
Intro: Physical AI의 패러다임 전환과 VLA의 부상
로봇 제어 기술의 역사는 좁은 범위의 특정 작업을 수행하기 위해 고안된 하드코딩 기반 제어기에서 시작하여, 2020년대 중반에 이르러 Physical AI의 구현을 목표로 하는 파운데이션 모델, Vision-Language-Action(VLA) 시대로 급격한 패러다임 전환을 맞이했다.
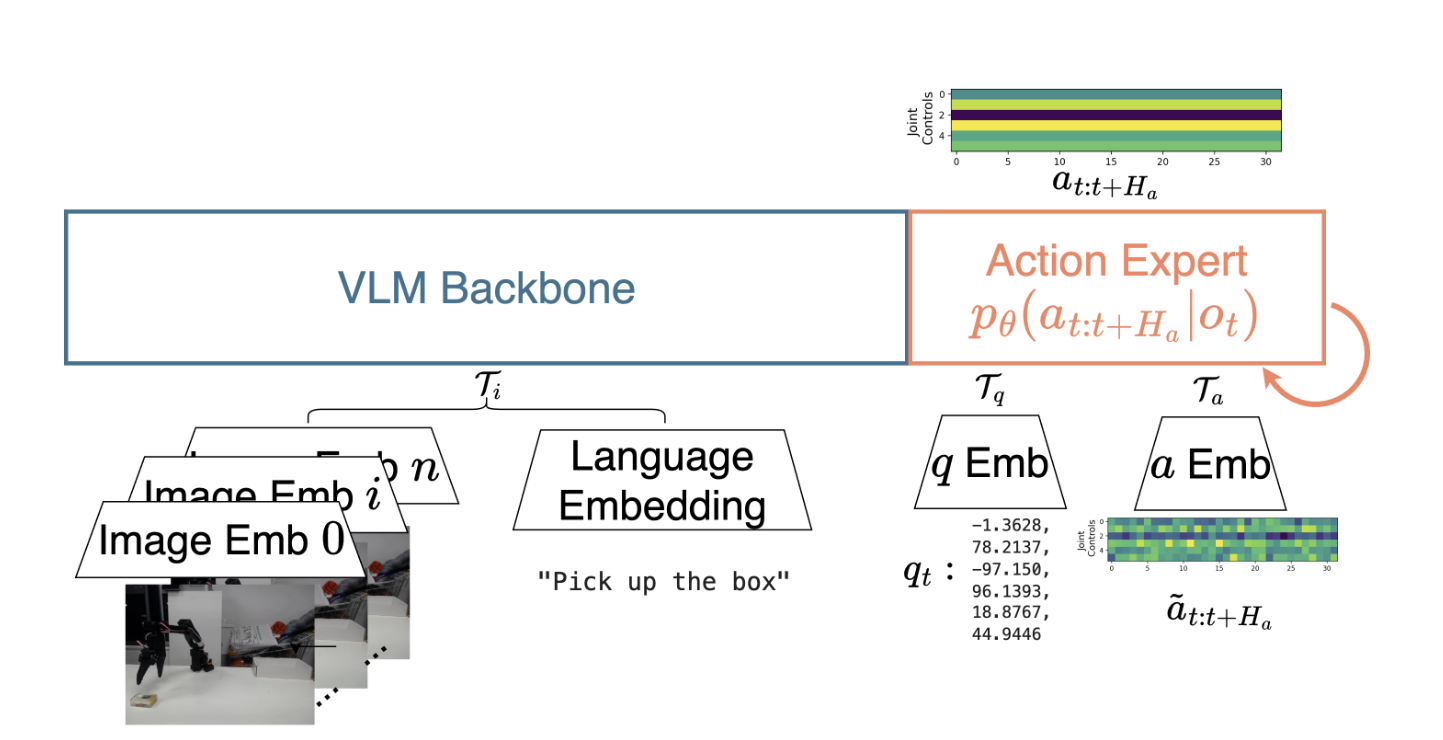
VLA 모델은 시각적 입력과 고차원 센서 모터 상태(Proprioceptive state)를 자연어 명령과 함께 융합하여 로봇의 관절 및 말단 장치(End-effector)를 직접 제어하는 저수준의 모터 명령(Low-level motor command)을 출력하는 구조를 갖는다.
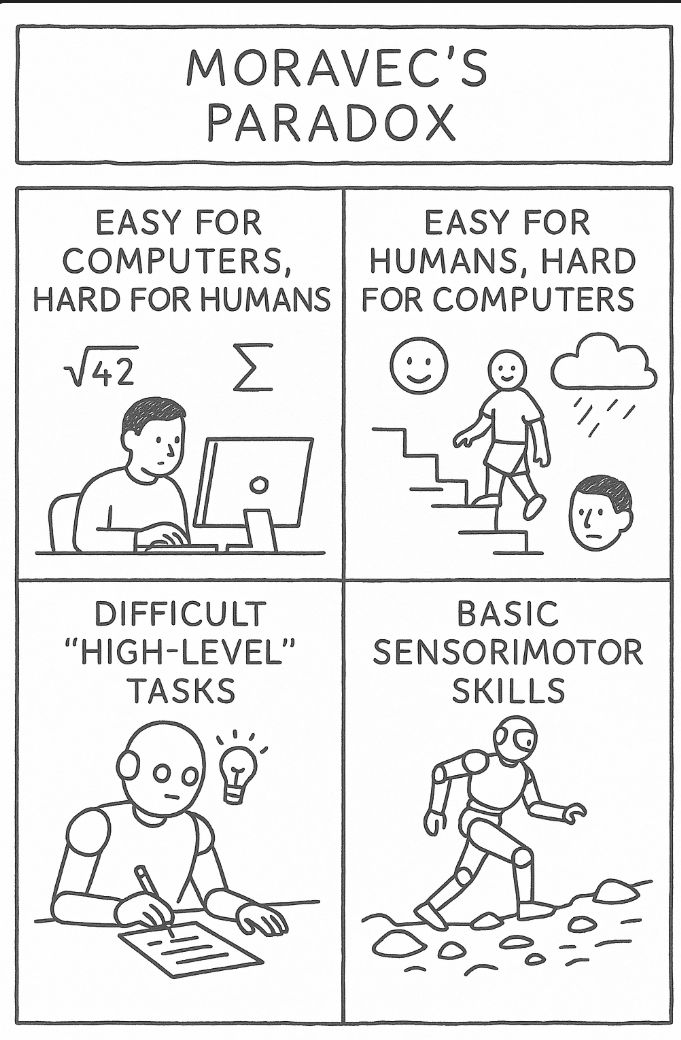
전통적인 로봇 공학이 직면했던 '모라벡의 역설(Moravec's paradox)'을 극복하기 위해 제안된 이 아키텍처는, LLM이 텍스트 공간에서 보여주었던 경이로운 일반화 능력을 물리적 세계로 확장하려는 시도에서 출발했다.
