lexical analyzer generator의 구조
lex program lex compiler transition table/actions
여기서 transition table과 오가는 것이 있는데 그게 Automaton simulator(lexing)이다.
regular expression NFA (Optional) DFA
regular expression으로 나타난 specification을 NFA로 변환하고 필요하다면 DFA로 변환할 수 있다. NFA나 DFA를 통해 token을 인식할 수 있다.
Specification of Tokens
모든 lexeme patterns를 명세하는 것을 효율적이지 못하다. 따라서 regular expression을 사용한다.
예를 들어, 숫자를 나타낼 수 있는 정규 표현식은 다음과 같다.

digit은 0부터 9의 숫자가 될 수 있고, digits는 으로 을 제외한 digit들의 concatenation으로 나타낼 수 있다. 마지막으로 num은 우선 정수부분에 숫자가 꼭 있어야 하고, 소수점 자리에 있을 수 있고 없을 수 있으며 마지막은 지수승을 의미한다.
참고로 는 를 의미한다. 이면 소수부분이 없다는 뜻이겠다.
지수승부분도 마찬가지이다.
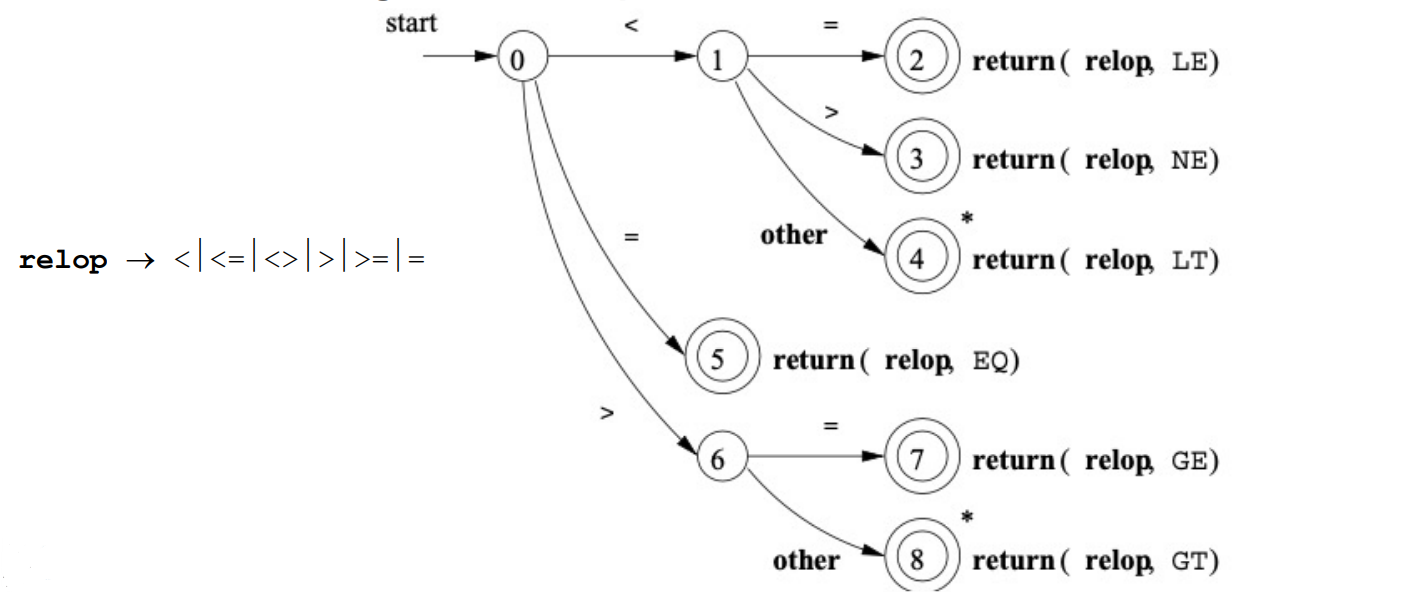
Recognition of tokens
어떻게 프로그램이 인식할까?
finite automata는 정규식으로 생성된 strings를 인식할 수 있다.
손으로 직접 만들 수도 있고 tool의 도움으로 만들 수도 있다.

열심히 성장 중인 백엔드