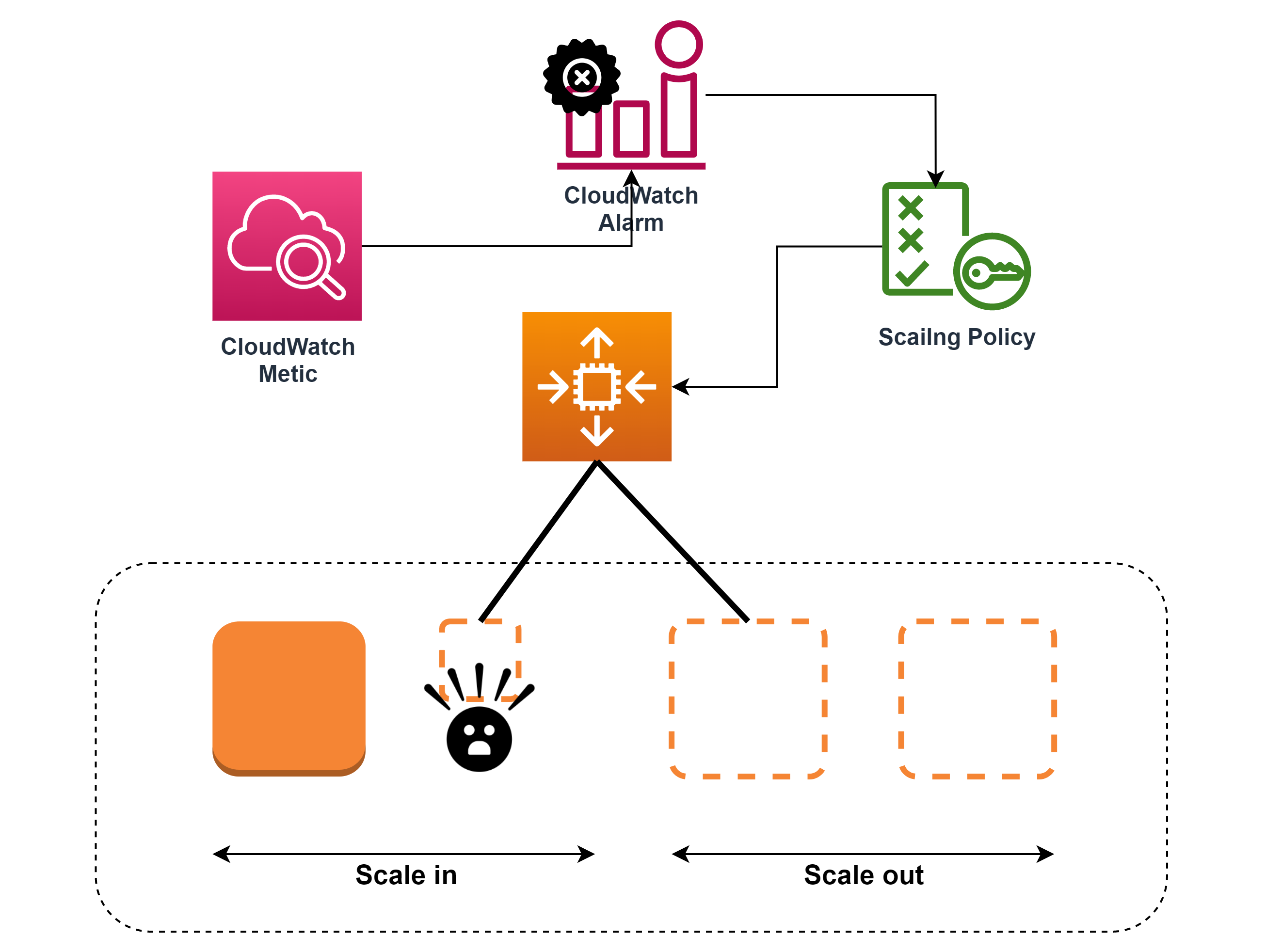
Cloudwath Alarm을 통해 EC2 Auto Scailng Group의 Scailng Policy를 설정 할 수 있습니다.
Auto Scailng Group의 Metric의 경우 하나의 EC2가 아닌 여러 EC2의 메트릭에 의해서 지표가 표현 되기 때문에 올바는 Cloudwath Alarm을 설정하지 않는 경우 예기치 않은 Scailng Event가 발생이 될 수 있습니다.
