
최근에 llama.cpp 관련 포스팅을 했었는데, 이번엔 gpu를 신나게 태울 수 있는 llm 서빙 엔진 vllm에 대해서 알아보려고 한다.

vllm(Virtual Large Language Model)은 UC Berkeley에서 개발된 LLM을 효율적으로 추론하고 서빙할 수 있도록 도와주는 오픈소스 라이브러리다.
💡 llama.cpp와의 차이점
- gpu 환경에서 최대 throughput을 달성하도록 설계 (vllm 도큐먼트에서 SOTA serving throughput이라고 표현하고 있다)
→ vllm은 양자화는 지원하지만 .gguf 형식 모델은 지원 안된다 ! PagedAttention을 사용하여 K,V memory를 효율적으로 관리- vram 사용 최적화하여 더 큰 batch 크기 지원
- 수천개 요청을 동시에 처리 가능(배치처리 최적화)하므로, 대량 요청 처리에는 vLLM이 훨씬 우수하다.
About PagedAttention
vllm의 핵심요소는 결국 PagedAttention이다.
그래서 pagedAttention이 뭔데? 먼저 pagedAttention의 사용 배경을 알기 위해서는, KV Cache 개념을 이해해야 한다.
- KV Cache
: decoding process에서 다음 토큰 생성을 위해 gpu 메모리에 저장된 K,V tensor
기존 트랜스포머 모델은 decoding process에서 매 토큰 생성 시마다 전체 입력 시퀀스에 대한 K, V 벡터를 재계산한다. 이는 시퀀스 길이가 늘어날수록 계산량을 기하급수적으로 증가시킨다.
계산 복잡도 - / 메모리 사용 -
반면, KV cache를 사용하는 경우, 다음 토큰 생성을 위해 이전 토큰의 K, V 벡터를 attention 연산 결과를 메모리에 저장하여 중복 계산을 방지하도록 한다. 기존 방법보다 계산 복잡도는 낮으나, 메모리 사용이 시퀀스 길이에 비례하여 증가된다.
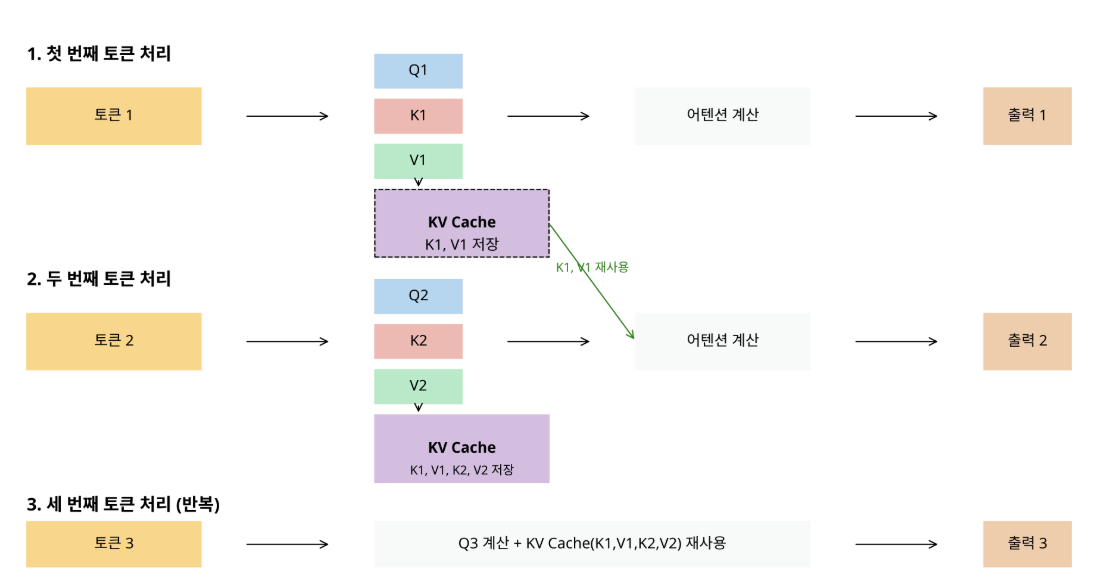
KV Cache 작동 원리
initial token generation: 첫 번째 토큰을 생성할 때, 모델은 입력 시퀀스에 대해 Q, K, V 벡터를 계산
saving K, V value: 계산된 K, V 값들을 메모리에 저장 (= KV Cache)
next token generation: 다음 토큰을 생성할 때, 모델은 새로운 토큰에 대한 Q, K, V만 계산하고, 이전 토큰들에 대한 K, V는 캐시에서 가져온다
cache update: 새로 계산된 K, V 값을 캐시에 추가2-4 과정을 원하는 길이의 시퀀스가 생성될 때까지 반복
계산 복잡도 - / 메모리 사용
대용량 언어 모델에서는 많은 메모리가 소모되고, 시퀀스 길이에 따라 KV cache가 매우 가변적이기 때문에, KV cache를 효율적으로 관리하는 것이 하나의 큰 도전 과제가 되었다. vllm에서는 이러한 문제 해결을 위하여 PagedAttention을 도입했다. 이는 운영 체제의 가상 메모리와 페이징 기술에서 영감을 받았다고 한다.
