cluster.fork();
cluster.fork();
} else {
// Im a child, Im going to act like a server
// and do nothing else
const express = require('express');
const app = express();
function doWordk(duration) {
const start = Date.now();
// duration동안 while루프
while (Date.now() - start < duration) {
}
}
app.get('/', (req, res) => {
doWordk(5000); // 이 코드는 이벤트 루프에서 처리된다.
// 결국 또다른 req를 처리하지 못하며, 데이터베이스나 파일처리도 못할 것이다.
res.send('Hi there');
});
app.get('/fast', (req, res) => {
res.send('This was fast!');
});
app.listen(3000);
}코드를 설명하자면 다음과 같다.
- index.js를 처음 실행하면
cluster.isMaster는 master이므로 fork를 4번하게된다. - fork를 하면 다시 index.js가 실행된다.
- 이번에는
cluster.isMaster가 master가 아니므로 false가 되므로 else문이 실행되게 된다.
그리고 나서 하나는 localhost:3000으로 접속하고 또 다른 하나는 localhost:3000/fast로 동시 접속해보자. / 경우는 5초가 걸리는 반면에 그와 동시에 접속한 /fast는 바로 실행되었다.
🚨 주의. 다만 내 컴퓨터 환경인 윈도우에서는
/나/fast둘다 5초가 걸려서 제대로 실행이 안되었고 우분투 환경에서는 제대로 실행되었다. (이유는 잘 모르겠다)
클러스터를 사용하지 않았을때는 우리 서버가 일을 하고 있어서 다른 어떤 것도 할 수 없었다. 하지만 클러스터를 했을때 이미 일을 하고 있어도 다른 인스턴스에게 또 다른일을 시킬 수 있기 때문에 /fast가 바로 실행될 수 있었던 것이다.
Benchmarking Server Performance
'그러면 fork를 엄청 많이하면 성능이 엄청 좋아지는거 아닌가? 🤔' 이렇게 생각할 수도 있겠다. 그러나 불행히도 그렇지는 않다. 클러스터링을 사용하기 시작하면 수익률이 감소하는 지점은 분명이 있다.
먼저 서버가 요청을 처리하는데 걸리는 시간을 측정하는 방법, 성능을 벤치마킹하기 위해 사용할 프로그램을 살펴보자.
Apache benchmark
우리가 사용할 성능측정도구는 Apache benchmark 이다. 사용하기전에 설치부터 해주자.
$ sudo apt install apache2-utils그런 다음 아래 명령을 실행한다. 이 의미는 총 500개 요청을 하는데 50개씩 동시에 요청을 진행한다는 뜻이다.
$ ab -c 50 -n 500 localhost:3000/fast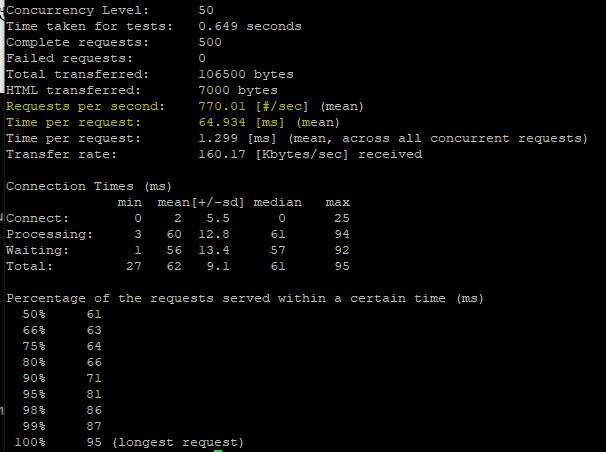
- Time taken for tests : 총 500개를 처리했을때 걸린 시간 650ms -> 0.65s
- Requests per second : 초(sec)당 몇개 요청을 처리할 수 있는지. 여기서는 770개의 요청을 처리할 수 있다고 계산되었다.
- Time per request : 동시 처리했을때 걸리는 시간. 여기서는 50개 동시처리시에 65ms만큼 걸린다.
- Time per request : 1개 요청 처리시 걸리는 시간. 1.3ms로 처리하였다는 것을 알 수 있다.
Benchmark Refactor + Need More Children
일단 doWork 기능을 대체해보자.