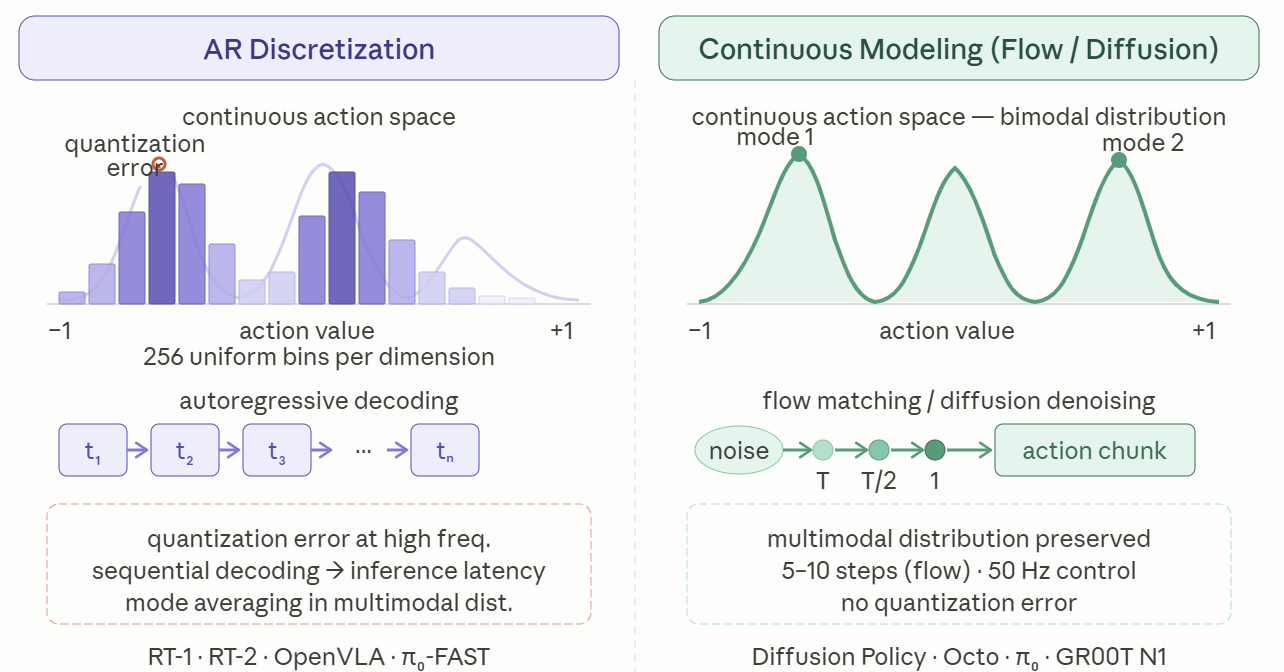
2026년 현재, VLA 모델의 아키텍처 환경은 초기 Autoregressive(자기회귀) 기반의 Discretization(이산화) 모델에서 벗어나, Continuous Generative Action Modeling(연속적 행동 모델링) 기법인 Flow Matching으로 그 중심축이 이동했다.
더 나아가 주요 빅테크 및 로보틱스 선도 기업들은 모델의 인지 구조를 설계함에 있어, Daniel Kahneman의 인지 이론(Thinking, Fast and Slow, 2011)에 기반한 이중 시스템(System 1 / System 2) 토폴로지를 채택하거나, 이를 정면으로 반박하며 인지와 행동을 단일 스트림으로 융합하는 조화 추론(Harmonic Reasoning) 아키텍처를 독자적으로 구축하는 등 철학적·방법론적 분기점을 형성하고 있다.
VLA 발전 궤적 따라가기
본 글에서 추적하는 VLA의 발전 궤적은 다음 네 단계로 요약된다.
- Discrete action token + Autoregressive — RT-1, RT-2, RT-X, OpenVLA 등 이산화 기반 모델군 (2022–2023)
- Diffusion / Flow matching action head — Diffusion Policy, Octo, RDT-1B, π₀, CogACT 등 (2024)
- System 1 / System 2 분리, FAST 토크나이저, Knowledge Insulation — GR00T N1, Helix, π₀.₅, Gemini Robotics, OpenVLA-OFT 등 (2025 상반기)
- RL 기반 자기개선, Embodied Reasoning, On-device, World-model 결합 — π*₀.₆, Gemini Robotics 1.5/-ER 1.6, Helix 02, GR00T N1.7 등 (2025 하반기–2026)
본문에서는 이 기술의 출발점인 RT 시리즈와 OpenVLA의 출현을 먼저 고찰하고, 이후 2024–2026년의 최신 VLA 모델 시리즈·버전별 구조적 차이점, 설계 철학, 장단점을 순차적으로 분석한다.
1. VLA의 태동과 이산화(Discretization)의 한계: RT 시리즈와 OpenVLA
범용 로봇 정책(Generalist Robot Policy)의 초기 형태는 거대 언어 모델(LLM)과 비전-언어 모델(VLM)의 트랜스포머 아키텍처를 로봇 제어에 이식하는 시도에서 비롯됐다. 이는 연속적인 물리적 공간을 언어와 유사한 이산적인 토큰으로 변환하는 접근법을 취했다.
1.1 RT-1 및 RT-X: 로봇 제어의 언어 모델화
-
아키텍처
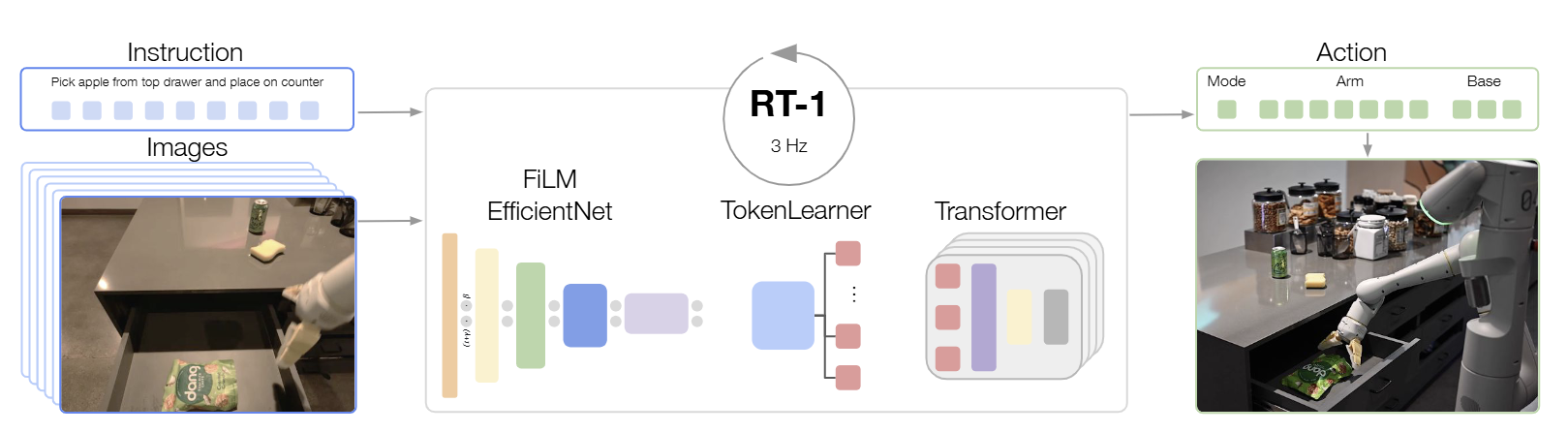
Google DeepMind가 발표한 Robotics Transformer 1 (RT-1)은 자기회귀 기반 VLA의 실현 가능성을 입증한 기념비적인 아키텍처다. RT-1은 35M개 파라미터로 구성된 효율적인 트랜스포머 아키텍처를 채택하고, 15프레임의 이미지 히스토리와 자연어 명령을 입력으로 한다.각 이미지는 ImageNet으로 사전 학습된 EfficientNet-B3 모델을 통과하여 81개의 visual token으로 평탄화(Flattening)되며, 자연어 지시문은 Universal Sentence Encoder(USE)를 통해 임베딩된다.
텍스트 임베딩은 FiLM 레이어를 통해 이미지 특징을 조건화(텍스트 지시에 따라 이미지 특징 해석 방식을 동적으로 조정)하고, 추론 속도를 높이기 위해 어텐션 기반 토큰 압축 모듈인 TokenLearner를 도입하여 visual token 수를 동적으로 축소함으로써 2.4배의 추론 가속을 달성했다.
