컨테이너 오케스트레이션
컨테이너 오케스트레이션 도구는, 수십~수백개의 컨테이너를 관리하고자 할 때 효율적으로 관리하기 위해 사용하는 도구
컨테이너를 어떻게 수십~수백개의 컨테이너를 사용하게 되는가?
아키텍처의 트렌드가 모놀리식에서 마이크로서비스로 바껴가는 과정에서 컨테이너의 갯수가 증가하고, 여기에 확장성을 고려해 스케일링까지 더할 경우 발생할 수 있다.
Google의 경우 일주일에 수십억 개의 컨테이너들을 운영을 하고 그 운영원칙들에 따라 디자인 한것이 쿠버네티스(Kubernetes, k8s)이다.
쿠버네티스(Kubernetes, k8s)란
- 오픈소스로 만들어진 컨테이너 오케스트레이션 도구
- 컨테이너화된 애플리케이션을 자동으로 배포, 스케일링하는 등의 관리 기능을 제공
- 각기 다른 환경(온프레미스 서버, VM, 클라우드)에 대응 가능
-> 아마존 ecs랑 비슷한 구조를 가짐 (같진 않음)
언제 사용해야 하는가?
- 마이크로서비스를 컨테이너 방식으로 운영하는 조직이 확장성을 고려해야 할 때
- 무중단 서비스, 즉 고가용성을 제공해야 할 때
- 그 밖에 다양한 기능들: 자가 치유, 배치 실행, 구성 관리, 로드 밸런싱
언제 사용하지 말아야 하는가?
- 여러 Tier(단계)로 나뉘어지지 않은 모놀리식 아키텍처에서는 적합하지 않습니다.
- 서너 개에 불과한 컨테이너만을 다루려면 적합하지 않습니다.
- 서너 개의 불과한 컨테이너는 docker-compose로도 충분
- 비교적 단순한 아키텍처에, 스케일링이 필요하지 않은 경우에는 적합하지 않습니다.
파드 (pods)
쿠버네티스의 배포가능한 가장 작은 컴퓨팅 유닛
도커 컨테이너처럼 파드 내에서 다음 요소들은 격리
- 하나 이상의 애플리케이션 컨테이너
- IP 주소
- 볼륨과 같은 공유 스토리지
파드 추가하기
kubectl apply -f simple-pod.yaml
서비스
파드를 외부로 노출시키기
디플로이먼트(Deployment)
쿠버네티스에서의 디플로이먼트는 파드를 업데이트하기 위한 선언적 명세입니다.
디플로이먼트는 파드의 복제본을 자동으로 업데이트하게 해주는 명세이므로,
쿠버네티스가 지원하는 배포 전략으로는 재생성(Recreate)과 롤링 배포(RollingUpdate) 방식을 선택 할 수 있음
디플로이먼트 적용하기 (파드와 마찬가지로 리소스를 적용하는 명령은 동일합니다)
kubectl apply -f <디플로이먼트_파일>
파드의 진실
쿠버네티스에서는 사실 직접 사용자가 개별 파드를 만들 일이 그리 많지 않습니다. 왜냐하면 파드는 일시적이고, 언제나 삭제될 수 있음을 감안하고 만들기 때문입니다. 예를 들어, 파드가 실행되는 공간인 노드가 만일 실패하는 경우, 그 안에서 실행되는 파드 역시 사용할 수 없게 됩니다.
쿠버네티스 Best practice
Yaml 관리는 어떻게?
