Cold Start Similar Artists Ranking with Gravity-Inspired Graph Autoencoders

한줄요약
Gravity-Inspired Graph Autoencoders로 cold start 문제를 해결한다.
이 논문을 보기 전에 Gravity-Inspired Graph Autoencoders for Directed Link Prediction 라는 선행 연구 논문을 보고 오셔야합니다. 선행 연구 논문을 이해하고 있다는 가정하에 리뷰를 진행합니다. 제가 리뷰한 선행 연구 논문 아래에 링크로 첨부합니다. 아래 링크에 설명된 내용은 다시 여기 리뷰에서 설명하지 않을 생각입니다.
https://velog.io/@chwchong/Gravity-Inspired-Graph-Autoencoders-for-Directed-Link-Prediction
ABSTRACT
음악 스트리밍 서비스에서는 유사 아티스트 순위 목록을 추천하는데, 이러한 기능을 구현하는 것은 서비스 사용 데이터(예를 들면 재생기록이나 좋아요 버튼)가 있어야하는데 신인 아티스트는 이것이 적거나 없으므로 추천이 되지 않는 문제가 있다. 이를 추천시스템에서 cold start라고 하는데, 이 논문에서는 이를 해결하는 방법을 제시한다.
1. INTRODUCTION
음악 스트리밍 서비스에는 아티스트 간 공유 청취자 비율이나 청취자의 알려진 선호도에서 아티스트간의 유서성을 예측하여 아티스트를 추천한다. 하지만 이렇게 되면 신인 아티스트는 추천이 안 되는 현상이 발생하고, 청취 데이터는 첫 번째 출시 시점에는 제공되지 않기 때문에 충분히 많은 수의 사용 상호 작용이 될 때까지 이러한 아티스트는 추천되지 않는 공정성의 우려가 제기된다. 이러한 문제를 추천시스템에서 cold start 라고 하는데, 음악 스트리밍 서비스에서만 이런 문제가 발생하는 것이 아닌 비디오와 같은 다른 항목을 추천하는 미디어에서도 발생한다.(이 논문에서는 음악 스트리밍 응용 프로그램에 중점을 두고, 'deezer'라는 음악 스트리밍 서비스 산업 데이터로 심층적으로 실험하였다.)
이 논문에서는 graph의 directed한 link 예측을 통해 ranking 하고, cold start를 해결한다.
2. PRELIMINARIES
여기서 그러면 신인 아티스트의 경우 청취자의 재생기록, 좋아요 등이 아예 없을텐데 어떻게 추천을 시켜준다는건가요?라고 질문할 수 있다. 이런 cold start 문제를 논문에서는 메타데이터를 이용한다. 아티스트의 출신국가, 음악장르 등의 데이터는 신인 아티스트에게도 존재하기 때문이다. 이 저자의 발표를 보니 'deezer'라는 음악 스트리밍 서비스가 기본적으로 제공하는 데이터라고 한다.
논문에서는 warm node와 cold node를 설명하는데,
warm node는 상호작용도 있고, 특징벡터도 있는 것이고
cold node는 상호작용은 없고, 특징벡터만 있는 것이다.
훈련은 warm node로만 훈련을 하고 vaild와 test를 cold node로 평가하는 것이다,
3. A GRAPH-BASED FRAMEWORK FOR COLD START SIMILAR ITEMS RANKING
음악 스트리밍 서비스의 추천 기능을 n개의 node와 (nxk)개의 edge를 가진 그래프 구조로 요약될 수 있다.(여기서 각 node당 k개의 edge를 가진다. 그래서 (nxk)개의 edge이다.) 여기서는 모두 warm node이고 서비스 내부 규칙에 따라 충분한 상호작용이 있는 아티스트들입니다. 이 그래프의 egdes는 dircted하고, weight가 있으며 각 node는 f차원의 특징벡터를 가지고 있습니다. cold node는 node만 있고, 상호작용이 없으므로 edge는 없는 상태일텐데 누락된 edge를 잘 예측하는지, k개의 edge들의 weight를 ranking 했을 때 순위가 정확한지를 평가해야한다.
이제 이 논문에서는 graph에서 누락된 link를 찾는 것을 목표로 모델을 제시한다. 내가 이 논문의 모델을 한 마디로 정리하자면 특징벡터를 GCN으로 쫙 압축시키고(encoder), node의 mass와 그 압축 시킨 공간에서의 거리를 가지고 A^ij를 재구성한다(decoder). 아래에 식을 첨부한다.(참고로 아래 식의 GNN이 GCN이다.)
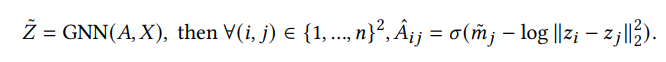
여기서 GCN으로 압축할 때 nx(d+1)차원까지 압축하는데 (d+1)차원에서 d차원은 node 임베딩이고, 나머지 1차원은 mass이다.
4. EXPERIMENTAL EVALUATION
본 논문은 음악 스트리밍 서비스 'deezer'에서 24270명의 아티스트로 실험한다. 각 아티스트는 20명의 다른 아티스트를 가리킵니다.(k = 20) 그래서 한 아티스트 당 20명의 다른 아티스트가 추천되는 구조입니다. 각 edge의 weight는 0~1 집합에서 정규화된 가중치 Aij를 갖는다. directed한 graph 라서 node-i가 node-j의 top-20안에 들어왔다고 해서 그 반대의 경우는 성립하지 않을 수 있다. 신인가수의 추천 목록에 아이유가 나올 수는 있지만 그 반대의 경우는 아닌 것이 쉬운 예시이다.
