Building effective agents 아티클을 정리한 내용입니다.
Agent의 의미
"에이전트(Agent)"는 넓은 의미로 사용되는데 넓게는 평생 동작하는 어떤 복잡한 임무도 수행할 수 있는 완전 자동 시스템을 말하는 경우도 있고, 사전 정의된 워크플로우를 수행하는 구체적인 구현체를 말하는 경우도 있습니다.
Claude를 서비스 중인 Anthropic에서는 이러한 에이전트 시스템을 Agentic system이라 명명하며 딱 두 개의 범주로 나눕니다.
- 워크플로우(Workflow): 사전 정의된 코드 경로대로 동작하는 LLM과 tool로 구성된 시스템
- 에이전트(Agent): LLM이 사용할 수 있는 프로세스와 tool list를 갖고 주어진 임무를 달성하기 위해 동적으로 프로세스를 구축하는 시스템
언제 Agnet를 사용해야 하는지
Anthropic에서는 정말 필요할 때만 시스템에 복잡도를 추가한다고 합니다.
이런 복잡도 관리가 보장이 된다면 문제를 해결하는데 워크플로우가가 거의 항상 적합합니다.
문제를 해결하기 위한 워크플로우의 복잡도를 관리할 수 없을 정도로 규모 있는 어플리케이션에서는 Agent가 적합하다고 하지만, 대부분의 경우에는 단일 LLM API Call만으로도 해결이 가능하다고 합니다.
Framework 도입 검토
Langgraph, Amazon Bedrock, Rivet 등 다양한 에이전트 프레임워크 서비스들이 있습니다.
에이전트 프레임워크는 tool을 정의 및 파싱하고, LLM 호출을 연결하는 저수준의 작업들을 쉽게 구현할 수 있도록 해줍니다.
하지만 이러한 프레임워크는 추상화 계층으로 인한 불필요한 복잡도를 추가하고, 동작에 대한 블랙박스 부분을 만들기 때문에 꼭 필요할 때 도입하는 것이 좋습니다.
시작 단계에서는 LLM API를 직접 호출하는 것부터 시작하는 것을 추천합니다.
Block -> Workflow -> Agent 순으로의 개발
Anthropic이 제시하는 에이전트 시스템을 구축하기 위한 표준 방법에 대해 소개합니다.
Block - The augmented LLM
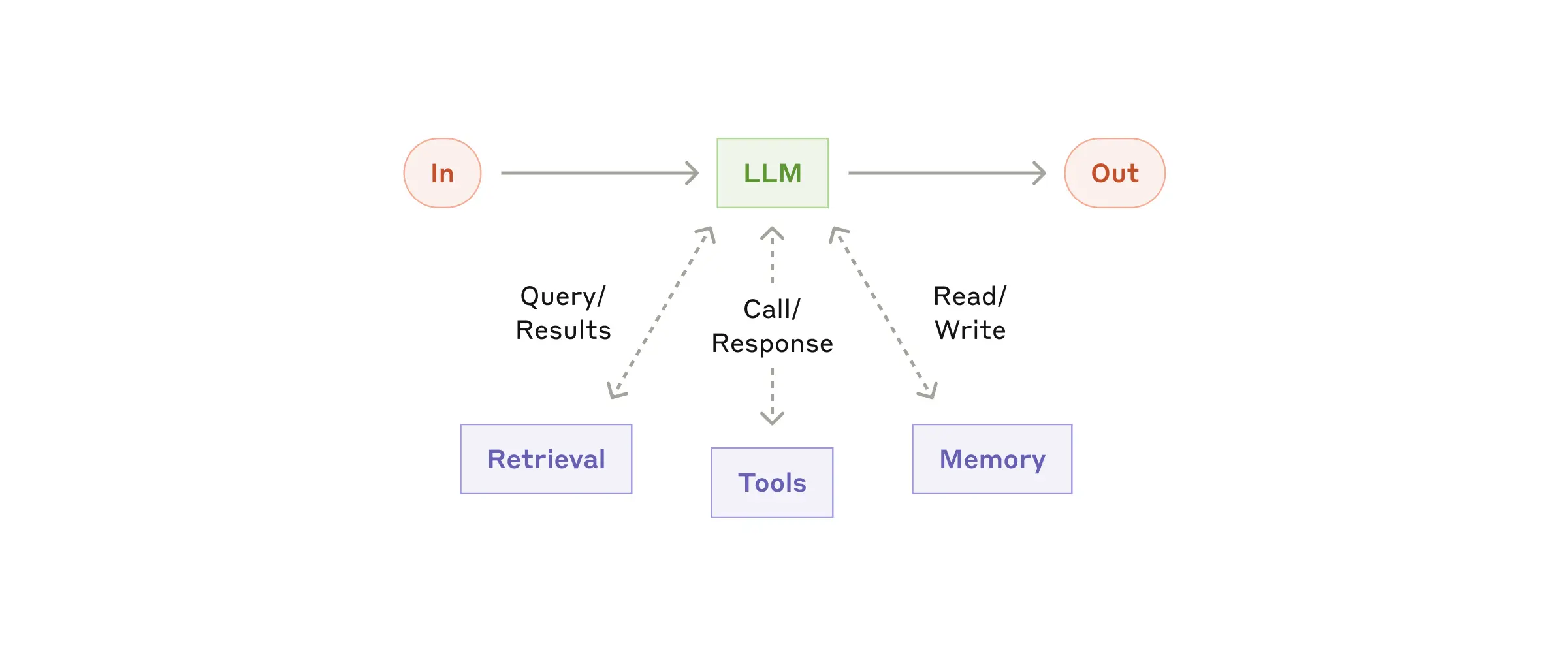
이 단계에서는 시스템의 가장 기초가 되는 LLM이 최상의 성능을 낼 수 있도록 Retrieval, Tool call, Memory (more context)를 도입합니다.