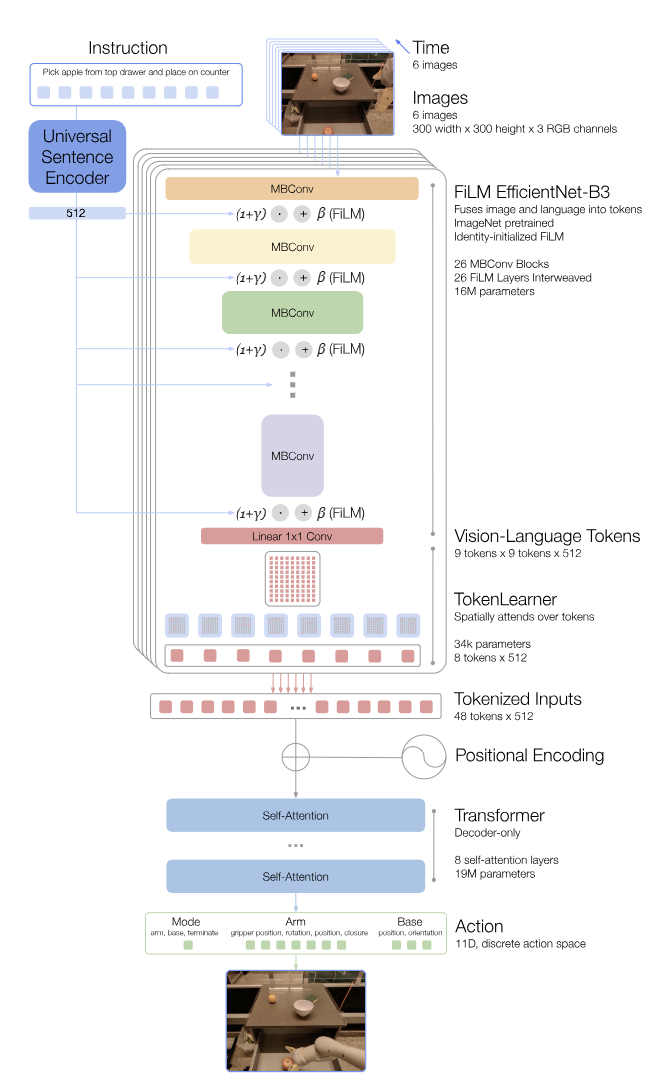
-
Action Tokenization
RT-1의 핵심 설계 철학은 '행동의 토큰화'에 있다.로봇의 연속적인 모터 명령(팔의 움직임 7자유도, 베이스 움직임 3자유도, 모드 전환 스위치 등)은 각 차원별로 256개의 동일한 크기를 가진 이산적인 구간(Bin)으로 균등 분할된다.
예를 들어 −1.0에서 1.0 사이의 연속적인 동작 값이 주어졌을 때, 이를 255개의 구간으로 나누어 약 0.00784 너비의 토큰으로 변환하는 식이다. 모델은 Causal masking이 적용된 decoder를 통해 Categorical cross-entropy objective function을 사용하여 이 action token을 예측한다.
-
RT-X 및 Cross-Embodiment
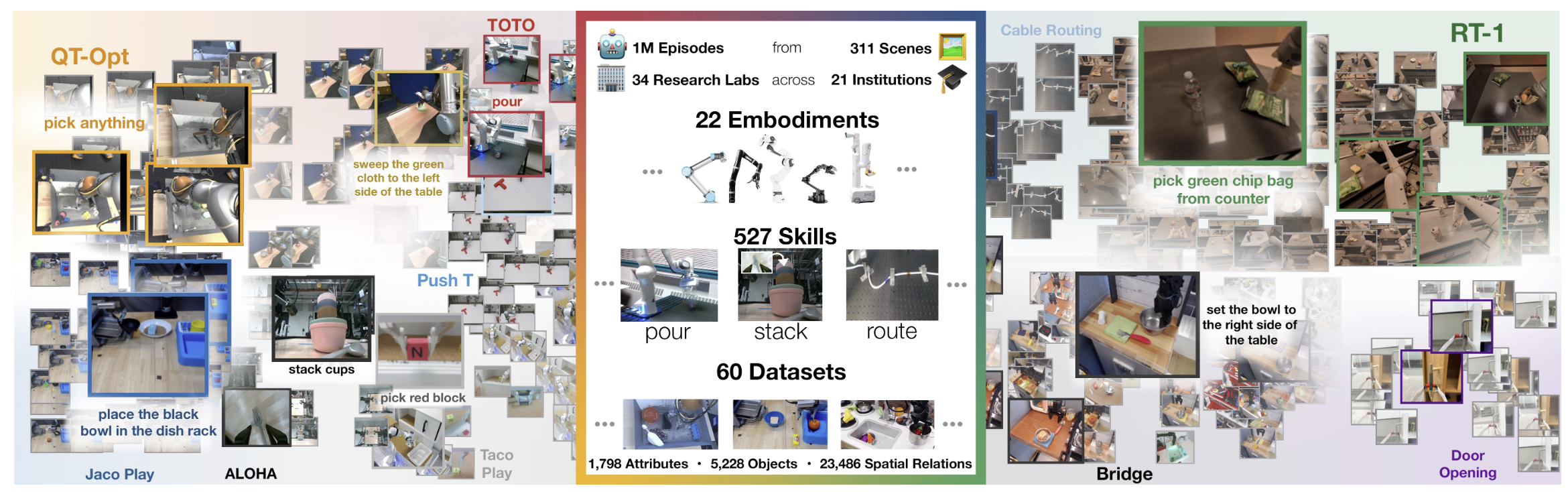
이러한 패러다임은 RT-X 및 RT-2로 이어지며 교차 신체성(Cross-Embodiment) 획득에 크게 기여했다. 전 세계 33개 연구실과 협력하여 22종의 서로 다른 로봇으로부터 52만 7천 개의 궤적을 수집한 Open X-Embodiment(OXE) 데이터셋을 바탕으로 훈련된 RT-1-X는 단일 모델이 여러 로봇 형태를 제어할 수 있음을 입증했으며, 개별 로봇 전용 정책보다 평균 50% 향상된 성공률을 보였다.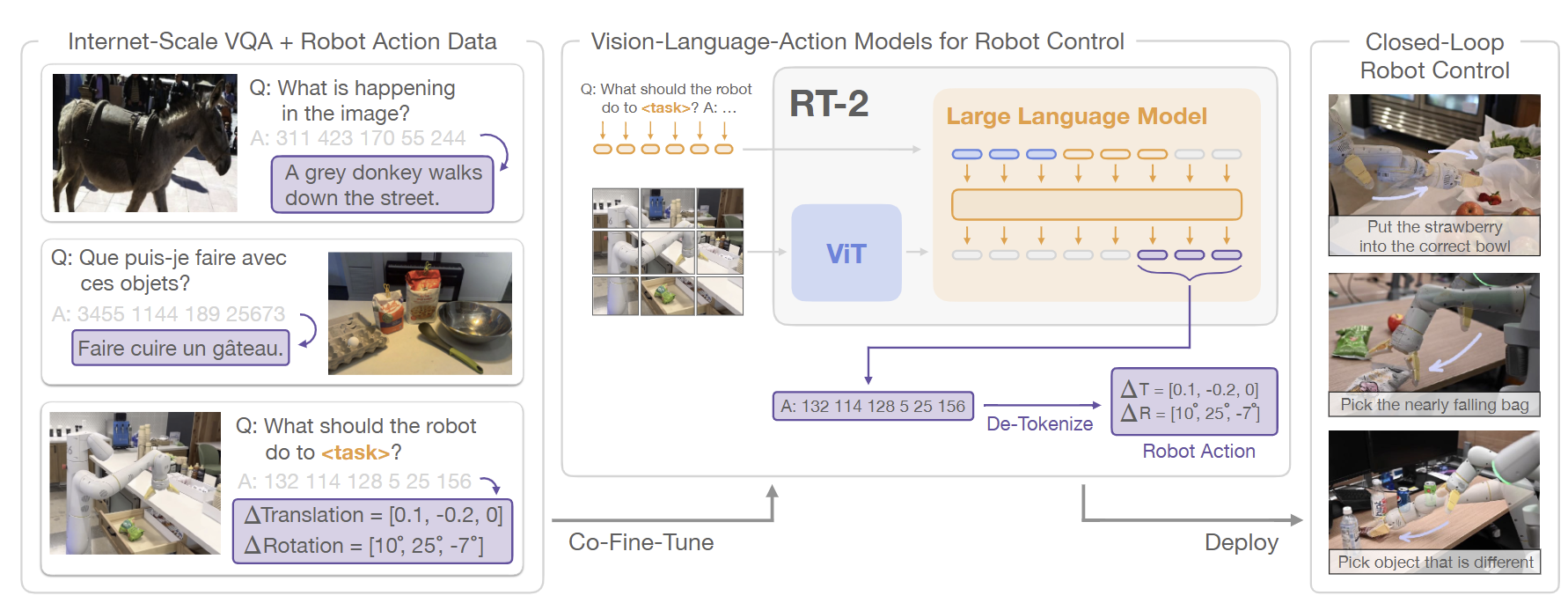
RT-2는 VLM(ViT 및 UL2 백본)을 로봇 데이터에 미세조정하여 토큰화된 로봇 행동을 일반 텍스트 토큰과 동일한 공간에서 출력하도록 규모를 확장했다.
PaLI-X-55B 기반의 RT-2는 추상 개념을 처리하는 Emergent Reasoning에서 RT-1 대비 3배 수준의 일반화 성능 향상을 달성했다.
