공부 방향
크게 4가지
- Google academy PCA - Google Product 서비스 공부 겸 PCA 자격증 목적
- 내부 커리큘럼 - 조금 더 자세하게 실무에 필요한 내용들을 개념 정리 (google support, billing)
- GCP Hands on - GCP환경을 간단하게나마 처음으로 환경을 구축하고 3tier 아키텍처를 만들어보는 실습을 통해 환경에 익숙해지기
- Workshop - Data Pipeline, 빅쿼리, dataproc 등 관리형 서비스 알기 위해 스터디
1. Google academy PCA (8.22-9.26)
1) IAM access - 사용자계정, 서비스계정, 그룹등 리소스 계층구조
2) VPC - subnet, 방화벽규칙, cidr
3) Storage - GCS, cloud sql, spanner, firestore, bigtable
4) Container - GKE, Cloud Run
5) Serverless - AppEngine, Cloud Funtion, Cloud Run
6) Monitoring - SRE(SLI, SLO, SLA)
PCA 자격증을 목표로 하는 교육이긴 하지만 공식 교육이기 때문에 문제 풀이 보다는 다양한 google products의 서비스들의 특징을 설명해주고 skills boost를 통해 퀴즈를 풀거나 lab실로 제품을 경험 해볼 수 있는 시간
2. 내부 커리큘럼
VPC Network
1) VPC 기본 개념
VPC(Virtual Private Cloud)
클라우드 내 프라이빗 공간을 제공함으로써, 클라우드를 퍼블릭과 프라이빗 영역으로 논리적으로 분리할 수 있게 해주는 가상 네트워크망
VPC를 분리함으로써 확장성을 가질 수 있고, 네트워크에 대한 완전한 통제권을 가질 수 있음.
2) CIDR, Subnet 이란?
Subnet이란?
하나의 IP 네트워크 주소를 지역적으로 쪼개서 여러 개의 지역 네트워크로 사용할 수 있도록 하는 작은 네트워크
-> GCP에서는 VPC(메인네트워크)를 쪼개서 여러개의 서브넷으로 나눌 수 있음.
CIDR, SUBNETMASK 역할
사용자마다 얼마만큼에 네트워크(IP)가 필요한지 다르기 때문에 적절하게 사용하기 위해서 subnet mask, cidr 이용
Subnet Mask
IP주소에 대한 네트워크 아이디와 호스트 아이디를 구분하려고 사용하거나 클래스 구분하기 위해 사용됨
클래스(cidr 이전)
A,B,C로 구분하며 A클래스 가까울수록 할당받는 host ip 개수가 늘어남

CIDR(Classless Inter-Domain Routing)
1993년 이전에는 IP 주소를 할당하는 방식으로 클래스 기반 방식을 사용했지만, 사용되는 호스트의 수가 늘어남에 따라 할당 가능한 IP 주소의 수가 고갈되는 것과 라우팅 테이블의 크기가 커지는 문제를 해결하기 위해, 1993년부터 도입한 표준 IP 주소 할당 방식
기존의 사용하던 서브넷 마스크는 8자리 단위로만 끊기게 되어 낭비되는 주소가 많았기 때문에 조금더 세밀한 조정이 가능한 CIDR 표기법이 생기게됨.
CIDR 표기법
A.B.C.D/E
A부터 D까지는 IPv4 주소와 동일하게 8비트씩 끊어 0부터 255까지 10진수 숫자. /뒤에 오는 0~32까지의 숫자로 구성된 E를 추가하는것이 사이더 표기법입니다. CIDR값에 따라 호스트값이 달라지며 값이 적어질수록 할당하는 ip주소 값이 커지게 됩니다.
Subnet mask와 cidr
255.255.255.255 = 32
255.255.255.0 = 24
255.255.0.0 = 16
255.0.0.0 = 8
0.0.0.0 = 0
추가로 기존 클래스로만 구분하자면 8, 16, 24 정도겠지만 CIDR는 9, 17, 25 도 포함가능.
3) Firewall rules 이란?
GCP VPC내에서 TCP, UDP 포트나 지정 프로토콜을 허용 해줄때 이용됨.
source filter에서는 ipv4 범위지정, 소스태그, 서비스 계정을 통해 특정 네트워크에만 액세스 를 허용 하게끔 할 수 있음.
4) Routes란?
영어 뜻대로 길을 뜻하는데 다른 길이 아닌 네트워크 트래픽의 길을 나타내며 가상 머신(VM) 인스턴스에서 다른 대상 위치로 이동하는 경로를 정의하는게 Routes
대상위치는 방법에 따라 내부, 외부 연결 모두 가능함.