- 애플리케이션 정의를 상위 디렉토리에 넣고, 티어별로 디렉토리를 따로 구성
릴리즈시 이미지 버전관리
- 자동으로 SHA 해시값이 붙게 만드는것이 좋음
- 1.0.2-efb901
- 의미론적 버전 + 해시값
- latest 사용은 가능하면 하지 않음
- latest는 항상 변경될 수 있으며, 무엇이 릴리즈되 었는지 알기 힘듬
파드
파드를 직접 만들지 않는것을 권장
레플리카셋보다는 디플로이먼트를 사용하는것을 권장
모든 서비스를 LoadBalancer나 NodePort로 구성하기보다는 인그레스를 앞단에 배치하는 것을 권장
볼륨
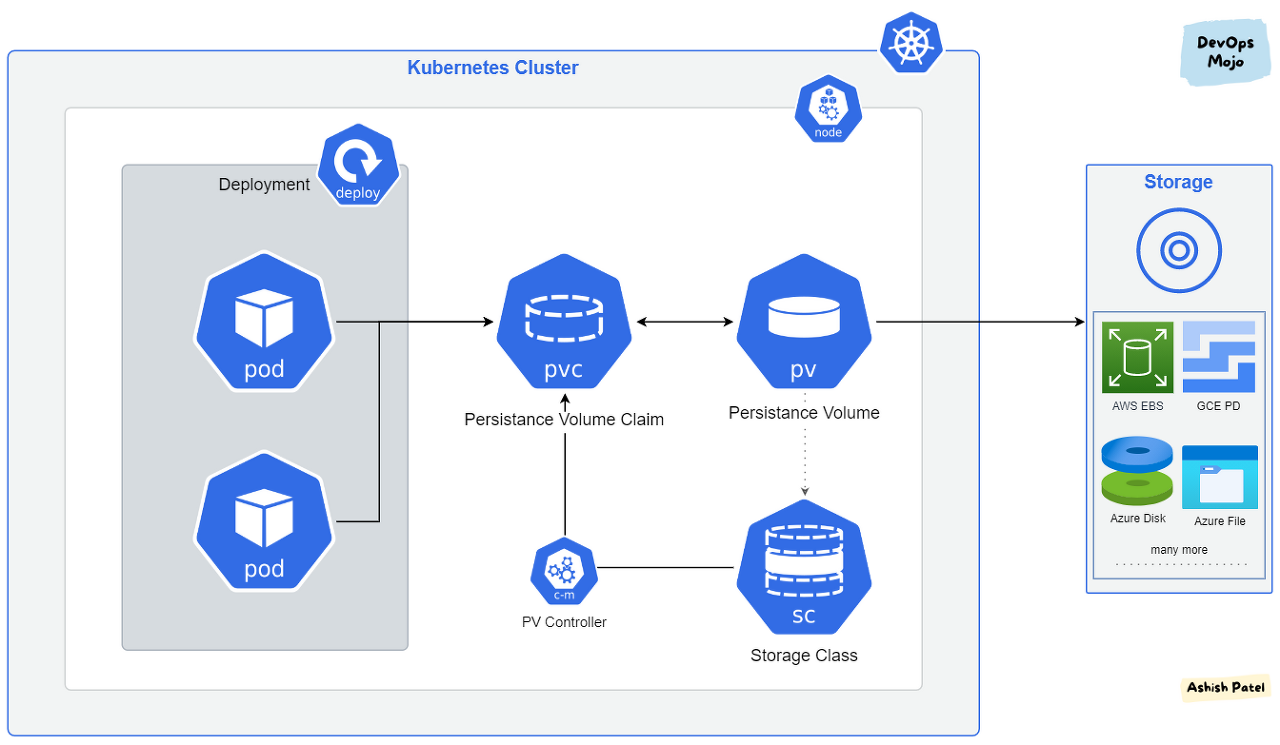
pv를 직접 연결하지 않고 pvc를 사용하여 볼륨을 느슨하게 연결
데이터베이스
- 대부분 서비스는 디플로이먼트로 배포
- 데이터베이스는 스테이트풀셋을 사용해서 마스터/슬레이브로 구성 가능
- 볼륨을 동적으로 연결
- 트래픽은 마스터를 향하게 두되, 트래픽이 증가할 경우, 전략을 바꿈
- 실제 스토리지와 연결할 때에는 SaaS서비스를 사용하는 것이 저렴
- 관리의 책임, 비용 등을 고려할 때
배포
helm으로 패키징하고, 필요한 부분만
질문
Q1) 디플로이먼트가 지원하는 배포 전략에서 블루/그린이나 카나리는 찾아볼 수 없습니다. 어떻게 블루/그린이나 카나리 배포를 할 수 있을까요?
