https://www.techbeamers.com/python-interview-questions-programmers/
해당 페이지를 참고하고, 제가 면접을 보며 들었던 내용들을 기반으로 정리했습니다.
python
python의 특징에 대해 설명해주세요.
- 파이썬은 인터프리터 언어로써, 코드를 작성한 후 컴파일 없이 즉싱 실행할 수 있습니다. 가독성이 높은 코드를 작성하기 쉬우며, 머신러닝, 데이터 분석 같은 다양한 분야에서 사용됩니다.
인터프리터와 컴파일러에 대한 차이점을 설명해주세요.
- 인터프리터는 프로그래밍의 소스 코드의 내용을 한번에 한줄씩 읽어들여서 실행합니다.
- 컴파일러는 전체 프로그램 코드를 스캔하여 소스 코드(고급 프로그래밍 언어)를 오브젝트 코드(어셈블리어(저급 프로그래밍 언어))로 바꾸어주는 역할을 합니다.
- 인터프리터는 소스 코드를 해석하는데는 적은 시간이 걸리지만 실행 시간은 느립니다. 반면 컴파일러는 소스코드를 해석하는데는 많은 시간이 걸리지만 한번 오브젝트 코드로 바꿔놓으면 실행 시간은 빠릅니다.
pep 8에 대해서 아시나요? 읽어보셨다면 어떤 것들이 있나요?
- pep는 파이썬의 코딩 규칙에 대한 제안서입니다.
- 들여쓰기와 tab, space를 혼합 사용 금지, 최대 줄 금지, 네이밍 규칙 등이 있습니다.
- 들여쓰기는 스페이스 4번, space와 tab은 혼합 사용을 금지해야 하며, 최대 줄 길이는 79자를 넘어가면 안됩니다. 넘어가게 된다면 백 슬래시를 사용합니다.
- 네이밍 규칙은 Class의 경우 앞 대문자, function의 경우는 소문자로 지정하고, function의 경우 언더바를 사용하여 단어를 나눕니다.
list와 tuple의 공통점과 차이점에 대해서 설명해주세요.
- 공통점으로는 둘 다 여러 데이터를 담을 수 있는 컨테이너형 변수입니다.
- 그리고 인덱스를 통해 특정 요소에 접근할 수 있으며, iterable합니다. 즉, for 문에 넣고 돌릴 수 있습니다.
- 차이점으로는 list는 mutable 하지만 tuble은 immutable합니다.
- 따라서 list는 딕셔너리의 key 값으로 쓸 수 없지만, tuple은 가능합니다.
- 왜냐면 딕셔너리의 key 값은 immutable한 객체만 올 수 있기 때문입니다.
- 그리고 속도의 차이점이 있습니다.
- 같은 수의 요소를 넣은 후, for 문을 돌리면 tuple이 list보다 속도가 빠릅니다.
왜 tuple이 list보다 빠를까요?
- list는 mutable이기 때문에 객체가 생성된 후 크기를 확정해야 하는 경우를 대비하여 추가 메모리 블록을 할당해줍니다.
- 반대로 tuple은 한번 생성하면 변경할 수 없어 크기가 고정적이기 때문에 최소 메모리 블록을 할당해줍니다.
- 그렇기 때문에 tuple이 list보다 속도가 더 빠릅니다.
- 디버깅 관련해서도 tuple의 immutable한 속성으로 인해 더 쉽게 추적할 수 있어서 디버그가 list 보다 쉽습니다.
파이썬은 메모리 할당을 어떻게 할까요?
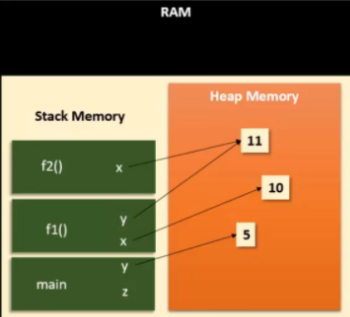
- 파이썬의 method와 그 안에 있는 변수들은 stack memory에 저장됩니다.
- 힙 메모리에서는 객체들을 할당해줍니다.
- 파이썬의 모든 것은 객체이기 때문에 변수들에 대응하는 객체들은 모두 힙에 저장되고, stack 메모리에 저장되어 있는 변수들이 객체를 가리키게 됩니다.
메모리 할당 해제하는 로직을 설명해주세요.
- 우선 stack에 저장되어 있는 method가 리턴되면 해당 method의 영역의 할당이 해제됩니다.
- 할당이 해제되면서 힙에 있는 객체들을 가리키지 않게 되는데, 만약 다른 method의 변수들도 가리키지 않는다면 reference counting이 0이 되면서 객체도 자동으로 해제가 됩니다. 이것이 파이썬의 가비지 콜렉터입니다.
