Deep Variational Autoencoder with Shallow Parallel Path for Top-N Recommendation (VASP)
.png)
한줄요약
VASP = FLVAE + Neural EASE
FLVAE -> VAE_CF의 변형 버전이라고 생각하면 된다.
Neural EASE -> EASE의 변형 버전이라고 생각하면 된다.
VAE_CF -> Variational Autoencoders for Collaborative Filtering 논문 참고
EASE -> Embarrassingly Shallow Autoencoders for Sparse Data 논문 참고
이 논문은 위 2개의 논문을 반드시 읽어야 원활하게 이해할 수 있다.
0. Abstract
- EASE -> Neural EASE로 업그레이드
- VAE -> FLVAE로 업그레이드
Neural EASE와 FLVAE를 병렬로 학습한다.
1. INTRODUCTION
non-linear와 linear를 모두 모델링 하기 위해 non-linear의 VAE와 linear의 EASE를 결합하여 훈련한다.
2. RELATED WORK
- Matrix Factorization
- AutoRec
- MultVAE
- EASE
- RecVAE
- H+VAMP
- Wide&Deep Learning
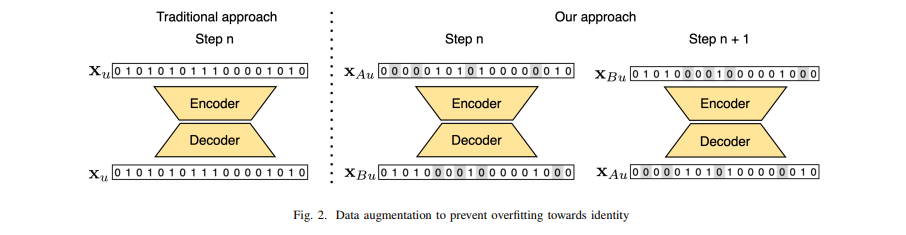
Residual networks를 이용하고, Focial Loss를 채택함으로써 성공적인 추세에 따르고 있다. 참고로 Focial Loss는 불균형 데이터에 강하다(Focal Loss for Dense Object Detection 논문 참고). 일부 item이 다른 item보다 더 popular한 우리의 상황에 완벽하게 맞는다. popular 하지 않는 item은 상호작용이 많지 않아서 추천이 어려운데, Focial Loss를 쓰게 되면 이러한 상황에 loss가 커지게 되어 cold start와 popular 하지 않은 item에 focus를 두게 된다. 또한 과적합을 방지하기 위해 X1을 훈련할 때는 X2를 보여주고, X2를 훈련할 때는 X1을 보여주는 방식을 사용한다(뒤에서 자세히 설명하겠다).
3. OUR APPROACH
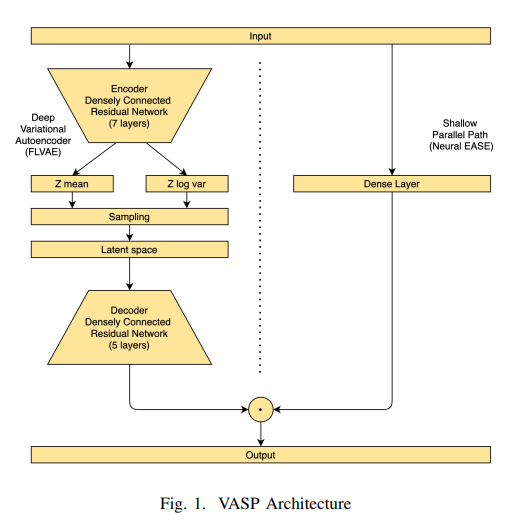
VASP 모델은 FLVAE와 Neural EASE를 따로 계산 한 뒤에 각각 sigmoid를 씌운 상태로 요소 곱을 하여 합친 것이다.
