개요
EffectiveJava Item11 equals를 재정의하면 hashCode 를 재정의하라 를 공부하면서, 객체에 대한 equals 를 재정의를 해주려면 hashCode를 재정의 해줘야 한다는 것을 알았다. 기본 default hashCode가 객체가 다르면 어쨌거나 다른 값을 주기 때문이다. 기본 default Object의 hashCode는 어떻게 기본값을 가질까? 타 블로그를 보면 hashCode는 메모리값에서 가져오기 때문에 기본 default hashCode가 다르다고 한다. 하지만 정말 메모리값과 관계가 있는지 궁금해졌다.
코드로 확인해보기
- 논리적 동치성이 같은
nutritionFacts1,nutritionFacts2의 메모리값, hashCode 값을 비교한다. nutrionFacts1의 메모리주소값,hashcode,toString값을 비교한다.- 만약
hashCode가 메모리값에서 가져온다면hashCode와 memory 주소값을 같아야 한다.
- 만약
@Test
void memoryTest() {
NutritionFacts nutritionFacts1 = NutritionFacts.builder(10,20).build();
NutritionFacts nutritionFacts2 = NutritionFacts.builder(10,20).build();
System.out.println("nutritionFacts1 Memory address: " + VM.current().addressOf(nutritionFacts1));
System.out.println("nutritionFacts1.hashCode: " + nutritionFacts1.hashCode());
System.out.println("nutritionFacts1.hashCode: " + System.identityHashCode(nutritionFacts1));
System.out.println("nutritionFacts1.toString: " + nutritionFacts1.toString());
System.out.println("nutritionFacts1.Hashcode (HEX) : "+Integer.toHexString(nutritionFacts1.hashCode()));
System.out.println("======================================================================================");
System.out.println("nutritionFacts2 Memory address: " + VM.current().addressOf(nutritionFacts2));
System.out.println("nutritionFacts2.hashCode: " + nutritionFacts2.hashCode());
System.out.println("nutritionFacts2.hashCode: " + System.identityHashCode(nutritionFacts2));
System.out.println("nutritionFacts2.toString: " + nutritionFacts2.toString());
System.out.println("nutritionFacts2.Hashcode (HEX) : "+Integer.toHexString(nutritionFacts2.hashCode()));
}- 결과
nutritionFacts1 Memory address: 30312130760
nutritionFacts1.hashCode: 195699326
nutritionFacts1.hashCode: 195699326
nutritionFacts1.toString: NutritionFacts@baa227e
nutritionFacts1.Hashcode (HEX) : baa227enutritionFacts2 Memory address: 30312130824
nutritionFacts2.hashCode: 1408739590
nutritionFacts2.hashCode: 1408739590
nutritionFacts2.toString: NutritionFacts@53f7a906
nutritionFacts2.Hashcode (HEX) : 53f7a906
- Memory 주소와 hashCode의 관계
- Memory address ≠ hashCode
- 둘은 다르다. 하지만 다르다고 해서 hashCode가 메모리주소로부터 값을 가져오지 않는다라는 것은 보장을 하지 못한다.
- 하지만 nutritionFacts1과 nutritionFacts2 의 주소값은 30312130760, 30312130824 로 뭔가 물리적인 주소가 가까이 있는 것으로 보인다. hashCode는 195699326, 1408739590 로 둘은 관계가 없어보인다.
- 확실하지 않기 때문에 hashCode를 좀 더 까보기로 한다.
- toString과 hashCode의 관계
- Integer.toHexString(hashCode) = toString() 이 된다.
- toString() 에서 @뒤에 붙는 값은 메모리 주소가 아니였다. 😬 hashCode의 16진수값이였다.
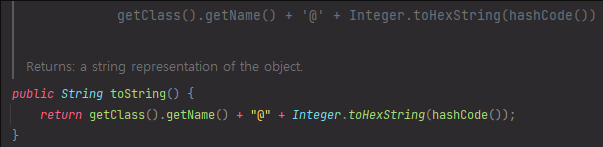
- 빼박...
Objects.hashCode 파헤치기
코드를 보면 불행히도 구현부를 찾을 수가 없다...😰
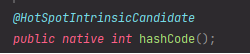
hashCode() 주석을 보면 다음과 같이 적혀있는 것을 확인할 수 있다.
As much as is reasonably practical, the hashCode method defined by class Object does return distinct integers for distinct objects. (The hashCode may or may not be implemented as some function of an object's memory address at some point in time.)
클래스 Object에 의해 정의된 hashCode 메서드는 고유한 개체에 대해 고유한 정수를 반환합니다. (hashCode는 특정 시점에서 객체의 메모리 주소의 일부 기능으로 구현되거나 구현되지 않을 수 있습니다.)
즉, hashCode는 단순히 고유한 개체에 고유한 정수를 반환을 하지, 메모리주소로 무조건 구현되지는 않는다는 말이다.
hashCode가 실제로 정의된 코드를 찾으려고 했으나, 찾을 수가 없었다.
stack over flow에도 의견이 분분했다. 그러던 와중 좋은 글을 발견했는데, 내부 jdk코드까지 확인한 그래도 나름 신빙성이 있어보이는 글 같았다.
How does the default hashCode() work?
이후 글은 위 링크를 보고 정리한 내용이다.
hashCode implementation은 JVM 에 달려있다.
OpenJDK 의 jvm.h 코드를 확인해본다.
JNIEXPORT jint JNICALL
JVM_IHashCode(JNIEnv *env, jobject obj);JVM_ENTRY(jint, JVM_IHashCode(JNIEnv* env, jobject handle))
JVMWrapper("JVM_IHashCode");
// as implemented in the classic virtual machine; return 0 if object is NULL
