
다소 뒷북인 Qwen3 paper review 지만...
하루에 논문 1편씩(?) 간단하게 훑고 올려 보기로 했다.
자세히 읽는 것도 좋지만 요즘 워낙 논문이 많이 쏟아지니까.. 빠르게 훑고 중요 논문이나 공부해야할 용어라던지, 기술 등은 따로 자세히 공부해서 포스팅 해 보는 것도 좋을거 같아서 시작해본다.
👉🏻 Qwen3
Abstract
Qwen3는 0.6 ~ 2,350억 개에 이르는 다양한 매개변수 규모의 대규모 언어 모델(LLMs) 시리즈다. 이 모델은 성능, 효율성, 그리고 다국어 능력을 발전시키기 위해 설계되었다. 주요 혁신 사항은 복잡하고 다단계 추론을 위한 사고 모드(thinking mode)와 빠르고 컨텍스트 기반의 응답을 위한 비사고 모드(non-thinking mode)를 단일 프레임워크에 통합한 것이다.
이는 사용자가 특정 작업에 따라 모델의 동작을 유연하게 조정할 수 있게 한다. 또한, 사고 예산(thinking budget) 메커니즘을 도입하여 추론 시 계산 리소스를 동적으로 할당할 수 있게 함으로써, 작업 복잡성에 따라 지연 시간과 성능의 균형을 맞출 수 있다. Qwen3는 SOTA를 달성했으며, 특히 코드 생성, 수학적 추론, 에이전트 작업 등 다양한 벤치마크에서 뛰어난 성능을 보인다. Qwen2.5에 비해 Qwen3는 다국어 지원을 29개에서 119개 언어 및 방언으로 확장하여 전 세계적인 접근성을 높인다.
1. Introduction
인공 일반 지능(artificial general intelligence, AGI) 또는 초인공지능( artificial super intelligenc, ASI) 추구는 오랜 인류의 목표다. GPT-4o, Claude 3.7, Gemini 2.5, DeepSeek-V3, Llama-4, Qwen2.5와 같은 large foundation models의 최근 발전은 이 목표를 향한 상당한 진전을 보여준다. 이 모델들은 수조 개의 토큰에 이르는 방대한 데이터셋으로 훈련되어 인간의 지식과 능력을 효과적으로 추출한다.
최근에는 강화 학습을 통해 최적화된 추론 모델(reasoning models)의 발전이 기반 모델의 추론 시간 확장 및 더 높은 수준의 지능 달성 가능성을 강조한다. 대부분의 최첨단 모델은 독점적(proprietary)이지만, 오픈 소스(open-source) 커뮤니티의 급속한 성장은 오픈 가중치 모델과 비공개 소스 모델 간의 성능 격차를 크게 줄였다. 점점 더 많은 최고 수준의 모델들이 오픈 소스로 공개되어 인공 지능 연구와 혁신을 촉진하고 있다.
Qwen-3 Overview
Qwen3는 Qwen 모델 제품군의 최신 시리즈로, 다양한 작업과 도메인에서 SOTA를 달성하는 open-weight 대규모 언어 모델 컬렉션이다. 이 시리즈는 dense 아키텍처 모델과 Mixture-of-Experts(MoE) 아키텍처 모델을 모두 포함하며, 매개변수 규모는 0.6억 ~ 2,350억 개에 달한다.
Qwen3의 주요 특징은 다음과 같다.
- 통합된 사고 및 비사고 모드: Qwen3는
사고 모드(thinking mode)와비사고 모드(non-thinking mode)를 단일 모델에 통합한다. 이를 통해 사용자는 다른 모델(예: Qwen2.5에서 QwQ로 전환) 간에 전환할 필요 없이 이 모드들 사이를 전환할 수 있다. 이 유연성은 개발자와 사용자가 특정 작업에 맞게 모델의 동작을 효율적으로 조정할 수 있도록 한다.- 사고 예산(Thinking Budget) 메커니즘: Qwen3는
사고 예산(thinking budget)기능을 통합하여, 사용자가 작업 실행 중 모델이 적용하는 추론 노력의 수준을 세밀하게 제어할 수 있도록 한다. 이 기능은 계산 리소스 및 성능을 최적화하는 데 중요하며, 실제 애플리케이션의 다양한 복잡성을 충족하도록 모델의 사고 동작을 맞춤 설정할 수 있게 한다.- 강화된 다국어 능력: Qwen3는 36조 개의 토큰으로 사전 훈련되었으며, 119개 언어 및 방언을 지원하도록 다국어 지원을 확장했다. 이는 교차 언어 이해 및 생성 능력을 향상시켜 전 세계적인 사용 사례에 대한 잠재력을 증폭시킨다.
- 효율적인 소규모 모델 구축: 플래그십 모델의 지식을 활용하여 소규모 모델 구축에 필요한 계산 리소스를 크게 줄이면서도 높은 경쟁력 있는 성능을 보장한다.
- 최첨단 성능: 광범위한 벤치마크에서 SOTA를 달성했으며, 코드 생성, 수학적 추론, 에이전트 작업 등에서 대규모 MoE 모델 및 독점 모델과 경쟁력 있는 성능을 보인다.
2. Architecture
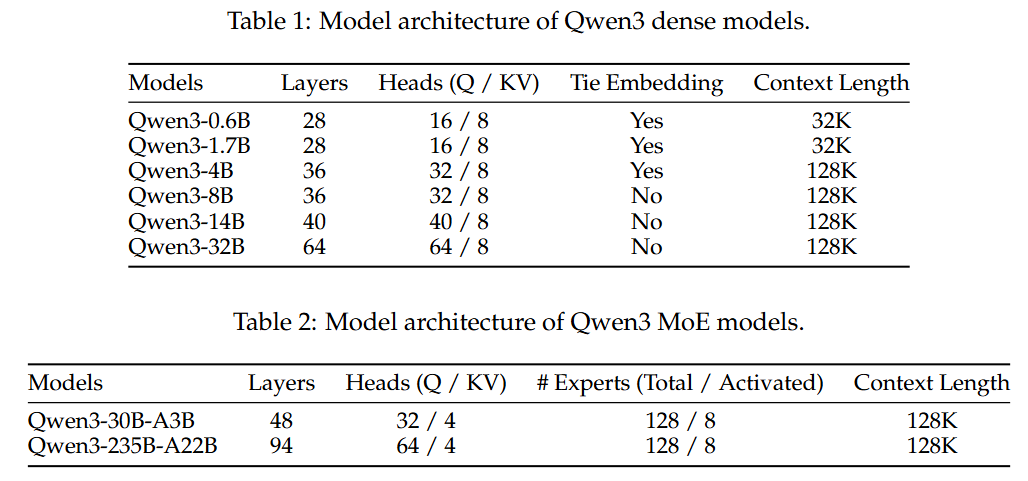
Qwen3 시리즈는 6개의 dense model(Qwen3-0.6B, Qwen3-1.7B, Qwen3-4B, Qwen3-8B, Qwen3-14B, Qwen3-32B)과 2개의 MoE model(Qwen3-30B-A3B, Qwen3-235B-A22B)로 구성된다.
플래그십 모델인 Qwen3-235B-A22B는 총 2,350억 개의 매개변수를 가지며, 토큰당 220억 개의 매개변수가 활성화된다.
Qwen3 dense model
Qwen3 dense model의 아키텍처는 Qwen2.5와 유사하며, 그룹화된 쿼리 어텐션(Grouped Query Attention, GQA), SwiGLU, 회전 위치 임베딩(Rotary Positional Embeddings, RoPE), 그리고 사전 정규화가 적용된 RMSNorm을 포함합니다. Qwen2에서 사용된 QKV-바이어스를 제거하고 QK-정규화(QK-Norm)를 어텐션 메커니즘에 도입하여 Qwen3의 안정적인 훈련을 보장합니다.
- 컨텍스트 길이: Qwen3-0.6B 및 Qwen3-1.7B는 32K 토큰, 나머지 조밀한 모델은 128K 토큰의 컨텍스트 길이를 지원합니다.
Qwen3 MoE model
Qwen3 MoE 모델은 Qwen3 조밀한 모델과 동일한 기본 아키텍처를 공유한다. Qwen2.5-MoE를 따라 fine-grained expert segmentation을 구현했다.
Qwen3 MoE 모델은 총 128개의 전문가를 가지며, 토큰당 8개의 전문가가 활성화된다. Qwen2.5-MoE와 달리 Qwen3-MoE 설계에서는 shared expert를 제외한다. 또한, global-batch load balancing loss를 채택하여 전문가의 전문화를 장려한다.
- 컨텍스트 길이: 두 MoE 모델(Qwen3-30B-A3B, Qwen3-235B-A22B) 모두 128K 토큰의 컨텍스트 길이를 지원
- 토크나이저: Qwen3 모델은
byte-level byte-pair encodin(BBPE)을 구현한 Qwen의 토크나이저를 사용하며, a vocabulary size는 151,669임
3. Pre-training
Qwen3 모델의 사전 훈련은 데이터 규모와 다양성, 언어 지원 측면에서 Qwen2.5에 비해 크게 확장되었다.