(FLVAE는 Focal loss + VAE이고, Neural EASE는 matrix였던 EASE를 Neural로 바꾼 것이다)
(VAE_CF -> Variational Autoencoders for Collaborative Filtering 논문 참고)
(EASE -> Embarrassingly Shallow Autoencoders for Sparse Data 논문 참고)
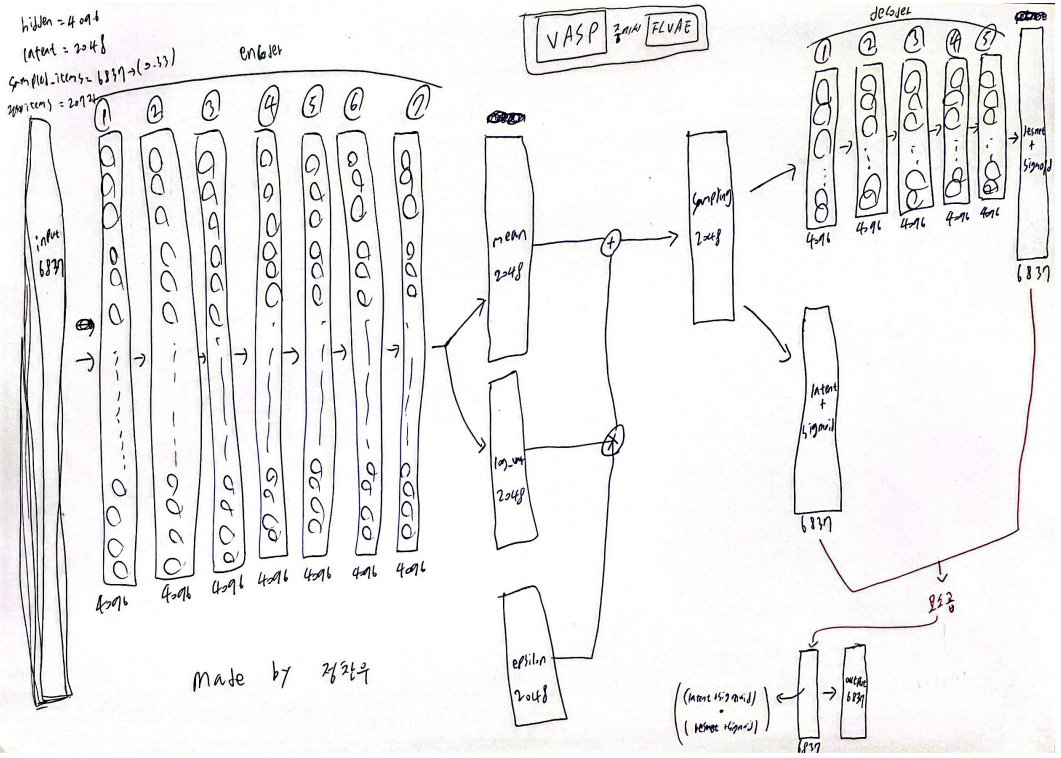
아래에 내가 간단하게 그린 FLVAE와 Neural EASE 사진을 첨부한다.
(논문에 나와있는 내용과 official code를 파보면서 그린 것이다. code는 마지막에 자세히 설명하겠다)
FLVAE의 특징은 Focal loss를 채택했다는 점과 Residual networks을 이용했다는 점 그리고 기존의 AutoEncoder와는 다르게 latent layer로 갈 수록 좁아지는게 아니라 똑같은 크기로 layer를 쌓았다는 점이다.