-
RT 시리즈가 갖는 계보적 의미
RT-1은 엄밀히 말해 VLA가 아니다. Internet-scale VLM을 사용하지 않고 ImageNet-pretrained vision encoder + USE embedding만 사용한다는 점에서 RT-2와 본질적으로 갈라지는 지점이다.그러나 (1) 7-DoF action을 256 bin으로 이산화하고, (2) 이를 시퀀스 모델링으로 푸는 방법은 이후 모든 VLA의 초석이 됐다는 점에서 역사적 의의가 크다. 추론 속도가 3Hz에 불과하다는 점도 실시간성과 모델 용량 사이의 트레이드오프를 처음으로 명시적으로 다룬 사례로 기억된다.
1.2 RT-H: Action Hierarchies를 통한 이중 구조
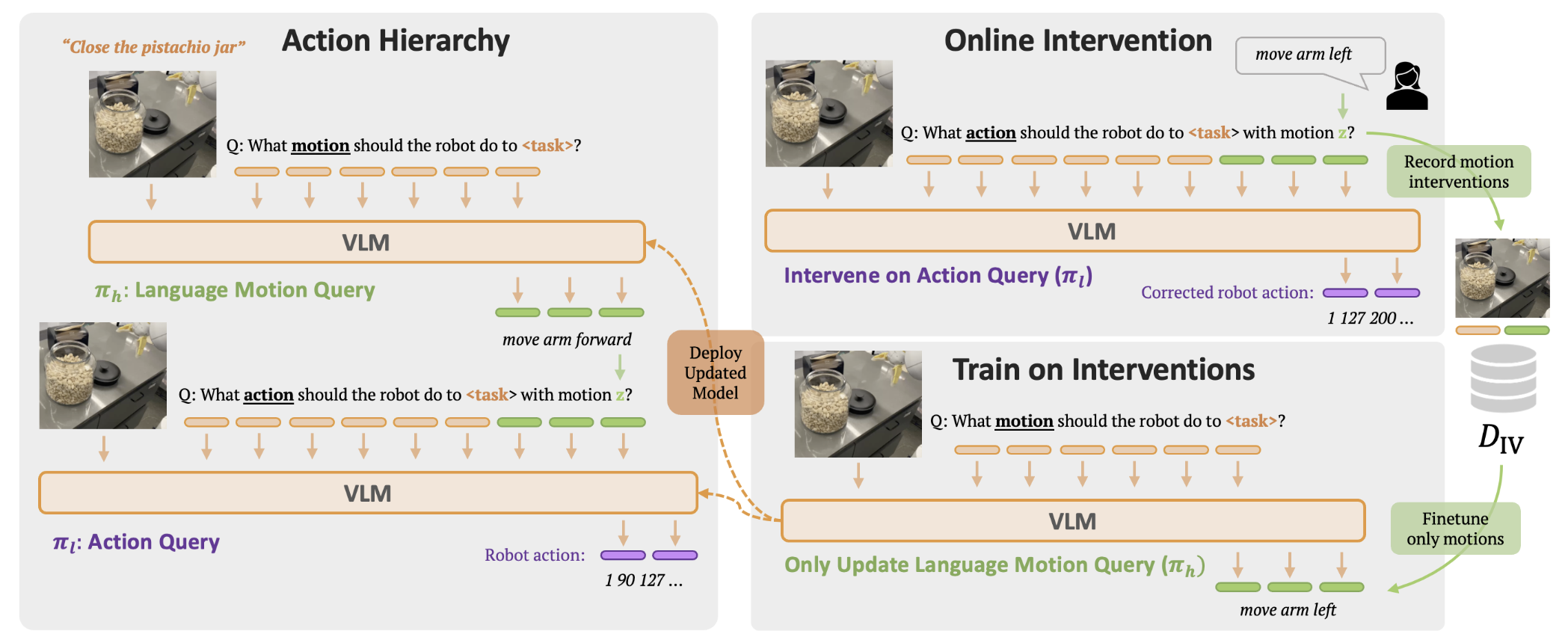
2024년 발표된 RT-H(Action Hierarchies via Language)는 단순 이산화 토큰화에서 한 발 더 나아가, high-level task→ language motion→ low-level action이라는 위계 구조를 도입했다.
PaLI-X 기반 단일 모델로 두 단계를 모두 출력(RT-H-Joint)하며, Diverse+Kitchen 데이터에서 RT-2 대비 +15% 평균 성공률, action MSE 약 20% 개선을 달성했다.
계보적 의미에서 RT-H는 Dual-system 사고의 초기 형태로, 이후 2025년의 Helix, Gemini Robotics 1.5의 internal reasoning, Hi Robot으로 직접 연결되는 발판이 됐다. 또한 사람의 language-level intervention으로 정책을 즉석 교정할 수 있다는 점은 Human-Robot Interaction 관점에서도 중요한 기여다.
1.3 OpenVLA: 오픈소스 VLA의 표준화
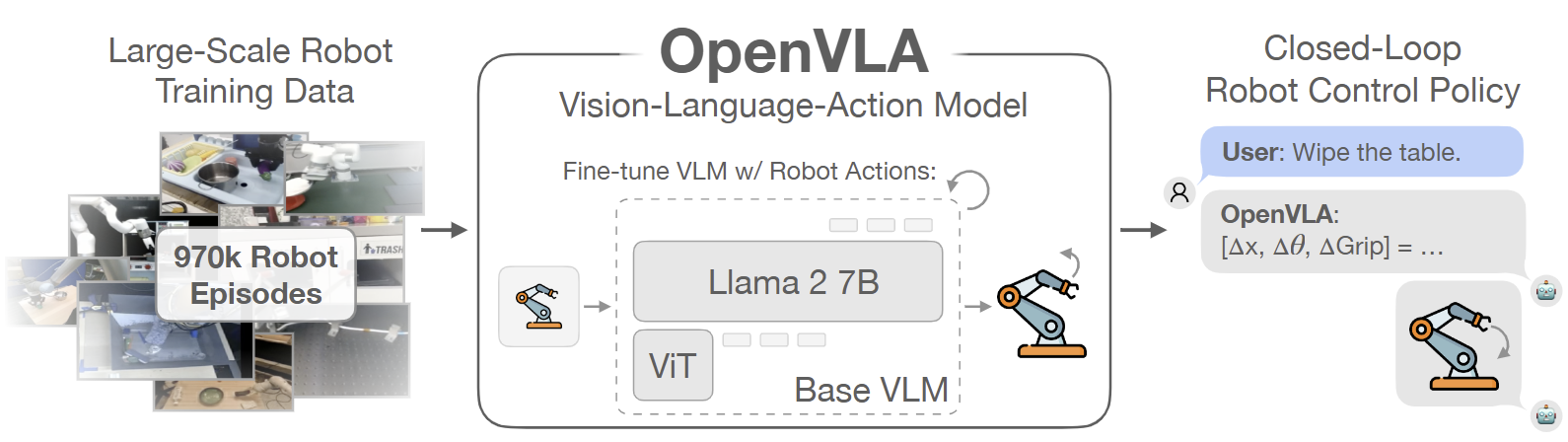
-
아키텍처 및 특징
RT-2의 성공 이후 완전한 오픈소스 및 상업적 이용이 가능한 VLA에 대한 수요는 2024년 OpenVLA의 출시로 충족됐다. 70억 파라미터(7B)를 갖춘 OpenVLA는 Llama-2 7B language backbone과 SigLIP visual encoder를 결합하여 단일 A100 GPU에서도 추론이 가능하도록 설계됐다.RT-X 데이터셋 전체를 활용하여 사전 학습된 OpenVLA는 이산화된 행동 토큰을 예측하는 RT 시리즈의 방법론을 계승하여 강력한 Zero-shot 능력을 발휘했다.
-
한계와 개선: OpenVLA-OFT
그러나 OpenVLA는 완전히 새로운 환경이나 복잡한 언어적 변형이 주어졌을 때 일반화 성능이 급격히 저하되는 취약점을 보였다. 이를 해결하기 위해 OpenVLA-OFT(2025)에서는 다음 두 가지 핵심 개선이 이루어졌다.-
합성 지시어 증강(Synthetic Instruction Augmentation): LLM을 활용하여 기존 로봇 궤적에 대해 의미론적으로 동일하지만 구조적으로 다양한 지시어를 대량 합성
-
최적화된 미세조정(OFT): LoRA 기반 효율적 미세조정을 통해 Parallel decoding + L1 손실 함수 조합으로 추론 속도와 정밀도를 동시에 개선
이러한 개선은 인간의 복잡한 의도와 로봇의 저수준 제어 사이의 간극을 메우는 데 성공적으로 기여했으며, 이후 MiniVLA, SmolVLA, TinyVLA와 같은 경량화 파생 모델의 기반이 됐다.
