XLNet: Generalized Autoregressive Pretraining for Language Understanding(2019)논문을 읽고 내용 요약 및 정리
1. Introduction
비지도 학습 representation은 자연어 처리 영역에서 크게 성공한 방식이다. 이러한 방법론은 전형적으로 대용량의 라벨링 되지 않은 텍스트 코퍼스들로 먼저 사전학습 된 후, 다운스트림 태스크에 모델이나 representation을 파인튜닝 하는 방식으로 진행된다. 자기회귀(AR, auto-regressive) 언어 모델링과 오토 인코딩(AE, auto-encoding) 언어 모델링은 성공적인 사전학습 objective이다.
AR 언어 모델링은 자기 회귀 모델로 텍스트 코퍼스에 대한 확률 분포를 추정하는 방식을 추구한다. 특히, 텍스트 시퀀스 가 주어지면, AR 언어 모델링은 가능도(likelihood)를 전방 곱(forward product) 또는 후방 곱(backward product) 로 분해(factorize)한다. 신경망과 같이 parametic한 모델은 각 조건 분포(conditional distribution)을 모델링하도록 학습된다.
AR 언어 모델은 단방향 문맥(전방 or 후방)만 인코딩하도록 학습되기 때문에, 깊은 양방향 문맥을 모델링하는 데 효율적이지 못하다. 그러나, 다운스트림 언어 이해 태스크는 때로 양방향 문맥 정보를 필요로 한다. 이는 AR 언어 모델링과 효율적인 사전학습 간 격차를 만든다.
이와 비교하면, AE기반 사전학습은 명확한 밀도 추정보다는 손상된(corrupt) 입력에서 원본 데이터를 재구축(reconstruct)하는 것을 목표로 한다. 이러한 사전학습의 예는 SOTA 사전학습 접근법이었던 BERT이다. 입력 토큰 시퀀스가 주어졌을 때, 토큰의 일정 비율을 [MASK]라는 special symbol로 대체하고, 모델은 이렇게 손상된 상태에서 원본 토큰을 되찾기 위해 학습된다. BERT는 재구성을 위해 양방향 문맥을 활용하도록 허용된다. 이러한 방법은 AR 모델링의 양방향 정보 격차를 해결하여 성능을 향상시킨다는 장점이 있다. 그러나, 사전학습동안 BERT에서 사용된 [MASK]와 같은 인공적인 심볼이 파인튜닝 당시 실제 데이터에 존재하지 않기 때문에, 사전학습과 파인튜닝 간 차이를 발생시킨다.
그리고 예측된 토큰이 입력에서 마스킹되어 있기 때문에, BERT는 AR 언어 모델링에서와 같이 곱 규칙(product rule)을 사용한 결합 확률(joint probability)을 모델링 할 수 없다. 즉, 마스킹되지 않은 토큰이 주어졌을 때, BERT는 예측된 토큰이 각각 독립적이라고 가정하는데, 이러한 가정은 고차(high-order), 장거리(long-range) 의존성이 자연어에 만연하기 때문에 지나치게 단순화(oversimplified)된 것이다.
현존하는 언어 사전학습 objective의 장단점에 맞서, 본 논문은 AR과 AE의 한계를 피하면서 최적의 AR 언어 모델링과 AE를 활용하는 일반화된 자기 회귀 방법론, XLNet을 제시한다.
- 첫째로, 통상적인 AR 모델과 같이 고정된 전방(forward) 혹은 후방(backward) 분해 순서(factorization order)를 사용하는 대신, XLNet은 모든 가능한 분해 순서의 순열(permutation)에 대하여 시퀀스의 예상
로그 가능도(log likelihood)를 최대화한다. 순열 연산 덕분에, 각 포지션의 문맥이 왼쪽과 오른쪽의 토큰으로 구성될 수 있다. 각 포지션은 모든 포지션에서 문맥적 정보를 활용할 수 있도록 학습한다. 즉, 양방향 문맥을 포착하는 거이다. - 둘째로, XLNet은 일반화(generalized)된 AR 언어 모델로서 데이터 손상에 의존하지 않는다. 그러므로, XLNet은 BERT와 같이 사전학습과 파인튜닝 간 차이로 문제를 겪지 않는다. 한편, 자기회귀 objective는 예측의 토큰 결합 확률을 분해하는
곱 규칙(product rule)을 제공하며, BERT에서 만들었던 독립성 가정을 제거한다.