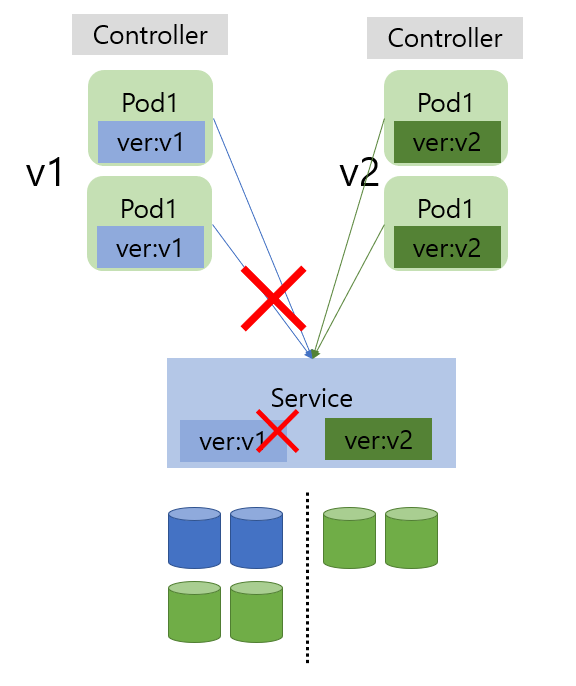
블루/그린
- Deployment의 자체적인 기능은 아니지만 Service의 Label을 변경하는 것으로 활용
- 문제 발생시 Label을 이전으로 되돌리는 것으로 RollBack
- 새로운 버전을 추가하고 기존 버전과의 연결을 끊는 것으로 Downtime 발생 X
- 배포 중 자원이 2배로 필요하다는 단점 존재
- 현재 가장 많이 사용하는 배포 방식
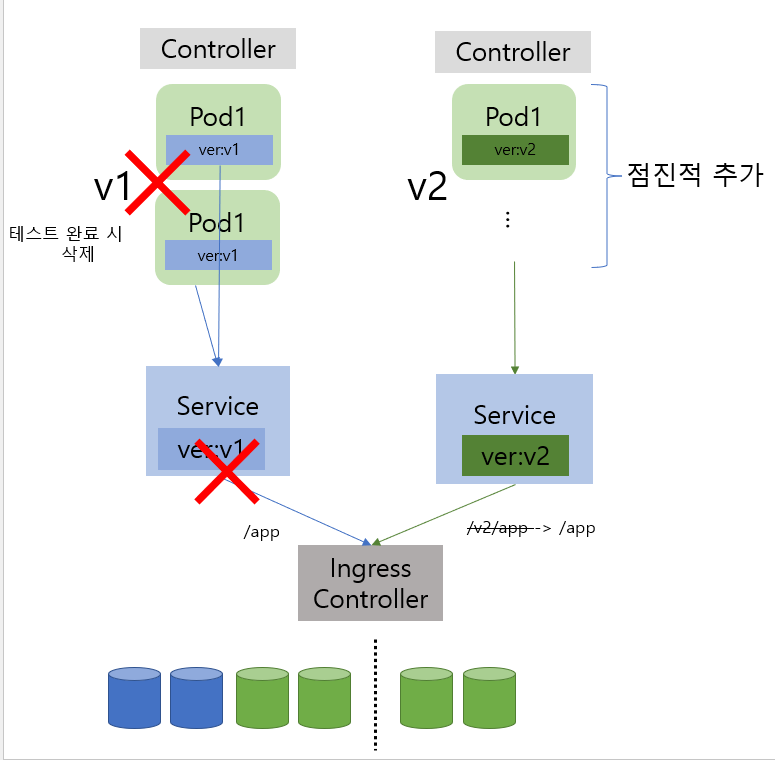
카나리 배포
- 서버개념에서 카나리 배포는 일정 트래픽을 버전2로 트래픽을 분산해서 문제가 없으면 신버전을 점진적으로 배포하는 방식이였고, 쿠버네티스에 카나리 배포도 비슷하지만 신버전을 테스트를 진행하면서 문제가 없으면 배포하는 형식
- 테스트가 정상적으로 종료되면 새로운 버전의 서버를 증가하고 기존의 버전은 삭제
- 테스트가 진행되거나 테스트가 종료될 때 자원 사용량이 늘어났다가 다시 줄어듬
도움받은 블로그 : https://jangcenter.tistory.com/107
Q2) 서비스의 타입은 ClusterIP, NodePort, LoadBalancer, ExternalName 네 가지가 있습니다. 이들은 어떻게 다른가요?
