갑작스러운 트래픽 증가에 대응하기 위해서는, 서버의 주요 메트릭을 모니터링하고, 특정 메트릭이 임계치를 넘을 때, 수평 확장이 자동으로 진행되게 하는 것이 바람직합니다.
Sprint
AWS를 통해 Auto Scaling Group의 원리를 익히고, 메트릭에 따른 스케일링 정책을 세우고 모니터링을 통해 정책이 적용되는지 확인해보기
Bare Minimum Requirement
- EC2 서버를 ASG를 통해 구성합니다. 구성은 다음을 따릅니다.
- CloudWatch 알람을 통해 ASG의 스케일 인/아웃을 진행합니다.
- 스케일 인/아웃이 진행될 때 디스코드에 알림을 보냅니다.
- 메트릭을 바탕으로 장애 발생 예상 시점에 디스코드에 알림을 보냅니다.
- CPU 사용률(CPUUtilization) 값이 특정 값 이상일 때 경보가 발생하게 하세요
시작 템플릿 구성
그룹 정보
원하는 용량: 1
최소 용량: 1
최대 용량: 3
시작 템플릿은 다음 구성을 따릅니다.
Ubuntu Server (LTS)
t2.nano
기존 혹은 신규 키 페어를 사용합니다
보안 그룹: 인바운드 HTTP 및 SSH 허용
사용자 데이터
#!/bin/bash
echo "Hello, World" > index.html
sudo apt update
sudo apt install stress
nohup busybox httpd -f -p 80 &CloudWatch와 조정 정책