XLNet은 새로운 사전학습 objecitve와 더불어, 구조적 설계를 향상시킨다.
-
최근 AR 언어 모델링의 진보에 영감받아, XLNet은
세그먼트 재귀(segment recurrence)메커니즘과Transformer-XL의 인코딩 전략을 사전학습에 통합하여, 더 긴 텍스트 시퀀스를 포함하는 태스크의 성능을 특히 향상시킨다. -
순열 기반 언어 모델링에 Transformer(-XL) 구조를 나이브(naive)하게 적용하는 것은 효과가 없는데, 이는 분해 순서가 임의로 되어있고 target이 모호하기 때문이다.
-
Related Work
순열 기반 AR 모델링에 대한 발상은 일부 논문에서 탐구되어 왔는데, 여기에는 몇가지 차이점이 있다. 먼저 이전의 모델들은 “orderless(순서가 없는)” 귀납적 편향(inductive bias)를 모델에 적용하여 밀도 추정을 향상시키는 데 목적이 있는 반면, XLNet은 AR 언어 모델이 양방향 문맥을 학습할 수 있게 하는 것을 목표로 한다. 기술적으로, target-aware 예측 분포 구성을 위해 XLNet은 target position은 two-stream attention을 통해 은닉층으로 통합시키는 반면, 이전의 순열 기반 AR모델은 모델의 MLP 구조에 내재한 함축적인 position awareness에 의존한다.
또 다른 관련 연구는 텍스트 생성 맥락에서 autoregressive denoising을 수행하는 것으로, 여기서는 고정된 순서(fixed order)만 고려한다.
2. Proposed Method
먼저 전통적인 AR 언어 모델링과 BERT를 사전학습 방면에서 비교해 본다. 텍스트 시퀀스 가 주어지면, AR 언어 모델은 전방 자기회귀 분해(forward autoregressive factorization)하에서 가능도를 최대화하는 방식으로 사전학습을 수행한다.
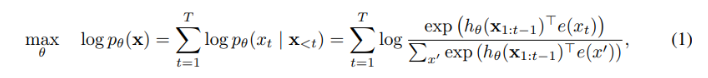
본 식에서 는 RNN 또는 Transformer와 같은 신경망 모델에서 생성된 context representation이고, 는 의 임베딩을 나타낸다.
이와 대조하여, BERT는 auto-encoding을 denoise 하는 것을 기반으로 사전학습을 수행한다. 명시적으로 말하면, BERT는 먼저 텍스트 시퀀스 에 대하여, 에서 일정 토큰 비율(예:15%)를 임의로 special symbol [MASK]로 설정함으로써 손상된 를 구축한다. 마스킹 된 토큰을 라고 할때, 학습 objective는 에서 을 재구축하는 것이다 :
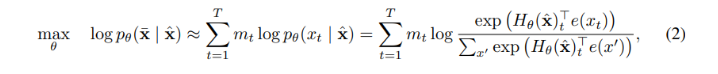
은 가 마스킹됨을 나타내고, 는 길이가 인 텍스트 시퀀스 를 히든 벡터 시퀀스 로 사상하는 트랜스포머이다.