-
1.4 Autoregressive tokenization의 구조적 한계
RT 시리즈와 OpenVLA가 채택한 이산화 및 자기회귀 기반 아키텍처는 로봇 제어를 언어 모델링의 영역으로 편입시켰다는 데 큰 의의가 있으나, 본질적인 수학적 한계를 지녔다. 이를 두 가지 핵심 문제로 요약할 수 있다.
-
양자화 오차(Quantization Error): 256개의 구간으로 물리적 행동을 균등 분할하는 Binning 방식은 저주파수(1–10 Hz)의 대략적 제어에는 적합하나, 고주파수(50 Hz 이상)의 복잡하고 세밀한 조작(Dexterous Manipulation)을 수행하기에는 양자화 오차가 지나치게 컸다.
-
추론 지연(Inference Latency): 트랜스포머의 자기회귀적 디코딩 특성상 토큰을 순차적으로 예측해야 하므로, 실시간 피드백 루프가 필수적인 로봇 제어 환경에서 치명적인 추론 지연을 유발했다.
이 두 가지 병목 현상은 VLA 아키텍처가 연속적인 행동 공간을 직접 모델링하는 생성형 방법론, 즉 Diffusion Policy와 Flow Matching으로 진화하는 강력한 동인이 됐다. 이 전환이 바로 다음 세대 모델들의 핵심 혁신이다.
2. 생성형 행동 모델링으로의 전환: Diffusion, Flow Matching
앞 장에서 살펴본 이산화(Discretization) 기반 자기회귀 VLA의 두 가지 구조적 한계는 VLA Action head의 근본적인 재설계를 요구했다. 그 해답은 이미지 합성 분야에서 큰 성공을 거둔 Diffusion Model과, 이를 발전시킨 Flow Matching에 있었다. 이 두 패러다임의 전환을 이해하는 것은 현재 주류 VLA 아키텍처의 설계 철학을 파악하는 데 있어 필수적이다.
2.1 Diffusion Policy의 등장과 핵심 통찰
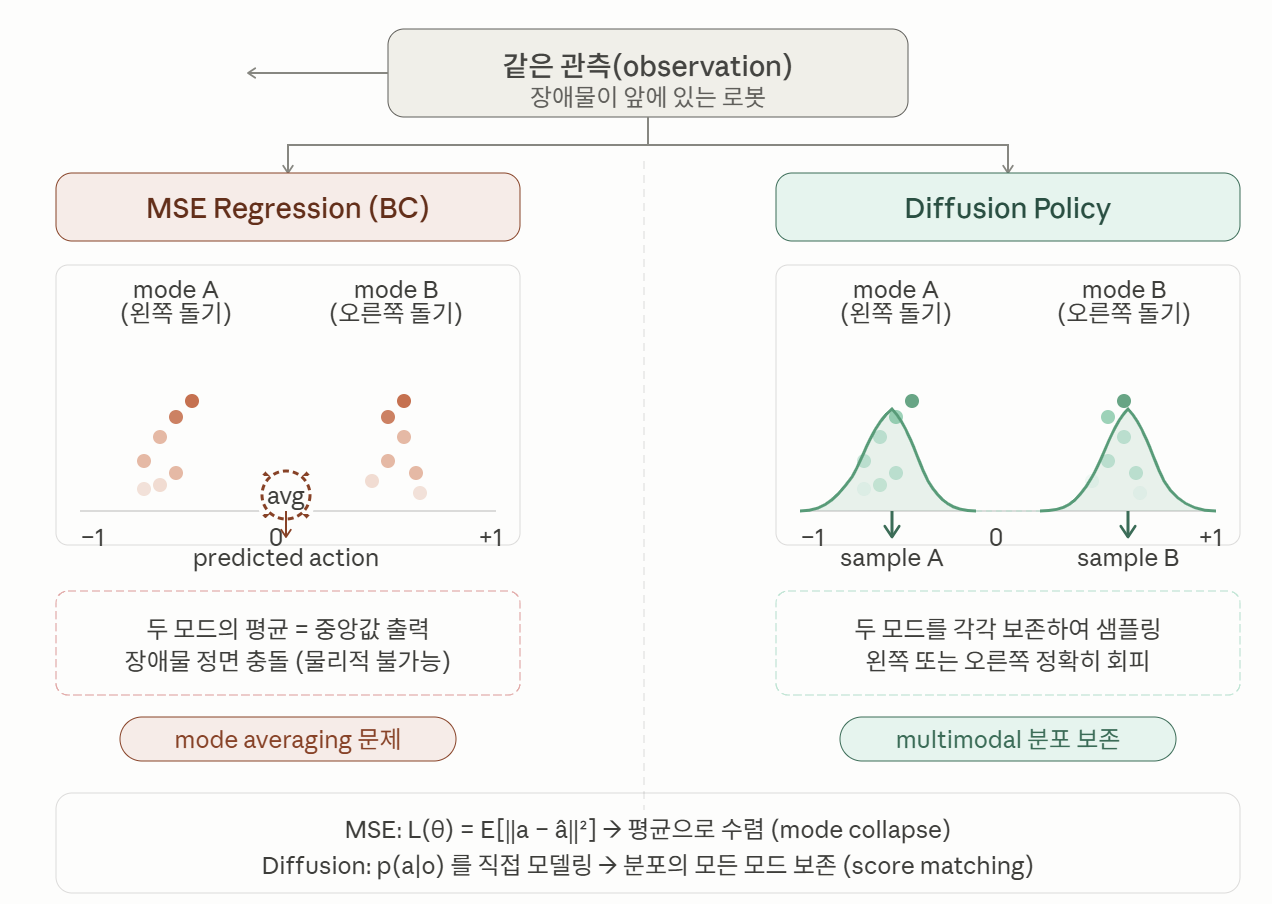
- 배경: Behavior Cloning(BC)의 구조적 약점
기존 Behavior Cloning(BC)의 고전적 약점은 Multimodal action distribution 문제에 있다. 동일한 시각적 관측에 대해 합리적인 행동이 여러 개 존재할 때, MSE Regression은 모든 가능한 행동의 평균을 학습하는 반면, 확산 모델은 이 다중 모드를 그대로 보존하여 각각의 합리적인 행동을 생성할 수 있다. Diffusion Policy(2023)는 이 문제를 정면으로 돌파하여, 12개 태스크에서 기존 명시적·암시적 정책 대비 평균 46.9% 향상을 달성했다.