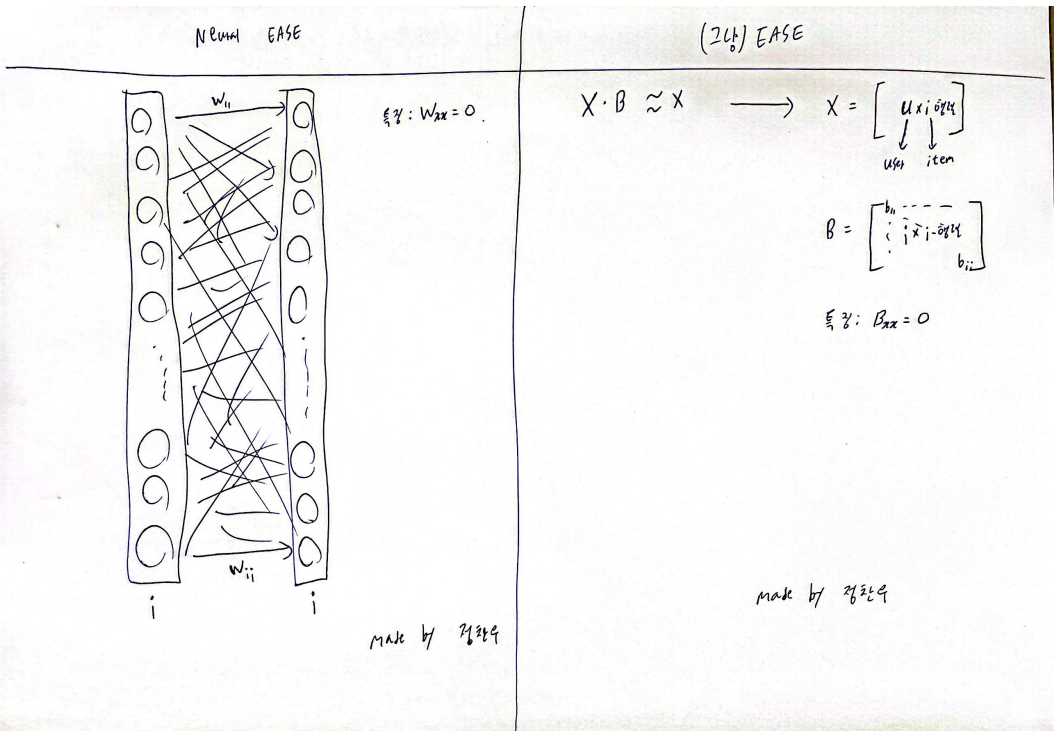
왼쪽이 Neural EASE이고, 오른쪽이 EASE이다. EASE는 B라는 weight-matrix 모델을 single-layer로 바꾼 것이다(딥러닝에 비선형 함수가 없다면 결국 행렬 연산의 연속 아니겠는가). 물론 EASE는 라그랑주 승수법으로 closed-form으로 최적화 연산을 하고, Neural EASE는 딥러닝 처럼 훈련을 하여 두 모델의 weight가 같지는 않다. 중요한 점은 EASE의 특징인 diag(B)=0이 Neural EASE에도 적용되어 Wii=0이 된다. EASE를 굳이 Neural EASE로 바꾼 이유는 FLVAE와 병렬 연산을 수행해야하고, backpropagation을 하여 훈련을 하기 위해서다.
과적합을 방지하기 위해 (아래 사진 참고) 왼쪽의 Traditional approach와는 다르게 오른쪽 Our approach처럼 각 user에 대하여 A와 B로 쪼개고 A를 input 값으로 넣을 때는 B를 output 값으로 하고, B를 input 값으로 넣을 때는 A를 output 값으로 넣어주어서 훈련을 한다. 이때 A와 B를 나눌 때 반반이 되게끔 나눠야한다.
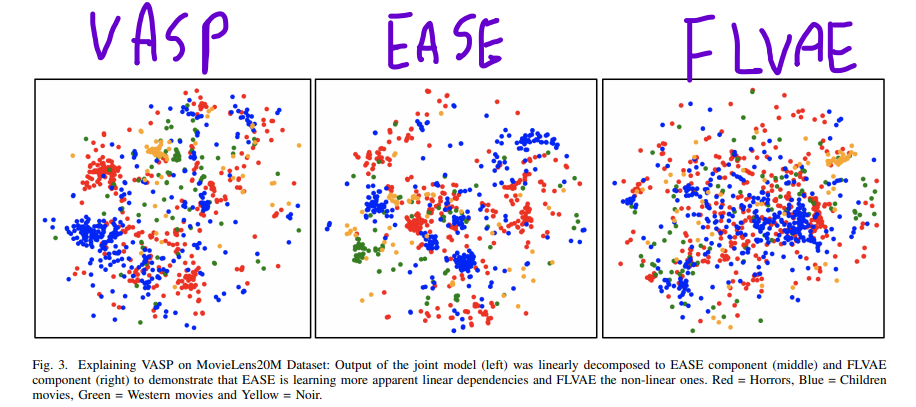
4. INTERPRETING VASP
EASE가 linear하고, FLVAE가 non-linear하다는 것을 보여준다.
5. EXPERIMENTAL SETUP
Datasets은 MovieLens-20M과 Netflix Prize Dataset을 사용했고, Metrics는 추천시스템 모델에서 사용하는 NDCG@k와 Recall@k를 사용한다.