3.1. Pre-training Data
-
규모 및 다양성: 모든 Qwen3 모델은 총 36조 개의 토큰으로 구성된 대규모 및 다양성 있는 데이터셋으로 훈련
Qwen2.5에 비해 두 배 많은 토큰 수와 세 배 많은 언어를 포함. 데이터셋은 코딩, STEM(Science, Technology, Engineering, and Mathematics), 추론 작업, 서적, 다국어 텍스트, 합성 데이터 등 다양한 도메인의 고품질 콘텐츠를 포함
-
데이터 확장 기법:
- Qwen2.5-VL 활용: Qwen2.5-VL 모델을 사용하여 대량의 PDF 문서에서 텍스트를 추출하고, 이를 Qwen2.5 모델로 정제하여 수조 개의 고품질 텍스트 토큰을 추가 확보
- 합성 데이터 생성: Qwen2.5, Qwen2.5-Math, Qwen2.5-Coder 모델을 사용하여 교과서, 질문-답변, 지침, 코드 스니펫 등 수십 개 도메인에 걸쳐 수조 개의 합성 텍스트 토큰을 생성
- 다국어 데이터 확장: Qwen2.5에서 지원하던 29개 언어에서 119개 언어 및 방언으로 지원 언어 수 크게 증가
-
다국어 데이터 주석 시스템: 훈련 데이터의 품질과 다양성을 높이기 위해 교육적 가치, 분야, 도메인, 안전 등 여러 차원에서 30조 개 이상의 토큰에 주석 작업하여 데이터 필터링 및 조합을 더욱 효과적으로 지원
3.2. Pre-training Stage
Qwen3 모델은 다음의 세 단계를 거쳐 사전 훈련된다:
General Stage (S1): 이 첫 번째 사전 훈련 단계에서 모든 Qwen3 모델은 4,096 토큰 시퀀스 길이를 사용하여 30조 개 이상의 토큰으로 훈련됨
이 단계에서 모델은 119개 언어 및 방언을 포함한 언어 숙련도와 일반적인 세계 지식에 대해 충분히 사전 훈련됨
Reasoning Stage (S2): 추론 능력을 더욱 향상시키기 위해 STEM, 코딩, 추론 및 합성 데이터의 비율을 늘려 사전 훈련 코퍼스를 최적화
모델은 약 5조 개의 고품질 토큰으로 4,096 토큰 시퀀스 길이로 추가 사전 훈련됨
Long Context Stage: 마지막 사전 훈련 단계에서는 고품질 장문 컨텍스트 코퍼스를 수집하여 Qwen3 모델의 컨텍스트 길이를 확장. 모든 모델은 수천억 개의 토큰, 32,768 토큰의 시퀀스 길이로 사전 훈련됨.
long context corpus에는 16,384에서 32,768 토큰 길이의 텍스트가 75%, 4,096에서 16,384 토큰 길이의 텍스트가 25% 포함됨. Qwen2.5를 따라 RoPE의 기본 주파수를 10,000에서 1,000,000으로
ABF technique (Xiong et al., 2023)을 사용하여 증가시킴.또한,
YARN (Penget al., 2023)및Dual Chunk Attention(DCA)을 도입하여 추론 시 시퀀스 길이 용량을 네 배로 증가시킴
3.3. Pre-training Evaluation
Qwen3 시리즈의 base language mode에 대한 포괄적인 평가를 수행한다. 평가는 주로 일반 지식, 추론, 수학, 과학 지식, 코딩 및 다국어 능력에 중점을 둔다. 평가 데이터셋은 15개의 벤치마크를 포함하며, Qwen2.5 및 DeepSeek-V3 Base, Gemma-3, Llama-3, Llama-4와 같은 다른 주요 오픈 소스 기본 모델과 비교된다.
🪑 benchmarks
-
General Tasks: MMLU (Hendrycks et al., 2021a) (5-shot), MMLU-Pro (Wang et al., 2024) (5shot, CoT), MMLU-redux (Gema et al., 2024) (5-shot), BBH (Suzgun et al., 2023) (3-shot, CoT), SuperGPQA (Du et al., 2025) (5-shot, CoT) -
Math & STEM Tasks: GPQA (Rein et al., 2023) (5-shot, CoT), GSM8K (Cobbe et al., 2021) (4-shot,CoT), MATH (Hendrycks et al., 2021b) (4-shot, CoT)
✅ 평가 결과 요약
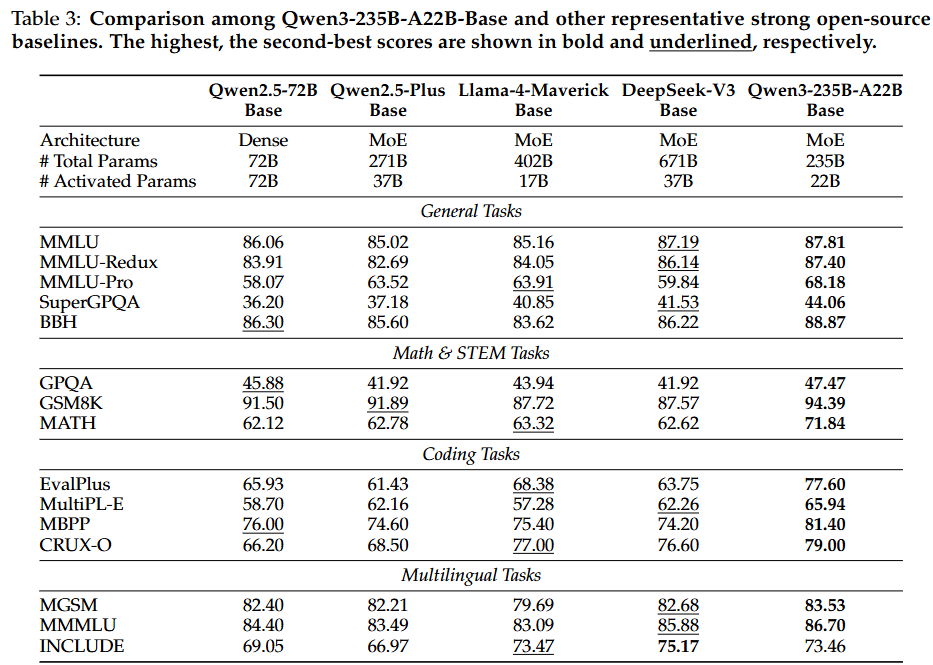
- Qwen3-235B-A22B-Base
: 대부분의 작업에서 DeepSeek-V3 Base, Llama-4-Maverick Base 및 Qwen2.5-72B-Base와 같은 이전 SOTA 오픈 소스 조밀/MoE 기본 모델을 능가하며, 훨씬 적은 총 매개변수 또는 활성화된 매개변수로 성능 달성
특히 DeepSeek-V3-Base보다 총 매개변수는 약 1/3, 활성화된 매개변수는 2/3 수준임에도 불구하고 15개 벤치마크 중 14개에서 더 우수한 성능을 보임
- Qwen3 MoE 기본 모델의 효율성
: 동일한 사전 훈련 데이터를 사용했을 때, Qwen3 MoE 기본 모델은 활성화된 매개변수의 1/5만으로 Qwen3 dense 기본 모델과 유사한 성능을 달성할 수 있음.
또한 Qwen2.5 MoE 기본 모델보다 활성화된 매개변수가 1/2 미만이고 총 매개변수도 적음에도 불구하고 더 나은 성능을 보임.