Block을 구현할 때는 구현하고자 하는 특정 사례에 적합한 것인지, LLM 호출이 쉽고 호출에 대해 잘 문서화 되어있는지 두 가지 핵심 관점을 갖고 진행하는 것이 중요합니다.
이를 구현하는 방법에는 여러가지가 있지만, 최근에 등장한 MCP(Model Context Protocol)으로 다른 서비스와 쉽게 통합할 수 있도록 구성하는 것이 좋은 전략입니다.
Workflow
워크플로우는 목적을 달성하기 위한 가장 단순한 형태여야하며, 목적에 따라 여러가지 접근법을 고려할 수 있습니다.
Prompt chaining
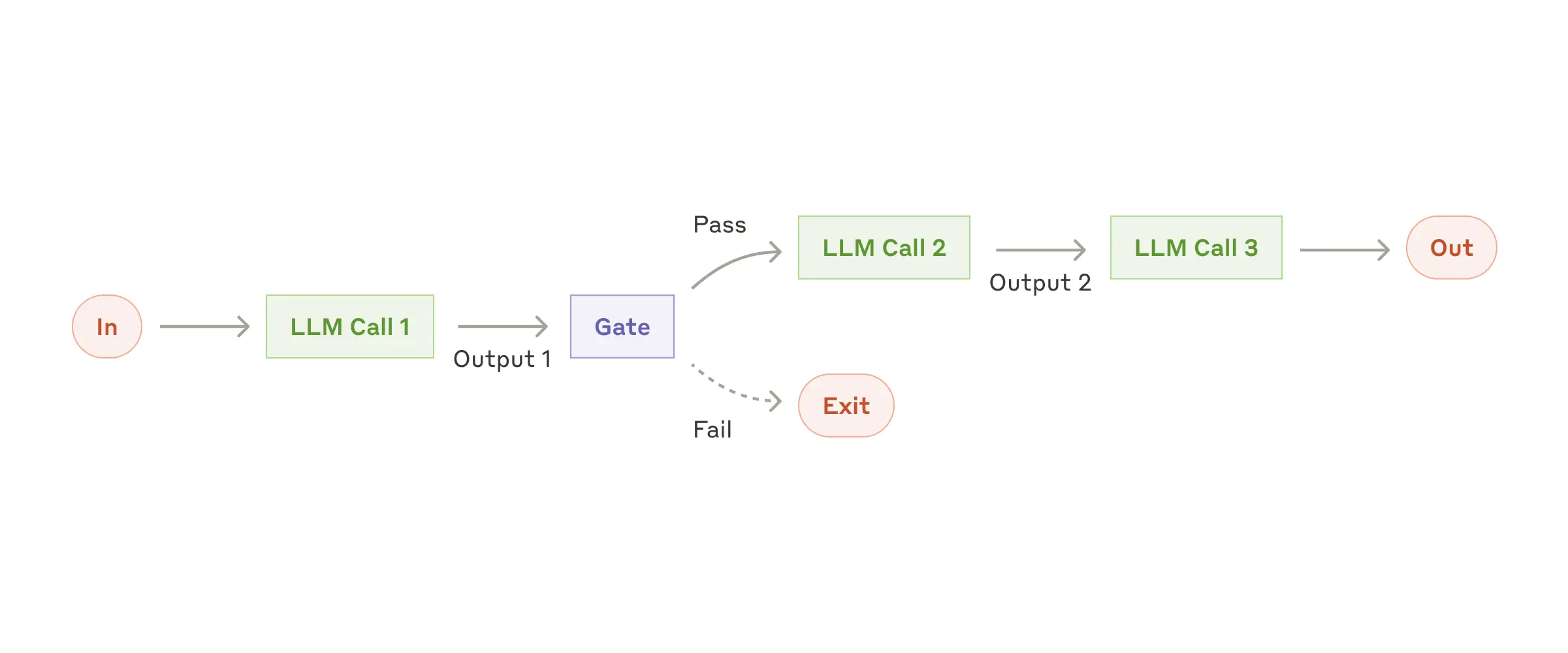
Prompt chaining은 태스크를 여러 단계로 분해하여 각 LLM 호출이 이전 단계의 출력을 처리하는 방식입니다. 중간 단계에서 진행 상황을 확인하기 위해 코드로 검사 로직을 추가할수도 있습니다.
