Abstract
- Multi-Modal feature learning: Training scheme and architecture
Introduction
- Importance of developing multimodal feature fusion: many recent works are implemented with the ensemble of multiple networks dealing with different modalities(images and text embedding) or just simple concatenating.
=> not enough to acheive rich representation including mutual information between different modalities.
-
Proposed more effective learning scheme => Two-phase training, selective updating algorithm
-
Main Goal : Improving performance in multi-label classfication task (especially image-text hashtag prediction) rather than using single predictor as well as, when one of the modalities does not realted to ground-truth.
Contributions
- Proposed CACNet (4 indivisual networks)
- Training process for fusing the features
- Selective updating only when two different modalities have mutual relationship while using control parameters(less vulnerable results)
- Simplified implementation using virtual sigmoid function for using Batch Gradient Descent (why BGD is complex to implement in this case?)
- Experiments
Method
The Overall Architecture
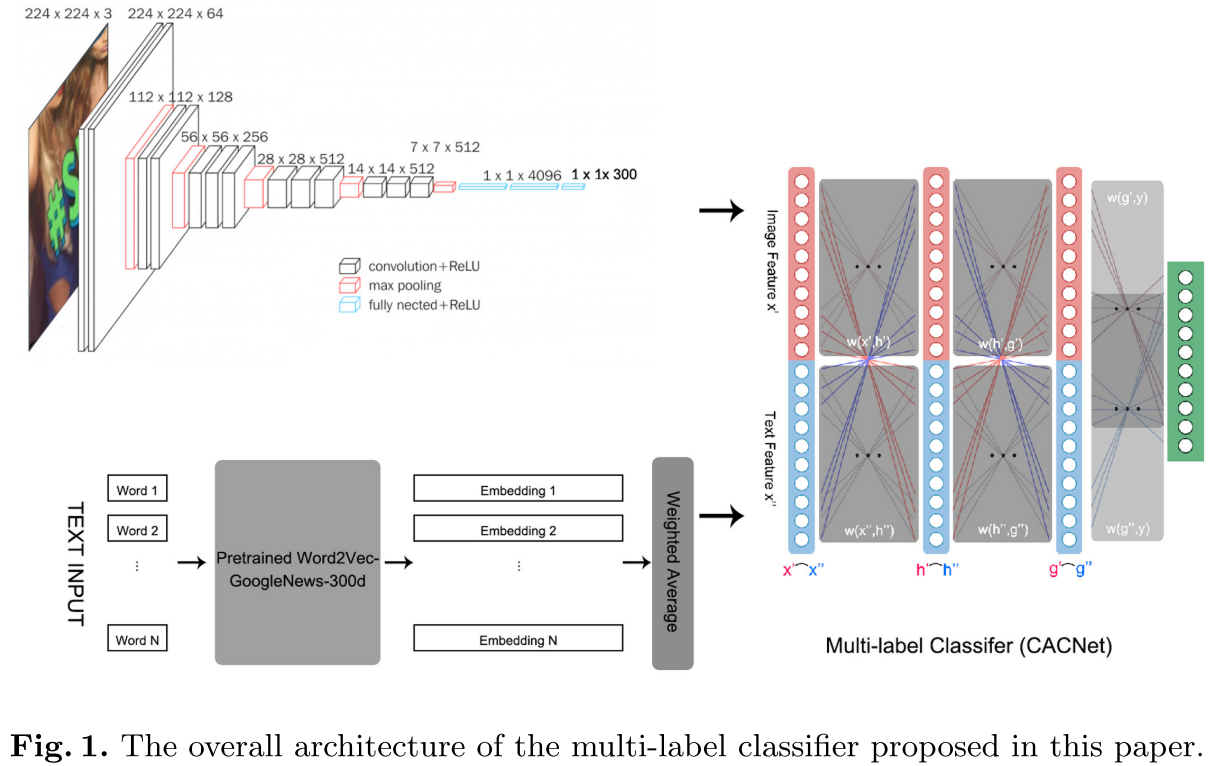
Pretrained VGG16(ImageNet) - image feature
Pretrained Word2Vec(Google News corpus) - text feature
Feature Extraction
previous work have proven that the weighted average of word embedding can strongly represent sentences. ~ 이하 문장 궁금?
Cross-Active Connection Network (이해 필요!)
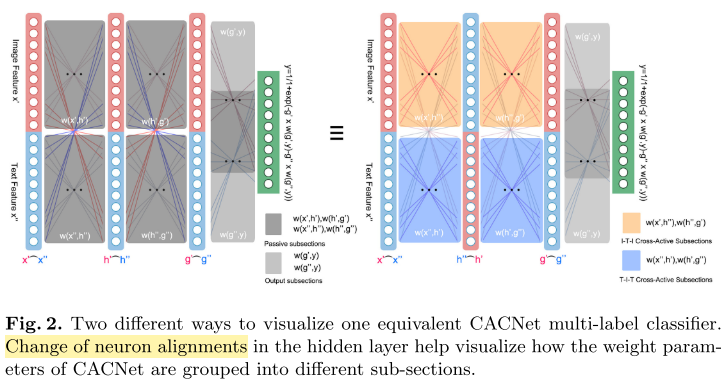
First phase: the cross-active connections 가 deactivated 될 때, loss function 계산이 안되므로, temporary use 용으로 virtual sigmoid output을 만듬
Passive subsection : update 시 freezing 되어있는 아이
Results
우리가 만든 CAC dataset에 대한 실험은 표 4
