데이터베이스
Database와 DBMS의 차이에 대해서 설명해 보세요.
- Database는 데이터가 실제 저장되는 저장소와 데이터를 합친 집합체입니다.
- DBMS는 데이터베이스를 효율적으로 관리하기 위한 시스템입니다.
데이터 독립성에 대해서 설명해 보세요.
- 하위 단계의 데이터 구조가 변경되더라도 상위 단계에 영향을 미치지 않게 하기 위한 속성입니다.
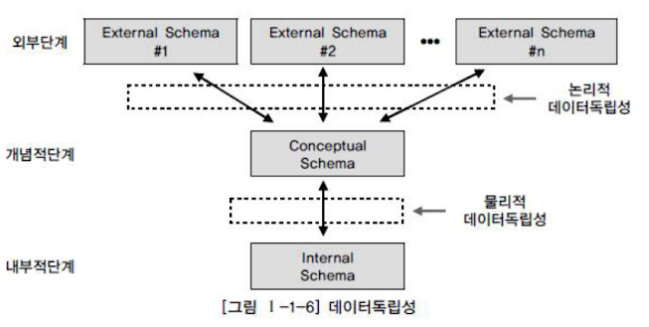
- 논리적 데이터 독립성과 물리적 데이터 독립성이 있습니다.
논리적 데이터 독립성
- 응용 프로그램에 영향을 주지 않고 데이터베이스 논리적 구조를 변경할 수 있는 능력입니다.
물리적 데이터 독립성
- 응용 프로그램이나 데이터베이스의 논리적 구조에 영향을 미치지 않고 데이터의 물리적 구조를 변경할 수 있는 능력
데이터 독립성의 기대효과에 대해서 설명해주세요.
- 데이터를 접근하는 응용프로그램에 영향을 미치지 않고도 데이터를 처리하는 하드웨어나 소프트웨어를 보다 발전된 형태로 변경 또는 대체 가능합니다.
데이터베이스의 스키마란 무엇인가요?
- 데이터베이스의 논리적 보기를 나타내는 일종의 골격구조입니다.
- 데이터베이스를 구성하는 데이터 개체(entity), 속성(Attribute), 관계(Relationship) 및 데이터 조작시 데이터 값들이 갖는 제약 조건 등에 관해 전반적으로 정의 합니다.
- MySQL에서는 데이터베이스.객체 라는 식으로 테이블을 지칭하는데, 여기서 데이터베이스가 스키마입니다.
- ERD를 물리적인 Table, Index, Constraint로 구현한 것이 DB 스키마입니다.
- 여기서 ERD는 설계도이며, DB 스키마는 설계도를 구현한 것입니다.
개체(Entity)
- 현실세계에 대해 사람이 생각하는 개념이나 정보의 단위.
속성(Attribute)
- 개체의 성질이나 상태를 기술해주는 역할
관계(Relationship)
- 속성 관계와 개체 관계가 있다.
- 각 속성들간의 혹은 각 개체들간의 이어져 있는 선을 관계라고 한다.
예시
- '학생'이라는 개체

-
'학번', '이름', '학과'라는 3개의 속성들로 구성된다.
-
이 속성들이 모여 '학생'이라는 개체를 표현할 때 의미가 생긴다.
-
'학생'개체와 '교수'개체
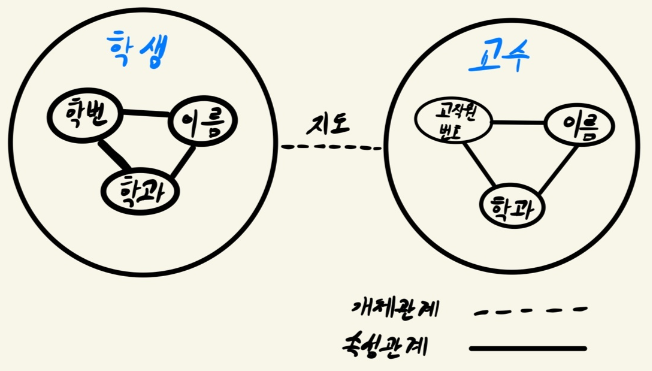
-
DB에서는 일반적으로 개체 관계만 명시적으로 취급, 속성 관계는 암시적으로 취급.
-
학번으로 학생의 이름을 검색하려면 속성 관계를 통해 정보 검색
-
학번으로 학생의 지도교수 이름을 검색하려면 '지도'라는 개체 관계를 통해 검색
즉, 개체(Entity)는 데이터베이스에 저장하려는 대상, 속성(Attribute)은 그 개체가 가지고 있는 특징이나 정보를 나타냅니다, 관계는 개체 간 혹은 속성 간의 연결 고리이다.
table과 entity는 같은 개념이 아니다. table은 entity의 하위 개념이라고 생각하면 된다. 데이터베이스에서 entity를 저장하는데 사용되는 구조이다.
따라서, 엔터티는 데이터베이스에 저장하려는 대상을 나타내고, 테이블은 실제로 데이터를 저장하는 데 사용되는 구조입니다. 테이블은 엔터티를 저장하는 방법 중 하나이며, 데이터베이스에 따라 다른 방식으로 엔터티를 저장할 수도 있습니다.