이번 포스팅에서는 Cloudwath Alarm의 동작 방식에 대해 알아보고 올바른 EC2 Scaling Policy 적용을 위한 Clouwatch Alarm 설정에 대해 알아 보도록 하겠습니다.
1. CloudWatch Alarm 동장방식의 이해
- period(기간) : alarm을 평가하기 위한 datapoint의 간격을 지정합니다. 1분으로 설정 하면 평가 시간 기준으로 1분 단위의 data point가 생성이 되고 5분으로 생성하면 5분 단위의 data point가 생성이 됩니다.
- evaluation period(평가 기간) : 몇 개의 datapoint를 가지고 alarm을 평가할지 정의합니다. period가 2분이고 evaluation period가 5이면 10분동안의 2분간격으로 생성 된 5개의 datapoint를 가지고 평가 합니다.
- Datapoints to Alarm : evaluation period 기간 중 몇 개의 datapoint가 기준값을 위반 했을 때 알람을 발생할지 정의 합니다.
AWS CloudWatch Alarm은 period에 관계없이 period가 1분 이상인 경우에는 매분 Cloudwath Alarm에 대해서 평가를 합니다. 위의 예시는 period : 1, evaluation period : 3, datapoints to alarm :3에 대한 예시입니다. 10:03에 Threshold 값을 넘었지만 10:01 과 10:02의 값이 Threshold를 넘지 않아 Alarm의 상태가 OK입니다. 10:05가 되면 가장 최근 3개의 Datapoint 값 모두가 Threshold가 넘게 되어 Alarm의 상태가 변경이 됩니다.
2. Missing Data 대한 처리
Cloudwath Alarm은 evaluation range(평가 기간) 동안 없는 Datapoint에 대해서 아래와 같은 방식으로 처리합니다.
- notBreaching – 존재 하지 않는 datapoint를 Threshold을 위반하지 않은 datapoint로 처리 합니다.
- breaching – 존재 하지 않는 datapoint를 Threshold을 위반하지 않은 datapoint로 처리 합니다.
- ignore – 현재 Alarm 상태가 유지 됩니다.
- missing – 알람 평가 기간 중에 모든 datapoint가 없는 경우에는 알람의 상태가 INSUFFICIENT_DATA로 변경이 됩니다.
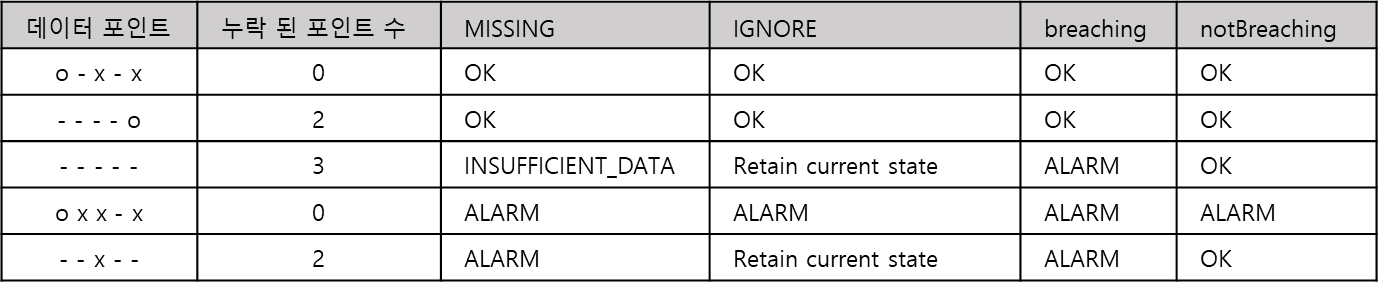
Cloudwatch Alarm은 평가를 하기 위해 Evaluation period 보다 많은 수의 datapoint를 사용 합니다. 위의 테이블은 일부 datapoint가 누락 된 상태에서 Datapoints to Alarm : 3, Evaluation period : 3 일때의 예시 입니다. Cloudwatch Alarm은 누락 된 datapoint에 대해 평가를 하기 5개의 datapoint를 사용합니다. 첫번째 행의 경우에는 평가 범위(5) 중에 총 3개의 datapoint가 존재하고 임계값을 위반한 값이 2개 이므로 Alarm의 상태는 OK가 됩니다. 두번째 행의 경우에는 평가 범위(5) 중에 총 1개의 datapoint가 존재하지만 임계값을 위반한 값이 아니기 때문에 Alarm의 상태는 OK가 됩니다.세번째 행의 경우에는 datapoint가 존재 하지 않는 케이스로 missing data의 처리 방식에 의해서 Alarm의 상태가 정해집니다. 다섯번째 행의 경우에는 조기 경보 상태라는 특별한 상태 입니다. 아마존에서는 조기 경보를 방지하기 위해서 임계값을 위반한 datapoint를 평가할 때 다음과 같은 로직을 사용합니다. 예를 들어 - - - - x 의 경우에 다음 datapoint가 비위반 datapoint을 경우 - - - x o가 되기 때문에 바로 Alarm 상태로 변경하지 않습니다. 위 테이블의 다섯번째 행의 경우에는 - - x - - 가장 오래된 datapoint가 evaluation period(3) 만큼 오래 되었고 다른 모든 데이터가 누락 또는 위반한 datapoint이기 때문에 Alarm 상태로 표현이 되었습니다.