다른 영역이나 vpc를 통한 트래픽(ping) 연결
외부 IP주소끼리의 경우
Ping연결 가능 (ICMP 방화벽 규칙에 의해서 제어됨)
다른 vpc 내부 IP주소끼리의 경우
Ping연결 불가능 (동일 VPC가 아닌경우 패킷손실 확인)
->해결책으로는 VPC peering (vpc네트워크를 연결하는 기술)
5) VPC peering 이란?
동일한 프로젝트에 속하는지 또는 동일한 조직에 속하는지에 관계없이 두 개의 VPC의 네트워크 내부 IP 연결을 허용시켜주기 위해 사용
VPC Peering 장점
- 네트워크 지연 시간 : 내부 주소를 이용하는것은 외부 주소를 사용하는거 보다 지연시간이 짧음.
- 네트워크 보안 : 공개 인터넷에 서비스를 노출할 필요가 없어 그와 관련된 위험에 안전
주의 사항
다른 프로젝트 vm을 연결할 때는 서브넷 ip가 겹치면 안됨.
VPC peering 실습
1) vpc 2개 각 subnet 하나씩 생성
2) vm 생성 후 처음 ping -c 3 내부 ip로 패킷 전송 했을때 100% 실패 확인
3) vpc peering 공개 서브넷 경로를 통해 내보내기로 1->2, 2->1로 peering 전송


활성화 이후 패킷전송 확인됨.
6) Shared VPC란?
공유 VPC를 사용하는 조직은 여러 프로젝트의 리소스를 공통 VPC 네트워크에 연결할 수 있으므로 해당 네트워크의 내부 IP를 사용하여 서로 안전하고 효율적으로 통신 할 수 있음.
필수 관리 역할이 필요
- 조직 관리자
- 공유 VPC 관리자
- 서비스 프로젝트 관리자
peering vpc와 shared vpc 차이
shared vpc는 동일한 조직 내에 포함되어 있어야만 내부 연결이 가능
Network Service
1) Cloud DNS란?
DNS(Domain Name Server)
보유중인 도메인이 있다면 도메인을 등록하여 사람이 읽을 수 있는 주소를 주소창에 도메인 검색 했을때 해당 도메인 ip주소로 이동 시켜주는 서비스
ex)www.naver.com
2) Cloud CDN란?
CDN (Content Delivery Network)은 글로벌 엣지 네트워크를 사용하여 사용자에게 최대한 가깝게 콘텐츠를 제공함으로써 콘텐츠 전송을 가속화 하는 콘텐츠 전송 네트워크를 뜻합니다.
장점
- 고속 컨텐츠 전송 - CDN 사용시 저장된 캐시에 경우 컨텐츠가 캐쉬에서 직접 제공 처음 요청 될 경우 캐시로 저장됨
- 다중 사용자 확장 - 웹페이지의 부하가 줄어들어 더 많은 사용자 수용가능
3) Cloud NAT란?
NAT(Network Address Translation)는 사설IP를 공인IP로 변경에 필요한 주소 변환 서비스
외부 ip주소가 없는 특정 리소스들을 아웃바운드 연결을 할 수 있게합니다.
강점
- VM 보안 강화 : 외부 IP가 있어야 하는 필요성을 줄이는데 도움이 됨.
- VM 기반 서비스 확장성보장 : Cloud NAT는 NAT IP주소 수를 자동으로 확장하도록 구성이 가능하기 때문에 관리현 인스턴스 그룹에 속한 VM을 지원함
- 고가용성 : Cloud NAT는 분산형 소프트웨어 정의 관리형 서비스이므로 프로젝트의 VM이나 단일 물리적 게이트웨이에 의존 하지 않음
3. Hands-on
3Tier Architecture Web->WAS->DB (이중화)
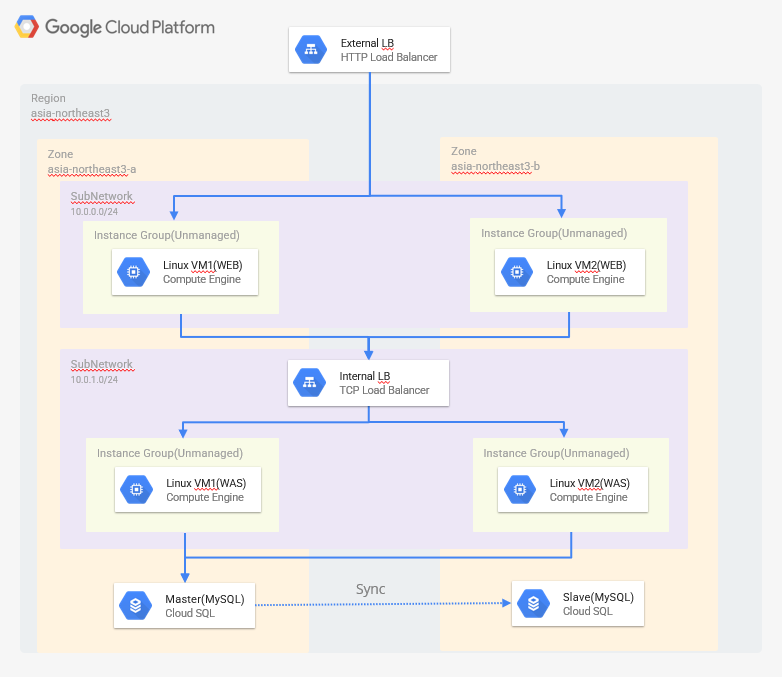
진행순서
1) VPC 서브넷 추가 (10.0.0.0/24, 10.0.1.0/24)
2) Unmanaged instance group 4개 추가 (a-zone, b-zone각자 2개씩)
이유 : 서브넷과 존이 다 달라서
3) instance group 마다 Web VM, WAS VM 생성 (web으로는 apache2, was로는 tomcat사용)