Prompt chaining이 적합할 때
task를 고정된 더 작은 task로 쉽게 분해할 수 있을 때 적합합니다.
LLM 호출을 통해 input을 더 쉬운 task로 만들어 정확도를 높이는 것입니다.
활용 예시
- 문서 생성 후 다른 언어로 번역
- 개요 작성, 개요가 제시된 기준을 충족하는지 확인, 개요를 바탕으로 전체 문서 작성
Routing
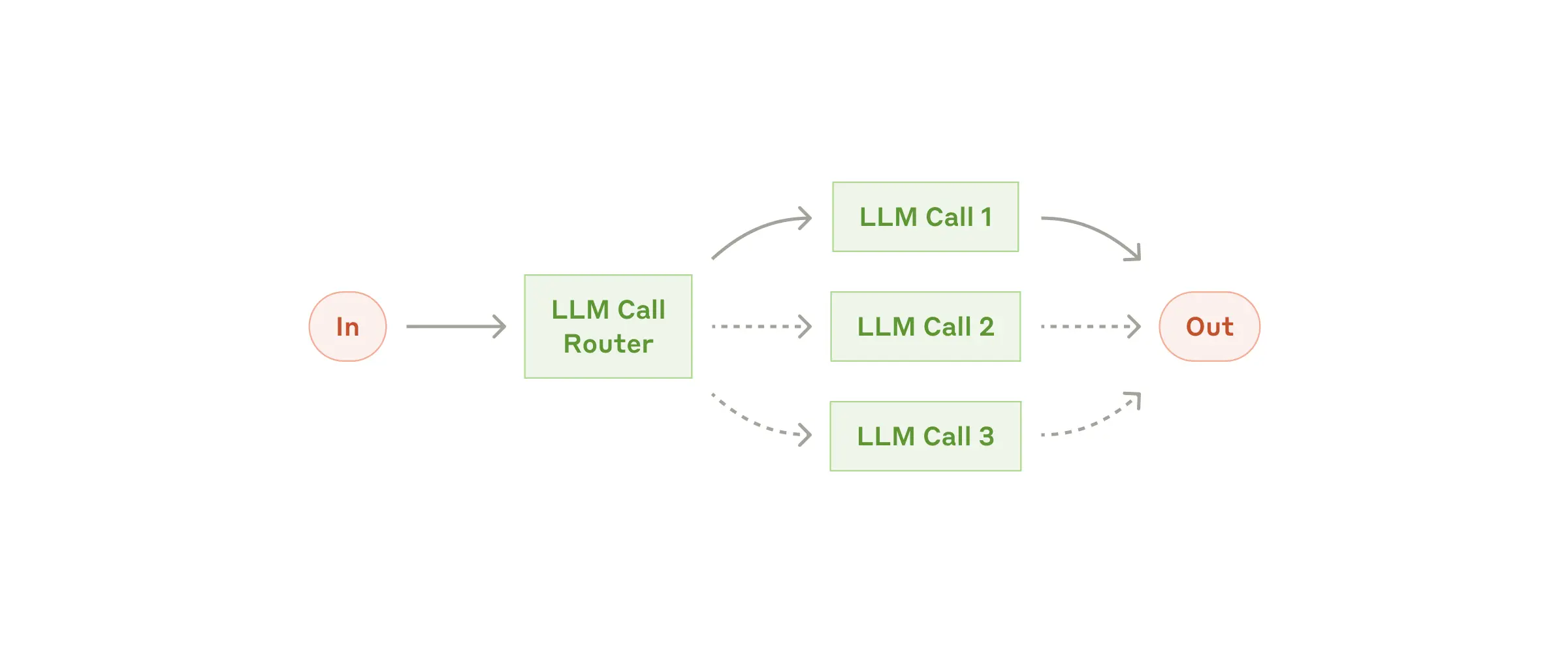
Routing은 입력을 분류하고 전문화된 후속 태스크로 방향을 지정합니다.
위 예시에서 LLM1, LLM2는 서로 다른 시스템 프롬프트를 사용하거나, 서로 다른 모델이 될 수도 있고 심지어는 LLM이 아닌 모델이 될수도 있습니다.
