프로듀서 동작
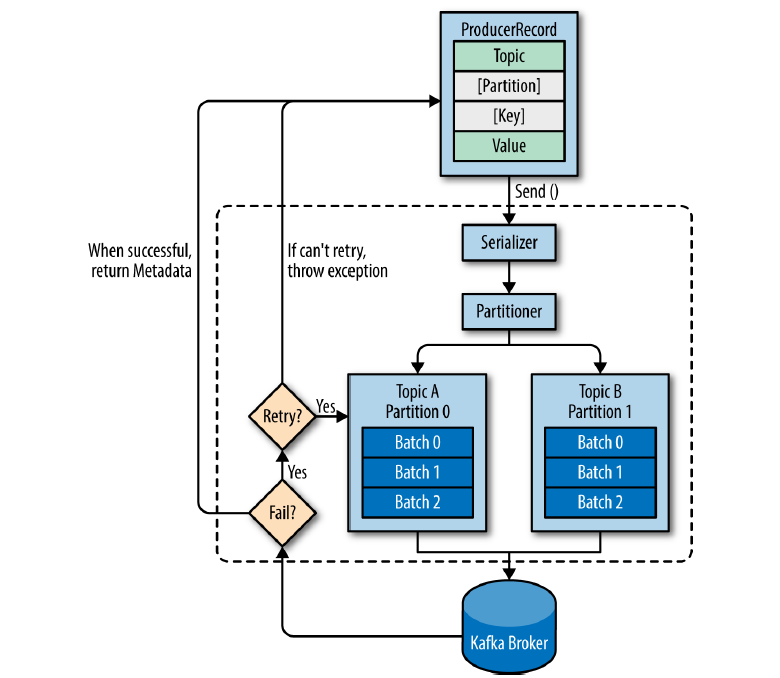
사용자는 프로듀서를 통해 Kafka에 메시지를 보내게 되는데 해당 데이터는 ProducerRecord 형태로 전송되어야 합니다. ProducerRecord는 반드시 Topic과 Value값을 가져야 하며 어느 파티션에 전송할지를 의미하는 Partition과 레코드 정렬을 위한 Key는 선택값입니다.
사용자가 메시지를 send() 메소드로 보내게 되면 프로듀서가 처음으로 하는 일은 Serializer를 통해 key/value 형태의 데이터를 ByteArray로 바꾸는 일입니다. 데이터가 성공적으로 변환되면 변환된 데이터는 파티셔너로 전송됩니다. 만약 ProducerRecord에 Partition을 지정했다면 파티셔너는 아무일도 하지 않고 단순히 지정한 파티션을 반환해줍니다. 만약 아무것도 지정하지 않았다면 파티셔너가 Key값을 이용해 파티션을 선택해서 반환해주는데 기본적으로는 round robin 방식으로 동작하게 됩니다.
위의 작업이 끝나면 프로듀서는 어느 토픽과 파티션으로 메시지를 전송할 지 알 수 있게 됩니다. 프로듀서는 작업을 마친 후 바로 메시지를 전송하지 않고 토픽과 파티션이 같은 데이터를 배치로 전송하기 위해 잠시 모아둡니다.
서로 다른 쓰레드가 배치 전송을 담당하게 되며, 브로커가 메시지를 수신하면 프로듀서에게 응답을 반환해줍니다. 메시지가 성공적으로 쓰여지면 토픽과 파티션 등의 정보가 담긴 Record Metadata를 반환해주며 실패할경우 에러를 반환합니다.
에러가 반환될경우 프로듀서는 몇 번 전송을 반복하며 최종적으로 실패하게 되면 예외를 반환합니다.