Qwen2.5 dense 기본 모델의 활성화된 매개변수의 1/10만으로도 비교할 만한 성능을 달성하여 추론 및 훈련 비용에서 상당한 이점을 제공
- Qwen3-dense 기본 모델의 성능
: Qwen3 조밀한 기본 모델의 전반적인 성능은 더 높은 매개변수 규모의 Qwen2.5 기본 모델과 비교할 만 함. 특히 STEM, 코딩 및 추론 벤치마크에서 Qwen3 조밀한 기본 모델은 더 높은 매개변수 규모의 Qwen2.5 기본 모델의 성능을 능가하기도 함
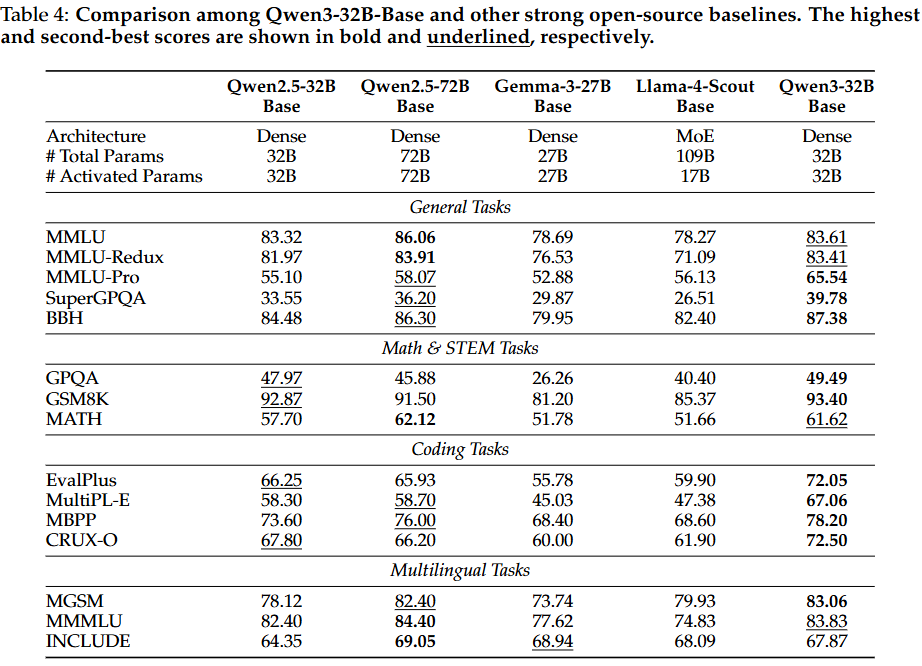
- Qwen3-32B-Base
: Qwen3 시리즈 중 가장 큰 조밀한 모델로, Qwen2.5-32B-Base 및 Gemma-3-27B Base보다 대부분의 벤치마크에서 뛰어난 성능을 보임. Qwen2.5-72B-Base보다 매개변수가 절반 이하임에도 불구하고 15개 평가 벤치마크 중 10개에서 Qwen2.5-72B-Base를 능가
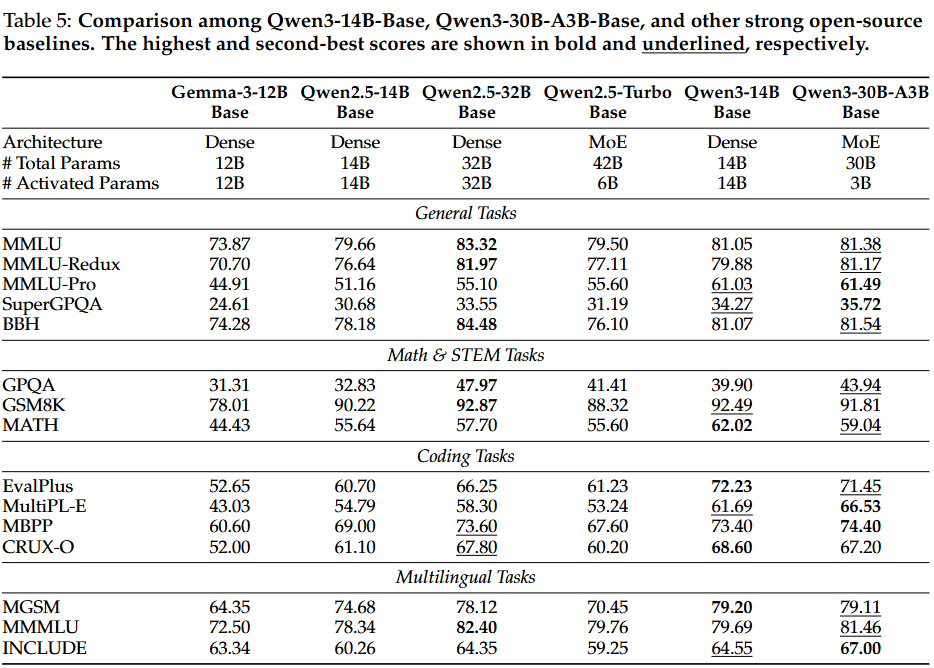
- 소형 모델의 강점
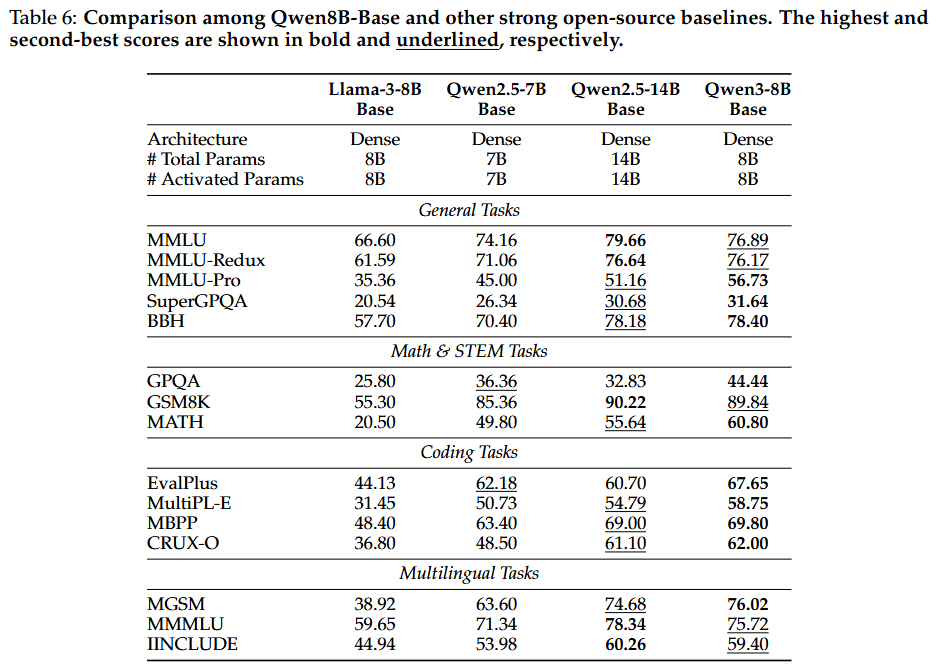
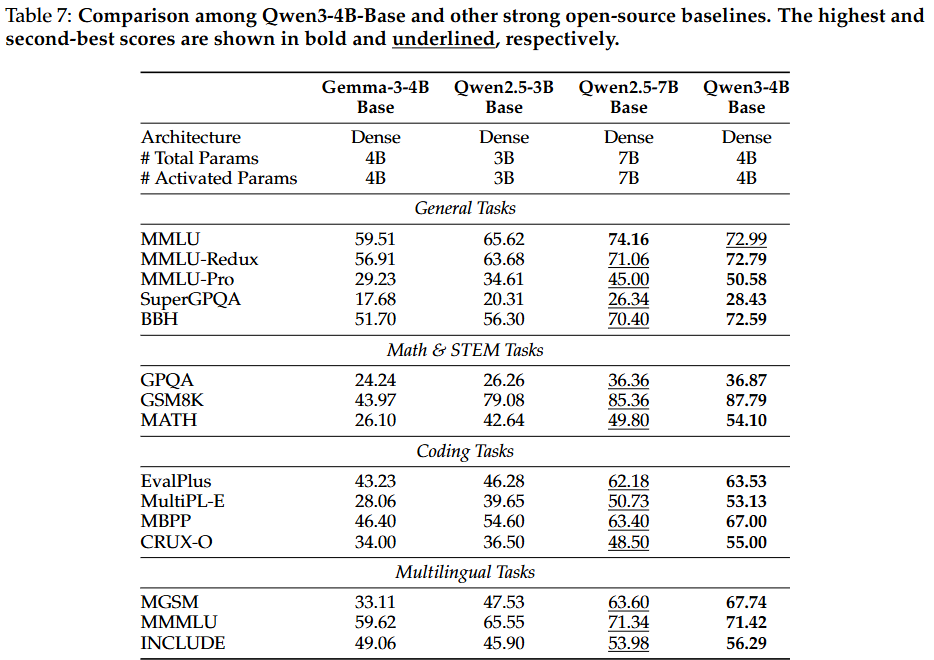
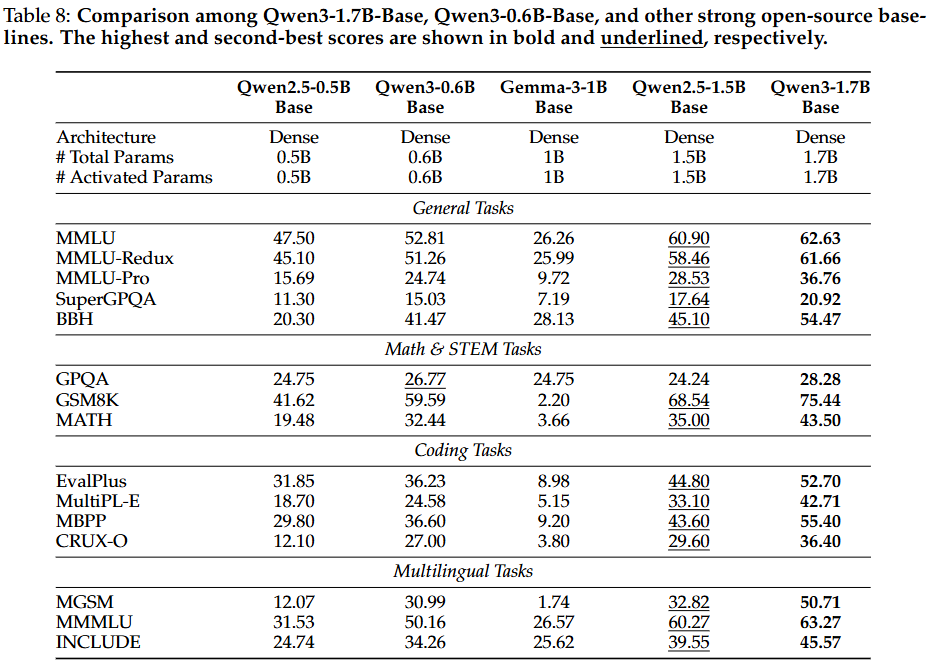
: Qwen3-8B / 4B / 1.7B / 0.6B-Base 모델들은 모든 벤치마크에서 강력한 성능을 유지.