Service 의 type 종류
-
ClusterIP : 클러스터 내부에서만 접근할 수 있는 IP를 할당
- 외부에서는 접근할 수 없으로 port forwarding 또는 proxy를 통해 접근이 가능함
- 서비스 타입을 별도 type을 설정하지 않으면 ClusterIP가 default
-
NodePort : 노드의 특정 포트를 사용하여 접근하는 방식, 포트당 하나의 서비스만 사용 가능
- 포트당 하나의 서비스를 사용하며, 30000-32767범위내 포트를 사용
- 단점은 노드가 사라졌을때 자동으로 다른노드를 통해 접근이 불가능
-
LoadBalancer : 노드포트 앞단에 특정 LoadBalancer를 사용하여 접근하는 방식
- Nodeport 타입의 확장판이라고 할 수 있으며 서비스를 외부에 노출 할 수 있습니다.
- 살아있는 노드를 체크하여 트래픽을 전달 할 수 있는 장점이 있음
- 클라우드 공급업체(AWS, GCP 등)에서 지원하는 기능을 사용해서 구현 할 수도 있음
-
ExternalName : DNS이름에 대한 서비스를 매핑함
- 외부에서 접근하기 위한 종류 아니며, 외부의 특정 FQDN에 대한 CNAME 매핑을 제공
- 어떠한 프록시도 설정되지 않는다.
도움받은 블로그 : https://kim-dragon.tistory.com/52
Q3) 애플리케이션에 HTTP 500과 같은 에러가 발생한 경우, 컨테이너를 다시 실행해야 할 것 입니다. HTTP 에러가 발생했다는 것을 어떻게 알 수 있을까요? 어떻게 해야 쿠버네티스가 에러가 발생한 컨테이너를 자동으로 재시작하게 만들 수 있을까요?
Liveness probe를 사용하면 에러가 발생한 컨테이너를 종료 후 다시 실행 시킬 수 있다.