가비지 콜렉터란?(GC)
- 메모리를 자동으로 할당해주고 해제해주는 것
- 즉, 위의 두 질문은 파이썬의 가비지 콜렉터의 로직을 설명하는 것이다.
- 결론은 파이썬은 reference counting을 이용해 메모리를 관리한다.
파이썬에서 class, object, instance를 구분해서 설명해주세요.
- 예시로 설명하겠습니다.
- 파이썬에서 class는 붕어빵의 틀과 같습니다.
- object(객체)는 이런 틀에서 만들어진 하나 하나의 붕어빵입니다.
- 그리고 붕어빵 틀이 여러개가 있고, 틀에 의해 만들어진 붕어빵도 여러개가 있는데, 어떠한 붕어빵 틀에서 만들어진 붕어빵인지 구분하기 위해 instance를 사용합니다.
- 즉, 붕어빵 틀1(class)에서 만들어진 붕어빵1(객체)은 붕어빵 틀1의 instance입니다.
self는 무엇인가요?
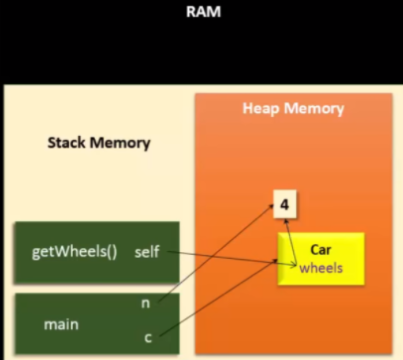
- 특정 class instance의 주소 값입니다.
- 특정 class로 객체를 만들면 그 class의 instance라고 불리우는데, self를 이용해 instance 값을 참조합니다.
- self는 stack memory에 저장되며, 특정 class의 instance를 참조해 그 안에 있는 attribute에 접근합니다.
method는 무엇인가요?
- class안에서 구현하는 함수를 말합니다.
- 위에 그림에서 보는것과 같이, stack memory에 저장되어 그 안에 있는 변수들이 해당 class 의 instance를 가리키게 됩니다.
생성자란 무엇인가요?
- 파이썬에서 init 이라는 메소드 이름을 가진 것을 생성자라고 합니다.
- 객체가 생성이 되면 자동으로 맨처음 호출돼 객체를 초기화해줍니다.
파이썬 모든 것이 객체라고 하셨는데, 그렇다면 int 변수도 객체인가요?
- 네. 파이썬은 x = 10처럼 변수를 할당하면 10이라는 int 객체를 만들어 놓고 변수 x가 그것을 가리킵니다.
- 그렇기에 다른 변수의 값이 10이 되면 만들어진 10의 객체의 주소를 가리키게 됩니다.
immutable과 mutable에 대해서 설명해주세요.
- mutable은 변경되는 객체이며 immutable은 변경되지 않는 객체입니다.
- mutable 객체로는 list, set, dict 정도가 있으며, 모든 객체를 각각 생성해서 참조합니다. 그렇기 때문에 안의 요소들이 같더라도 참조하는 메모리 주소는 다릅니다.
immutable 객체로는 int, float, tuple, str, bool 정도가 있으며, 값이 같은 경우에 변수에 상관없이 동일한 곳을 참조합니다. - 그리고 immutable한 객체들은 값을 변경시킬수 없습니다.
immutable과 mutable 둘 다 값이 변했을 때 메모리 주소는 어떻게 되나요?
- immutable 같은 경우 변한 값에 대한 메모리 주소를 참조하게 됩니다. 그렇기 때문에 9에서 10으로 변한다면 10에 대한 메모리 주소를 참조하게 됩니다.
- mutable은 객체를 각각 생성해서 메모리 주소를 참조하기 때문에, 값이 변하더라도 참조하는 메모리 주소는 변하지 않습니다.
str은 mutable 객체인데, 그렇다면 이것도 값이 변하더라도 같은 메모리 주소를 참조하겠네요?
- 아닙니다. str 타입의 경우 항상 문자열이 같은지 보고 같은 곳을 참조할지 판단하기가 쉽지 않기 때문에 항상 같은 곳을 참조 하지는 않습니다.
- 예를 들어 같은 문자열로 객체를 생성한 경우 해당 문자열에 대한 같은 메모리 주소를 가리키지만, replace 메소드로 값을 변경한 객체와 변한 문자열을 수동으로 값을 넣어주면 둘의 가리키는 메모리 주소는 다릅니다.
얕은 복사에 대해서 설명해주세요.
- 얕은 복사는 = 연산자나 슬라이싱의 특수한 경우를 통해 이루어집니다.
- 같은 메모리 주소를 가리키기 때문에 mutable한 list의 경우 얕은 복사를 한 후 값을 변경시킨다면 둘 다 같은 값으로 변하게 됩니다.