우리가 doWork 기능을 통해 점프해야 하는 데이터는 항상 정확히 같은 기간 동안 정지하려고 노력한다. 그리고 그것이 클러스터링에 이르기 시작할 때 무슨 일이 일어나는지 잘 알 수 없다. 그래서 우리는 직접 기능을 더 잘 시뮬레이션하는 다른 기능으로 교체할 것이다.
const cluster = require('cluster');
if (cluster.isMaster) {
cluster.fork();
} else {
const express = require('express');
const app = express();
const crypto = require('crypto');
app.get('/', (req, res) => {
crypto.pbkdf2('a','b', 100000, 512, 'sha512', (err, key) => {
console.log(key);
res.send('Hi there');
});
});
app.get('/fast', (req, res) => {
res.send('This was fast!');
});
app.listen(3000);
}
// package.json
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "set UV_THREADPOOL_SIZE=1 & node app.js"
},Test 1
그리고 한번 요청했을때 걸리는 시간을 확인해보자. 여기서는 821ms 정도가 걸린것을 알 수 있다.
$ ab -c 1 -n 1 localhost:3000/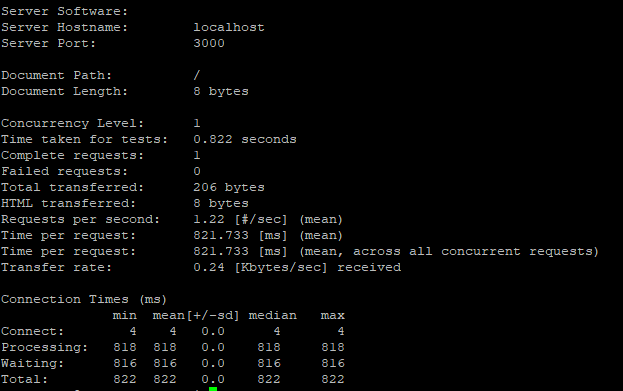
Test 2
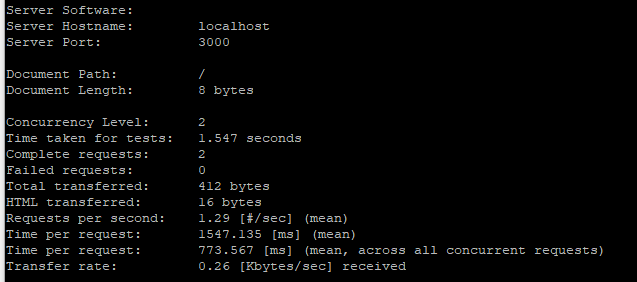
이번에는 2번을 동시에 요청했을때 걸리는 시간을 확인해보자. 하나는 773ms, 또 한개는 1547ms가 걸렸다.
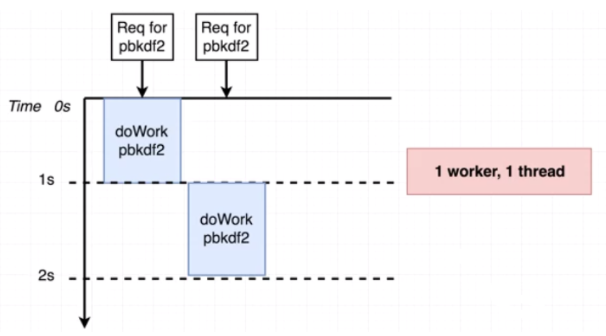
그림으로 보면 다음과 같은 동작을 하는 것처럼 보인다.
Test 3
그렇다면 이제 fork를 2번 해서 worker가 2개 생성되도록 변경한다음 다시 테스트를 해보자.
