네가지 황금 시그널
구글의 SRE 조직에서 정의한 “네가지 황금 시그널(The Four Golden Signals)”로 SRE 모니터링의 주요 측정 항목입니다.
구글은 분산 환경에서 한정된 항목만을 측정할 수 있다면, 이 네가지에 집중할 것을 권장합니다.
대기 시간 (Latency)
대기 시간은 서비스가 요청에 응답하는 데 걸리는 시간을 나타냅니다. 핵심은 지속 시간뿐만 아니라 성공적인 요청의 대기 시간과, 실패한 요청의 대기 시간을 구별하는 데에도 중점을 두어야 합니다.
트래픽 (Traffic)
트래픽은 서비스에 대한 수요 측정입니다. 대표적인 예로는, 초당 HTTP 요청 수가 있습니다.
오류 (Errors)
오류는 실패한 요청/전체 요청 의 비율로 측정됩니다. 대부분의 경우 이러한 실패는 명시적이지만(예: HTTP 500 오류) 암시적일 수도 있습니다(예: "결과 없음"이라는 메시지를 본문으로 전달하는 HTTP 200 응답).
포화 수준 (Saturation)
포화는 서비스 또는 시스템 리소스를 “얼마나 가득 채워서 사용하는가”로 설명할 수 있습니다. 전형적인 예로는 과도한 CPU 자원 사용이 있습니다. CPU 자원이 부족하면, 스로틀링을 초래하고 결과적으로 응용 프로그램의 성능을 저하시킵니다.
첫번째 발표
[C171] 람다를 모니터링 하려는 경우, 메트릭을 활용해 어떤 질문이 나올 수 있을까요? 레퍼런스(Lambda 키 메트릭)를 읽고, 어떤 질문을 해결할 수 있는지 알아봅시다. (힌트: 레퍼런스 문서에서 how many, how much, how long 으로 검색해보세요.)
how many dead-letter
동기식, 비동기식인지 호출 방법에 따라 모니터링할 메트릭이 달라짐
metrics을 활용하면 얼마나 많은 트래픽을 견딜 수 있는지 확인 할 수 있음
메모리 사이즈를 통해 얼마나 오랫동안 함수가 실행되는지등 여러 정보를 확인 할 수 있음
너무 많이 실행되지 않게 throttles을 지정할 수 도 있다.
람다에 경우 serverless서비스이기 때문에 컴퓨팅유닛 관련 메트릭은 없음
람다 함수의 성공률과 에러 개수등 확인가능
레퍼런스 문서
https://www.datadoghq.com/blog/key-metrics-for-monitoring-aws-lambda/#concurrency-metrics
[C172] 쿠버네티스에 어떤 파드가 Pending 상태에 머물러있다면, 어떤 계층부터 살펴보아야 할까요? 이 경우는 파드가 Running 상태인데 잘 작동하지 않는 경우랑은 어떻게 다른가요? (서비스는 연결되어 있다고 가정합니다)
pending상태에 머물러 있다면 스케줄러의 문제가 있거나 노드의 자원이 없거나 둘 중 하나가 문제 살펴 봐야할 관련 계층 메트릭은 컴퓨팅 유닛 관련 메트릭(컴퓨터 cpu관련)을 살펴보면됨
running 상태일때 작동하지 않는 경우는 서버 오류나 클라이언트 오류일것이라 생각되고 예방하는 방법은 Liveness probe, Readness probe등 probe를 추가로 지정하면 Liveness probe는 컨테이너의 상태를 주기적으로 체크해서, 응답이 없으면 컨테이너를 자동으로 재시작하고, 에러 발생시 에러 발생한 파드의 트래픽을 무시하게끔 하고 싶으면 Readiness probe를 사용할 수 있음
참고 문서
POD pending <- 검색
https://www.ibm.com/docs/ko/cloud-private/3.2.x?topic=tm-minio-server-pod-gets-stuck-in-pending-status
두번째 발표
[C173] 모니터링 시스템에는 메트릭 수집을 위한 두가지 방식의 메커니즘이 존재합니다. 바로 Pull 방식과 Push 방식입니다. 프로메테우스는 어떤 방식의 메커니즘을 사용하나요? 또한 Pull 방식과 Push 방식은 어떻게 다르며, 장단점은 무엇인지, 또한 해당 방식을 사용하는 모니터링 도구는 어떤 것들이 있는지 연구해보세요.
프로메테우스는 pull 방식을 사용합니다.
여기서 Pull 과 Push는 메트릭을 수집하는 방법을 말합니다.
어떤 수집 메트릭이 있을때 push에 경우 메트릭을 수집하는 서버에서 데이터를 전송 해주는 것이라면, Pull 베이스는 메트릭이 발생하는 서버에서 끌어온다고 보면 되는데 서로의 장단점이 있습니다.
PULL특징
주로 tcp 이용
PUSH
push와 pull방식은 관점에 따라 방식의 장단점이 나뉩니다.
수많은 관점중 일부만 적자면
- 수집 대상이 Auto-scaling 등으로 가변적일 경우, Push방식이 유리하다.
- 만약 새로운 수집 Host가 추가될 경우, Push방식에서는 Host가 Data-Backend로 수집데이터를 보내주기에, 전송된 데이터를 받기만 하면된다. 하지만 Pull 방식에선 중앙서버에서 pull해갈 Host/Service의 목록들을 관리하여야함
- 수집 대상의 유연성 측면에서는 Pull방식이 유리하다.
- Pull 방식에서 중앙서버는 데이터를 수동적으로 긁어가기만 하기에, Pull system에서 Data-Backend는 언제든지 새로운 데이터(unplanned metrics)들을 수용할 수 있으며 모든 메트릭을 요청할 수 있도록 구현되어있다. 하지만 Push 방식에선 메트릭을 중앙에서 정의하고 에이전트로 푸시하는 구조이며, 새로운 메트릭 수용을 위해서는 중앙 서버에서 해당 변경사항을 반영해줘야한다.