- immutable한 객체들은 어차피 같은 값에 따라 같은 메모리 주소를 가리키기 때문에 얕은 복사를 하던 깊은 복사를 하던 상관 없이 얕은 복사를 따라가게 됩니다.
슬라이싱의 특수한 경우는 무엇인가요?
- mutable한 객체안에 immutable한 객체들로만 이루어진 것이 아닌, mutable한 객체가 있다면, 슬라이싱을 하더라도 얕은 복사가 이루어집니다.
- 전체적인 객체의 메모리 주소는 다르지만, 그 안의 mutable한 객체들은 서로 같은 메모리 주소를 가리킵니다.
깊은 복사에 대해서 설명해주세요.
- 슬라이싱이나 deepcopy 함수를 통해 이루어집니다.
- 깊은 복사는 mutable한 객체의 내부에 있는 객체 모두 새롭게 만들어줍니다.
- 그렇기 때문에 서로 다른 메모리 주소를 가리켜 안의 값들을 변경시키더라도 서로 영향을 주지 않습니다.
list의 extend와 append의 차이점에 대해서 설명해주세요.
- list의 extend는 삽입 대상의 iterable한 객체를 풀어서 각각의 요소로 확장해 삽입시켜줍니다.
- list의 append는 삽입하려는 객체 전체를 해당 list의 요소로 집어넣어줍니다.
list의 extend와 + 연산자의 차이에 대해서 설명해주세요.
- extend는 확장하려는 list의 주소값이 변하지 않은 상태로 확장이 되며, + 연산자는 두 리스트가 더해진 새로운 리스트가 반환이 됩니다.
해당 코드의 결과물은 어떻게 나올거 같나요?
def extendList(val, list=[]):
list.append(val)
return list
list1 = extendList(10)
list2 = extendList(123,[])
list3 = extendList('a')
print "list1 = %s" % list1
print "list2 = %s" % list2
print "list3 = %s" % list3list1 = [10, 'a']
list2 = [123]
list3 = [10, 'a']- 위의 결과로 나옵니다.
- list1과 list3가 같은 이유는 list1과 list3가 호출한 extendList에서 파라미터에 list의 기본값을 넣어주지 않았기 때문에 첫 호출에서 생성한 list의 주소를 가리키게 됩니다.
- 반면 list2는 파라미터에 별도의 빈 list를 넣어주었기 때문에, 다른 주소를 가지는 list에 123이라는 숫자를 넣습니다.
위의 코드에서 우리가 원하는데로 각 리스트들이 다른 값을 가지게 하고 싶으면 어떻게 고쳐야 할까요?
def extendList(val, list=None):
if list is None:
list = []
list.append(val)
return list- list의 기본값을 None으로 설정해주고, 호출을 할 때 별도로 list 값을 주지 않는다면 새로운 list를 만들게 해서 서로 다른 주소를 가리키게 해줍니다.
- 이렇게 한다면 list1,2,3가 서로 다른 주소를 가리키기 때문에 각각 다른 값을 가질 수 있습니다.
해당 코드의 결과물은 어떻게 나올거 같나요?
list1 = ['a', 'b', 'c', 'd', 'e']
print(list[10:])- 정답은 [] 빈 문자열입니다.
- 슬라이싱이 아닌 단일 index로 접근한다면 error가 나오지만, 슬라이싱은 그렇지 않습니다.
- 이러한 동작은 파이썬에서 슬라이싱이 구현되는 방식 때문입니다.
- 파이썬은 슬라이싱 시, 범위를 벗어난 인덱스를 자동으로 제한하거나, 빈 시퀀스를 반환하도록 구현되어 있기 때문입니다.
python에서 슬라이싱이란 무엇인가요?
- 슬라이싱은 문자열의 일부 또는 목록의 일부를 추출하기 위한 문자열 작업입니다.
- Python에서 슬라이스()는 슬라이스 객체를 생성하는 생성자 함수이기도 합니다.
- 결과는 범위(시작, 중지, 단계)로 언급된 인덱스 집합입니다. slice() 메소드는 세 개의 매개변수를 허용합니다.
- 시작 - 슬라이싱을 시작할 시작 번호입니다.
- stop – 슬라이싱이 끝났음을 나타내는 숫자.
- step – 각 인덱스 이후 증가할 값(기본값 = 1).
- 파이썬은 슬라이싱 시, 범위를 벗어난 인덱스를 자동으로 제한하거나, 빈 시퀀스를 반환하도록 구현되어 있습니다.
pass와 continue의 차이에 대해서 아시나요?
- pass는 null 작업입니다. 실행할 때 아무일도 일어나지 않기 때문에 pass 줄을 제외한 나머지 코드들은 실행이 됩니다.
- 반면 continue는 블록에 남아있는 모든 명령을 실행하지 않은 상태로 두고 루프에서 다음 반복을 실행하도록 하는 점프 문입니다.