다음 측면에서 두 가지 사전학습 objectives(AR과 BERT의 DAE)에 대한 장단점을 비교한다:
- Independene Assumption(독립성 가정) : 식 (2)의 ≈ 문자로 강조된 것과 같이, BERT는 모든 마스킹된 토큰
가 독립적으로 재구축된다는 독립성 가정에 기반한 공통 조건부 확률(joint conditional probability) 을 분해(factorize)한다. 이와 대조하여, AR 언어 모델 objective (1)은 이러한 독립성 가정 없이 보편성을 유지하는 곱 규칙(product rule)을 사용하여 를 분해(factorize)한다. - Input noise(입력 노이즈) : BERT의 입력은 [MASK]와 같은 인공적인 심볼을 포함하고, 이러한 심볼은 다운스트림 태스크에는 나타나지 않아 사전학습과 파인튜닝 간 차이(discrepancy)를 만든다. BERT의 [MASK]로 원본 토큰을 대체하는 방식이 이러한 차이의 문제를 해결하지 못하는 것은, 원본 토큰이 작은 확률에서만 사용되기 때문이다. 그렇지 않으면, 식 (2)를 최적화하는 것이 쉬워질(trivial) 것이다. 반면, AR 언어 모델은 어떠한 입력의 손상에도 의존하지 않아 이러한 문제를 겪지 않는다.
- Context dependency(문맥 의존성) : AR representation 은 포지션 까지(즉, 토큰의 왼쪽까지)의 토큰에서만 조성되는 반면, BERT representation 는 양쪽의 문맥 정보에 접근할 수 있다. 즉, BERT objective는 모델이 더 나은 양방향 문맥을 포착하도록 사전학습 할 수 있다.
이러한 비교 결과, AR 언어 모델과 BERT는 각자 고유한 장점을 가지고 있다는 것을 발견한다. 그렇다면 양측의 이점을 취하고, 단점을 피하는 사전학습 objective가 존재하는가?에 대한 의문히 자연히 생기게 된다.
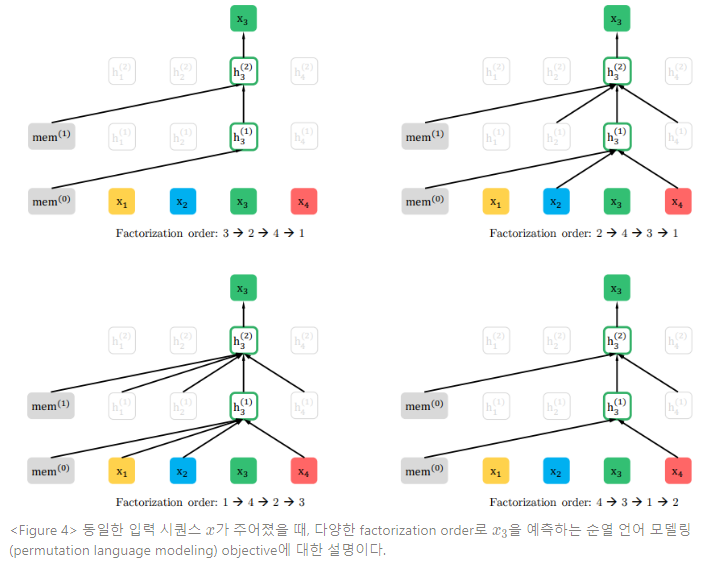
orderless NADE(2016)의 발상에 착안하여, 본 논문에서는 AR모델의 장점을 유지하면서 양방향 문맥을 포착할 수 있는 순열 언어 모델링(permutation language modeling) objective를 제안한다. 길이가 인 시퀀스 에서, 개의 상이한 순서(order)가 유효한 자기 회귀 분해(auto-regressive factorization)을 수행한다. 직관적으로, 모델 파라미터가 모든 factorization order에 거쳐 공유되면, 모델은 양쪽 포지션에 대한 정보를 모두 수집하도록 학습하게 된다.
이러한 발상을 공식화하면, 를 길이가 인 인덱스 시퀀스 에 대해 가능한 모든 순열 조합이라고 한다. 와 를 사용하여 순열 의 번째 엘리먼트와 초기의 번째 엘리먼트를 나타낸다. 그러면, 순열 언어 모델링 objective를 다음과 같이 표현할 수 있다 :
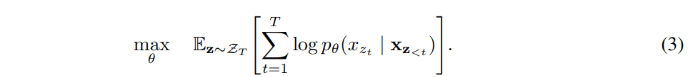
텍스트 시퀀스 를 위해 factorization order 를 샘플링하고, 가능도 를 factorization order에 따라 분해한다. 동일한 모델 파라미터 는 학습할 때 모든 factorization order에 걸쳐 공유되기 때문에, 는 시퀀스에서 모든 가능한 엘리먼트 를 목격하고, 따라서 양방향 문맥을 포착할 수 있게 된다. 또한, 이러한 objective가 AR 프레임워크에 맞추어지면, 앞서 논의했던 독립성 가정과 사전학습, 파인튜닝 간 차이도 피할 수 있게 된다.