각 table의 row는 특정 entity의 인스턴스를 나타낸다.
각 table의 column은 특정 entity의 속성을 나타낸다.
스키마 3 계층에 대해서 아시나요? 아신다면 서술해주세요.
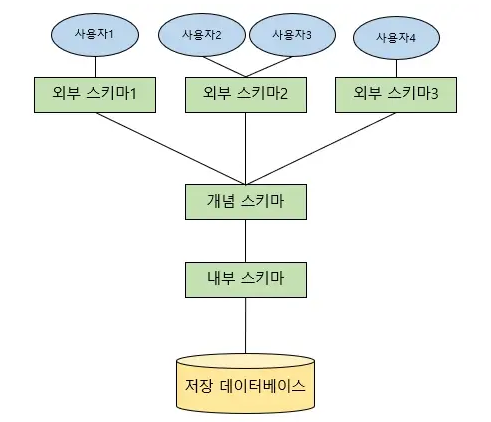
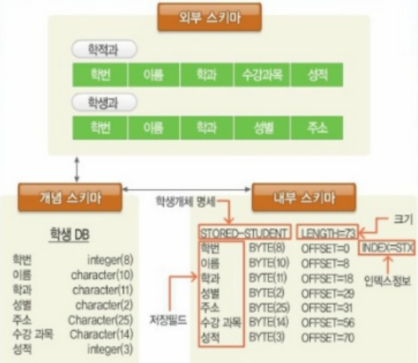
- 스키마 3 계층은 하나의 데이터베이스를 관점에 따라 세 단계로 나눈 것입니다.
- 외부 스키마, 개념 스키마, 내부 스키마가 있습니다.
외부 스키마
- 외부 스키마는 개별 사용자 관점에서 논리적 구조를 정의한 것입니다. 사용자 관점에 따라 필요한 엔터티와 컬럼이 다른 것을 볼 수 있습니다.
개념 스키마
- 개념 스키마는 외부 스키마를 통합한 조직 전체 데이터 베이스 구조를 논리적으로 정리한 것입니다.
내부 스키마
- 전체 데이터 베이스의 물리적 저장 형태를 기술한 것입니다.
데이터 독립성
- 스키마들은 데이터 독립성 (데이터베이스 내의 데이터, 데이터를 사용하는 사용자 및 응용 프로그램, 데이터베이스의 저장 구조가 서로 영향을 받지 않는 성질)을 가집니다.
- 즉, 개념 스키마가 변경되어도, 외부 스키마에 영향을 주지 않아야 하고, 내부 스키마가 변경되어도, 개념 스키마/외부 스키마에 영향을 주지 않아야 합니다.
primary key에 대해서 알고 계시죠? 설명해주세요.
- 후보키 중 선택한 메인 키로써, 각 row(record)를 unique 하게 구분하는 column(속성) 입니다.
- 그렇기 때문에 null 값을 가질 수 없으며, 중복된 값을 가질 수 없습니다. table 당 1개만 지정해야 합니다.
그렇다면 foreign key는 무엇이죠?
- 다른 table의 primary key column을 참조하는 table의 column 입니다.
super key는 무엇이죠?
- 각 row를 유일하게 식별할 수 있는 하나 또는 그 이상의 column들의 집합입니다.
candidate key(후보키)는 무엇이죠?
- super key 중에서 더 이상 쪼개질 수 없는 superkey를 후보키라고 합니다.
alternative key(대체키)는 무엇이죠?
- primary key로 선택받지 못한 후보키들입니다.
관계형 데이터베이스의 N:M 관계에 대해서 설명해주세요.
- RDB에서 양쪽 entity 모두 서로가 1:N 관계를 가지고 있는 구조입니다.
- 예를 들면 학생 entity와 과목 entity가 있을 때, N:M 관계를 가지게 됩니다.
- 특정 학생은 여러 과목을 선택할 수 있으며, 특정 과목 또한 여러 학생들에게 선택될 수 있습니다.
left outer join과 inner join에 대해서 차이를 설명해주세요.
- join은 두 개 이상의 테이블을 서로 연결하여 하나의 결과를 보여줍니다.
- inner join은 두 테이블에 모두 있는 내용만 join이 됩니다. A 교집합 B와 같습니다.
- 하지만 left outer join은 왼쪽 table인 A와 오른쪽 table인 B가 있는데, B에 있는 column을 포함해서 A 전체를 보여줍니다.
- B의 내용이 A에 없다면 null 값으로 표현됩니다.
RDB와 NoSQL를 비교 설명해주세요.
- RDB는 관계형 데이터베이스로 엄격하게 정의된 DB schema를 요구하는 table 기반 구조를 가집니다.
- NoSQL은 비관계형 데이터베이스로 table 형식이 아닌 비정형 데이터를 저장할 수 잇도록 지원합니다.
- RDB는 엄격한 schema로 인해 데이터 중복이 없어 데이터 update가 많을 때 유리합니다.