- 보통 pass는 선언만 해놓은 상태로 아무 작업도 원치 않을때에 사용하며, continue는 루프 문에서 점프문으로 많이 사용됩니다.
try/except/finally는 사용해보셨나요? 사용해보셨다면 로직이 어떻게 되나요?
- 네 사용해봤습니다. 프로그램이 에러가 생겼을 때, 예외처리를 위해 사용했습니다.
- 보통 장고 프레임워크에서 없을 수도 있는 데이터의 쿼리셋을 불러올 때 사용했습니다.
- try는 안전하지 않은 코드, 예를 들면 없을 수도 있는 데이터의 쿼리셋을 불러오는 코드를 작성합니다.
- except에는 fall-back 코드를 작성합니다. try에서 예외뿐만 아니라 오류로 걸리면 except문에 있는 코드를 실행시킵니다.
- else 문은 try절에서 예외로 빠지지 않고 정상적으로 실행이 되면 실행됩니다. except 없이는 사용 불가합니다.
- finally는 try나 except 둘 다 마지막에 실행하는 코드입니다.
python에서 home directory의 위치를 가져오고 싶다면 어떻게 해야하나요?
- os 모듈을 사용하여 ~ 문자를 expanduser에 넣어준다면 home directory의 주소를 가져올 수 있습니다.
import os
print(os.path.expanduser('~'))
>>> /home/user/사용자이름파이썬 애플리케이션에서 버그를 찾거나 정적 분석을 수행하는 방법은?
- 정적 분석기인 PyChecker를 사용할 수 있습니다.
- 파이썬 프로젝트의 버그를 식별하고 스타일과 복잡성 관련 버그도 보여준다. pychecker [options] file1.py file2.py ... 와 같이 사용할 수 있습니다.
- 또 다른 도구는 파이썬 모듈이 코딩 표준을 충족하는지 확인하는 Pylint입니다. C의 lint와 비슷합니다.
파이썬의 데코레이터를 아시나요? 안다면 간략한 설명 부탁드립니다.
- 데코레이터는 함수나 클래스를 수정하지 않고 기능을 추가할 수 있도록 해주는 파이썬의 특별한 문법입니다.
- 일반적으로 함수의 전처리나 후처리에 대한 필요가 있을때 사용합니다.
데코레이터를 왜 쓴다고 생각하시나요?
- 코드의 재사용성, 간결성, 유연성 등등이 있습니다.
- 한번 선언해 놓으면 해당 기능을 여러 함수나 클래스에서 반복해서 사용할 수 있습니다.
- 수정 또한 용이해져서 코드의 길이가 짧아지고 가독성이 향상됩니다.
데코레이터를 사용해 본 적 있나요? 있다면 어떤 기능으로 사용하셨나요?
- 보통 알고리즘 스터디를 통해 문제를 풀고 코드 리뷰를 할 때, 해당 로직이 어느 정도의 시간으로 문제를 해결했고 다른 팀원의 로직은 어느 정도의 시간으로 해결이 되었는지 각 케이스마다 비교 분석하기 위해 사용했었습니다.
import time
def my_decorator(func):
def wrapper(*args, **kwargs):
print(f"Function '{func.__name__}' is starting.")
start_time = time.time()
result = func(*args, **kwargs)
end_time = time.time()
print(f"Function '{func.__name__}' is finished. Elapsed time: {end_time - start_time:.2f} seconds.")
return result
return wrapper
@my_decorator
def my_function(x, y):
time.sleep(1) # simulate a long-running operation
return x + y
result = my_function(2, 3)
print(result)람다의 실행 시점에 대해 설명해주세요.
- 람다는 정의 시점이 아닌 실행 시 식을 평가합니다.
그렇다면 함수와 다른게 뭐죠?
- 람다는 일반 함수와 동일한 함수 객체입니다. 하지만 함수와는 다르게 람다는 이름이 없습니다.
- 그리고 메모리 저장 방식에 차이가 있습니다.
- 람다 함수와 일반 함수 모두 변수 값은 힙에 저장되지만, 함수 객체와 내부 상태의 저장 방식이 다릅니다.
- 람다 함수와 일반 함수 둘 다 정의했을 때 함수 객체를 힙에 저장하지만, 일반 함수의 내부 상태는 스택에, 람다 함수의 내부 상태는 힙에 저장됩니다.
파이썬에서 switch/case 문을 사용해 본적이 있나요?
- 파이썬에는 switch/case문이 따로 없습니다.
- 실제 2007 pycon에서 해당 안건에 대해 설문 조사를 하였지만, 많은 관심을 끌지 못해서 switch/case문에 대한 논의는 폐기되었습니다.
- switch/case 문 대신에 파이썬에서는 대체할 것으로 if/elif문과 dictionary가 있습니다.

항상 성장하는 개발자 최동혁입니다.