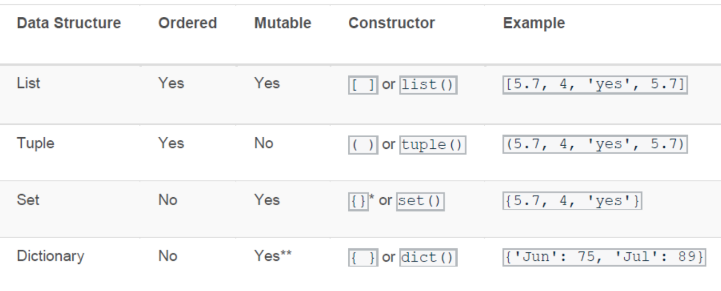
리스트(List)
튜플(Tuple)
- list와 tuple의 차이
- list는 데이터를 변경할 수 있고, tuple은 변경 할 수 없다.
- 튜플은 리스트에 비해 더 적은 메모리를 필요로 하고, 속도가 빠름.
- 튜플이 인덱싱할 때 더 적은 포인터를 사용하기 때문에 리스트보다 더 빠름.
- 튜플을 만드는게 리스트를 만드는 것보다 빠름.
- 리스트의 경우 값이 바뀔 수 있기 때문에 여분의 storage가 필요하다. 따라서 튜플을 사용하는 것이 메모리 절약도 할 수 있다.
튜플(tuple)의 특징
-
튜플 요솟값을 변경하려 할 때
l = [1, 2 ,3] t = (1, 2, 3) print(l[0], t[0]) l[0] = 10 print(l) t[0] = 10 print(t) >>> 1 1 >>> [10, 2, 3] Traceback (most recent call last): File "test.py", line 10, in <module> t[0] = 10 TypeError: 'tuple' object does not support item assignment- 리스트와는 다르게 튜플의 요솟값은 변경할 수 없다.
-
튜플 요솟값을 삭제하려 할 때
t1 = (1, 2, 'a', 'b') del t1[0] Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object doesn't support item deletion- 리스트는 del 함수를 사용하여 지울 수 있다.
- 하지만 튜플은 요소를 지우는 행위가 지원되지 않는다.
- del 함수의 시간 복잡도는 O(N)이다.
-
인덱싱과 슬라이싱
# 튜플의 인덱싱 t1 = (1, 2, 'a', 'b') >>> t1[0] 1 >>> t1[3] 'b' # 튜플의 슬라이싱 t1 = (1, 2, 'a', 'b') >>> t1[1:] (2, 'a', 'b') -
더하기, 곱하기
# 튜플의 더하기 t1 = (1, 2, 'a', 'b') t2 = (3, 4) >>> t1 + t2 (1, 2, 'a', 'b', 3, 4) # 튜플의 곱하기 >>> t2 * 3 (3, 4, 3, 4, 3, 4)- 리스트와 마찬가지로 서로 다른 튜플을 +를 이용하여 합칠 수 있다.
주의사항
- 리스트와 마찬가지로 특정 값끼리 덧셈을 하고 싶다면, 인덱싱을 이용하여 특정 값을 추출해온 뒤 더하면 되는데, 이때 리스트와 마찬가지로 서로 데이터 타입이 다른 데이터들끼리는 더할 수 없다.
- 덧셈과 마찬가지로 특정 값에 대해서 곱하고 싶다면 인덱싱으로 값을 추출해온 뒤 곱해주면 된다.
- 리스트와 마찬가지로 튜플에서도 곱하기를 할 수 있으며 숫자와 문자열 둘 다 가능하다.
-
튜플 값 추가하기
t1 = (1, 2, 'a', 'b') t1.append(2) >>> Traceback (most recent call last): File "c:\Users\c\Desktop\test.py", line 2, in <module> t1.append(2) AttributeError: 'tuple' object has no attribute 'append'- 리스트와 다르게 append를 쓰지 못한다.
- 값 추가 불가능
-
원하는 위치에 값 추가
t1 = (1, 2, 'a', 'b') t1.insert(0, '0번째') >>> Traceback (most recent call last): File "c:\Users\c\Desktop\test.py", line 2, in <module> t1.insert(0, '0번째') AttributeError: 'tuple' object has no attribute 'insert'- 리스트와 다르게 insert를 쓰지 못한다.
-
sort, reverse, index, count
t1 = (1, 2, 'a', 'b', 1) # sort() t1.sort() >>> Traceback (most recent call last): File "c:\Users\c\Desktop\test.py", line 2, in <module> t1.sort() AttributeError: 'tuple' object has no attribute 'sort' # reverse() t1.reverse() >>> Traceback (most recent call last): File "c:\Users\c\Desktop\test.py", line 2, in <module> t1.sort() AttributeError: 'tuple' object has no attribute 'reverse' # index() t1.index('a') >>> 2 # count() t1.count(1) >>> 2- 튜플은 값을 수정할 수 없기 때문에 순서를 바꾸거나, 뒤집거나 값을 바꾸는 등 관련된 함수를 사용할 수 없다.