3. Scailng 정책 적용 시 주의 사항
Cloudwatch Alarm을 통해서 Scailng 정책을 적용하고자 한다면 모든 EC2의 datapoint가 동일한 시점에 확인이 되지 않을 수 있다는 것을 고려하여야 합니다. 예를 들어 아래와 같은 케이스가 있을 수 있습니다.
1. 서비스 운영자는 신속하게 트래픽에 대응하고자 1분 간격의 1개의 datapoint가 임계값을 위반 하였을 경우 scale-out/in이 발생이 되게 설정하였습니다.
2. 한개의 EC2가 있고 해당 EC2의 CPU 사용량이 높아 scale-out이 발생이 됩니다.
3. 새로 생성 된 EC2는 내부 이슈로 인해 트래픽을 받지 못하고 CPU의 사용량이 낮았습니다.
4. ASG의 평균 CPU 사용량은 임계값보다 높기 떄문에 scale-in 이 발생하면 안됩니다.
5. 하지만 Cloudwatch Alarm에서 평가를 할 때 새로 생성 된 EC2의 CPU 값만 확인이 가능하면 예기치 못한 scale-in이 발생합니다.
아래의 예시는 동일한 ASG의 CPU 사용량을 조회 한 결과로 동일한 Timestamps이지만 조회 시점에 따라 CPU 사용량이 달라지는 것을 보여줍니다.만약 평가 시점에서 새로 생성 된 EC2의 datapoint만 확인이 가능했다면 scale-in이 발생이 되었을 것이고 Cloudwatch Grpah 상에서는 정상적으로 두 개의 EC2의 평균값이 그려지게 되어 scale-in이 발생한 원인을 찾기 힘들어 집니다.
# aws cloudwatch get-metric-data --metric-data-queries '[{"Id": "m1", "MetricStat": {"Metric": {"Namespace": "AWS/EC2", "MetricName": "CPUUtilization", "Dimensions": [{"Name": "AutoScalingGroupName", "Value": "kdy-alarm"}]}, "Period": 60, "Stat": "Average"}, "ReturnData": true}]' --start-time $(date -u +%FT%TZ --date='-1 minutes') --end-time $(date -u +%FT%TZ)
{
"MetricDataResults": [
{
"Id": "m1",
"Label": "CPUUtilization",
"Timestamps": [
"2023-04-19T04:25:00Z"
],
"Values": [
0.125
],
"StatusCode": "Complete"
}
],
"Messages": []
}
# aws cloudwatch get-metric-data --metric-data-queries '[{"Id": "m1", "MetricStat": {"Metric": {"Namespace": "AWS/EC2", "MetricName": "CPUUtilization", "Dimensions": [{"Name": "AutoScalingGroupName", "Value": "kdy-alarm"}]}, "Period": 60, "Stat": "Average"}, "ReturnData": true}]' --start-time $(date -u +%FT%TZ --date='-1 minutes') --end-time $(date -u +%FT%TZ)
{
"MetricDataResults": [
{
"Id": "m1",
"Label": "CPUUtilization",
"Timestamps": [
"2023-04-19T04:25:00Z"
],
"Values": [
49.94166666666667
],
"StatusCode": "Complete"
}
],
"Messages": []
}4. 결론
Cloudwatch Alarm을 활용하면 Cloudwatch Metric에 대해서 알람이 발생이 되었을 때 여러 작업을 수행 할 수 있도록 설정이 가능합니다. 다만, Cloudwatch Alarm 동작에 대한 정확한 이해 없이 설정을 하였을 경우 예기치 못한 방식으로 작업이 수행 될 수 가 있습니다. 그러므로 의도한 방향으로 작업이 수행 되기 위해서는 datapoint와 missing data에 대한 적절한 설정이 필요한 것을 알 수 있습니다.