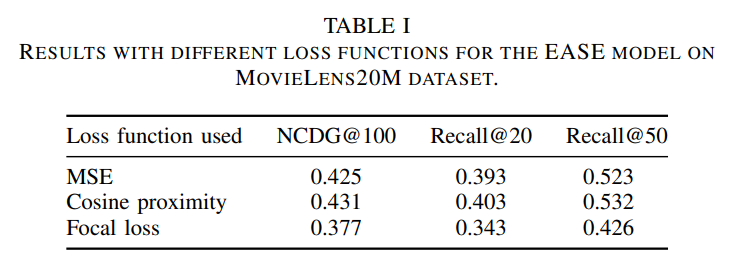
6. RESULTS AND DISCUSSION
Neural EASE에서 Cosine proximity를 사용할 때 성능이 제일 좋았다. 그래서 코드에서도 loss를 Cosine proximity를 채택하여 사용한다.
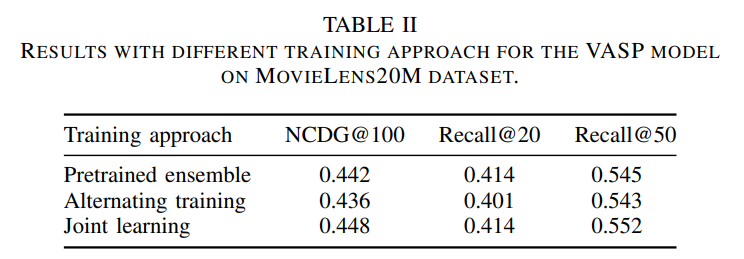
VASP에서는 Joint learning training이 성능이 제일 좋았다. Joint learning approach로 코드에 구현이 되어있다.
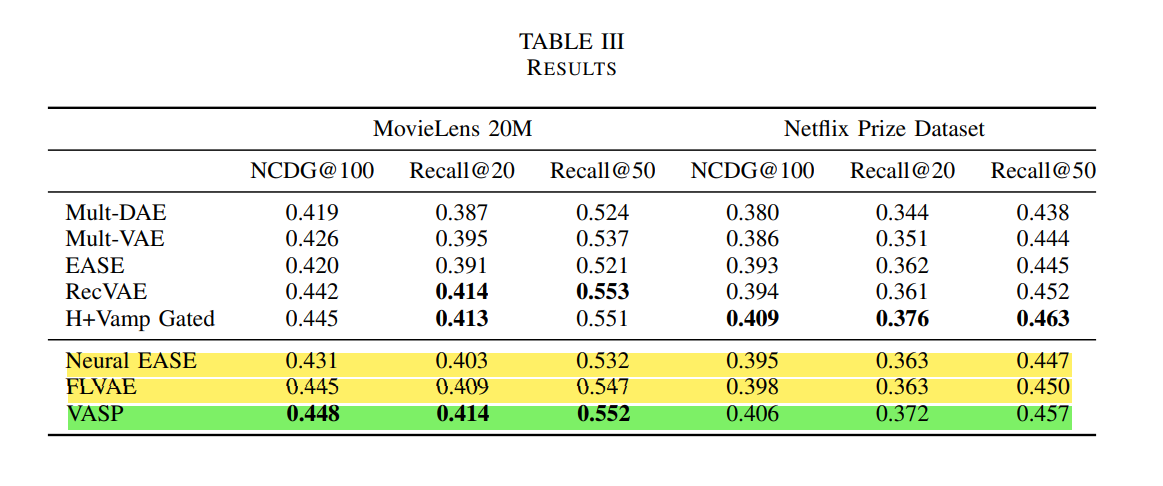
7. CONCLUSION
VASP가 MovieLens-20M에서 SOTA를 깨는 결과를 보여주었다. 과적합 방지를 위한 방법(논문에서 III-D)을 사용하면 성능이 향상된다는 것을 증명했다. 그리고 Neural EASE를 단독으로 훈련했을 때 EASE보다 더 좋은 성능을 보였고, FLVAE를 단독으로 훈련했을 때 Multi-VAE보다 더 좋은 성능을 보였다.
code
official code -> https://github.com/zombak79/vasp
그리고 내 github에 official code에는 올라와 있지 않은 Neural EASE 단독 code를 조만간 올리겠다.