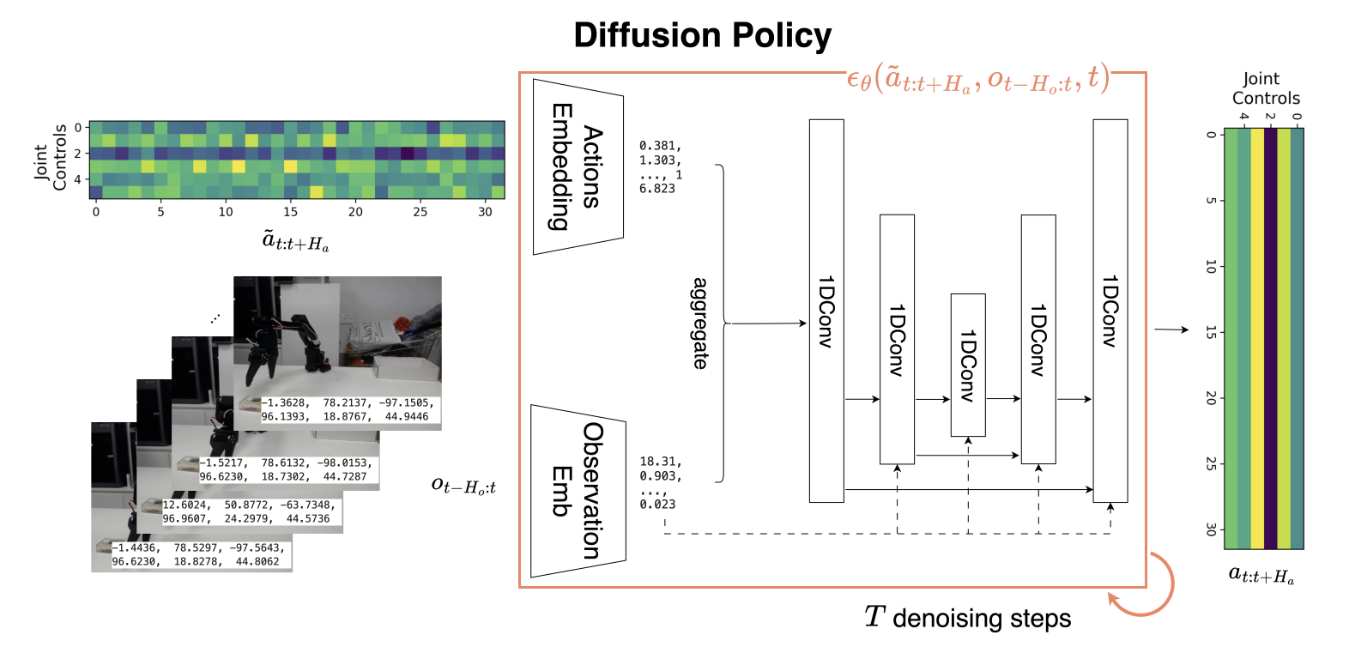
- 아키텍처: DDPM(Denoising Diffusion Probabilistic Model) 기반 행동 생성
Diffusion Policy의 아키텍처는 ResNet 기반 시각 인코더를 통해 관측치를 압축하고, 조건부 DDPM이 1D 합성곱 U-Net 또는 트랜스포머를 통해 노이즈 상태의 행동 벡터를 단계적으로 제거(Denoising)하여 실제 Action chunk를 생성하는 방식이다.
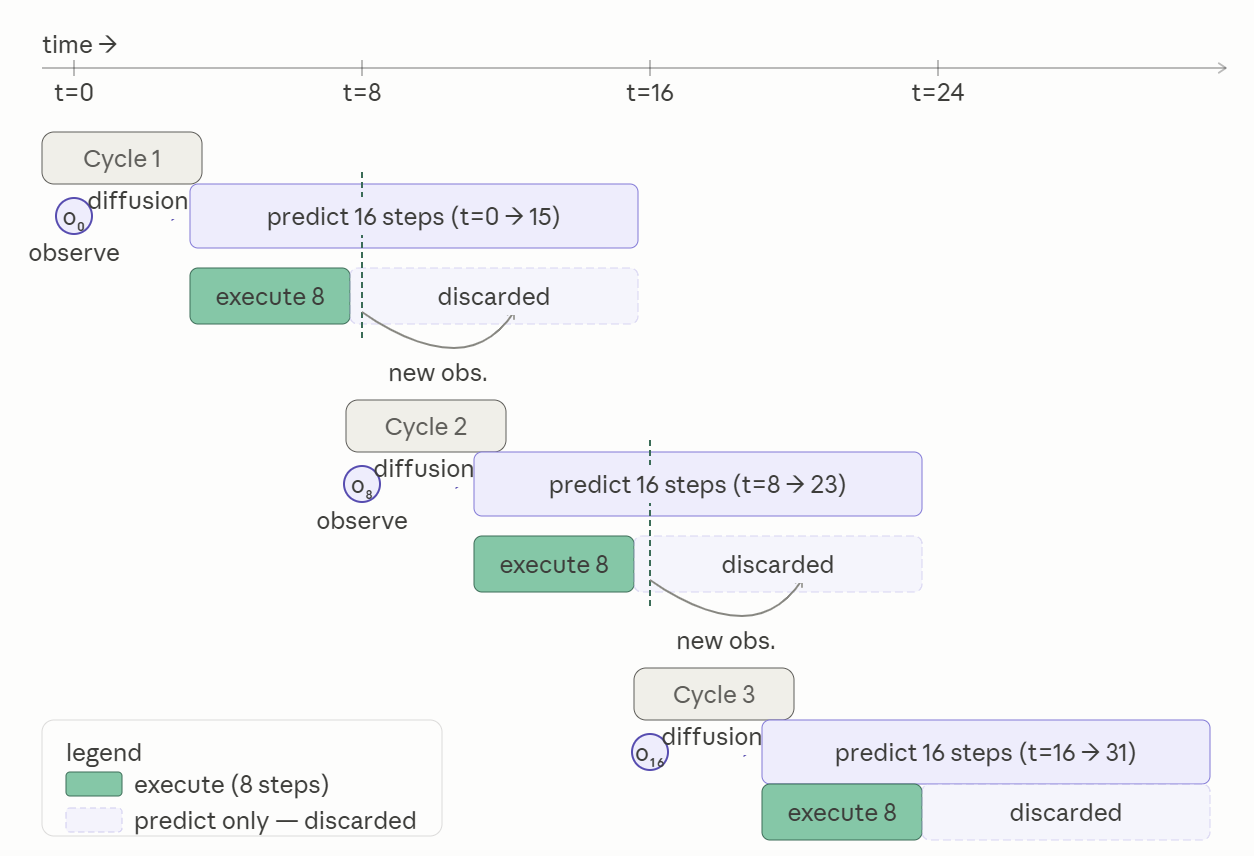
핵심 설계 선택으로는 예측 16스텝, 실행 8스텝으로 구성된 '점진적 수평선 제어(Receding-horizon control)'와 End-effector position 제어 방식이 채택됐다.
계보적 측면에서 Diffusion Policy의 통찰은 이후 Octo, RDT-1B, π₀, CogACT, GR00T N1의 Action expert가 모두 직계 후손으로 발전했다는 점에서 그 의의가 크다. 다만 전통적으로 100단계의 디노이징 스텝이 필요하다는 점은 실시간성에 부담이 됐으며, 이후 Consistency model과 플로우 매칭 등 후속 가속 연구로 이어지게 되었다.
2.2 Octo: Diffusion Policy의 파운데이션 모델화
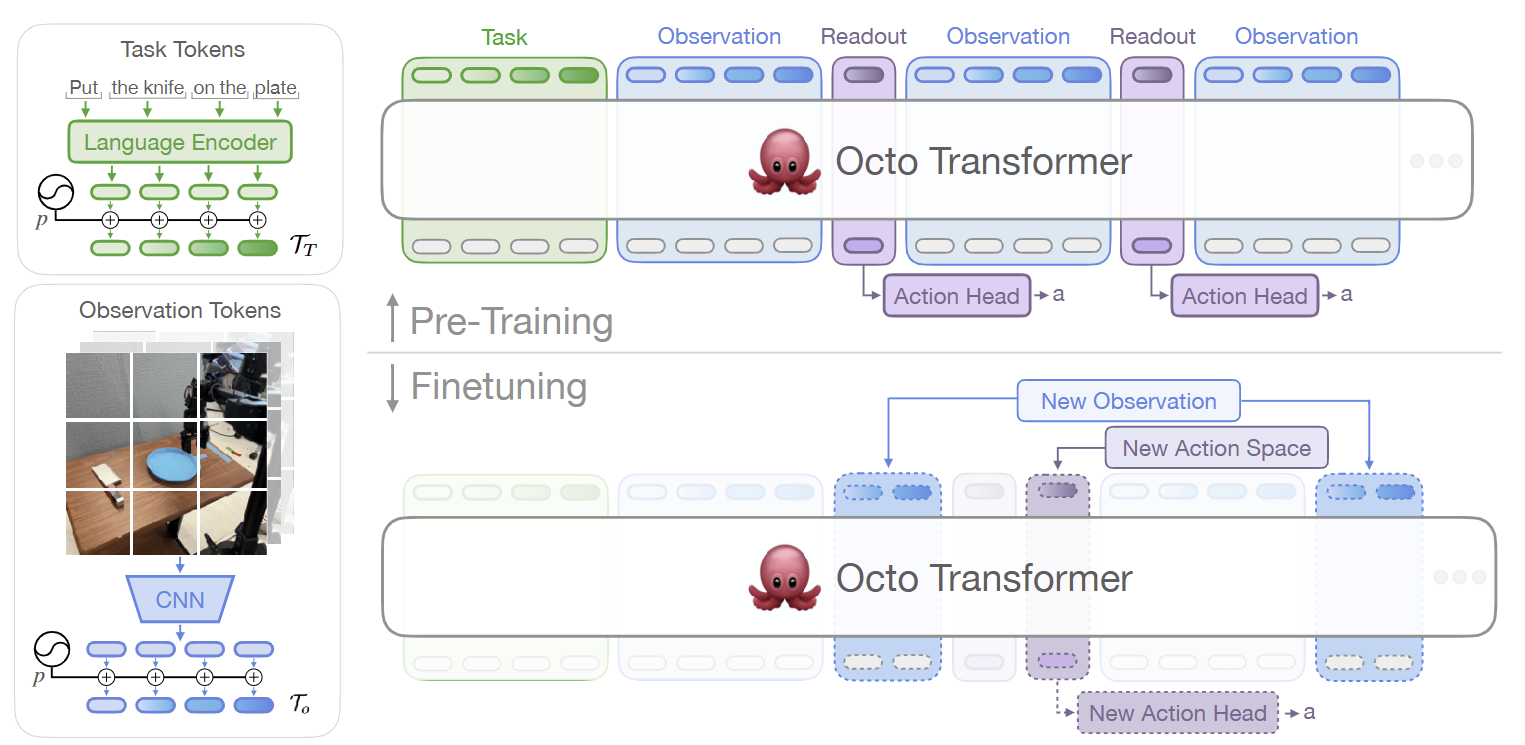
-
아키텍처
Octo는 Diffusion Policy를 로봇 파운데이션 모델에 적용한 대표적인 오픈소스 아키텍처다. Open X-Embodiment 데이터셋의 80만 개 궤적으로 학습한 Octo는 2,700만 매개변수의 Octo-Small과 9,300만 매개변수의 Octo-Base 두 버전으로 제공된다.Octo의 핵심 설계는 트랜스포머 백본과 경량 확산 행동 헤드(약 3M 매개변수, ~5단계 디노이징)의 조합이다. 시각적 관측치와 자연어 명령은 모달리티별 토크나이저(Modality-specific tokenizers)를 통해 공통 토큰 형식으로 변환되어 트랜스포머 백본을 통과한다.