Qwen3-8B / 4B / 1.7B-Base 모델들은 더 큰 규모의 Qwen2.5-14B / 7B / 3B Base 모델들보다 절반 이상의 벤치마크에서, 특히 STEM 관련 및 코딩 벤치마크에서 뛰어난 성능을 보임.
4. Post-training
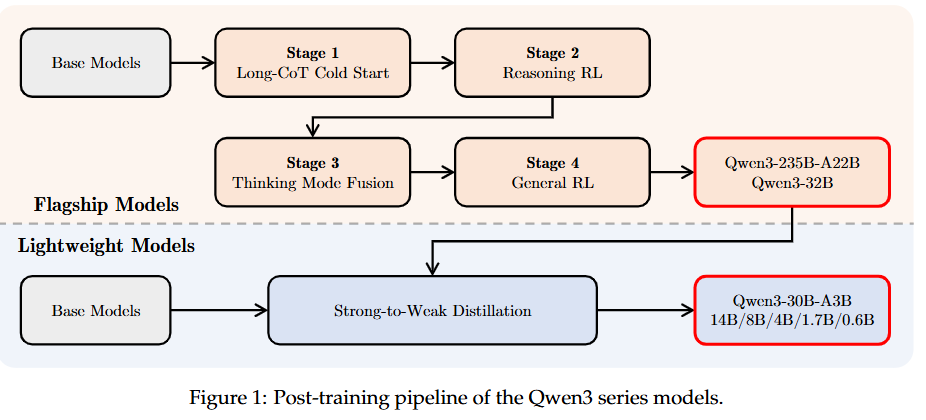
Qwen3의 후처리 훈련 파이프라인은 두 가지 핵심 목표로 전략적으로 설계되었다:
- 사고 제어 (Thinking Control): "비사고 모드"와 "사고 모드"라는 두 가지 개별 모드의 통합을 포함하여, 사용자가 모델이 추론에 참여할지 여부를 선택하고, 사고 과정에 대한 토큰 예산을 지정하여 사고의 깊이를 제어할 수 있는 유연성을 제공합니다.
- 강화-약화 증류 (Strong-to-Weak Distillation): 경량 모델의 후처리 훈련 프로세스를 간소화하고 최적화하는 것을 목표로 합니다. 대규모 모델의 지식을 활용하여 소규모 모델 구축에 필요한 계산 비용과 개발 노력을 크게 줄입니다.
플래그십 모델은 정교한 4단계 훈련 프로세스를 따른다. 처음 두 단계는 모델의 "사고" 능력 개발에 중점을 두고, 다음 두 단계는 강력한 "비사고" 기능을 모델에 통합하는 것을 목표로 한다.
경량 모델의 경우, 모든 소규모 모델에 대해 개별적으로 4단계 훈련 프로세스를 수행할 필요 없이 teacher model로부터 직접 출력을 증류(distillation)하는 것이 효과적이다. 이 접근 방식은 GPU 시간을 1/10만 요구하면서도 더 나은 즉각적인 성능과 모델의 탐색 능력 향상(Pass@64 점수 향상)을 가져온다.
4.1. Long-CoT Cold Start
-
목표: 모델에 Chain-of-Thought(CoT) 추론의 기초적인 패턴을 주입하는 초기 단계
-
데이터셋 구축: 수학, 코드, 논리적 추론, 일반 STEM 문제 등 광범위한 범주를 아우르는 포괄적인 데이터셋을 수집. 각 문제에는 검증된 참조 답변 또는 코드 기반 테스트 케이스가 쌍으로 연결
-
필터링: Qwen2.5-72B-Instruct를 사용하여 검증하기 어렵거나, CoT 추론 없이도 정확하게 답변할 수 있는 쿼리, 또는 지나친 반복, 추측성 답변 등을 제거
-
후보 응답 생성: QwQ-32B를 사용하여 각 쿼리에 대해 여러 후보 응답을 생성하고, 정확도가 낮은 경우 인간 주석자가 수동으로 평가
-
훈련: 선별된 데이터셋을 사용하여 초기 콜드 스타트(cold-start) 훈련을 수행하며, 이 단계에서는 즉각적인 추론 성능보다는 기본적인 추론 패턴 주입에 집중함
4.2. Reasoning RL
-
목표:
강화 학습(Reinforcement Learning, RL)을 통해 모델의 추론 능력을 실질적으로 향상 -
데이터: 콜드 스타트 단계에서 사용되지 않았고, 모델이 학습할 수 있으며, 도전적이고, 다양한 하위 도메인을 포괄하는 query-verifier pair를 수집
-
훈련:
GRPO (Shao et al., 2024)를 사용하여 모델 매개변수를 업데이트하며, 큰 배치 크기와 높은 rollout 수, 그리고 샘플 효율성을 높이기 위한 오프-정책(off-policy) 훈련이 유익함이 관찰되었음. 탐색(exploration)과 활용(exploitation)의 균형을 맞추기 위해 모델의 엔트로피를 제어하여 훈련 안정성을 유지 -
성과: 단일 RL 실행 과정에서 훈련 보상 및 검증 성능이 꾸준히 향상되었으며, 예를 들어 Qwen3-235B-A22B 모델의 AIME’24 점수는 170 RL 훈련 단계 동안 70.1에서 85.1로 증가

사고 모드와 비사고 모드의 chat template (Table 9)
명령어(Flag) 사용: 사용자가 프롬프트 끝에
/think또는/no_think라는 특별한 명령어를 붙여 모델의 작동 방식을 제어함./think는 기본값이므로 생략 가능
사고 모드 (Thinking Mode) :사용자가/think명령어를 사용하면, 모델은 최종 답변을 내놓기 전에 먼저<think>...</think>태그 안에 자신의 사고 과정(reasoning process)을 생성하도록 학습됩니다.
비사고 모드 (Non-Thinking Mode) :사용자가/no_think명령어를 사용하면, 모델은 사고 과정을 거치지 않고 비어있는<think></think>태그를 출력한 뒤 바로 최종 답변을 생성하도록 학습됩니다
4.3. Thinking Mode Fusion
-
목표: 이 단계는 이전에 개발된 "사고" 모델에 "비사고" 기능을 통합하는 것이 목표. 이를 통해 개발자는 추론 동작을 관리하고 제어하는 동시에, 사고 및 비사고 작업에 대한 별도의 모델을 배포하는 비용과 복잡성을 줄임
-
훈련 방식: 추론 RL 모델에 대한 지속적인 지도 미세 조정(continual supervised fine-tuning, SFT)을 수행하고 두 모드를 융합하기 위한 채팅 템플릿을 설계
-
SFT 데이터 구성: SFT 데이터셋은 "사고" 데이터와 "비사고" 데이터를 모두 결합. "사고" 데이터는 2단계 모델을 사용하여 생성되며, "비사고" 데이터는 코딩, 수학, 지시 따르기, 다국어 작업, 창의적 글쓰기, 질문 답변 및 역할극 등 다양한 작업을 포괄하도록 신중하게 큐레이션됨.
-
채팅 템플릿 설계: 사용자가 모델의 사고 프로세스를 동적으로 전환할 수 있도록 채팅 템플릿을 설계했. 예를 들어, "사고 모드" 및 "비사고 모드" 샘플에 대해 사용자 쿼리 또는 시스템 메시지에 각각
/think및/no think플래그를 도입합니다. 기본적으로 모델은 사고 모드에서 작동. -
사고 예산 (Thinking Budget) 구현: 모델이 "비사고" 모드와 "사고" 모드에서 모두 응답하는 방법을 학습하면, 불완전한 사고를 기반으로 응답을 생성하는 중간 케이스를 처리하는 능력이 자연스럽게 발달.
모델의 사고 길이가 사용자 정의 임계값에 도달하면, 사고 프로세스를 수동으로 중지하고 특정 지침을 삽입하여 모델이 해당 지점까지 축적된 추론을 기반으로 최종 응답을 생성하도록 함. 이 능력은 명시적으로 훈련되지 않고 사고 모드 통합 적용의 결과로 자연스럽게 나타나는 특징임.
