IP(인터넷 프로토콜)
- 지정한 IP주소에 데이터 전달
- 패킷이라는 통신 단위로 데이터 전달
한계
-
비연결성
패킷받을 대상이 없거나 서비스 불능 상태여도 패킷 전송 -
비신뢰성
패킷이 사라지거나 순서대로 안올 수 있음 -
프로그램 구분
같은 IP사용하는 서버에서 통신하는 애플리케이션이 둘 이상일때
TCP(전송 제어 프로토콜)
- 연결지향, 연결을 해야 보냄
- 데이터 전달 보증
- 순서 보장
- 신뢰성 있는 프로토콜
인터넷 프로토콜 스택의 4계층

Hello 메시지 전송
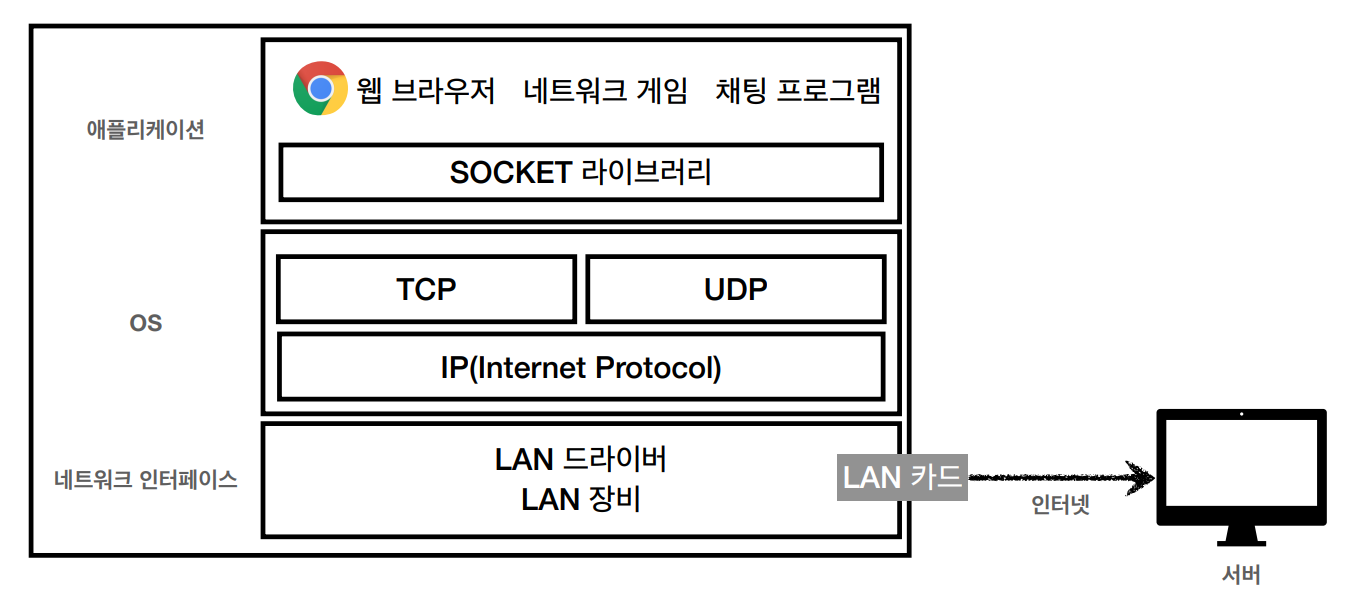
Hello 메시지에 TCP 정보 추가 -> ip주소 추가한 ip 패킷 생성 -> LAN카드 통해 서버 전송
TCP 3 way handshake
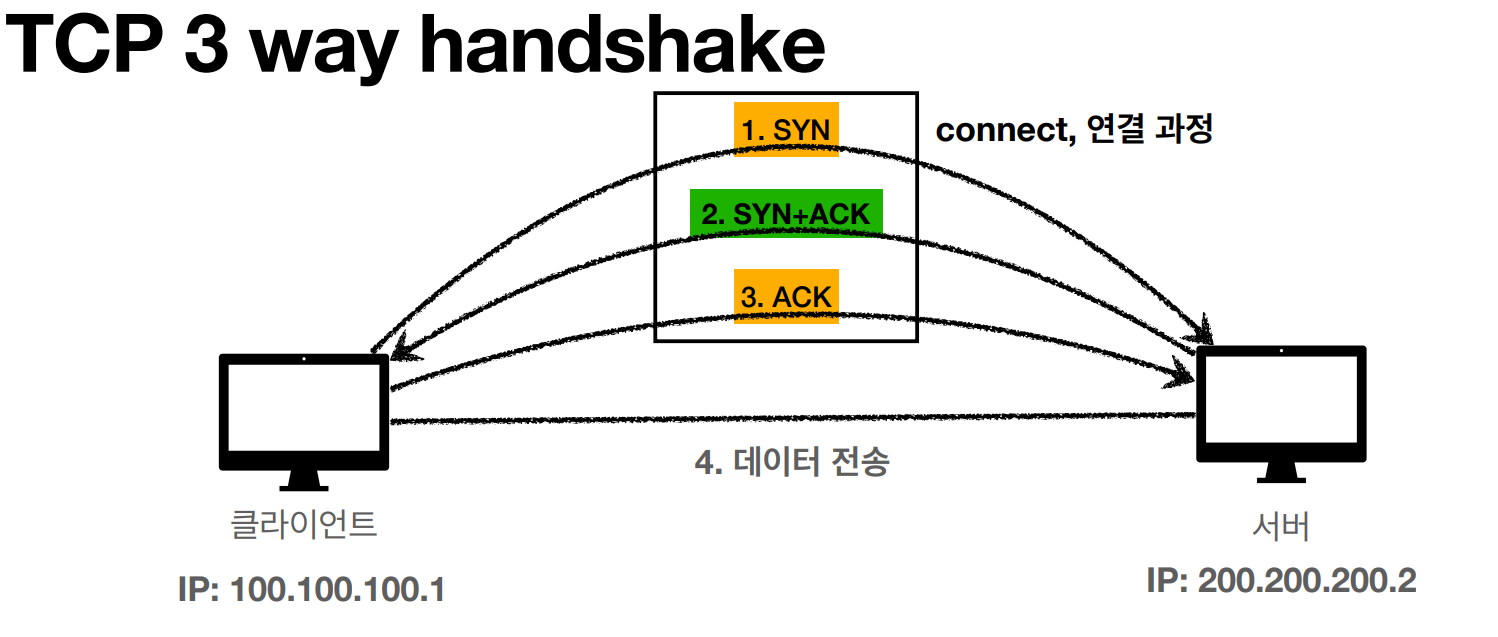
SYN: 접속요청
ACK: 요청 수락
1. 클라이언트가 서버로 SYN
2. 서버가 클라이언트로 SYN+ACK
3. 클라이언트가 서버로 ACK
4. 데이터 전송(3번 수행시 같이 보낼 수도 있음)
- 데이터 전송시 데이터 수신 확인을 전송 -> 데이터 전달 보증
- 순서 잘못왔을때, 재요청 -> 순서보장
UDP(사용자 데이터그램 프로토콜)
- IP와 거의 같다 + PORT + 체크섬 추가
- 애플리케이션에서 필요한 부분만 확장할 수 있다.
PORT
- 같은 IP에서 프로세스 구분하기 위해 사용한다.
EX)같은 IP에서 게임서버 연결인지 화상통화 통신인지 알 수가 없다. 이를 출발지 포트, 목적지 포트를 통해 프로세스를 구분한다. - 0~65535 할당 가능
- FTP : 20,21
- TELNET : 23
- HTTP : 80
- HTTPS : 443
DNS
- 전화번호부 처럼 도메인 이름에 맞는 IP주소를 찾아 반환해준다.