- 해당 index를 알기 위한 index()와 중복 갯수를 세어주는 count()는 사용할 수 있다.
-
변환
t1 = (1, 2, 'a', 'b', 1) # tuple -> list list((t1)) >>> [1, 2, 'a', 'b', 1] # list -> tuple tuple((t1)) >>> (1, 2, 'a', 'b', 1)- 형 변환은 괄호를 두개 써주면 된다.
셋(Set)
- list와 set의 차이
- 중괄호 { } 사용
- 생성할 때 list는 list(), set은 set()으로 생성
- list는 [] 으로 초기화를 할 수 있지만, set은 {} 으로 초기화 불가!
- {}은 dictionary임.
- 하지만 set1 = {1, 2, 3} 처럼 set의 형태를 명시해주면 set으로 쓸 수 있다!!
- 요소들이 순서대로 저장되어 있지 않아 indexing이 존재하지 않는다.
- 그렇기 때문에 list와 다르게 index로 특정 아이템을 가져올 수 없다.
- 순서대로 저장되어 있지 않아 for 문에서 읽어들일때 무작위 순서로 나온다.
- 동일한 값의 요소가 1개 이상 존재할 수 없다.
- 새로 저장하려는 값이 포함 되어있는 값이라면 새로운 요소가 이 전 요소를 치환한다.
결론
List는 순서가 있는 Collection으로 Ordered collection으로 불리우며,
Set은 순서를 보장하지 않은 Collection으로 Unordered collection으로 불리운다.
셋(set)의 특징
-
set 생성 방법
set = {12, 23, 31} # 변수를 set으로 지정할 때 set2 = set([12, 23, 31]) # set() 함수 사용- set() 함수를 사용해서 set을 만들기 위해서는 list를 parameter로 전달해야 하는데, 일반적으로 list를 set으로 변환하고 싶을때 사용한다.
-
중복된 값 제거
set1 = set([12, 23, 31, 12]) # set() 함수 사용 >>> set1 {12, 31, 23} set2 = {12, 23, 31, 12} >>> set2 {12, 31, 23} -
요소 추가 add()
my_set = {10, 20, 30} my_set.add(40) >>> my_set {10, 20, 30, 40}- 시간 복잡도 = O(1)
-
요소 삭제 remove()
my_set = {10, 20, 30} my_set.remove(10) >>> my_set {20, 30}- 시간 복잡도 = O(1)
- list와 tuple의 경우 O(N)이다.
-
LookUp in 조건문
- set에 어떠한 값이 포함되어 있는지 알아보는 함수
- set에서 lookup을 사용하기 위해서는 in, not in 키워드를 같이 사용해야 한다.
my_set = {10, 20, 30} if 20 in my_set: print("20 여기 있어!") # output 20 여기 있어! my_set = {10, 20, 30} if 40 not in my_set: print("여기 40은 없어") # output 40은 여기 없어- list와 tuple의 in 연산자의 시간 복잡도는 O(N)이지만, set은 다르다!
- set의 in 과 not in은 O(1)이다. 주의
- 집합의 모든 element를 순회하는 for i in set1 같은 경우의 시간 복잡도는 다른 자료구조들과 똑같이 O(N)이다.
-
Intersection (교집합)
set1 = {3, 4, 9, 1, 4, 2, 5, 6, 7, 8, 10} set2 = {5, 6, 7, 8, 9, 10} >>> set1 & set2 {5, 6, 7, 8, 9, 10}- & 연산자의 시간 복잡도는 O(len(set1) + len(set2)) 이다.
-
Union (합집합)
set1 = {3, 4, 9, 1, 4, 2, 5, 6, 7, 8, 10} set2 = {5, 6, 7, 8, 9, 10} # '|' 키워드 사용시 >>> set1 | set2 {1, 2, 3, 4, 5, 6, 7, 8, 9, 10} # 'union' 함수 사용시 >>> set1.union(set2) {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}- | 연산자의 시간 복잡도 또한 O(len(set1) + len(set2)) 이다.
- 차집합도 마찬가지이다.
딕셔너리(Dictionary)
- 대응이 되는 데이터들을 묶어주는 자료형
- 중괄호 {}로 작성되며, 내부 원소는 데이터 : 데이터 의 형태로 이루어 진다.
- set도 {}로 작성되지만 안에 데이터를 명시하지 않고 {}만 쓴다면 dict임.