4.4. General RL
-
목표: 다양한 시나리오에서 모델의 능력과 안정성을 광범위하게 향상시키는 것
-
보상 시스템: 20개 이상의 다양한 작업에 대한 정교한 보상 시스템을 구축했으며, 각각 맞춤형 채점 기준이 있음. 다음 핵심 능력 향상에 중점:
지시 따르기(Instruction Following): 모델이 콘텐츠, 형식, 길이, 구조화된 출력 사용 등 사용자 지시를 정확히 해석하고 따르도록 보장형식 따르기(Format Following):/think및/no think플래그에 따라 사고 모드와 비사고 모드를 전환하고,<think>및</think>토큰을 사용하여 사고 및 응답 부분을 분리하는 등 특정 형식 규칙을 준수하도록 함선호도 정렬(Preference Alignment): 개방형 쿼리에 대한 모델의 유용성, 참여도 및 스타일을 개선하여 보다 자연스럽고 만족스러운 사용자 경험을 제공하는 데 중점을 둠에이전트 능력(Agent Ability)지정된 인터페이스를 통해 도구를 올바르게 호출하도록 모델을 훈련하는 것을 포함특수 시나리오 능력: 검색 증강 생성(RAG) 작업과 같은 특정 시나리오에 맞춰진 작업을 설계하여 정확하고 맥락에 적절한 응답을 생성하도록 모델을 유도하여 환각(hallucination) 위험을 최소화
-
보상 유형:
규칙 기반 보상(Rule-based Reward): 추론 RL 단계에서 널리 사용되었으며, 지시 따르기 및 형식 준수와 같은 일반 작업에도 유용참조 답변을 사용한 모델 기반 보상(Model-based Reward with Reference Answer): 각 쿼리에 대한 참조 답변을 제공하고, Qwen2.5-72B-Instruct가 이 참조를 기반으로 모델의 응답을 채점하도록 함참조 답변 없는 모델 기반 보상(Model-based Reward without Reference Answer): 인간 선호도 데이터를 활용하여 보상 모델을 훈련하여 모델 응답에 스칼라 점수를 할당
4.5 Strong-to-Weak Distillation
-
목표: 경량 모델(5개의 조밀한 모델: Qwen3-0.6B, 1.7B, 4B, 8B, 14B 및 1개의 MoE 모델: Qwen3-30B-A3B)을 최적화하고 강력한 모드 전환 기능을 효과적으로 부여하기 위해 설계됨
-
두 가지 주요 단계:
-
오프-정책 증류(Off-policy Distillation): 초기 단계에서는 응답 증류를 위해
/think및/no think모드로 생성된 teacher model의 출력을 결합. 이는 경량 student model이 기본적인 추론 기술과 다른 사고 모드 간에 전환하는 능력을 개발하는 데 도움이 됨. -
온-정책 증류(On-policy Distillation): 이 단계에서는 학생 모델이 미세 조정을 위해 온-정책 시퀀스를 생성.
프롬프트가 샘플링되고, student model은
/think또는/no think모드로 응답을 생성합니다. 그런 다음 student model은 teacher model(Qwen3-32B 또는 Qwen3-235B-A22B)의 로짓과 일치하도록 미세 조정되어 KL 발산(KL divergence)을 최소화
-
4.6. Post-training Evaluation
명령어 미세 조정 모델의 품질을 종합적으로 평가하기 위해 사고 및 비사고 모드에서 모델 성능을 평가하는 자동화된 벤치마크를 채택한다.
평가 벤치마크 범주:
- 일반 작업: MMLU-Redux, GPQA-Diamond, C-Eval, LiveBench 등
- 정렬 작업: IFEval, Arena-Hard, AlignBench v1.1, Creative Writing V3, WritingBench 등이 사용되어 인간 선호도에 대한 모델의 정렬도 평가
- 수학 및 텍스트 추론: MATH-500, AIME’24 및 AIME’25, ZebraLogic, AutoLogi 등이 수학 및 논리적 추론 능력을 평가
- 에이전트 및 코딩: BFCL v3, LiveCodeBench v5, Codeforces Ratings 등이 모델의 코딩 및 에이전트 기반 작업 능력을 테스트
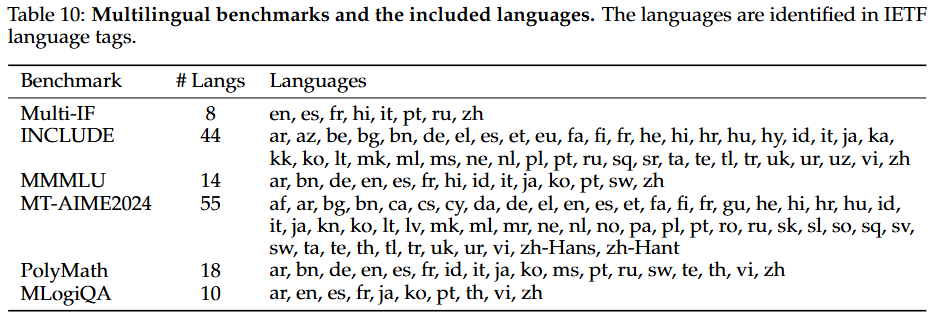
- 다국어 작업: Multi-IF, INCLUDE, MMMLU, MT-AIME2024, PolyMath, MLogiQA 등이 명령어 따르기, 지식, 수학, 논리적 추론 등 다양한 다국어 능력을 평가
주요 평가 결과 요약:
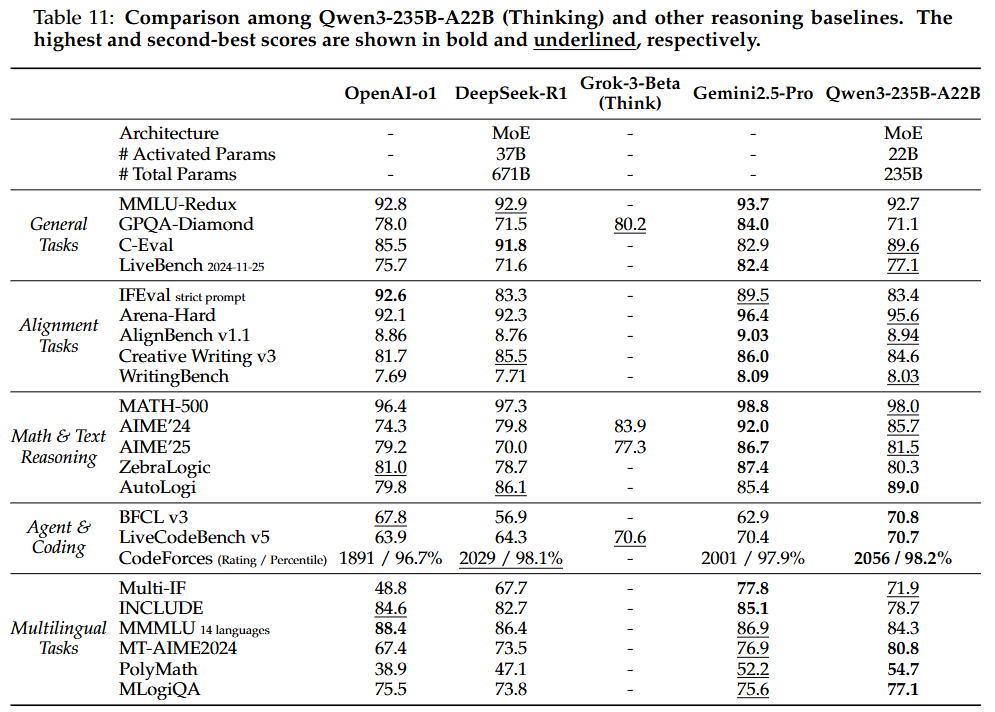
- Qwen3-235B-A22B (플래그십 모델):
-
사고 모드: 오픈 소스 모델 중 전반적으로 SOTA를 달리며, DeepSeek-R1 및 DeepSeek-V3와 같은 강력한 기준 모델을 능가.