Liveness probe는 컨테이너의 상태를 주기적으로 체크해서, 응답이 없으면 컨테이너를 자동으로 재시작해준다. HTTP 에러가 발생 했는지 확인하려면 HTTP Request를 지정된 포트, 주소로 보내 상태를 확인하여 응답의 상태코드가 200 보다 크고 400 보다 작으면 진단이 성공한 것으로 간주한다. 추가로 프로브가 실패한 후 컨테이너가 종료되거나 재시작 되기를 원한다면 활성 프로브(liveness probe)를 지정, 에러 발생시 에러 발생한 파드의 트래픽을 무시하게끔 하고 싶으면 준비상태 프로브(Readiness probe)를 지정함
livenessProbe 매커니즘
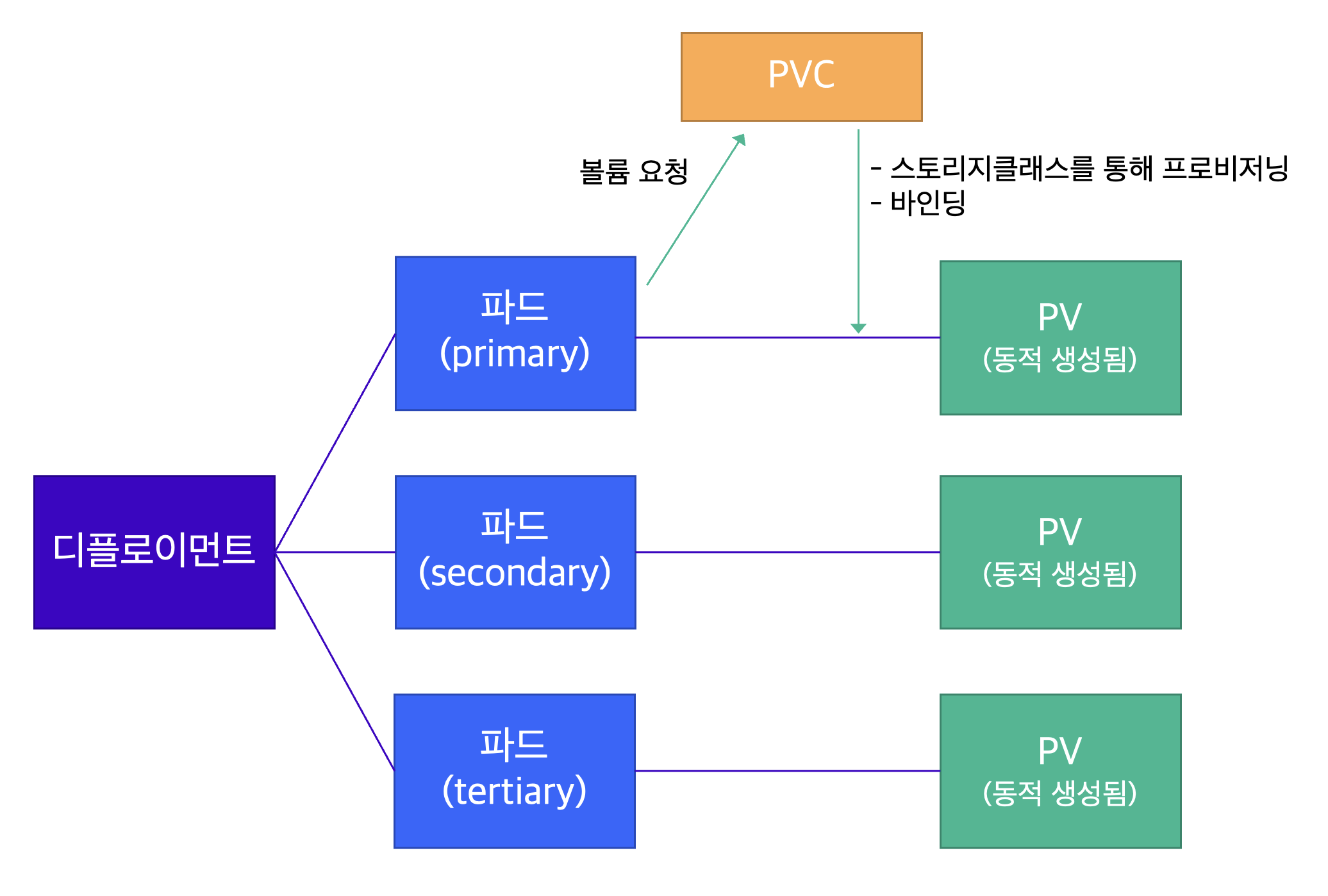
Q4) 왜 파드와 PV(퍼시스턴스볼륨)를 직접 연결하지 않는걸까요?
수동 연결이 안되는건 아니지만 스토리지 제공자를 수동으로 호출하여 새 스토리지 볼륨을 생성한 다음 Kubernetes에서 이를 나타내는 PersistentVolume객체 를 생성해야 하기때문에 pvc를 사용하는것 일반적이다 pvc를 이용하면 사용자는 pv를 연결할 때 어떤 스토리지를 사용하는지 신경 쓰지 않아도 사용자가 요청할 때 자동으로 스토리지를 프로비저닝합니다.
그외에도 파드가 볼륨의 세부 사항을 몰라도 볼륨을 사용할 수 있게 도와줍니다.
PVC필요성
추가로 수평확장을 할때 기본적으로 PV와 PVC의 매핑은 1대1 관계이기 때문에 파드마다 별도의 데이터를 저장할 수 있게 만드려면 수평확장되는 파드에 서로 다른 PV가 연결되어야함 그러기 위해서는 스토리지클래스를 활용하면 개별 PV를 생성이 가능함