4) VM Tag설정 (http=80, was(tomcat)=8080, mysql=3306)
5) External LB(HTTP), Internal LB 생성(TCP)
6) WEB 인스턴스에서 tcp lb로 프록시 설정이 필요
7) WAS 인스턴스에서 MySQL로 연결
8) MySQL 복제본 생성 (Replication)
힘들었던점
- WAS(tomcat) 연동
문제점 : 자바와 톰캣 설치 후 설치경로로 들어가 ./startup.sh 했음에도 서버가 열리지 않던 문제
해결법
현재 경로와 기존 환경설정 경로가 달라서 에러가 나왔고 로그로 나온 관련 에러 구글링을 통해 환경변수를 재 지정하여 해결
export JAVA_HOME=/usr/local/java
export CLASSPATH=.:$JAVA_HOME/jre/lib/ext:$JAVA_HOME/lib/tools.jar
PATH=$PATH:$JAVA_HOME/bin
export CATALINA_HOME=/usr/local/tomcat8
export CLASSPATH=$CATALINA_HOME/lib/jsp-api.jar:$CATALINA_HOME/lib/servlet-api.jar- External LB -> WEB -> Internal LB -> WAS 구현
문제점 : 외부 노출이 되지 않던 로드밸랜서를 web vm과 연결하는 작업
해결법
Reverce proxy 사용
webserver로 사용하던 apache2에 기본으로 탑재되어 있는 기능인 modeproxy를 활용
/etc/apache2/sites-available/000-default.conf를 수정
000-default.conf
<VirtualHost *:80>
...
# Forward Proxy 경우 On / Reverse Proxy Off
ProxyRequests Off
# 호스트가 받은 HTTP 요청을 Proxy 요청시 사용
# Reverse 경우 On으로 해야함
ProxyPreserveHost On
# Proxy에 연결할 URL
# ServerHost:localhost -> Apache -> ProxyPass URL
ProxyPass / http://192.168.10.146:8080/service/ # 뒤에 슬래쉬는 붙여줘야함
# WAS 가 redirect HTTP 응답을 보냈을 경우 Location, Content-Location HTTP 헤더를 수정 클라이언트에 전달한다.
# reverse proxy가 이 헤더를 수정하지 않으면 클라이언트는 redirect 시 제대로 연결할 수 없으므로 꼭 설정해야 한다.
ProxyPassReverse / http://192.168.10.146:8080/service/
...
수정 후 restart
알게된점
- 포워드, 리버스 프록시 차이
- 이중화를 하는 이유
포워드 프록시(forward proxy)
클라이언트(사용자)가 인터넷에 직접 접근하는게 아니라 포워드 프록시 서버가 요청을 받고 인터넷에 연결하여 결과를 클라이언트에 전달해주는 역할
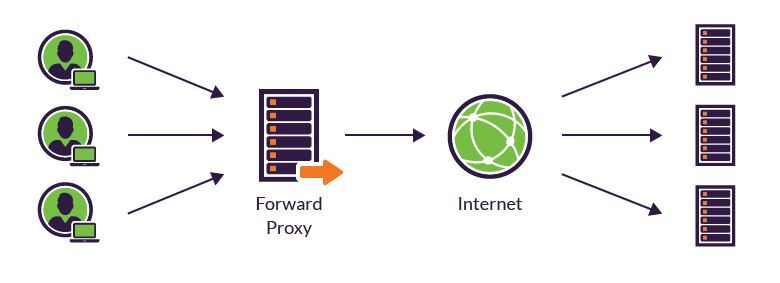
리버스 프록시(reverce proxy)
클라이언트가 서버를 호출할 때 리버스 프록시를 호출하게 되고 프록시 서버가 서버를 요청하여 받은 응답을 클라이언트에게 전달하는 방식

VM 이중화
- 사용중인 vm이 장애를 일으켜도 고가용성을 유지 하기 위해서
- 부하 분산을 통하여 급격한 트래픽에 대비
Cloud SQL 이중화 (Replication)
- 2대 이상의 DBMS를 나눠서 데이터를 저장하는 방식으로 사용목적은 크게 실시간 Data 백업과 여러대의 DB서버의 부하를 분산 시킬수 있습니다.