활성화된 매개변수가 60%, 총 매개변수가 35%에 불과함에도 불구하고 DeepSeek-R1보다 23개 벤치마크 중 17개에서 뛰어난 성능을 보임. OpenAI-o1, Grok-3-Beta (Think), Gemini2.5-Pro와 같은 closed-source 선도 모델과도 경쟁력이 매우 높아, 오픈 소스 모델과 클로즈드 소스 모델 간의 추론 능력 격차를 좁힘
-
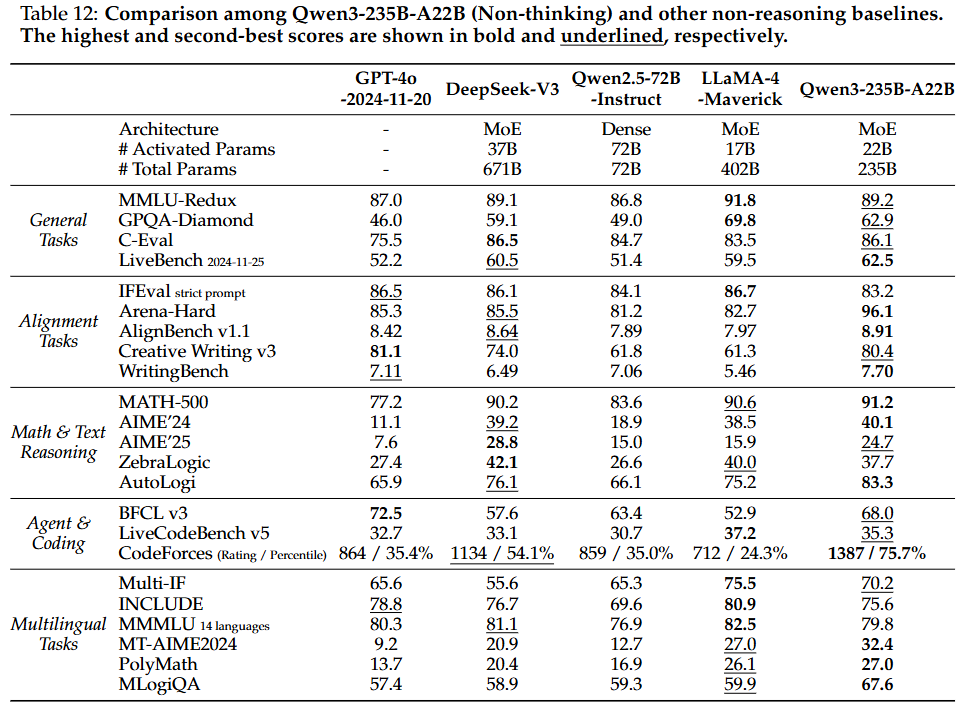
비사고 모드: DeepSeek-V3, LLaMA-4-Maverick 및 이전 플래그십 모델인 Qwen2.5-72B-Instruct를 포함한 다른 주요 오픈 소스 모델을 능가. 클로즈드 소스 GPT-4o-2024-11-20보다 23개 벤치마크 중 18개에서 우수한 성능을 보여, 의도적인 사고 과정이 강화되지 않아도 본질적으로 강력한 능력을 보임
-
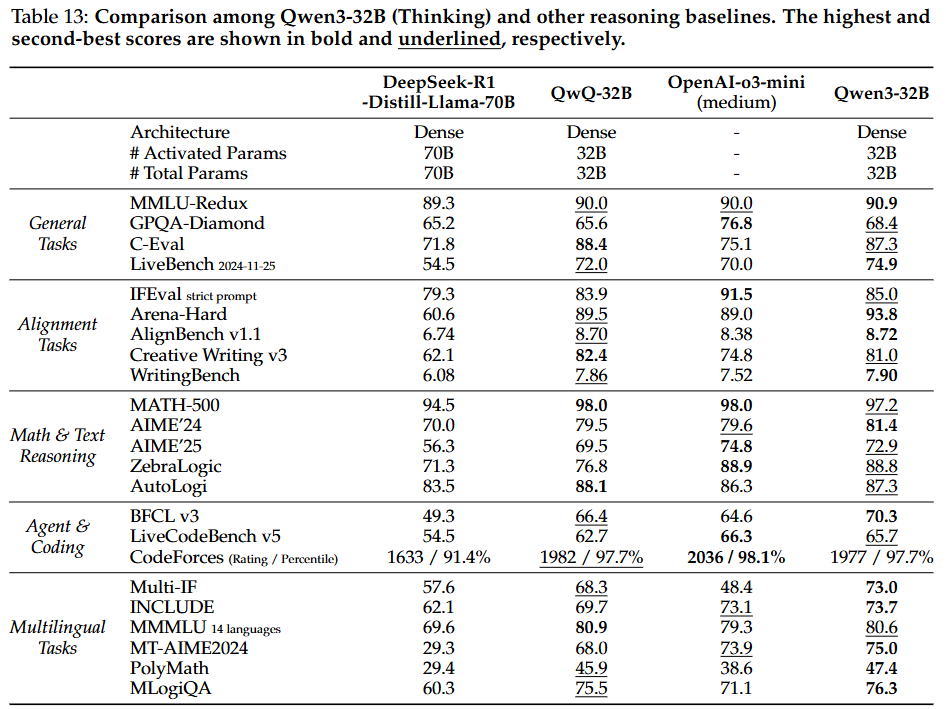
- Qwen3-32B (flagship dense model):
- 사고 모드: 이전의 가장 강력한 추론 모델인 QwQ-32B를 23개 벤치마크 중 17개에서 능가하여, 32B 규모에서 새로운 SOTA 추론 모델이 됨. 클로즈드 소스 OpenAI-o3-mini (medium)와도 경쟁력을 가지며 더 나은 정렬 및 다국어 성능을 보임.
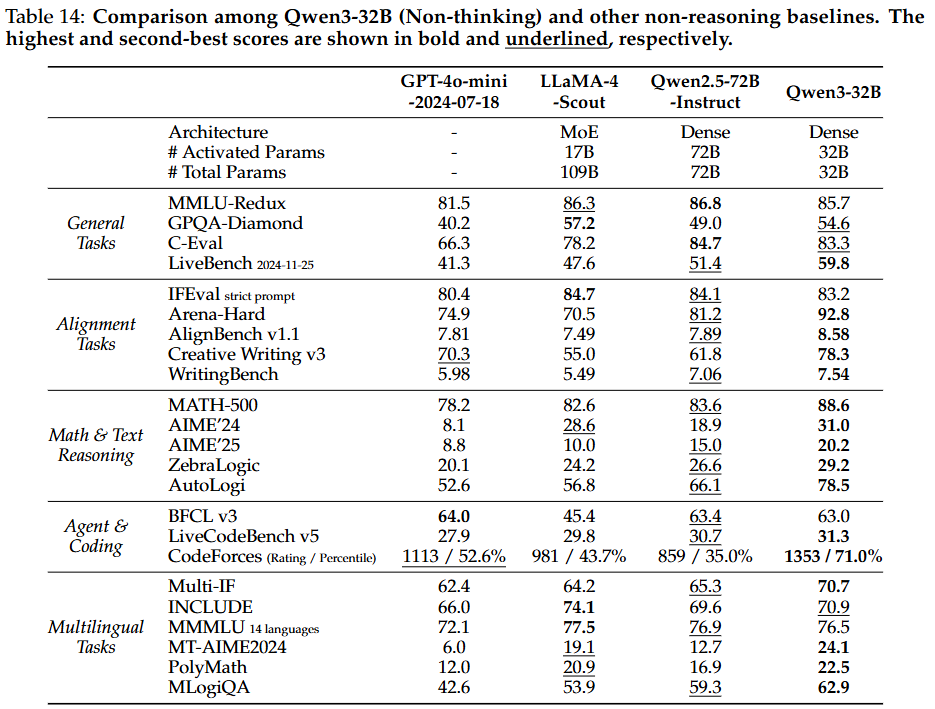