- Remark on Permutation
본 논문에서 제안한 objective는 시퀀스 순서가 아닌 factorization order만을 배치한다. 즉, 원본 시퀀스의 순서를 유지하고, 원본 시퀀스에 상응하는 포지셔널 인코딩을 사용하고, factorization order의 순열을 구성하기 위해 적절한 트랜스포머의 어텐션 마스크에 의존한다.
순열 언어 모델링 objective는 desired properties를 갖고, 표준 트랜스포머 파라미터화로 나이브(naive)한 시행이 효과적이지 않을 수 있다. 이러한 문제점에 직면하기 위해, 다음 토큰의 분포 를 표준 소프트맥스 공식을 사용하여 파라미터화한다고 가정한다.
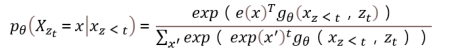
다음과 같은 식에서 는 적절한 마스킹 절차 이후에 공유된 트랜스포머 신경망에 의해 생성된 의 hidden representation을 나타낸다.
representation 은 예측할 포지션, 즉 값에 의존하지 않는다. 결국, 타겟 포지션과 관계없이 동일한 분포가 예측되는데, 이로써 유용한 representation을 학습하는 것이 불가하다. 이러한 문제를 피하기 위해, 다음 토큰 분포가 타겟 포지션을 잘 알 수 있도록(aware) 재파라미터화(re-parameterize) 하는 것을 제안한다 :
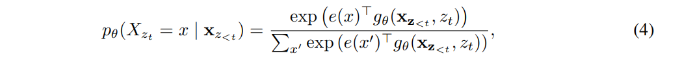
다음과 같은 식에서 는 타겟 포지션 를 부가적인 입력으로 취하는 새로운 형태의 representation을 나타낸다.
- Two-stream self-attention
target-aware representations에 대한 발상은 타겟 예측의 모호함을 제거했지만, 을 표현하는 방법은 복잡한 문제로 남아있다. 그래서 타겟 포지션 에 “머물러(stand)” 있으면서 에 의존하여 어텐션을 통해 의 문맥에서 정보를 수집하는 것을 제안한다. 이러한 파라미터화가 작용하려면, 표준 트랜스포머 구조에서는 모순되는(contradictory) 2가지 요건이 필요하다. :
(1) 토큰 와 를 예측하기 위해서는 문맥 가 아닌 포지션 를 사용해야 하는데, 그렇지 않으면 objective가 중요하지 않게(trivial) 된다.
(2) 에서 다른 토큰 를 예측하기 위해 는 문맥 도 인코딩해서 전체 문맥 정보를 제공해야 한다. 이러한 모순점 극복을 위해, 한개가 아닌 두개의 hidden representation을 사용하는 것을 제안한다 :
- content representation , 축약하면 은 트랜스포머의 표준 은닉 상태(hidden state)와 유사한 역할을 한다. 이러한 representation은 문맥과 를 인코딩한다.
- 쿼리 representation, , 축약하면 는 앞서 논의한 것처럼 문맥 정보 와 포지션 에만 접근할 수 있고, 문맥 에는 접근할 수 없다.
첫번째 레이어 query stream이 학습가능한 벡터, 즉 로 초기화될 때, content stream은 상응하는 워드 임베딩, 즉 로 설정된다. 각 셀프 어텐션 레이어 에 대하여 two-stream representations는 다음과 같이 공유된 파라미터 세트로 스키마틱(shematically)하게 업데이트된다.