Routing이 적합할 때
명확하게 구분되는 카테고리가 있고, 각 카테고리를 구분해서 처리하는 것이 좋을 때 유용합니다. 분류를 하는 Router는 LLM 뿐만 아니라 전통적인 분류 모델/알고리즘을 활용할 수 있으며 정확하게 처리되는 것이 중요합니다.
활용 예시
- 서비스 챗봇(일반 질문, 환불 요청, 기술 지원)를 다음 프로세스, 프롬프트, 도구로 안내
- 쉽고 일반적인 질문은 작은 모델로, 어렵고 특이한 질문은 더 강력한 모델로 라우팅하여 비용과 속도 최적화
Parallelization
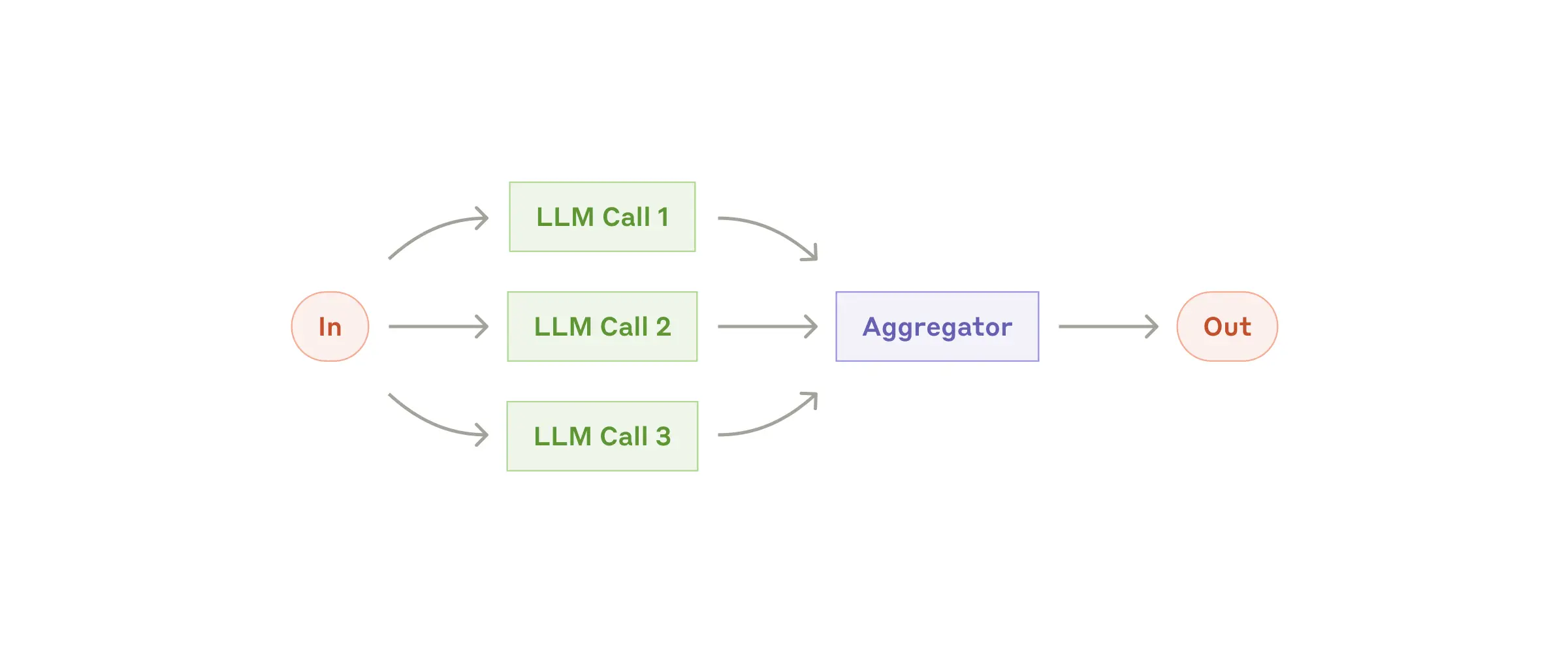
어떤 경우는 여러 LLM이 동시에 output을 출력하고, 프로그래밍적으로 이들을 적절히 합치는 유형의 task가 있습니다. 여기에는 크게 두 가지 유형이 있습니다.