return handle == NULL ? 0 : ObjectSynchronizer::FastHashCode (THREAD, JNIHandles::resolve_non_null(handle)) ;
JVM_ENDObjectSynchronizer::FastHashCode() 는 identity_hash_value_for 에서 불리고, 다른 사이트(e.g: System.identyHashCode())에서도 불린다.
intptr_t ObjectSynchronizer::identity_hash_value_for(Handle obj) {
return FastHashCode (Thread::current(), obj()) ;
}
--------------------------------------------------------------------
intptr_t ObjectSynchronizer::FastHashCode(Thread* current, oop obj) {
//...
// Load ObjectMonitor's header/dmw field and see if it has a hash.
mark = monitor->header();
// ...
hash = mark.hash();
if (hash == 0) { // if it does not have a hash
hash = get_next_hash(current, obj); // get a new hash
// ...
return hash;
}FastHashCode()에서 새로운 해시 코드 할당은 get_next_hash 함수를 사용한다.
다음은 get_next_hash() 함수이다. get_next_hash()에서 실제 hash 생성을 한다.
static inline intptr_t get_next_hash(Thread* current, oop obj) {
intptr_t value = 0;
if (hashCode == 0) {
// This form uses global Park-Miller RNG.
// On MP system we'll have lots of RW access to a global, so the
// mechanism induces lots of coherency traffic.
value = os::random();
} else if (hashCode == 1) {
// This variation has the property of being stable (idempotent)
// between STW operations. This can be useful in some of the 1-0
// synchronization schemes.
intptr_t addr_bits = cast_from_oop<intptr_t>(obj) >> 3;
value = addr_bits ^ (addr_bits >> 5) ^ GVars.stw_random;
} else if (hashCode == 2) {
value = 1; // for sensitivity testing
} else if (hashCode == 3) {
value = ++GVars.hc_sequence;
} else if (hashCode == 4) {
value = cast_from_oop<intptr_t>(obj);
} else {
// Marsaglia's xor-shift scheme with thread-specific state
// This is probably the best overall implementation -- we'll
// likely make this the default in future releases.
unsigned t = current->_hashStateX;
t ^= (t << 11);
current->_hashStateX = current->_hashStateY;
current->_hashStateY = current->_hashStateZ;
current->_hashStateZ = current->_hashStateW;
unsigned v = current->_hashStateW;
v = (v ^ (v >> 19)) ^ (t ^ (t >> 8));
current->_hashStateW = v;
value = v;
}
value &= markWord::hash_mask;
if (value == 0) value = 0xBAD;
assert(value != markWord::no_hash, "invariant");
return value;
}-
해석
- hashCode를 생성하는 여러가지 방법들이 있다.
- A randomly generated number.
- A function of memory address of the object.
- A hardcoded 1 (used for sensitivity testing.)
- A sequence.
- The memory address of the object, cast to int.
- Thread state combined with xorshift (https://en.wikipedia.org/wiki/Xorshift)
- hashCode를 생성하는 여러가지 방법들이 있다.
-
JVM 별 호출 hashCode
- OpenJDK8 : 5번 사용 여기에서 확인가능
product(intx, hashCode, 5, "(Unstable) select hashCode generation algorithm") - OpenJDK9 : 5번 사용 여기에서 확인가능
- OpenJDK 7, OpenJDK 6 : 0번째 random number generator 사용.
product(intx, hashCode, 0, "(Unstable) select hashCode generation algorithm" )
- OpenJDK8 : 5번 사용 여기에서 확인가능
HashMap은 어떻게 객체를 찾을까?
hashmap에 객체가 추가될 때, JVM은 그 객체를 메모리에 넣을 위치를 결정하기 위해 hashCode를 찾는다. 객체를 다시 검색할 때 해시코드는 객체의 위치를 가져오는데 사용된다. 즉, 해시코드는 실제메모리 주소가 아니라 지정된 위치에서 객체를 가져오기 위한 JVM의 링크라고 보면 된다.
💎 결론
default hashCode는 OpenJDK 만 봤었을 때 memory 주소와 전혀 관계가 없다!
hashCode의 구현부는 JDK에 달려있다. 물론 우리가 매번 JDK 를 선택할 때마다 이렇게 소스를 까서 어떤 방식을 사용하는지 알 필요는 없다.
하지만, hashCode가 메모리주소와 관련이 있다는 많은 글 사이에서 실제로 메모리 주소와 관련이 있는지 확인하는 과정이 의미가 컸다.
더불어, toString() 의 @뒤에 붙는 아이는 메모리주소라 관련없어요. hashCode랑 관련 있어요!
블로그에 최대한 내가 눈으로 확인한 것들과 그것을 바탕으로 한 내 의견을 담고 싶다.
블로그 글 채우기가 아닌 의미있고 정확한 글을 올리고 싶다.
hashCode 파헤지기 끝!!!!!!!!!!!!!!!!!!!!!! 😀

4개의 댓글

안녕하세요 글 잘 읽었습니다. get_next_hash 함수에서 hashCode case 가 4 일 경우 메모리 주소를 참조하여 해시 값을 반환한다고 명시되어있습니다. 하지만 결론에서는 메모리 주소와 hashCode 가 완전 관계 없다고 하지만 이러한 근거가 무엇인지 궁금합니다.
저도 이와 관련해서 토론중이라 생각이 궁금합니다.
감사합니다

재미있는 글이네요!