- 비사고 모드: 거의 모든 벤치마크에서 모든 기준 모델보다 뛰어난 성능을 보임. Qwen2.5-72B-Instruct와 일반 작업에서 동등한 성능을 보이며, 정렬, 다국어 및 추론 관련 작업에서 상당한 이점을 보여 Qwen3가 Qwen2.5 시리즈 모델보다 근본적으로 개선되었음을 다시 한번 입증
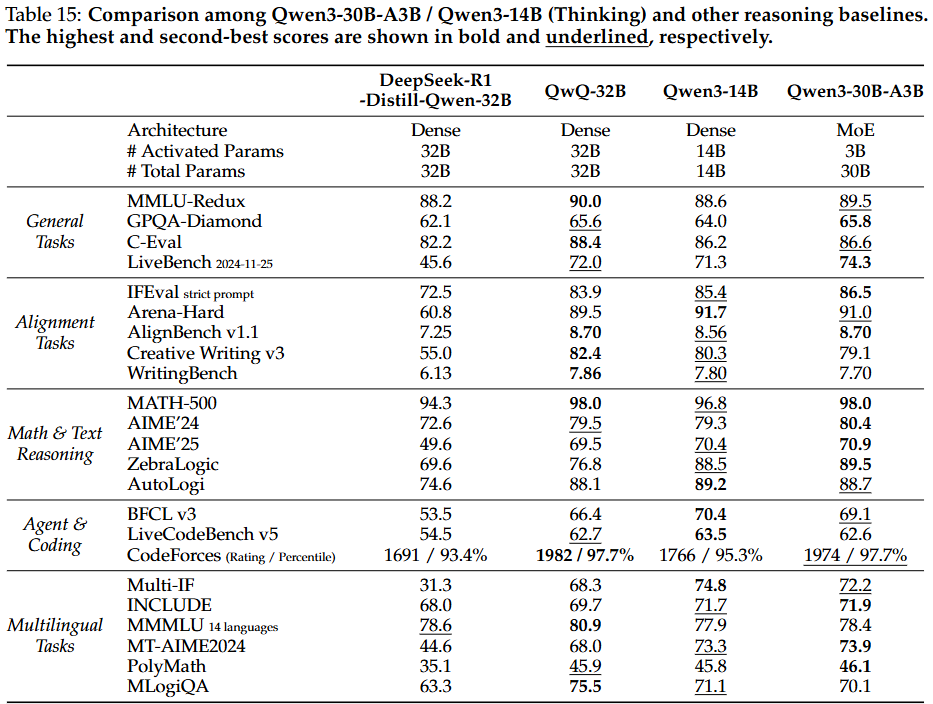
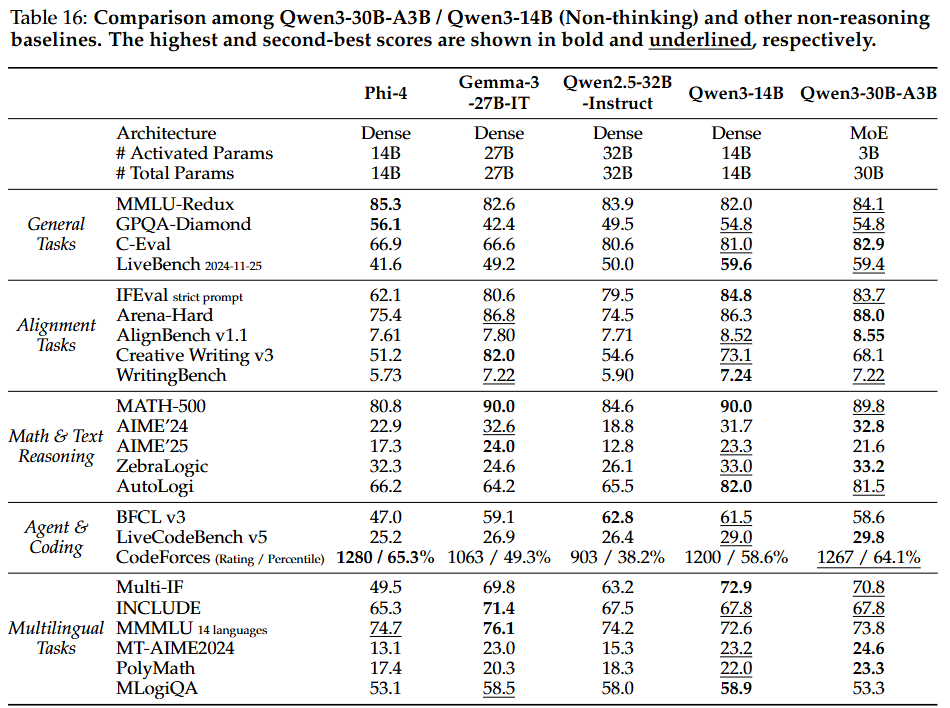
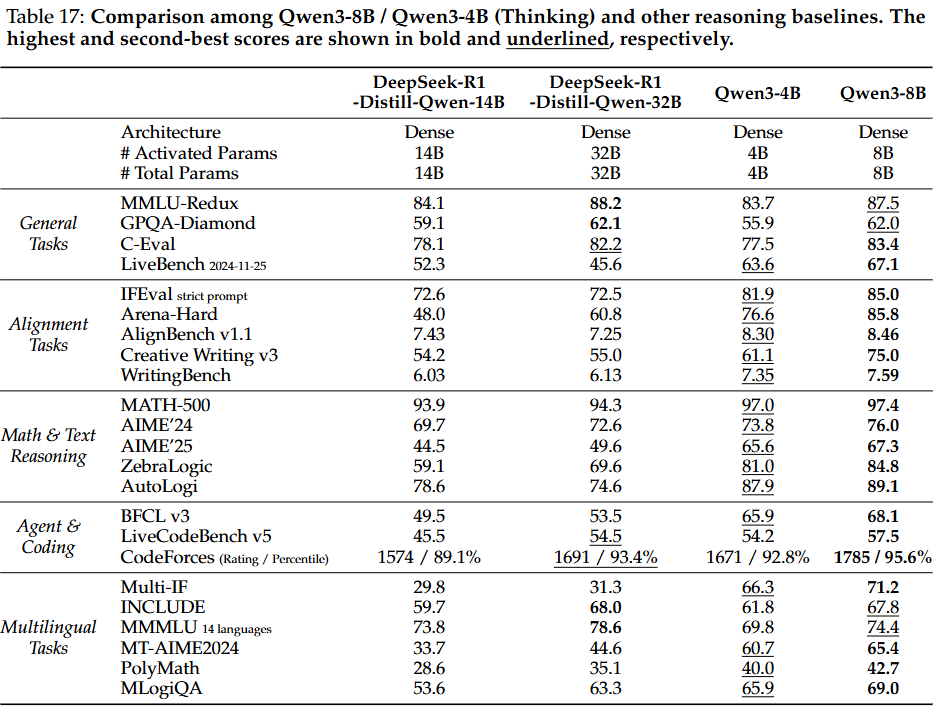
- 경량 모델 (Qwen3-30B-A3B, Qwen3-14B 및 기타 소형 모델):
- 강화-약화 증류의 성공: 이 모델들은 유사하거나 더 큰 매개변수 양을 가진 오픈 소스 모델보다 일관되게 우수한 성능을 보여, 강화-약화 증류 접근 방식의 성공을 입증. 특히 Qwen3-30B-A3B는 QwQ-32B와 비교할 만한 성능을 더 작은 모델 크기와 1/10 미만의 활성화된 매개변수로 달성하여 경량 모델에 심오한 추론 능력을 부여하는 강화-약화 증류의 효율성을 보임.
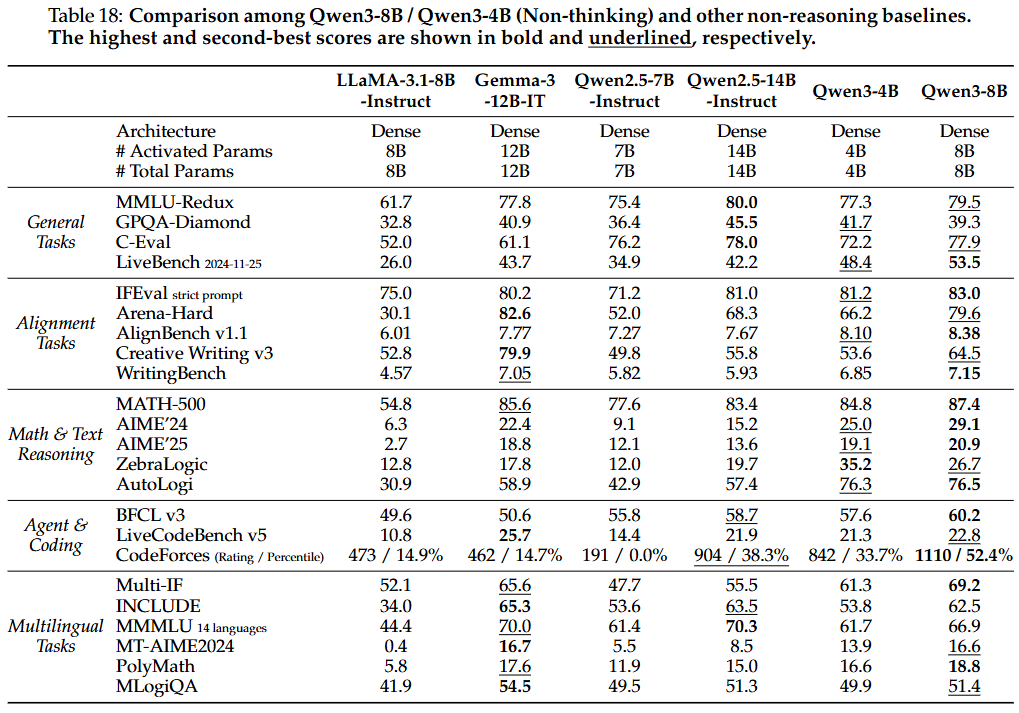
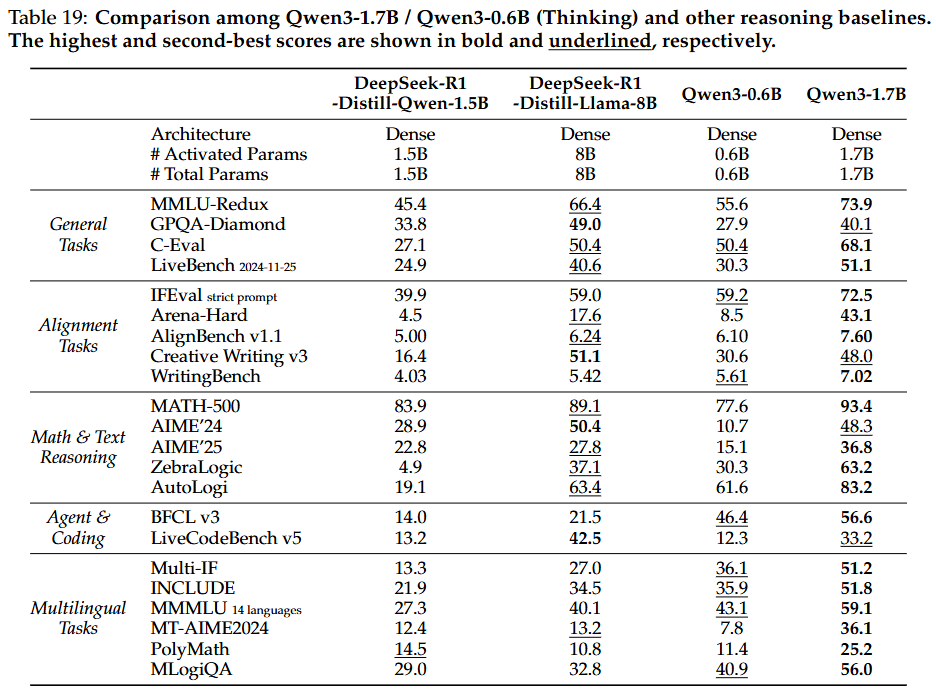
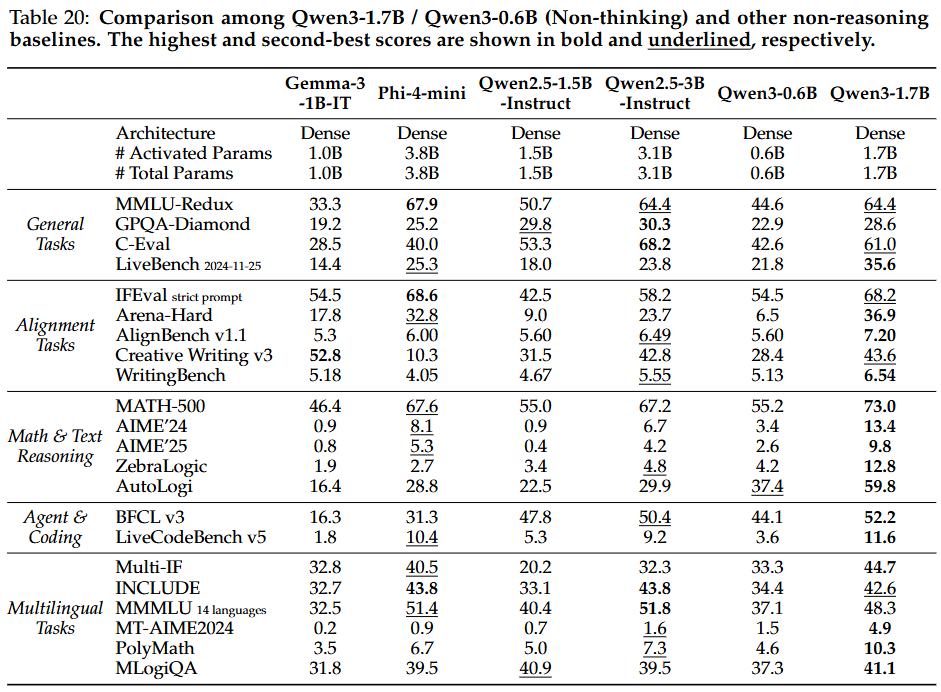
4.7. Discussion
-
사고 예산의 효과 (Effectiveness of Thinking Budget): Qwen3는 증가된 사고 예산을 활용하여 지능 수준을 향상시킬 수 있음을 입증한다. 수학, 코딩, STEM 도메인에 걸친 4가지 벤치마크에서 할당된 사고 예산에 비례하여 확장 가능하고 부드러운 성능 향상을 보인다.