- Sectioning: 하위 task 여러개를 동시에 수행
- Voting: 다양한 output을 위해 같은 task를 여러번 수행
Parallelization이 적합할 때
- Sectioning -> 병렬 처리가 속도를 향상시킬 수 있을 때
- Voting -> 더 신뢰성있는 결과를 위해 다양한 관점, 시도가 필요할 때
활용 예시
-
Sectioning
- 응답 LLM이 사용자의 요청을 처리하는 동안, 병렬 실행되는 다른 모델이 부적절한 콘텐츠나 요청을 검사
- LLM 성능을 평가할 때 특정 관점을 더 중요하게 보도록 지시하는 서로 다른 시스템 프롬프트를 넣어 병렬적으로 실행 -
Voting
- 여러 다른 프롬프트로 코드 취약점이나 콘텐츠 적절성 등을 검토하여 점수 집계
Orchestrator-workers
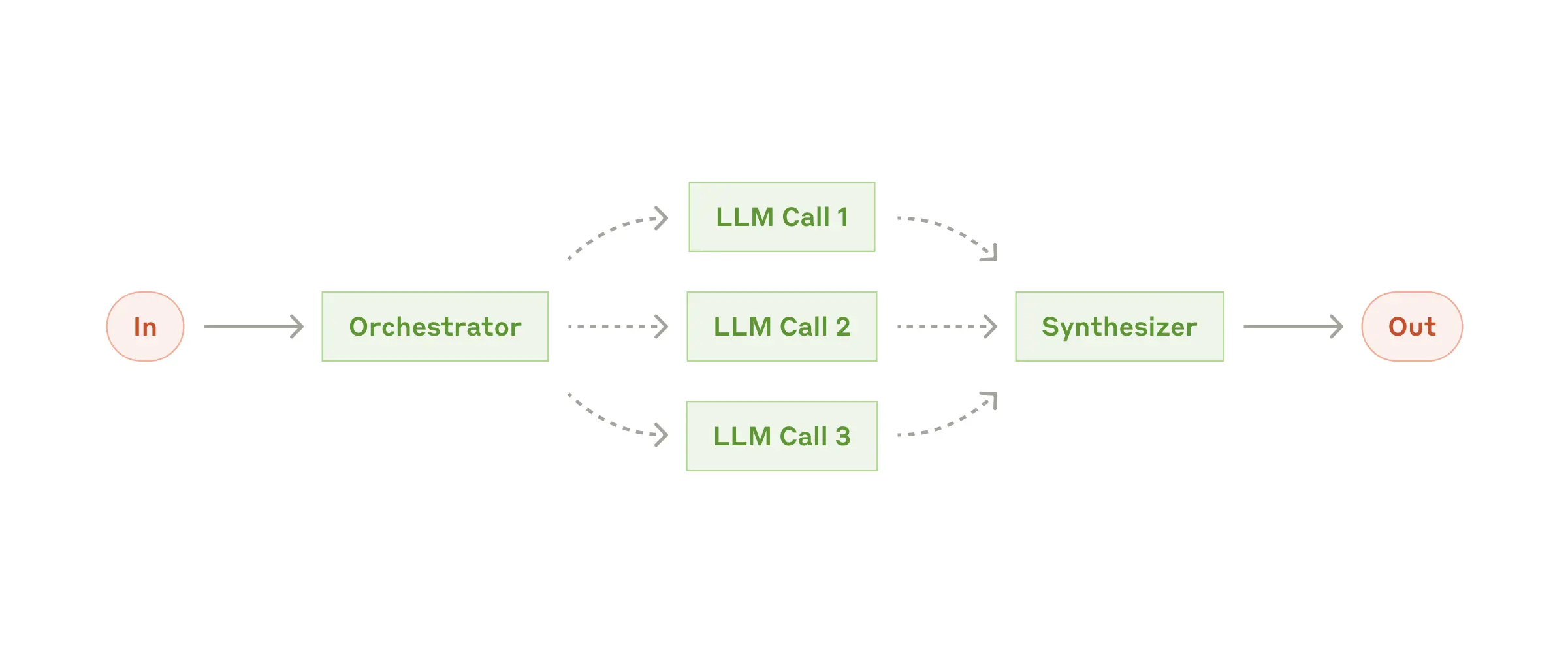
중앙 LLM(workers)이 task를 자율적으로 분리하고, 각 subtask의 실행 결과를 합치는 워크플로우입니다.
Parallelization과 유사한 구조를 갖지만 subtask가 사전 정의되어있지 않고, input에 따라 orchestrator가 결정하는 것이 주요 차이점입니다.
Orchestrator-workers가 적절할 때
task가 복잡하여 rule-based로는 subtask를 분리하기 어려울 때 사용합니다.