URI
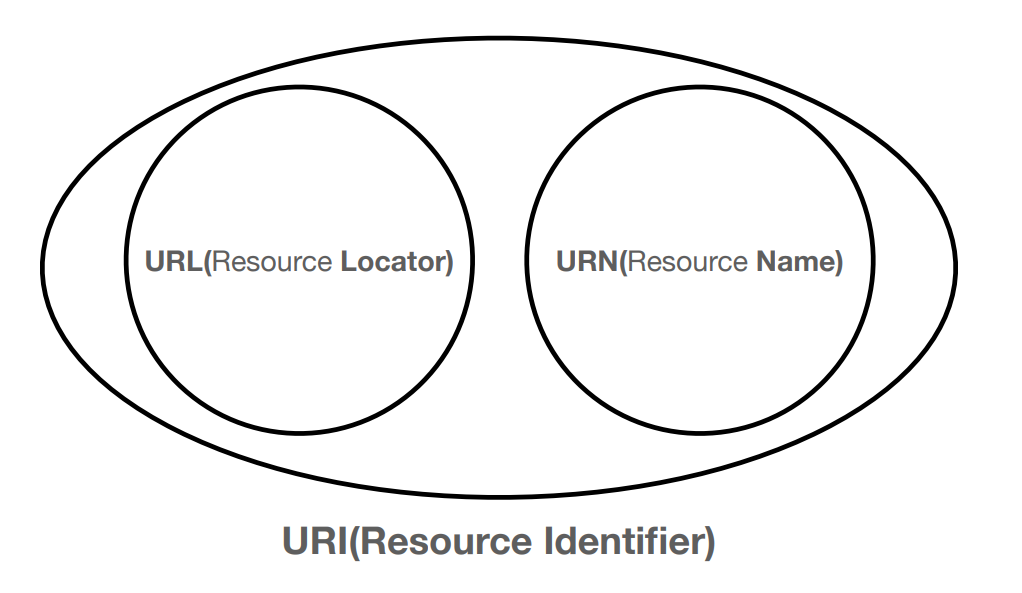
URL은 리소스 위치
URN은 리소스 이름
URN 이름만으로 리소스를 찾을 수 있는 방법이 보편화 되어있지 않음,
따라서 보통 URL URI 같은 의미로 사용한다.
URL
scheme://[userinfo@]host[:port][/path][?query][#fragment]
- scheme에는 주로 프로토콜 사용 ex) http, https
- host에는 도메인 네임, port는 일반적으로 생략
- /path는 리소스 경로
- query는 키,값 형태이며 , ?로 시작, &로 추가 가능하다
HTTP
- HTTP 메시지에 모든것을 전송한다.
클라이언트 서버 구조
- 비지니스 로직, 데이터 처리를 서버에서 수행
- UI, 사용성등은 클라이언트에서 집중
- 각각 독립적으로 집중, 진행할 수 있다.
무상태 프로토콜(Stateless)
- Stateful - 상태 유지
-> 서버가 클라이언트의 이전 상태를 보존한다. 중간에 다른 서버로 바뀌면 안됨 - Stateless - 무상태
-> 서버가 클라이언트의 이전 상태를 알 수 없다. 클라이언트가 이전 상태까지 전부 포함해서 요청한다.
-> 서버바뀌거나 다른서버가 와도 어차피 요청에 다 포함 되어있어서 상관없음
-> 무한한 서버증설 가능
-> 스케일아웃, 수평확장에 유리하다
한계
- 모든것을 무상태로 할 수는 없음 ex) 로그인은 상태유지로 해야한다.
- 모든 데이터를 포함해서 요청해야하므로 요청 데이터량이 많다.
비연결성
- 요청 주고 받을때만 연결하고, 아닐땐 끊어버림, 최소한의 자원을 사용할 수 있다.
- http는 비연결성 모델이다.
- 브라우저에서 수천명이 서비스 사용해도 동시 처리 요청은 매우 작다.
한계
- 매번 TCP 3 way handshake 시간 쓰며 연결해야함
- 매번 데이터를 다운받아야한다.