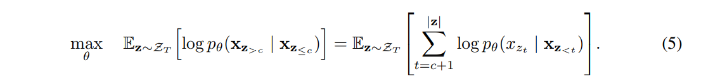
어텐션 연산에서 Q, K, V은 각각 쿼리, 키, 밸류를 나타낸다. content representation의 업데이트 규칙은 표준 셀프 어텐션과 완전히 동일하므로, 파인튜닝 하는 동안에 쿼리스트림을 단순 드롭하고 트랜스포머(-XL)로 content stream을 사용한다. 마지막 레이어의 query representation 을 식 (4) 연산에 사용할 수 있게 된다.
- Partial prediction
순열 언어 모델링 objective가 몇 가지 이점을 갖고 있지만, 순열 때문에 최적화 문제가 훨씬 어려워지고 초기 수렴 속도가 늦어지게 된다. 최적화 어려움을 감소시키기 위해, factorization order에서 마지막 토큰만 예측하게 한다. 공식적으로, 를 non-target subsequence 와 target sequence 로 분리한다. 여기서 c는 cutting point이다. 이 objective는 non-target subsequence에서 조성된 target subsequence 로그 가능도를 최대화하는 것이다.
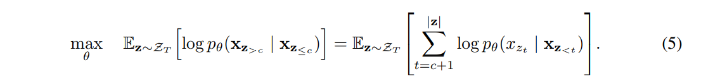
factorization order인 가 주어졌을 때, 시퀀스에서 가장 긴 문맥을 가진 가 target으로 선택된다. 하이퍼파라미터 는 예측을 위해 약 토큰이 선택될 때 사용된다. 즉, . 선택되지 않은 토큰의 query representation은 연산될 필요가 없어, 연산 속도와 메모리를 절약할 수 있다.
본 논문에서 제시한 objective function은 AR 프레임워크에 적합하기 때문에, SOTA AR 언어 모델, Transformer-XL을 사전학습 프레임워크로 통합시키고 방법론을 명명한다. Transformer-XL의 두 가지 중요한 테크닉, relative positional encoding(상대적 포지셔널 인코딩) scheme과 segment recurrence(세그먼트 재귀) mechanism을 통합한다. 앞서 논의한 것과 같이, 원본 시퀀스에 기반한 단순한 relative positional encoding이 적용된다.
다음으로는 재귀 메커니즘을 어떻게 순열 모델링 환경과 통합하고, 모델이 어떻게 이전 세그먼트의 은닉 상태를 재사용할 수 있도록 할 것인지에 대해 논의한다.
일반적으로, 긴 시퀀스 에서 추출한 2개의 세그먼트 와 를 가지고 있다고 가정해보자. 와 는 각각 와 의 순열이 된다. 그러면, 순열 에 기반하여 첫 세그먼트를 처리하고 획득한 content representation 을 각 레이어 에 캐싱한다. 다음 세그먼트 에 대한 메모리의 어텐션 업데이트는 다음과 같다.
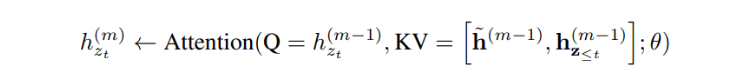
본 식에서 는 시퀀스 차원 간 연결을 나타낸다. 포지셔널 인코딩은 원본 시퀀스의 실제 포지션에만 의존한다. 그러므로, 이러한 어텐션 업데이트는 representation 을 획득하고 나면, 에 독립적이 된다. 이러한 과정은 이전 세그먼트의 factorization order를 몰라도 캐싱과 메모리 재사용이 가능하게 한다. 모델은 이전 세그먼트에 대한 모든 factorization order의 메모리를 활용할 수 있도록 학습한다. 쿼리 스트림도 동일한 방식으로 연산된다. Figure 1의 (c)는 투 스트림 어텐션을 적용한 순열 언어 모델링의 개요이다.