프로듀서 옵션
- bootstrap.servers
host:port 형식의 리스트로 클라이언트가 카프카 클러스터에 처음 연결하기 위한 정보를 적게됩니다. 처음 연결이 성공하면 프로듀서가 추가적인 정보를 알게 되므로 모든 브로커의 주소를 적을 필요는 없습니다. - acks
프로듀서가 카프카 토픽의 리더에 메시지를 전송한 후 요청을 완료하기를 기다리는 옵션입니다. 0, 1, -1로 표현하며, 0은 유실있는 빠른 전송, 1은 메시지를 받았는지 리더만 확인, -1은 리더와 팔로워 모두 메시지를 받았는지 확인합니다. - compression.type
전송시 선택할 압축 타입입니다. none, gzip, snappy, lz4, zstd 중 하나를 선택하면 됩니다. - key.serializer
key/value 형태의 데이터를 직렬화 할 때 key를 직렬화 하기 위해 사용할 클래스를 정하는 옵션입니다. org.apache.kafka.common.serialization.Serializer 인터페이스를 상속해서 구현되어야 합니다. - value.serializer
key.serializer와 동일한 역할을 하며 대신 value를 직렬화합니다. org.apache.kafka.common.serialization.Serializer 인터페이스를 상속해서 구현되어야 합니다. - retries
전송에 실패할경우 최대로 재전송 가능한 횟수입니다. - batch.size
프로듀서가 동일한 토픽을 동일한 파티션으로 보내려 할 때 모아서 전송할 크기입니다. linger.ms로 배치 전송시 추가적인 메시지를 대기하는 시간을 설정합니다.
코드적 전송 방법
메시지 보내고 무시
단순하게 메시지를 보내고 반환값을 무시하면 되는 방법입니다. 정상/비정상 상황을 검사하지 않으므로 운영환경에서는 추천되지 않습니다.
동기 전송
메시지를 보내고 반환값이 올때까지 동기적으로 대기하는 방법입니다. 전송이 되었는지 확인하므로 신뢰성 있는 메시지 전달이 가능합니다.
비동기 전송
콜백 인터페이스를 구현하여 성공할경우의 동작과 실패할경우의 동작을 비동기적으로 작업하게 하는 방법입니다. 동기 방식에 비해 더욱 많은 메시지를 보낼 수 있습니다.
전송 과정
프로듀서가 전송하는 메시지는 send() 메소드를 통해 시리얼라이저, 파티셔너를 거쳐 카프카로 전송됩니다.
파티셔너
프로듀서는 토픽으로 메시지를 보낼 때 어느 파티션으로 보낼지 결정해야 하는데 이를 결정해주는 것이 파티셔너입니다. 파티션은 기본적으로 메시지의 키를 해시해 결정합니다. 따라서 키 값이 동일하면 같은 파티션으로 전송됩니다.
만약 많은 양의 메시지를 전송해야 할 경우 파티션을 늘리 수 있는데, 파티션 수가 변경되면 메시지의 키와 매핑된 해시테이블도 변경되므로 파티션을 늘리기 전과 후의 해시 결과값이 달라져 다른 파티션으로 보내질 수 있습니다. 관리자의 의도와 다르게 전송될 수 있으므로 되도록 파티션 수를 변경하지 않는 것을 권장합니다.
라운드 로빈 전략
메시지의 키 값은 필수값이 아니므로 메시지를 전송할 때 별도의 키를 제공하지 않고 전송할 수 있습니다. 이럴경우 기본적으로 라운드로빈 전략으로 동작하게 됩니다.
스티키 파티셔닝 전략
프로듀서의 전송은 기본적으로 배치 전략을 따릅니다. 배치 전송을 할 때 단순한 라운드 로빈으로 전송할경우 새로운 메시지마다 다음 파티션으로 배치되므로 파티션의 배치가 다 차기 전까지, 배치 대기시간이 초과되기 전까지 대기하고 전송하게 되어 효율이 떨어집니다.
카프카는 이를 효율적으로 처리하기 위해 스티키 파티셔닝 전략을 도입했습니다. 스티키 파티셔닝은 하나의 파티션에 메시지를 먼저 채워서 카프카로 배치 전송하는 전략입니다. 따라서 단순한 라운드 로빈보다 빠르게 메시지를 전송할 수 있습니다.
메시지의 순서가 그다지 중요하지 않다면 스티키 파티셔닝 전략을 이용하는게 좋습니다.