BERT의 [CLS] 토큰과 유사한 '판독 토큰(Readout token)'을 통해 과거 관측 시퀀스의 압축된 벡터 임베딩을 생성하고, 이를 확산 행동 헤드의 조건부 입력으로 제공한다. Block-wise causal attention 덕분에 새로운 관측 입력이나 행동 출력 헤드 추가 시 백본을 고정한 채 가벼운 매개변수만 튜닝할 수 있다.
-
한계: action head 용량의 병목
Octo의 핵심 한계는 경량 diffusion head의 용량 제약이다. 이후 RDT-1B와 CogACT가 '경량 헤드로는 부족하다'며 헤드 자체를 키우는 방향으로 분기한 것은 바로 이 지점에서 출발한다. 또한 이산화 기반 RT-2-X 대비 Long-horizon dexterous task에서 성능이 부족하다는 점이 π₀ 비교 평가에서 명확히 드러났다. 오픈소스 라이선스, 코드 품질, 미세조정 용이성 측면에서는 사실상 표준이 되었다.
2.3 플로우 매칭(Flow Matching)의 수학적 우수성
-
Diffusion Policy vs Flow Matching : SDE vs ODE
2025년 하반기부터 2026년에 이르러 최첨단 VLA 구현의 표준은 확산 정책에서 플로우 매칭으로 급격히 재편됐다. 두 방법론 모두 연속적인 시간을 다루지만, 그 수학적 기반에서 결정적 차이가 있다.Diffusion 모델은 확률 미분 방정식(Stochastic Differential Equation, SDE)을 통해 노이즈를 점진적으로 제거하는 방향성을 추구한다. 반면 Flow Matching은 상미분 방정식(Ordinary Differential Equation, ODE)을 기반으로 시간의 흐름에 따른 벡터장(Vector field)을 직접 학습하여, 단순한 기저 분포를 복잡한 대상 데이터 분포로 매핑한다.
수학적으로 플로우 매칭은 Conditional Flow Matching 손실 함수가 Diffusion의 noise prediction과 등가이지만, 노이즈와 최종 행동 궤적 사이의 직진성이 강한 Velocity field를 학습하므로 샘플링 경로가 훨씬 단순화된다.
-
실용적 우위: 추론 속도와 실시간 제어
확산 모델이 20~50단계에 걸쳐 달성했던 추론 품질을 단 5~10단계의 추론만으로 달성할 수 있어 지연 시간(Latency)이 획기적으로 줄었다. 또한 에너지 기반 모델에서 필수적이었던 Negative sample extraction의 복잡성이 제거되어 훈련 속도가 가속화됐다.이러한 속도와 예측 가능성의 결합은 로봇 제어에서 필수적인 실시간 폐루프 제어를 가능케 했으며, 이후 π₀, GR00T N1, SmolVLA, Helix S1, Gemini Robotics On-Device에서 모두 Flow Matching 헤드를 채택하는 계기가 됐다.
| 특성 | Diffusion Policy | Flow Matching |
|---|---|---|
| 수학적 기반 | 확률 미분 방정식 (SDE) 기반 노이즈 예측 | 상미분 방정식 (ODE) 기반 벡터장(속도) 예측 |
| 샘플링 경로 | 비선형적이며 예측 불가능한 경로 | 노이즈와 최종 이미지/행동을 잇는 직관적이고 직선에 가까운 경로 |
| 필요 추론 단계 | 20 ~ 50 단계 (실시간 적용에 불리함) | 5 ~ 10 단계 (실시간 및 엣지 컴퓨팅에 최적화) |
| 훈련 및 안정성 | 훈련이 상대적으로 안정적이고 레시피가 성숙함 | 훈련 과정이 민감할 수 있으나, 훈련 후 추론은 매우 결정적이고 견고함 |
3. 오픈소스 VLA의 진화
플로우 매칭의 도입은 무거운 VLA 모델을 경량화하여 소비자용 하드웨어에서도 훈련 및 배포가 가능하도록 만드는 오픈소스 생태계의 폭발적인 성장을 이끌었다. 본 장에서는 몇가지 주요 오픈소스 VLA 모델들에 대해 정리하고 비교한다.