QA의 질의 · 문맥 문단과 같이, 많은 다운스트림 태스크는 다수의 입력 세그먼트를 갖는다. 이번에는 AR 프레임워크에서 다수의 세그먼트를 모델링할 수 있게 XLNet을 학습시키는 방법에 대해 논의한다.
사전학습 단계에서 BERT의 방법론을 따라, 2개의 세그먼트를 임의로 샘플링한다(동일한 문맥이든, 아니든 관계없이). 그리고 두 개의 세그먼트를 하나의 시퀀스 연결로 취급하여 순열 언어 모델링을 수행하려 한다. 여기서 동일한 문맥에 속한 메모리만 재사용한다. 구체적으로, XLNet의 입력은 BERT의 [CLS, A, SEP, B, SEP]과 동일한데, 여기서 SEP, CLS는 special symbol이고, ‘A’와 ‘B’는 두 개의 세그먼트에 해당한다. XLNet이 2개의 세그먼트 데이터 포맷을 따르긴 하지만, NSP가 ablation study에서 성능 향상을 보이지 않기 때문에 XLNet-Large는 NSP objective를 사용하지 않는다.
- relative segment encoding
절대적 세그먼트 인코딩을 각 포지션의 워드 임베딩에 추가하는 BERT와 상이하게, Transformer-XL의 상대적 인코딩에 대한 발상을 확장하여 세그먼트 인코딩을 수행하려 한다.
시퀀스에서 포지션 와 가 주어질 때, 와 가 동일한 세그먼트라면, 세그먼트 인코딩 또는 를 사용하는데, 와 는 각 어텐션 헤드의 학습 가능한 모델 파라미터를 뜻한다. 즉, 두 개의 포지션이 어떤 특정 세그먼트에서 왔는지 판단하는 것이 아닌, 두 개의 포지션이 동일한 세그먼트 내의 포지션인지 판단한다. 이는 상대적 인코딩(relative encoding)의 핵심적인 발상과 일치한다. 즉, 포지션간 관계만 모델링하는 것이다.
가 를 처리할 때, 세그먼트 인코딩 는 어텐션 가중치 를 연산하는 데 사용된다. 여기서 는 표준 어텐션 연산의 쿼리 벡터와 같고, 는 학습 가능한 head-specific 편향 벡터이다. 결국, 값은 노멀한 어텐션 가중치에 더해진다.
이러한 상대적 세그먼트 임베딩을 사용하면 두 가지 이점이 있다. 첫째, 상대적 인코딩의 귀납적 편향(inductive bias)이 일반화(generalization)를 향상시킨다. 둘째, 입력 세그먼트가 2개를 넘어 절대적 세그먼트 임베딩을 사용할 수 없는 태스크에 대한 파인튜닝 가능성을 열어 준다.
식 (2)와 식 (5)를 비교하여, BERT와 XLNet 모두 부분적 예측(partial prediction)을 수행한다는 것을 관측한다. 즉, 시퀀스에서 토큰의 subset만 예측한다. 이는 BERT에서 필수 선택인데, 모든 토큰이 마스킹되면 의미있는 예측이 불가하기 때문이다. 덧붙여, BERT와 XLNet에서 부분적인 예측은 모두 충분한 문맥의 토큰만 예측하여 최적화의 어려움을 줄여주는 역할을 한다. 그러나 이전에 논의했던 독립성 가정(independence assumption) 때문에 BERT는 타겟 간 의존성을 모델링하지 못한다.
이러한 차이를 더 잘 이해하기 위해, 예시 [New, York, is, a, city]를 살펴본다. BERT와 XLNet은 2개의 토큰 [New, York]를 예측 타겟으로 선택하고 (New York | is a city)를 최대화한다고 가정한다. 또한, XLNet은 factorization order [is, a, city, New, York]를 샘플링한다고 가정한다. 이러한 경우, BERT와 XLNet은 각각 다음의 objectives로 나타낼 수 있다 :
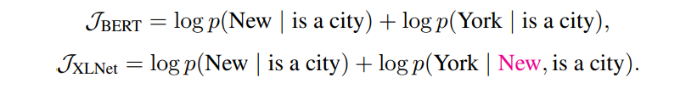
상단의 식을 보면, XLNet은 (New, York)간 의존성을 포착할 수 있는데, BERT는 그렇지 못하다는 것을 알 수 있다. 이러한 예시에서 BERT는 (New, city)나 (York, city)같은 일부 의존성은 학습할 수 있지만, XLNet이 동일한 target 내에서 더 많은 의존성 쌍을 학습하고 더 “dense”한 효율적 학습 신호를 포함한다.