- 보안 측면에서는 Push방식이 유리하다
- Pull방식은 수집 대상 서버에서 중앙 폴러가 접근할 수 있는 포트, IP 등을 수신 대기해야 한다.
- HA(고가용성) 측면에서 Pull방식이 유리하다.
- Data-Backend에서 장애가 발생하더라도, Pull 방식에선 수집 Host에 영향이 없으나 Push 방식에선 데이터 전송 재시도 등 Host에 영향이 생긴다.
- 일괄 작업에 대한 메트릭을 가져올 경우 PUSH 방식이 유리하다
- pull의 경우, scraping 주기와 batch 작업의 주기가 일치하지 않음
- push는 일괄 작업이 끝나면 메트릭을 모니터링 시스템으로 보내기만 하면됨
대표적인 pull방식 도구 Prometheus, push방식 도구 CloudWatch 에이전트
[C174] 어떤 조직의 SLO가 다음과 같습니다. "GET 호출의 99%는 10ms 이내에 수행되어야 한다" 그렇다면, 이러한 SLO를 달성하려면 어떤 메트릭을 수집하고 어떻게 계산해야 할까요? (척도는 표준화된 범용 지표를 사용합니다)
주요 SLI의 정의를 표준화
집계 간격: 1분
집계 범위: 하나의 클러스터에서 수행되는 모든 태스크
측정 빈도: 매 10분
집계에 포함할 요청: 전체 HTTP GET 요청
SLO = SLI + 목표값(Goal)
SLI = GET 호출의 응답시간
목표 = GET 호출의 99%는 10ms 이내 수행
참고 해야할 메트릭은 요청, 응답메트릭에서 http get 요청에 응답시간 메트릭의 평균과 어떤 요청이 응답이 느린지, 빠른지를 확인하여 느린곳에서는 왜 느린지 확인 하는식으로 SLO를 달성 시키면 되지 않을까합니다..
혜연님 발표
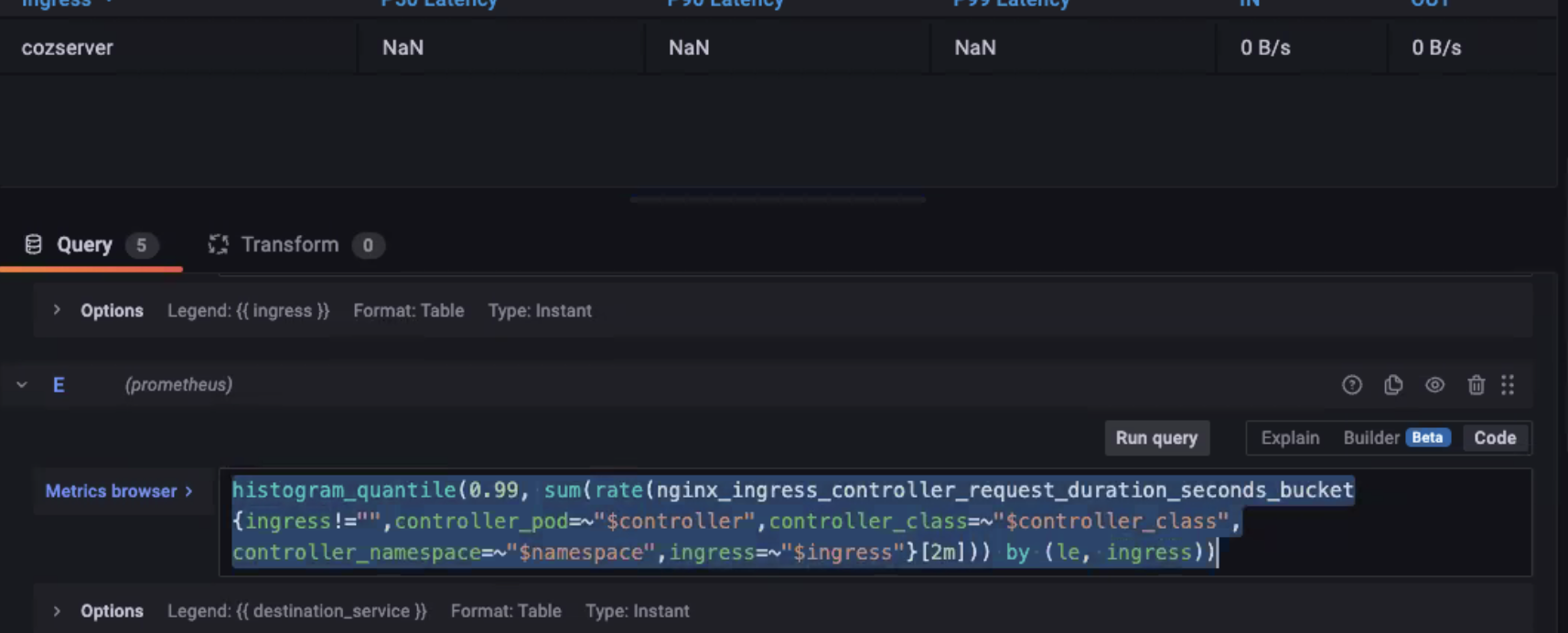
latency (대기시간) 측정을 하면 될것이라 생각 했다.
- histogram_quantile(0.99, rate(http_request_duration_seconds_bucket[7d])) -> 7d 간 상위 99% http 응답을 확인
https://sre.google/workbook/implementing-slos/
프로메테우스에서 그라파나를 이용해 평균 응답시간 구하는 방법
NGINX Ingress controller를 import하여