- 반면 NoSQL은 데이터 중복으로 인해 잦은 update가 있다면 중복된 데이터를 같이 update 해줘야 해서 update가 적고 조회가 많을 때 유리합니다.
NoSQL이 왜 조회가 많을 때 유리한가요?
- NoSQL은 key-value 형태의 데이터 모델을 사용해 단일 레코드에 대한 검색 및 쓰기 작업에 최적화 되어있습니다.
- 그리고 단순하면서도 확장성이 뛰어나기 때문에 big data 시스템에서 많이 사용됩니다.
RDBMS와 NoSQL의 확장 방법에 대해 설명해주세요.
- RDBMS는 보통 수직 확장을 사용합니다. 이는 하드웨어 자원의 업그레이드, 즉 더 많은 CPU나 메모리를 사용하여 데이터 처리 능력을 향상시키는 방법입니다.
- 반면 NoSQL은 수평 확장을 사용합니다. 이는 여러 대의 컴퓨터에 데이터를 분산하여 처리하는 방법입니다. 이 방법은 데이터 양이 증가하더라도 서버를 추가하면 처리 능력을 높일 수 있으므로 대규모 데이터 처리에 적합합니다.
얘기를 들어보면 수평 확장이 더 간편해보이는데, RDBMS는 왜 수평적 확장을 하지 않죠?
- RDB는 ACID와 트랜잭션을 보장하기 위해 수평적 확장이 쉽지가 않습니다. 그리고 multiple server로 수평적 확장을 하게 되면 join을 하기 위해 굉장히 복잡한 과정이 필요합니다.
transaction에 대해서 설명해주세요.
- 트랜잭션은 데이터베이스 내에서 수행되는 작업의 최소 단위로, 데이터베이스의 무결성을 유지하며 DB의 상태를 변화시키는 기능을 수행합니다.
- 트랜잭션은 하나 이상의 쿼리를 포함해야 하고, ACID 4가지 규칙을 만족해야 합니다.
ACID에 대해서 설명해주세요.
- A는 Atomicity 원자성입니다. 트랜잭션에 포함된 작업이 모두 수행이 되거나 수행이 되지 않는 하나의 작업으로 이루어져야 합니다.
- C는 Consistency 일관성입니다. 트랜잭션이 실행을 완료하면 일관성 있는 db 상태로 유지하는 것을 의미합니다.
- 예를 들면 송금을 하기 전과 송금을 한 후에 잔액의 data type은 integer여야 하는 것입니다.
- I는 Isolation 고립성입니다. 여러 트랜잭션이 동시에 수행될 때 각 트랜잭션은 다른 트랜잭션의 연산작업에 끼어들지 못하도록 독립적으로 작업을 수행해야 합니다.
- D는 Durability 지속성입니다. 수행된 트랜잭션은 데이터베이스에 영원히 반영되어야 함을 의미합니다.
Commit과 Rollback에 대해서 아시나요? 아신다면 설명해주세요.
- commit은 트랜잭션 작업을 완료했다고 확정하는 명령어입니다. commit 명령어가 실행되면 작업 내용이 실제 DB에 저장되고, DB가 변경됩니다.
- rollback은 작업 중 문제가 발생해서 다시 되돌리고 싶을 때 변경 사항을 취소하고 이전 commit 상태로 되돌려줍니다.
동시성 제어(concurrency control)란 무엇이죠?
- 트랜잭션이 동시에 수행될 때 일관성을 해치지 않도록 트랜잭션의 데이터 접근을 제어하는 DBMS의 기능입니다.
어떤 식으로 접근을 제어하나요?
- 보통 작업을 하고 있는 트랜잭션은 해당 데이터를 Lock으로 잠금 처리를 하여 다른 트랜잭션이 접근하지 못하게 합니다.
- Lock이 걸린 데이터는 Unlock이 될 때까지 다른 트랜잭션들은 접근하지 못하고 기다려야 합니다.
그렇게 하면 Deadlock이 발생하지 않나요?
- 맞습니다. lock을 걸어 놓고 unlock하지 않은 상태에서 서로의 lock이 걸린 데이터에 접근하려고 할 때 발생하는데, 해결방법이 3가지가 있습니다.
- 첫번째로는 예방기법입니다. 트랜잭션이 실행되기 전에 필요한 데이터를 전부 locking 해주는 것인데, 전부 lock을 걸어 놓는다면 트랜잭션의 병행성을 보장하지 못할 수 있습니다.
- 두번째로는 회피기법입니다. 자원을 할당할 때 timestamp를 사용하여 deadlock이 발생하지 않도록 해줍니다.
- 세번째로는 탐지/회복기법입니다. 트랜잭션이 실행되기 전에는 아무런 검사를 하지 않고, deadlock이 발생하면 이를 감지하고 회복시키는 방법입니다.
index를 아시나요?
- index는 데이터베이스에서 table의 검색 성능을 높여주는 대표적인 방법중 하나입니다.
- 특정 열에 대한 정렬된 데이터의 복사본을 생성하여 데이터의 위치를 더 빠르게 찾을 수 있도록 해줍니다.

항상 성장하는 개발자 최동혁입니다.