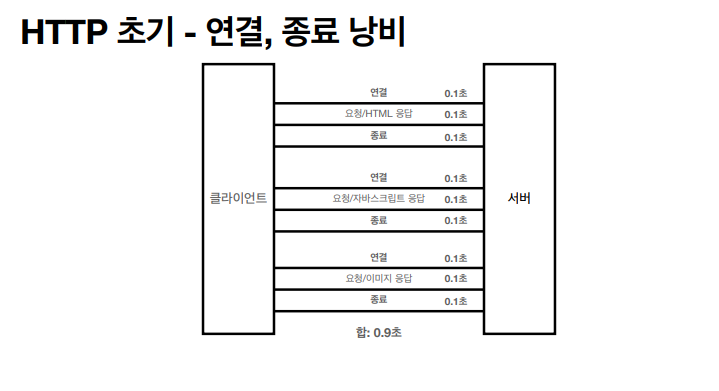
극복
- http 지속 연결(보통 한페이지를 다 다운 할 동안 유지한다. 내부메커니즘 따라 다름)
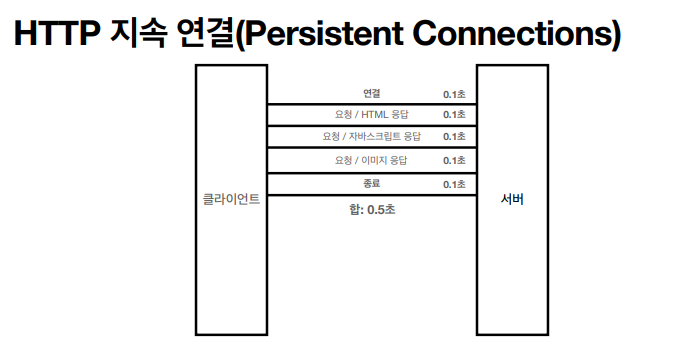
HTTP API 설계
- 리소스 식별, URI 계층구조를 활용하여 설계한다.
문제점
• 회원 목록 조회 /members
• 회원 조회 /members/{id} -> 어떻게 구분하지?
• 회원 등록 /members/{id} -> 어떻게 구분하지?
• 회원 수정 /members/{id} -> 어떻게 구분하지?
• 회원 삭제 /members/{id} -> 어떻게 구분하지?
극복
- URI는 리소스만 식별해야함. 리소스(회원)와 행위를 분리하자
- 행위를 나타내는 메서드 GET,POST,PUT,PATCH,DELETE를 통해 나타낸다.
GET
- 리소스를 조회한다. 전달하는 데이터는 query를 통해서 전달
- 서버에서는 전달받은 데이터를 통해 데이터베이스를 조회하여 응답 데이터를 만들고 클라이언트에게 전달한다.
POST
- 클라이언트가 서버로 메시지 바디를 통해 서버로 요청 데이터를 전달한다.
- 서버에서 요청한 데이터를 처리한다.
- POST는 요청을 처리하는 방법이 다양하다. 그래서 리소스마다 요청이 왔을때 어떻게 처리할지를 사전에 정해야한다.
- 리소스만으로 URI를 설계하려고 하되, 어쩔 수 없는 경우에는 동사를 통한 컨트롤 URI를 사용할 수도 있다.
PUT
- 리소스 대체, 리소스가 있으면 대체, 없으면 새로 생성.
- 👉 POST와의 차이점은 클라이언트가 리소스의 위치를 식별하고 URI를 지정해서 서버로 보낸다. POST는 서버가 리소스의 위치를 지정한다.
- 리소스 완전 대체! 부분변경 이런거 안됨 그냥 기존을 덮어쓴다.
PATCH
- 리소스 부분 변경
DELETE
- 리소스 제거
메소드 안전 safe
- 호출해도 리소스를 변경하지 않는것을 말함.
멱등
- 한 번 호출하든 두 번 호출하든 결과가 똑같은 것을 말함
- POST는 멱등이 아니다. 두 번 호출하면 같은 결제가 중복해서 발생할 수 있다.
- GET, PUT, DELETE는 멱등하다.
- 정상 응답을 주지 못하였을때, 재요청을 해도되는지에 대한 자동 복구 매커니즘의 기본 개념이 된다.
캐시가능
- 한번 응답받은 응답결과 리소스를 캐시를 통해 저장해서 사용해도 되는가?
- GET, HEAD, POST, PATCH 가 이론적으로는 캐시가능이다.
- 실제로는 GET, HEAD정도만 쓰인다.

개린이
많은 도움이 되었습니다, 감사합니다.