- 서로 연관이 있는, 대응이 되는 데이터를 표현하고 싶다는 마음에 나타내는 자료형
- 마치 사전(Dictionary)처럼 대응이 된다.
- key를 통해 Value를 얻는다.
- key(탐색의 기준) : value(탐색의 기준에 대응되는, 찾고자 하는 값)
- key는 중복되어서도 변해서도 안된다.
dictinary의 특징
-
dict 생성 방법
my_dict = { 1 : "one"} >>> my_dict { 1 : "one" } my_dict = {} my_dict[1] = "one" >>> my_dict { 1 : "one" } my_dict = dict() my_dict[1] = "one" >>> my_dict { 1 : "one" }- 데이터를 명시하지 않고 중괄호 {} 만 사용하더라도 dict이다.
- dict() 함수를 이용해 딕셔너리를 생성할 수 있다.
-
key 값 중복
my_dict = { 1 : "one", 1 : "two"} >>> my_dict { 1 : "two" }- 이미 존재하는 key값이 또 추가 되면 key 값의 요소를 치환한다.
-
요소 추가하기
my_dict["책"] = "점프 투 파이썬" >>> my_dict {"고양이" : "코리안숏헤어", "노트북" : "맥북", "핸드폰" : "아이폰", "책" : "점프 투 파이선"}- 시간 복잡도는 O(1)이다.
- list → append()
- 시간 복잡도는 O(1)
- set → add()
- 시간 복잡도는 O(1)
- list → append()
- 시간 복잡도는 O(1)이다.
-
요소 수정하기