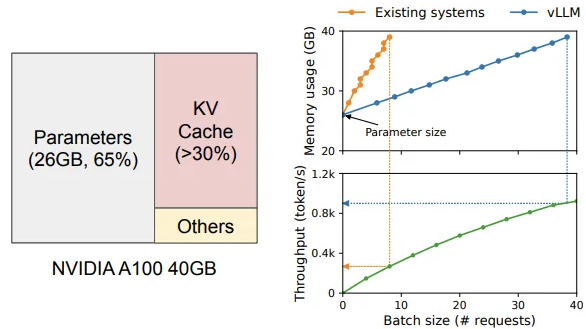
-
위 이미지에서 왼쪽 그래프는 NVIDIA A100 40GB GPU에서 LLM 서빙할 때의 메모리 레이아웃을 보여준다. 모델 파라미터가 26GB로 65%를 차지하고, KV cache가 30% 이상 차지함을 알 수 있다.
-
오른쪽 그래프는 Existing system을 통한 LLM serving과, vLLM을 통한 LLM serving 방법의 memory usage와 throughput을 비교한 결과이다. vLLM은 Existing system에 비해 KV cache 메모리의 급격한 증가를 완화하며, throughput을 눈에 띄게 향상시킴을 알 수 있다.
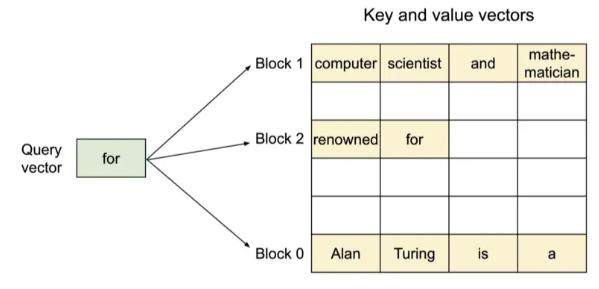
운영체제의 가상 메모리에서 물리적 메모리를 페이지 단위로 나누어 관리하듯이, PagedAttention은 위 그림과 같이 KV Cache를 고정된 크기 block으로 분할한다. 각 KV block은 비연속적인(non-contiguous) physical memory에 저장되고, 각 block은 필요할 때만 동적으로 할당되기 때문에 불필요한 memory reservation을 없앨 수 있다.
LLM 서비스 관점에서 PagedAttention의 작동방식을 좀 더 자세히 살펴보자.
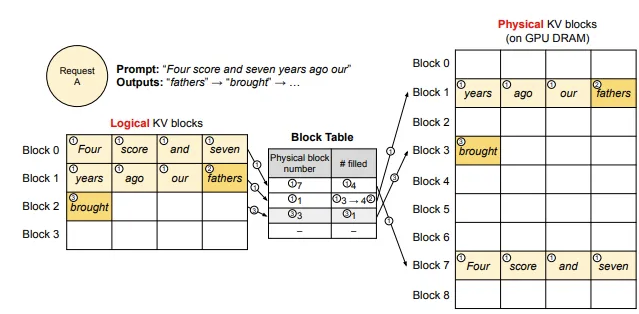
KV cache는 logical block과 physical block으로 구분하여 관리된다.
logical block: 각 요청에 대한 KV 캐시를 논리적으로 블록 단위로 나눈 것physical block: 실제 GPU 메모리에 할당된 블록block table: logical KV 블록과 physical KV 블록 간의 매핑 정보를 저장. 각 논리적 블록이 어떤 물리적 블록에 할당되었는지, 그리고 해당 블록에 채워진 토큰의 양(#filled) 등을 기록
Request A에서 "Four score and seven years ago our” 라는 프롬프트가 입력되었을때, 프롬프트 토큰을 저장하기 위해 필요한 logical KV block이 할당된다 (즉, 메모리를 미리 할당하지 않고 필요한 만큼만 할당) → block 0, block 1. 각 logical KV block은 block table을 통해 GPU DRAM 상의 physical KV block에 매핑되어 저장된다. → logical block 0 : physical block 7, logical block 1 : physical block 1
이후 토큰 생성 단계에서 마지막으로 할당된 logical block에 여유 공간이 있으면 해당 공간에 저장하고, logical block이 가득 차면 새로운 physical block을 할당받는다.
또한, PagedAttention은 메모리 효율성 향상을 위해 프롬프트가 여러 번 사용되거나, 유사한 프롬프트가 사용될 경우 저장된 KV cache 블록을 재사용하거나 공유할 수 있다. (Copy-on-Write) 이러한 메커니즘을 통해 프롬프트가 긴 시퀀스, beam search 등에서 메모리 절약 효과를 극대화시킨다.
논문, 공식 도큐먼트를 보고 핵심 내용 위주로 정리했는데, 더욱 자세한 내용이 궁금하다면 아래 논문을 참조하면 된다.
Efficient Memory Management for Large Language
Model Serving with PagedAttention (arXiv)
vLLM Application
vllm 은 현재 python 3.9+ (~3.12), linux에서 지원된다.
설치 방법은 간단히 pip install vllm 으로 하면 된다.
vllm을 커널에서 사용하기 위해서 먼저 vllm 서버를 시작해야 한다.
$ llm serve Qwen/Qwen2.5-1.5B-Instruct기본적으로 허깅페이스에서 모델을 다운로드하며, 지원되는 모델들은 도큐먼트에서 확인이 가능하다.
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen2.5-1.5B-Instruct",
"prompt": "San Francisco is a",
"max_tokens": 7,
"temperature": 0
}'
# or ?
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen2.5-1.5B-Instruct",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"}
]
}'python으로도 사용이 가능한데, 공식 문서에 예제 코드들이 있으니 참조하면 된다.