이 graph의 특징벡터는 56차원이다. 32+20+4로 구성되는데, 32차원은 genre벡터, 20차원은 country벡터, 4차원은 mood벡터이다.
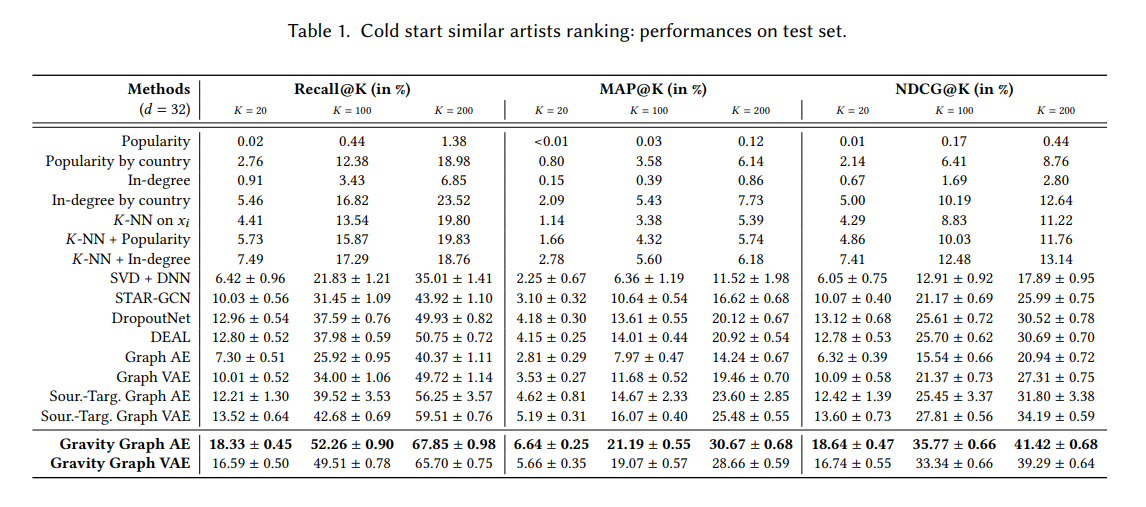
train:valid:test=8:1:1로 구성하고 train은 warm node이고, valid와 test는 colde node이다. 평가지표는 Recall, MAP, NDCG를 사용한다. 결과는 아래와 같다.
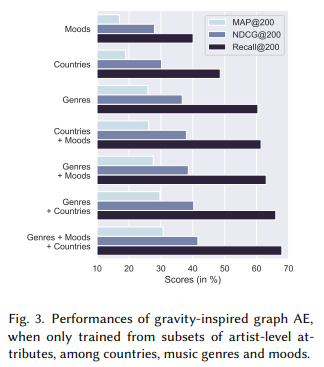
그리고 genre벡터, country벡터, mood벡터를 꼭 모두 사용해야하는가?라는 질문에 답변할 수 있는 실험 결과도 있다. 결론적으로는 모두 사용하는 것이 가장 높은 성능을 보인다. 아래 사진을 첨부한다.
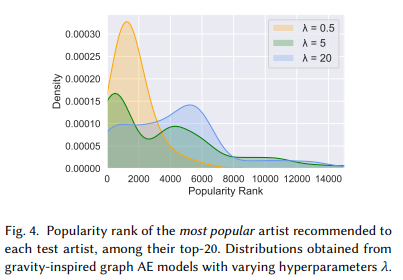
아래 식에서 (1)influence of j, (2)proximity of i and j가 있는데, (1)은 j의 mass를 의미하고, (2)는 i와 j의 거리를 의미한다. 만약 람다가 0이라면 (1)만 고려되는 것이므로 j의 mass가 큰 아티스트만 추천이 될 것이다. 즉, 인기 있는 아티스트만 추천될 것이다. 이렇게 되면 공정성 문제가 제기된다. 반대로 람다를 증가시키면 예측에서 mass의 상대적 중요성은 감소하고, (2)의 실제 노드 근접성을 더 고려한다. 이것은 덜 인기있는 콘텐츠의 추천을 증가시키는 경향이 있다. 이 논문에서는 람다는 5로 하는 것이 최적의 점수를 얻을 수 있다고 주장한다.
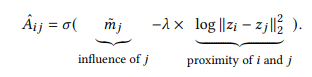
5. CONCLUSION
이 논문에서의 모델을 활용하여 cold start 문제를 해결하기 위한 효과적인 프레임워크를 제시하였다.
(다시 말하지만 이 논문의 선행연구 리뷰를 https://velog.io/@chwchong/Gravity-Inspired-Graph-Autoencoders-for-Directed-Link-Prediction 에 해놨다. 이 리뷰만 읽으면 모르는 단어들과 뭔가 설명이 많이 비어보이는 느낌을 받을 수도 있는데 위에 선행 연구 리뷰 링크에 들어가서 보면 좋을 것 같다.)
code
official code가 저자 github에 올라와있다. 아래에 링크를 첨부한다.
https://github.com/deezer/similar_artists_ranking