배치
프로듀서 전송은 카프카의 요청 수를 줄이고 IO 비용을 줄이기 위해 배치 전략을 따릅니다. 이에 관한 설정은 buffer.memory, batch.size, linger.ms 을 통해 결정하게 됩니다.
배치 전략은 효율적이지만 반드시 사용해야 하는 전략은 아닙니다. 카프카 사용 목적에 따라 처리량을 높일지, 지연 없는 전송을 해야 할지 선택해야 합니다. 만약 처리량이 높아야 한다면 batch.size와 linger.ms의 값을 크게 설정하고, 지연 없는 전송이 목적이면 batch.size와 linger.ms의 값을 작게 해야 합니다.
전송 방법
카프카는 전송 방법으로 '적어도 한 번 전송', '최대 한 번 전송', '정확히 한 번 전송' 방법을 제공합니다.
적어도 한 번 전송
적어도 한 번 전송은 브로커가 프로듀서에게 메시지를 받고 브로커가 ACK를 응답할 때, 중간에 유실될경우 프로듀서가 다시 전송하는 방법입니다. 메시지가 중복될 수 있지만 최소한 하나의 메시지는 반드시 보장하는 방법으로 카프카의 기본 전송 동작입니다.
최대 한 번 전송
최대 한 번 전송은 프로듀서에게 메시지를 받고 브로커가 ACK를 응답할 때, 중간에 유실될경우 프로듀서가 다시 전송하지 않고 다음 메시지를 전송하는 방법입니다. 메시지가 유실되어도 괜찮고 속도가 중요한 로그 수집이나 IoT 환경에서 주로 사용합니다.
중복 없는 전송
중복 없는 전송은 프로듀서가 고유한 PID를 할당받고, 이 PID와 메시지에 대한 번호(시퀀스 번호)를 메시지의 헤더에 포함해 브로커에게 전송하는 방법입니다. 브로커는 메시지를 받을 때 이전 시퀀스 번호의 다음 번호가 아니면 메시지를 무시하고, 다음 번호일경우 저장하게 되어 중복 없는 전송을 보장합니다.
이 번호들을 브로커의 메모리와 리플리케이션 로그에 저장하게 되어 브로커 장애가 발생해도 새로운 리더가 PID와 시퀀스 번호를 알 수 있어 중복 없는 메시지 전송이 가능해집니다.
중복 없는 전송은 당연히 오버헤드가 존재하며 성능에 민감하지 않고 정확성이 중요할경우 사용하면 됩니다. 이와 관련된 설정은 enable.idempotence, max.in.flight.requests.per.connection, acks, retries 입니다.
정확히 한 번 전송
정확히 한 번 전송은 중복 없는 전송 + 트랜잭션 API를 통해 구현하게 됩니다.
정확히 한 번 전송할 때, 프로듀서의 메시지는 Atomic하게 처리하게 되어 전송에 성공하거나 실패하게 됩니다. 이를 위해 카프카는 트랜잭션 코디네이터를 제공해줍니다. 트랜잭션 코디네이터는 프로듀서에 의해 전송된 메시지를 관리하며, 커밋 또는 중단을 표시합니다. 트랜잭션 관련 로그는 __transaction_state에 저장하게 됩니다.
과정
- 프로듀서가 브로커에게 코디네이터 위치 요청
- 프로듀서가 TID, PID를 트랜잭션 코디네이터가 위치한 브로커에 전송
- 트랜잭션 코디네이터는 TID, PID를 매핑해서 트랜잭션 로그에 기록
- 프로듀서가 토픽 파티션 정보를 트랜잭션 코디네이터에 전달
- 트랜잭션 코디네이터가 트랜잭션을 Ongoing 상태로 변경
- 프로듀서 메시지 전송
- 프로듀서 트랜잭션 완료를 코디네이터가 위치한 브로커에 전송
- 6의 메시지를 받은 브로커는 트랜잭션 코디네이터와 통신해 커밋 표시
- 트랜잭션 코디네이터가 트랜잭션을 Committed로 표시하고 프로듀서에게 완료됨을 알림
- https://dzone.com/articles/take-a-deep-dive-into-kafka-producer-api
- 실전 카프카 개발부터 운영까지 3장, 5장