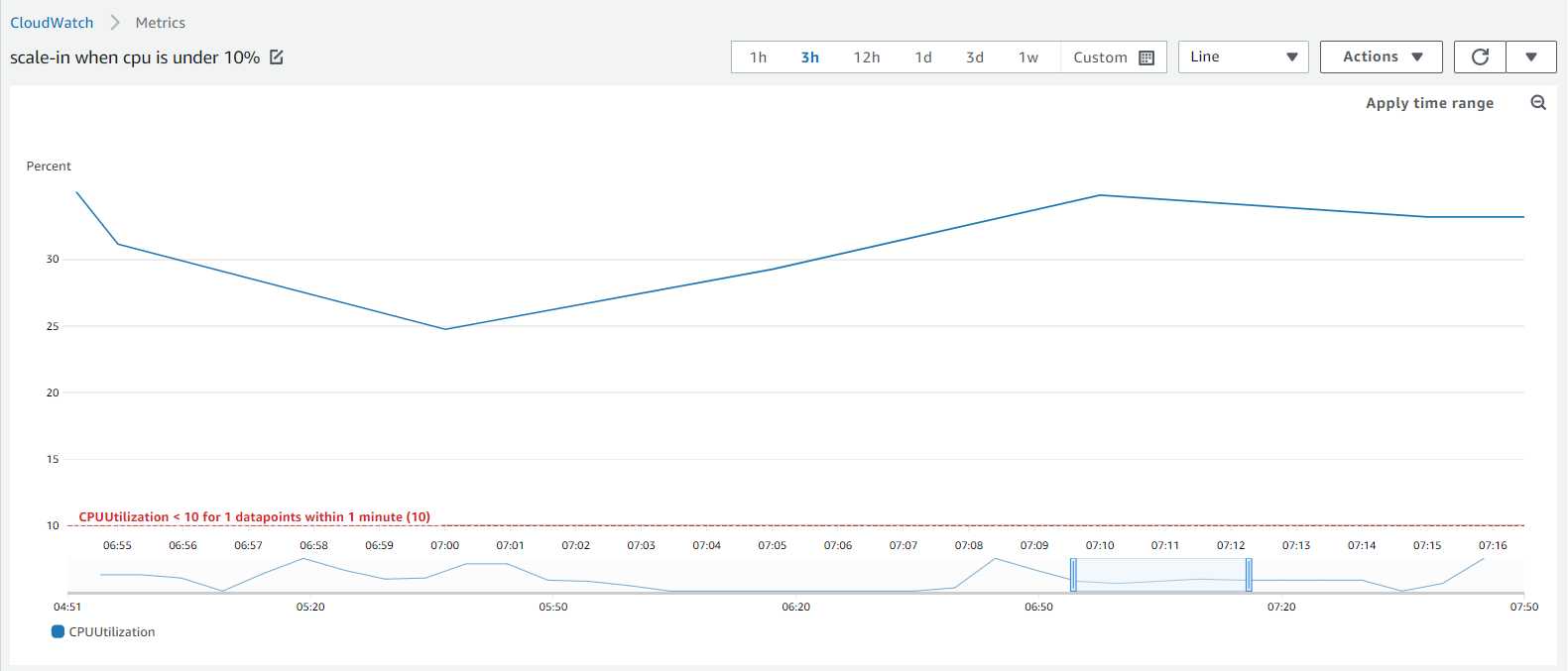
# unexpected scaling 사례
1분 간격의 1개의 datapoint가 임계값을 위반 하였을 때 scale-in이 되게 설정하고 아래와 같이 EC2 한 대가 Scailng policy에 의해서 Terminate가 되는 것을 확인 했습니다.
이벤트 발생 시간(2023/05/10 07:06)의 ASG 평균 CPU 사용량을 살펴보면 실제 CPU 사용량은 임계값(10%) 미만으로 떨어지지 않았습니다. 하지만 scale-in event가 발생이 되었습니다. 이처럼 올바른 Cloudwatch Alarm을 설정하지 않았을 경우에 예상한 방향과는 다르게 Cloudwatch Alarm이 발생할 수 있다는 점을 생각하여야 합니다.
scale-in event 발생

ASG(Auto Scailng Group) 평균 CPU 사용률