const cluster = require('cluster');
if (cluster.isMaster) {
cluster.fork();
cluster.fork();
} else {
const express = require('express');
const app = express();
const crypto = require('crypto');
app.get('/', (req, res) => {
crypto.pbkdf2('a','b', 100000, 512, 'sha512', (err, key) => {
console.log(key);
res.send('Hi there');
});
});
app.get('/fast', (req, res) => {
res.send('This was fast!');
});
app.listen(3000);
}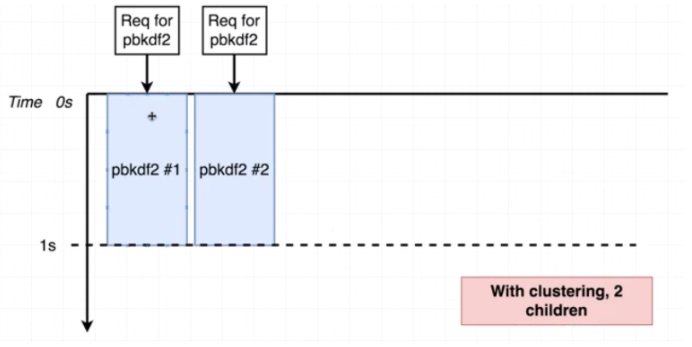
필자 우분투 서버는 CPU도 한개고 Core도 한개라서 위에처럼 결과가 나오진 않지만 Core 수가 2개 이상이라면 저런식으로 나올 것이다. (아마도?)
Test 4
그렇다면 6개의 클러스터링(=6개의 스레드 생성)을 했고, 6개의 동시요청을 해보면 어떻게 될까?
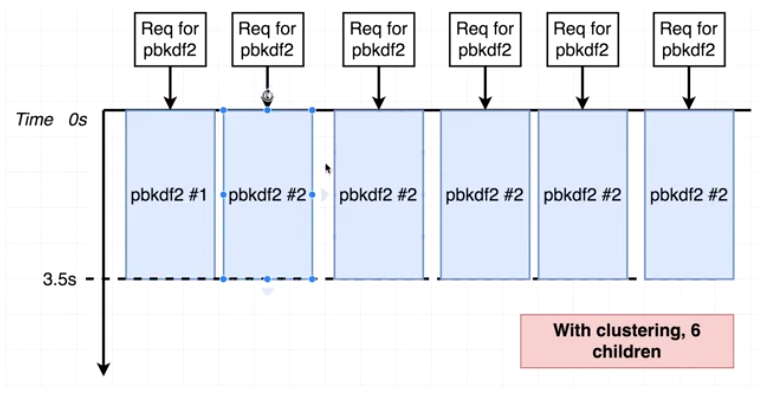
그 결과 우리의 코드가 6배 더 빨리 실행되지는 않는다. 그래서 비록 우리가 모든 들어오는 요청들을 동시에 처리할 수 있었지만 그 결과는 더 안좋게 나왔다.
Test 5
그럼 다시 2개의 클러스터링만 하도록하고, 6개를 동시요청 해보자.
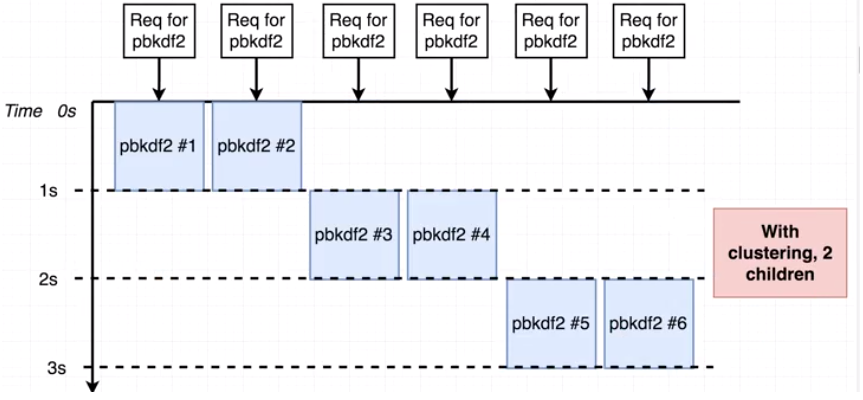
그 결과는 Test 4보다 좋게 나왔다. 그래서 비록 클러스터링을 더 적게 했지만 우리는 틀림없이 더 나은 성과로 끝났다.
✍ 결론. 따라서 클러스터링을 하기 전에 자신의 컴퓨터 코어 수를 알아본다음 코어수와 동일하게 클러스터링을 한다면 성능상 효과를 볼 수 있다. 또한 코어수를 넘게 클러스터링하면 오히려 부정적인 영향을 미칠 수 있다는 것도 알 수 있었다.

UV_THREADPOOL_SIZE 를 CPU 코어 수로 설정하는 것은 좋은 기준이 아닙니다. libuv는 CPU 집약적인 작업이 아닌 I/O 작업입니다