활용 예시
- 코딩 프로젝트 (여러 파일을 참조하여 여러 개의 다른 파일을 동시에 수정해야 함)
- 복잡한 검색 (파일 및 인터넷 등 여러 source에서 사용자 쿼리에 맞는 정보를 가져와 조합)
Evaluator-optimizer
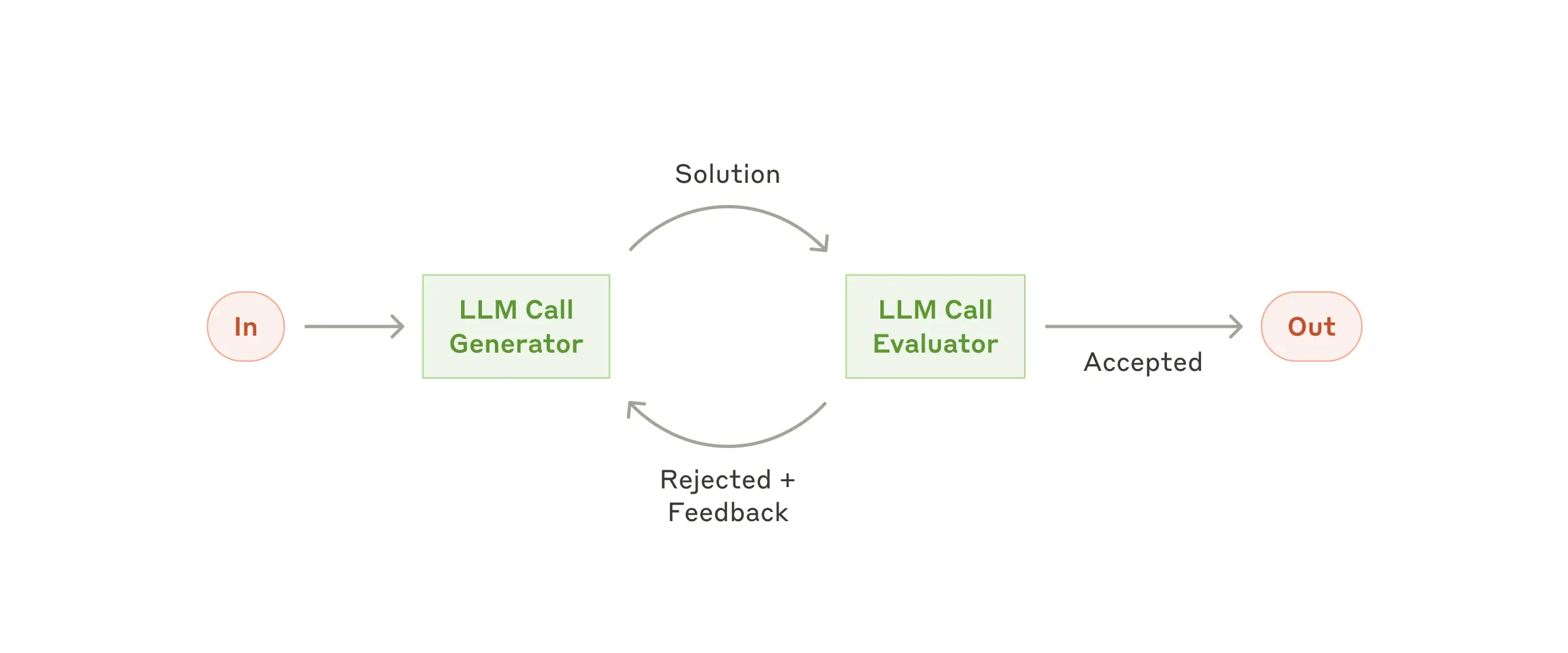
LLM이 생성한 답변을 평가하는 Evaluator가 별도로 존재하여, 답변이 accept 될 때까지 피드백 및 생성을 반복하는 워크플로우 입니다.
Evaluator-optimizer가 적절할 때
모델이 output을 생성할 때, 명확한 평가 기준이 있고 반복을 통한 개선을 측정할 수 있는 task에 적합합니다. 여기에 부합하는 두 가지 기준은 첫째는 인간의 개입(피드백)으로 output을 개선할 수 있는 유형의 task인지, 또 피드백을 LLM이 제공할 수 있는지입니다.