-
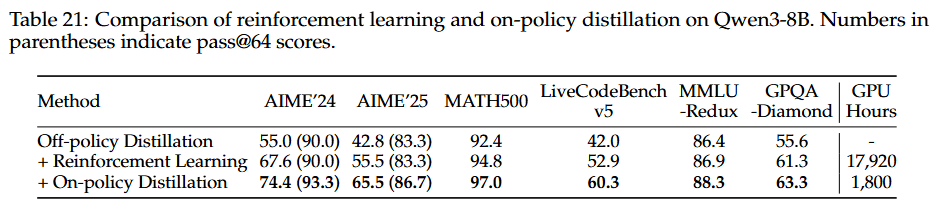
온-정책 증류의 효과 및 효율성 (Effectiveness and Efficiency of On-Policy Distillation): 온-정책 증류는 동일한 오프-정책 증류된 8B 체크포인트에서 시작한 직접 강화 학습보다 훨씬 더 나은 성능을 달성하며, GPU 시간은 약 1/10만 요구한다. 증류는 학생 모델이 탐색 공간을 확장하고 추론 잠재력을 향상시킨다.
-
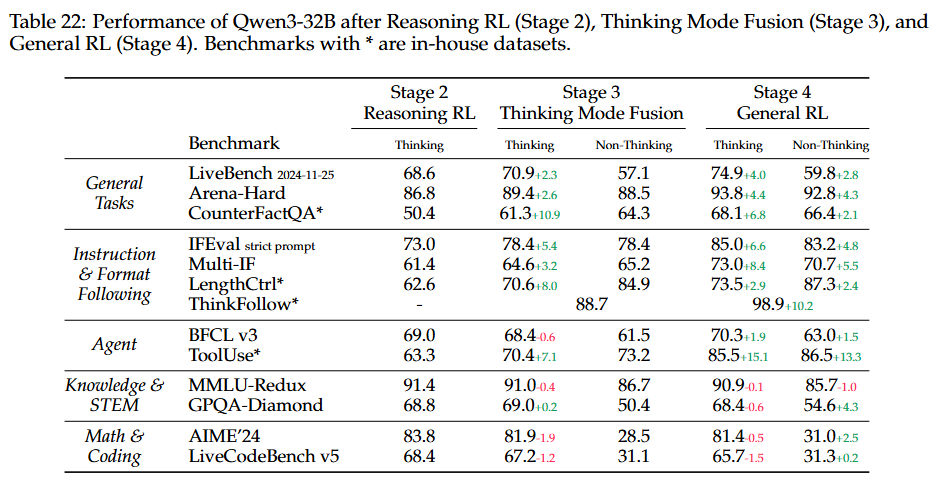
사고 모드 통합 및 General RL의 효과 (The Effects of Thinking Mode Fusion and General RL):
-
3단계(사고 모드 통합): 비사고 모드를 모델에 통합하고,
ThinkFollow벤치마크에서 88.7점을 기록하여 모드 간 전환 능력을 초기적으로 개발했음을 입증. 사고 모드에서 모델의 일반 및 지시 따르기 능력을 향상 -
4단계(General RL): 사고 및 비사고 모드 모두에서 모델의 일반, 지시 따르기 및 에이전트 능력을 더욱 강화.
ThinkFollow점수는 98.9로 향상되어 정확한 모드 전환을 보장합니다. -
성능 저하 및 trade-off: 지식, STEM, 수학, 코딩 작업에서는 사고 모드 통합 및 General RL이 유의미한 개선을 가져오지 못함. 실제로, AIME’24 및 LiveCodeBench와 같은 도전적인 작업에서 사고 모드 성능은 이 두 훈련 단계 후에 감소.
이는 모델이 더 넓은 범위의 일반 작업에 훈련되면서 복잡한 문제 처리에 대한 전문화된 능력이 저하될 수 있기 때문. Qwen3 개발 중에는 모델의 전반적인 다용도성 향상을 위해 이러한 성능 트레이드오프를 수용하기로 결정함.
-
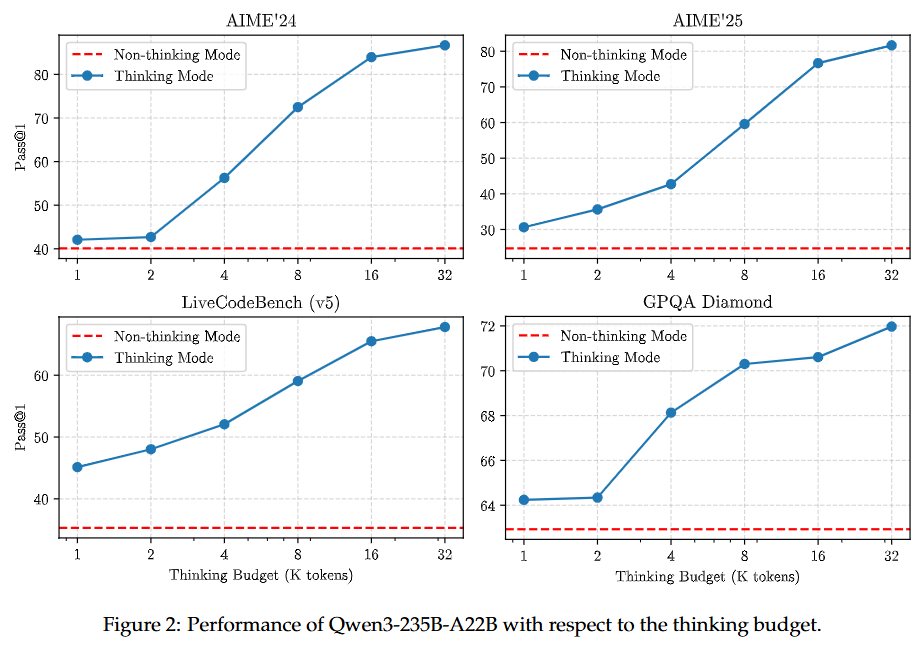
5. Conclusion
Qwen3는 사고 모드와 비사고 모드를 모두 특징으로 하여 사용자가 복잡한 사고 작업에 사용되는 토큰 수를 동적으로 관리할 수 있다. 이 모델은 36조 개의 토큰을 포함하는 방대한 데이터셋으로 사전 훈련되어 119개 언어 및 방언을 이해하고 생성할 수 있다.
Qwen3는 코드 생성, 수학, 추론 및 에이전트와 관련된 작업을 포함한 다양한 표준 벤치마크에서 사전 훈련 및 후처리 훈련 모델 모두에서 강력한 성능을 입증한다.
향후 연구 방향:
- 더 높은 품질과 더 다양한 콘텐츠의 데이터를 사용하여 사전 훈련 확장
- 효과적인 압축 및 극도로 긴 컨텍스트로의 확장을 위한 모델 아키텍처 및 훈련 방법 개선
- 환경 피드백으로부터 학습하는 에이전트 기반 RL 시스템에 특히 중점을 두고 강화 학습을 위한 계산 리소스 증대