4. Workshop
Data Pipeline
데이터 분석 파이프라인이란?
다양한 데이터 소스에서 원시 데이터를 수집한 다음 분석을 위해 데이터 레이크 또는 데이터 웨어하우스와 같은 데이터 저장소로 이전하는 방법입니다.
데이터는 저장소로 이동 전 일반적으로 데이터 처리 과정을 거쳐 저장이 되며 이후 탐색형 데이터 분석, 데이터 시각화, 머신 러닝 작업에 활용 할 수 있습니다.
데이터 파이프라인 유형
데이터 파이프라인에는 일괄 처리(batch processing)와 스트리밍 데이터(streaming data)의 두 가지 주요 유형이 있습니다.
일괄 처리 (batch Processing)
batch는 미리 설정된 시간에 일괄적으로 로드하여, 대용량 데이터를 처리 할 수 있겠끔 하는 일괄 처리 방식
장점으로는 안정성이 높음.
스트리밍 데이터(streaming data)
일괄 처리와 달리, 데이터를 지속적으로 업데이트 할 때 활용됨. 예로 POS(point of Sale) 시스템은 제품의 실시간 재고 여부가 필요하기 때문에 실시간 데이터가 필요함. 필요에 따라 선택 가능
장점으로는 지연시간 짧음.
데이터 분석 파이프라인 5단계

1. CAPTURE (데이터 수집)
- 데이터 마이그레이션 도구를 활용하여 한 클라우드에서 다른 클라우드로 마이그레이션 (google cloud 스토리지 전송 서비스)
- BigQuery를 이용하여 타사 SaaS(Youtube, Google Ads, Amazon S3, Res Shift 등)데이터 수집가능
- Pub/Sub 서비스를 사용하여 애플리케이션 실시간 데이터를 스트리밍 받을 수 있음
2. PROCESS (데이터 처리)
- Dataproc : 기본적으로 Hadoop, Spark의 클러스터를 함께 이용할 수 있고, 일괄 처리, 쿼리, 스트리밍, 머신 러닝을 위한 오픈 소스 데이터 도구를 활용할 수 있음
관리에 소요되는 시간과 비용을 줄여 데이터처리에 집중가능 - Dataprep : 데이터 분석가가 코드를 작성할 필요 없이 데이터를 처리할 수 있도록 도와주는 지능형 그래픽 사용자 인터페이스 도구
- Dataflow : 스트리밍 및 batch 데이터를 위한 서버리스 데이터 처리 서비스
Apache Beam 오픈 소스 SDK를 기반으로 한 파이프 라인을 이식가능 특징으로는 스토리지를 컴퓨팅과 분리하여 원활하게 확장가능
Hadoop 이란?
대용량의 데이터를 적은 비용으로 빠르게 분석할 수 있도록 하는 플랫폼
빅데이터 처리와 분석을 위해 사실상 표준으로 사용되는 영향력 있는 플랫폼
3. STORE (저장)
- GCS : 용도에 맞는 Standard, Nearline, Coldline, Archive로 맞게 선택 할 수 있고 이미지, 동영상, 파일 등을 위한 객체 저장소
- BigQuery : 서버리스 데이터 웨어하우스 페타바이트 규모의 데이터까지 원활하게 확장 가능.
4. Analyze (분석)
- BigQuery : BigQuery를 사용하는 경우 SQL을 사용하여 BigQuery에서 데이터를 직접 분석가능
- Cloud Stoge를 사용하는 경우에도 BigQuery로 쉽게 이동이 가능함.
5. USE (데이터 사용 및 시각화)
1) 데이터 사용
데이터 웨어하우스에 데이터가 있으면 Tesorflow, AI Platform을 통해 활용 가능.
- Tesorflow : 도구, 라이브러리, 커뮤니티 리소스가 포함된 엔드 투 엔드 오픈소스 머신 러닝 플랫폼
- AI Platform : 개발자, 데이터 과학자, 데이터 엔지니어가 ML 워크플로를 간소화 할때 이용
2) 데이터 시각화
- Data Studio : 손쉬운 데이터 시각화를 위해 사용
- Looker : 데이터 시각화, 임베디드 분석기능 제공
Dataproc
pandas (query)
프로그래머스 mysql로 풀어보고 pandas로 구현