활용 예시
- 문학 작품 번역 (번역의 뉘앙스, 문맥 등이 중요한 번역 task)
- 포괄적인 정보를 수집하기 위해 여러 단계의 검색과 분석이 필요한 복잡한 검색 task
Agents
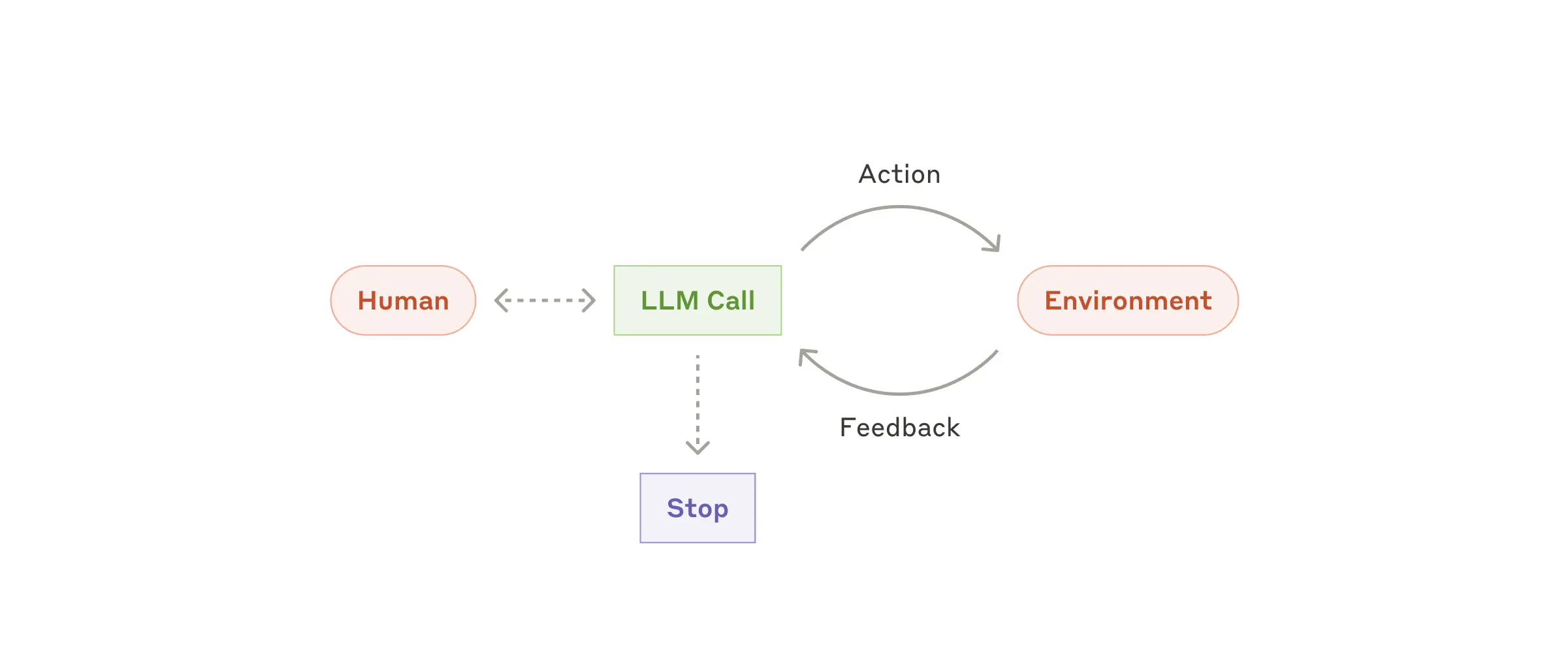
에이전트는 사용자로부터의 명령이나 대화로 작업을 시작합니다. task가 명확해지면, 에이전트는 독립적으로 계획하고 작동하며, 필요시에만 추가 정보나 판단을 위해 사용자와 상호작용을 합니다.
실행 중에 각 단계마다 tool calling이나 code execution을 수행하기 전에 "ground truth"를 바탕으로 현재 진행 상황을 평가하는 것이 중요합니다.
또한 체크포인트나 중단점을 만났을 때 사용자의 피드백을 요청할 수 있습니다. 또 일반적으로 task 완료 시 에이전트가 종료되지만, 예상치 못한 동작을 막고 제어를 유지하기 위해 최대 반복 횟수와 같은 중지 조건을 추가하는 것이 좋습니다.
이렇게 에이전트는 복잡한 task를 처리할 수 있는 훌륭한 도구이지만, 실제 구현은 생각보다 간단합니다. 일반적으로는 단순히 주변 환경에서 주어지는 feedback loop를 바탕으로 tool을 호출하는 LLM입니다. 즉 에이전트의 성공을 위해서는 tool set과 문서를 명확하고 신중하게 설계하는 것이 매우 중요합니다.
에이전트가 적절할 때
문제 해결에 필요한 단계 수를 예측하기 어렵거나 불가능하고, 고정된 경로를 하드코딩할 수 없는 문제 해결에 적절합니다.
또한 LLM이 오작동하더라도 감당할 수 있는 신뢰할 수 있는 환경에서 task를 수행할 수 있을 때 적합합니다. 신뢰할 수 있는 환경이라도 AI의 자율적인 특성으로 인해 많은 비용과 오류가 발생할 수 있기 때문에 출시 전에 광범위한 테스트와 적절한 가드레일을 함께 사용하는 것이 좋습니다.