- CloudWatch를 통한 Auto Scaling 그룹 지표 수집 활성화 필요
- Scale-in 조건: CPU 40% 이하
- Scale-out 조건: CPU 50% 이상
Lambda 코드
cloudwatch-alarm-to-slack-python 블루프린트를 기반으로 작성 활용
완성시킬 아키텍쳐
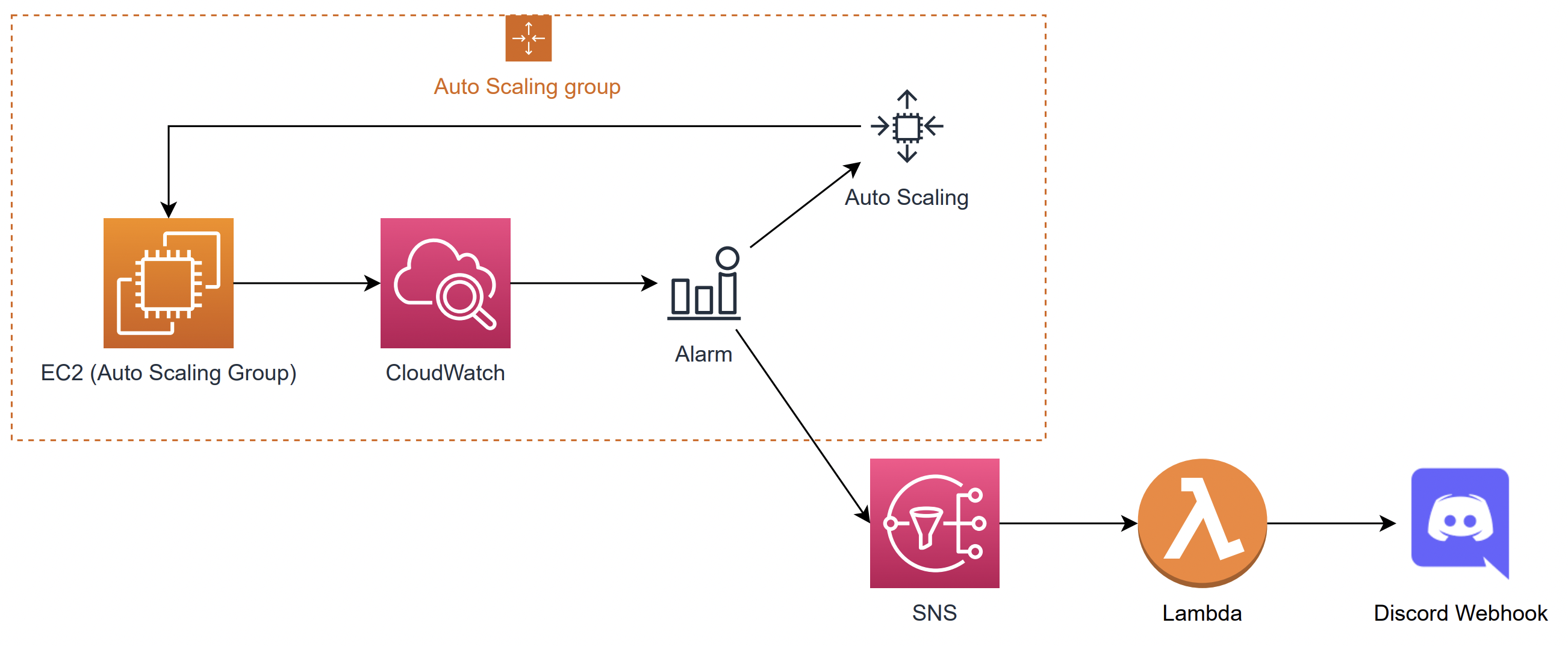
진행순서
- 우선 시작템플릿을 위 조건대로 구성 후 오토스케일링 그룹을 생성
- 이후 클라우드 워치에서 EC2 > Auto Scaling 그룹별 cpu사용량 메트릭을 참고한 cpu사용량 조건을 충족할 때 경보가 발동하는 scale-out, scale-in 경보 생성
- 스케일링 그룹에서 동적 조정 정책 2개 추가
- 람다를 블루스크린 cloudwatch-alarm-to-slack-python를 가져와서 디스코드 주소를 환경변수로 넣어준다.
- sns를 만들고 람다함수를 구독한 후 asg그룹에 알람으로 sns를 연결시켜줌
- ec2에 접속하여 강제적으로
steress -u 1명령어를 통해 cpu사용량을 높이고top으로 확인가능 - 경보가 울릴 때 마다 람다함수가 잘 작동하는지 확인
결과
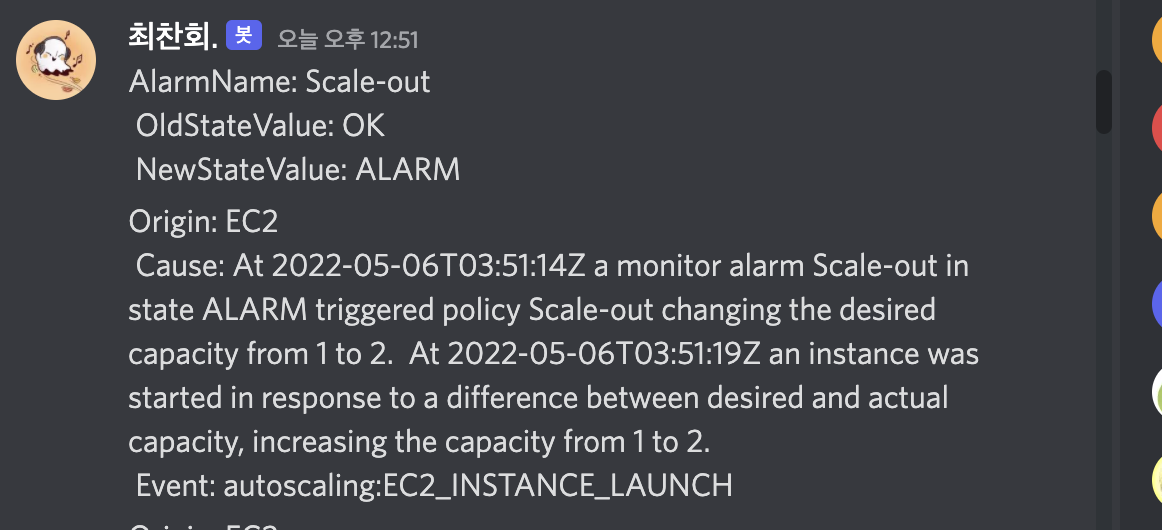


꾸준히 새로운 기술을 배워나가는중입니다.