my_dict = {"고양이" : "코리안숏헤어", "노트북" : "맥북", "핸드폰" : "아이폰", "책" : "점프 투 파이선"} my_dict["핸드폰"] = "아이폰12proMax" >>> my_dict {"고양이": "코리안숏헤어", "노트북": "맥북", "핸드폰": "아이폰12proMax"}- 요소 추가와 시간 복잡도는 동일하다.
-
요소 삭제하기
my_dict = {"고양이" : "코리안숏헤어", "노트북" : "맥북", "핸드폰" : "아이폰"} del my_dict["노트북"] >>> my_dict {'고양이': '코리안숏헤어', '핸드폰': '아이폰'}- dict의 del는 list 와는 다르게 시간복잡도가 O(1)이다.
- del 변수[key] list와 유사하지만 차이점은 index가 아니라 key 값을 사용해서 삭제를 한다.
- list의 del
- 시간 복잡도 O(N)
- set의 remove
- 시간 복잡도 O(1)
- list의 del
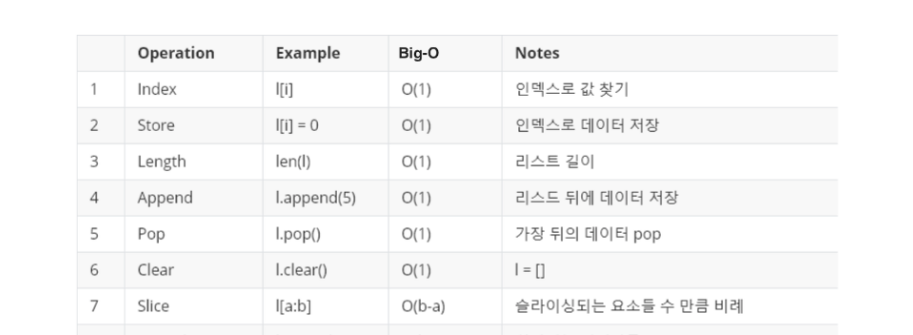
한눈에 보는 자료구조 차이
List, Set, Dictionary 기본 연산자들의 시간 복잡도(Big-O)
List
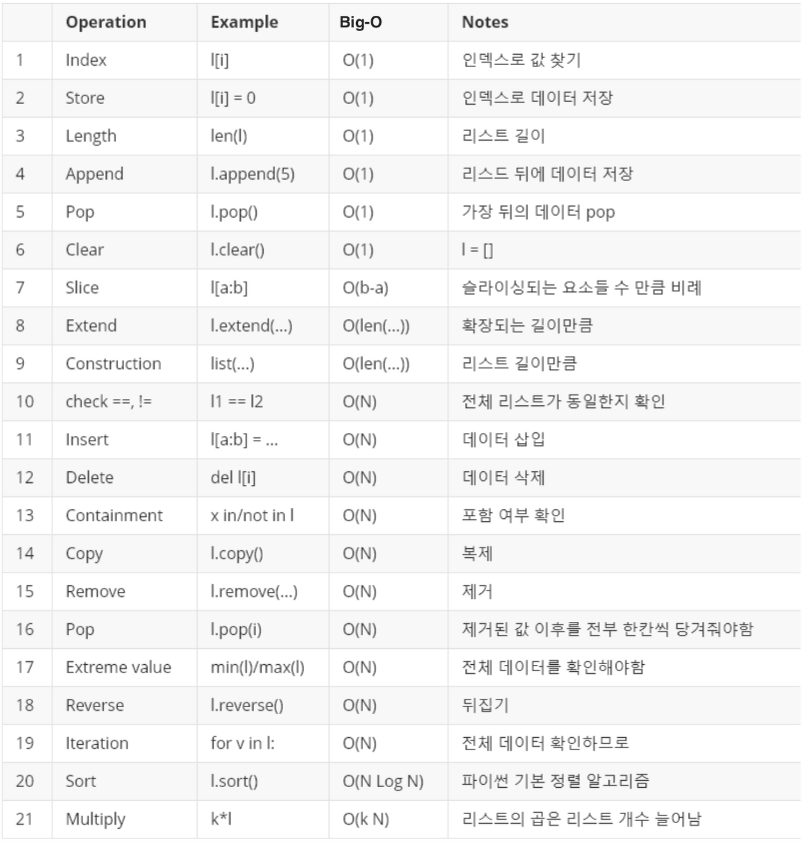
Set
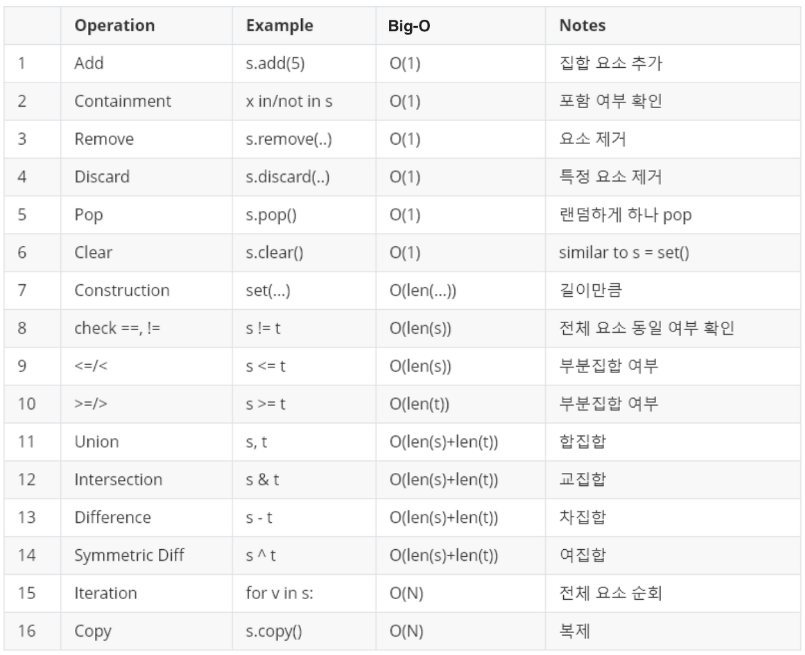
Dictionary
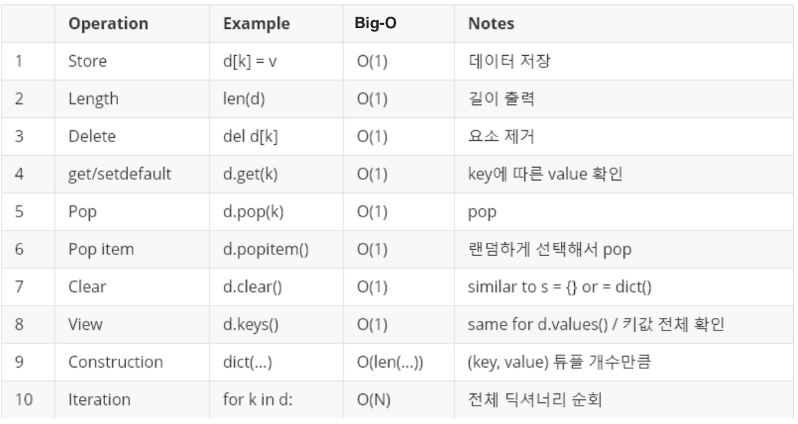
중요한것
- in 연산자(if a in b)
- List, Tuple
- 시간 복잡도 : O(N)
- 하나하나 순회하기 때문에 데이터의 크기만큼 시간 복잡도를 갖게 된다.
- Set, Dictionary
- 시간 복잡도 : O(1)
- 하지만 해시가 성능이 떨어졌을(충돌이 많은 경우)때 O(N)까지 떨어진다.
- 시간 복잡도 : O(1)
- List, Tuple

항상 성장하는 개발자 최동혁입니다.