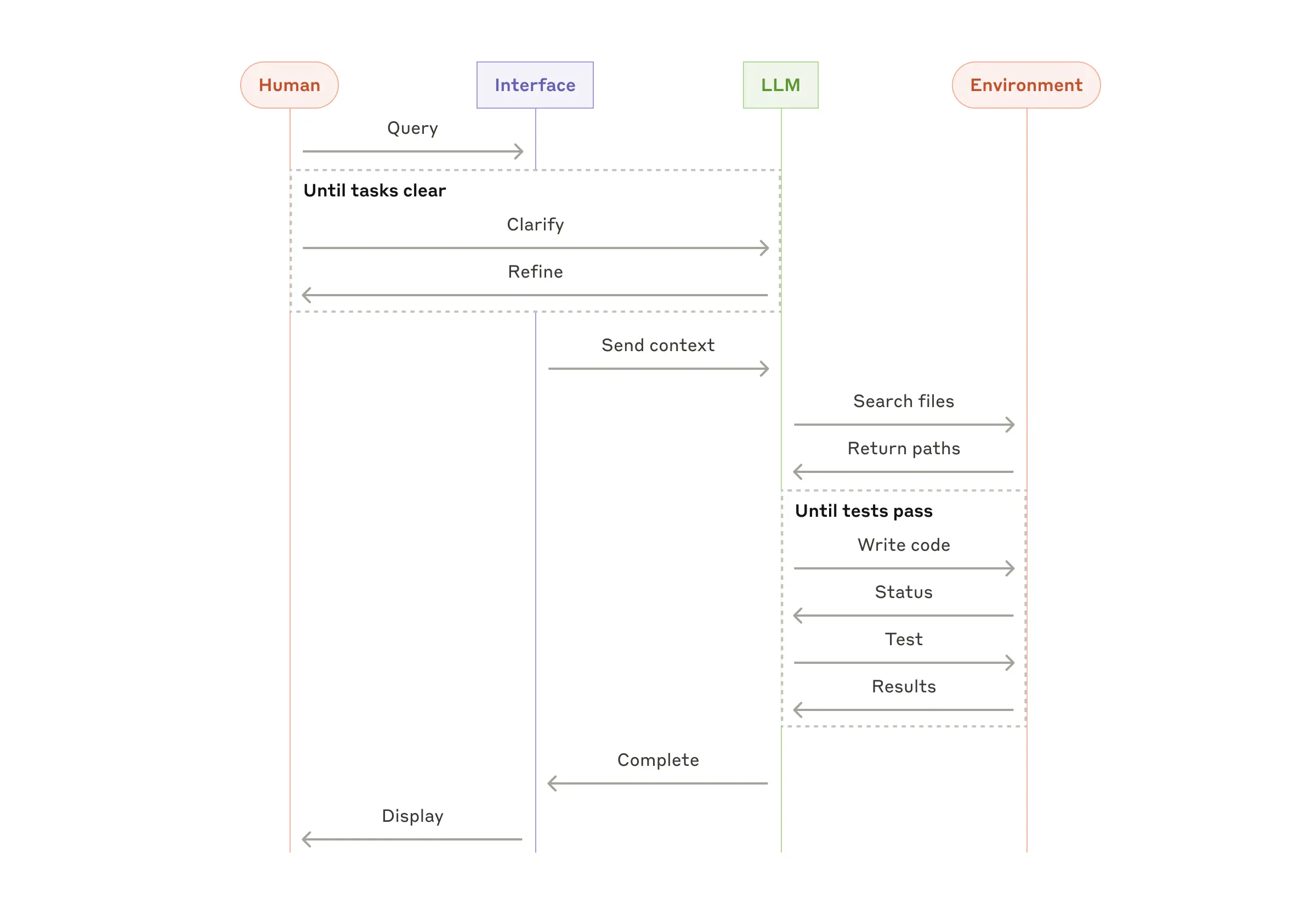
위 다이어그램은 Anthropic의 서비스 중 하나인 coding agent의 고수준 flow chart입니다.
아티클에서는 더 다양한 사례에 대해 자세히 소개하지만 중요한 것은 정말 필요할 때만 복잡도를 증가시킨다라는 원칙인 것 같습니다. 오컴의 면도날이 생각나네요
Summary
LLM 분야에서 성공하기 위해서는 가장 훌륭한 시스템을 구축하는 것이 아니라, 필요한 시스템을 구축하는 것입니다.
단순한 프롬프트로 시작하고, 간단한 방법으로 문제를 해결할 수 없을 때만 다단계 agentic 시스템을 추가하세요.
Anthropic은 에이전트를 구현할 때 다음의 세 가지 핵심 원칙을 따릅니다.
1. 에이전트 설계의 단순성을 유지
2. 에이전트의 계획 단계를 명시적으로 보여줌으로써 투명성 확보
3. 철저한 도구 문서화와 테스트를 통해 에이전트-컴퓨터 인터페이스(ACI) 최적화
프레임워크는 빠른 구현에는 도움이 되지만 프로덕션 단계에서는 신뢰성과 유지 보수를 위해 최대한 추상화된 레이어를 줄이고 직접 구축하는 것을 고려하는 것이 좋습니다.