3. Experiments
XLNet은 BERT를 따라 BookCorpus + Wikipedia를 사전학습 데이터로 사용하고, 이에 덧붙여 Giga 5, ClubWeb 2012-B, CommonCrawl을 사전학습에 사용한다. 휴리스틱을 사용하여 ClueWeb 2012-B와 Common Crawl에서 짧거나 질낮은 가사를 가려내고, SentencePiece로 토큰화(tokenization)를 거친 후, 종합 32.89B의 subword piece를 취한다.
XLNet-Large는 BERT-Large와 동일한 하이퍼파라미터 구조를 취하며, 비슷한 모델 크기이다. 사전학습에서는 항상 최대 시퀀스 길이를 512로 사용한다. BERT와 정당한 비교를 위해, BookCorpus와 Wikipedia에서만 XLNet-Large-wikibooks를 학습시키고, 원래 BERT에서 사용했던 모든 사전학습 하이퍼파라미터를 재사용한다. 그리고, 500K 스텝동안 Adam 가중치 감소 옵티마이저(weight decay optimizer)를 사용하여 512 TPU v3 chips로 학습하며, 배치 사이즈는 8192를 사용한다. 학습 과정은 5.5일이 소요되었는데, 종료 시에 여전히 underfit된 상태였음이 관측된다. 결국, XLNet-Base-wikibooks를 기반으로 ablation study를 수행한다.
재귀 메커니즘을 도입하여, 각 전방(forward)과 후방(backward)이 배치 사이즈의 반을 취하는 양방향 데이터 입력 파이프라인을 사용한다. XLNet-Large 학습에는 부분적 예측(partial prediction) 상수 를 6으로 설정한다. 파인튜닝 절차는 명시된 것을 제외하면 모두 BERT를 따른다. 먼저 길이 를 샘플링 할 때는 스팬 기반(span-based) 예측을 적용하고, (K L) 토큰 문맥 내에서 연이은 L의 스팬 토큰을 예측 target으로 선택한다.
다음 실험에서는 다양한 자연어 이해 데이터셋을 사용하여 본 논문의 방법론의 성능을 평가한다.
4. Conlusions
XLNet은 AR과 AE의 장점을 결합한 순열 언어 모델링 objective를 사용하는 일반화된 AR 사전학습 방법론이다. XLNet의 신경망 구조는 Transformer-XL과 two-stream attention 메커니즘의 설계를 결합하여, AR objective와 균일하게 작용하도록 개발된다. XLNet은 많은 태스크에서 이전 사전학습 objective보다 상당히 큰 발전을 이룬다.
Appendix

안녕하세요
공부 중 올려주신 블로그의 도움을 많이 받았습니다! 감사합니다.
와중에 모델에 대해서 공부하던 도중 혼자서 이해하기 힘든 부분이 생겨
이렇게 댓글을 남깁니다!!
transformer xl, xlnet에서 사용하는 함수 tf.einsum (‘ibnd,jbnd->ijbn’, (head_q, head_k) 는 모든 단어와의 상관관계를 계산하지 않는 것 같습니다. 예를 들어, [[i,am],[a,boy]] 라는 문장끼리의 상관성을 계산한다고 했을 때
i 는 i,a
am 은 am,boy
A 는 i, a
Boy 는 am,boy 와의 상관성만을 계산합니다.
혹시 이부분에 대해서 알고 계신 부분이 있을까요??
모델에 데이터를 인풋할 때 위의 i,am,a,boy 처럼 배치가 없이 2차원의 형태로 데이터가 들어가는 것으로 알고있습니다!!