3.1. SmolVLA
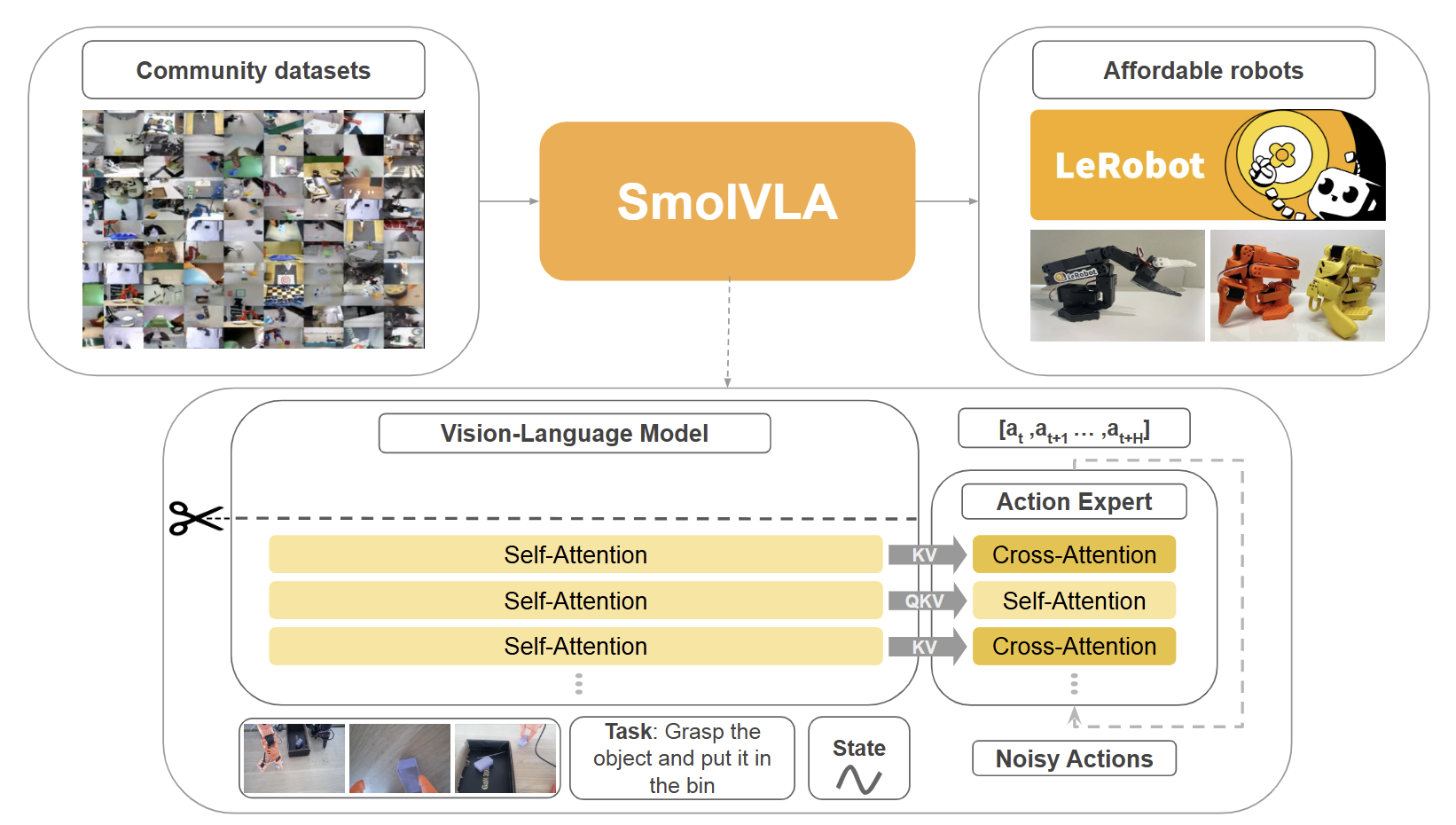
-
구조
SmolVLA는 약 450M 파라미터의 flow matching 기반 경량 VLA로, 작은 VLM backbone(SmolLM2 + SigLIP) + flow matching action expert 구조다. π₀의 dual-expert(VLM + action expert) 구조를 거의 그대로 가져오되, layer skipping(VLM의 절반만 forward 통과)과 interleaved cross-attention, self-attention으로 비용을 줄였다.학습 데이터는 OpenVLA의 1M 대비 4%인 23k trajectory(LeRobot 커뮤니티가 모은 SO-100/SO-101 SO-ARM dataset과 일부 OXE 부분집합)를 사용하였다. 학습은 single GPU에서 가능하고, 추론은 consumer GPU/CPU에서 가능한 수준이다.
-
설계 철학
SmolVLA의 철학은 "오픈소스의 진짜 의미는 weight 공개가 아니라 학습/추론까지 consumer 하드웨어에서 가능해야 한다는 것"이다. OpenVLA는 weight를 공개했지만 fine-tuning에는 여전히 A100급 GPU가 필요하고, 추론도 Jetson 같은 임베디드에서는 어렵다.SmolVLA는 LeRobot 생태계와 통합되어 SO-100/SO-101 같은 €500 짜리 robot arm에서 즉시 동작 가능하다. Flow matching을 채택한 것은 π₀의 50 Hz output을 작은 모델 사이즈에서 재현하기 위함이며, 데이터 23k trajectory는 "거대 사전학습 없이도 LeRobot 커뮤니티 데이터만으로 어디까지 가능한가"를 묻는 실험적 시도이기도 하다.
-
성능 및 기여
LeRobot 플랫폼(SO-ARM)에서 다양한 manipulation task 데모가 가능하다. 다만 RoboGate adversarial benchmark에서 cross-embodiment zero-shot 성공률이 0%로 보고된 바 있어, 작은 VLA의 일반화 한계는 분명하다.SmolVLA의 기여는 성능 자체보다 (a) LeRobot 생태계의 베이스 모델로 자리잡은 것, (b) HuggingFace Trainer/PEFT/Datasets에 native 통합되어 fine-tuning 진입 장벽을 한 단계 더 낮춘 것, (c) 학계가 "VLA 연구를 1× GPU에서 시작 가능"하게 만든 것이다.
3.2. CogACT
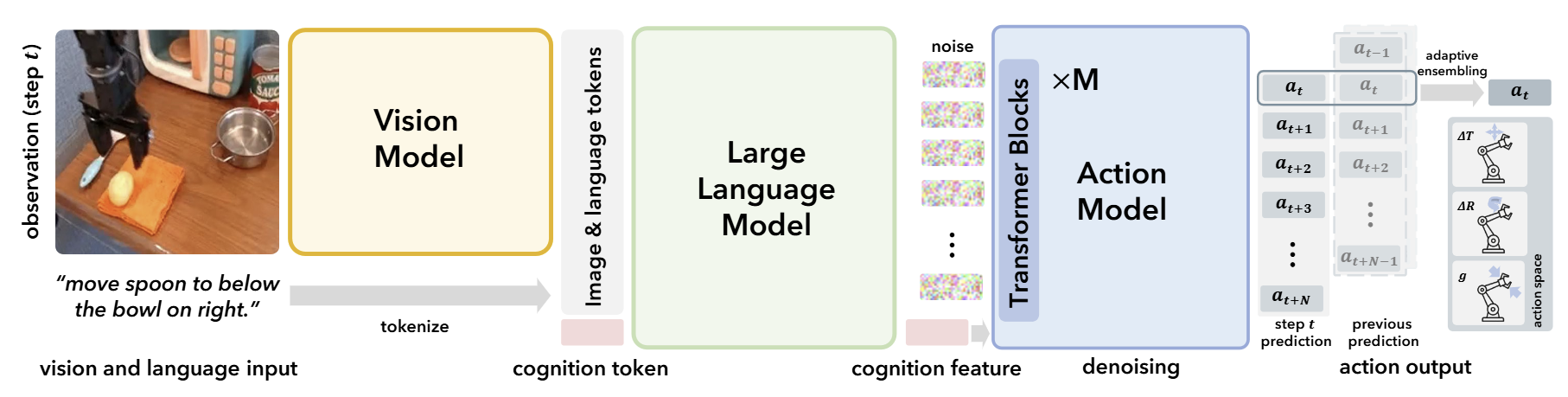
-
구조
CogACT는 "cognition은 VLM, action은 별도 transformer"라는 인지/운동 cortex 분리 비유로 설계된 모델이다. Vision은 DINOv2+SigLIP fused(OpenVLA와 동일), backbone은 Llama 계열의 7B VLM(OpenVLA와 호환), 그 위에 DiT(Diffusion Transformer) action head를 Base/Large로 얹는다.DiT-Base는 약 80M, DiT-Large는 약 300M 파라미터로 Octo의 3M head보다 훨씬 크다. VLM의 cognition feature가 condition으로 DiT에 들어가고, DiT는 action chunk(보통 16 step)를 diffusion으로 denoise한다. 학습은 OXE 0.4M trajectory로 사전학습 후 태스크별로 파인튜닝된다.
-
설계 철학
CogACT의 핵심 주장은 "Octo-style의 작은 diffusion head는 multimodal action distribution을 정확히 모델링하지 못한다"이다. Diffusion head가 충분한 capacity를 가져야만 같은 관찰에서 갈라지는 여러 합리적 action들을 모드 보존하며 학습할 수 있다는 것이다.이는 π₀의 별도 action expert(300M)와 같은 정신이지만, π₀가 PaLiGemma backbone에 expert를 추가한 것에 비해 CogACT는 OpenVLA backbone을 그대로 쓰고 head만 키우는 방식을 택했다. 즉 OpenVLA의 weight를 활용하면서도 head의 한계를 돌파하는 실용적 접근이라고 할 수 있다.
-
성능 및 기여
OXE 0.4M으로만 사전학습한 7B+DiT-L 모델이 simulation에서 OpenVLA(7B) 대비 +35%, real robot에서 +55%, RT-2-X(55B) 대비 +18% 성능 향상을 보고했다. 특히 SimplerEnv Google robot/WidowX zero-shot에서 RT-1, RT-1-X, RT-2-X, Octo, OpenVLA를 모두 넘어섰다.CogACT의 기여는 (a) "action head 크기가 결정적"이라는 정량 증명, (b) OpenVLA backbone + 큰 DiT head라는 hybrid 패턴을 제시해 후속 연구에 영향을 주었고, (c) cognition/action 분리가 dual-system VLA의 정신적 토대를 제공한 것이다.
3.3. RDT-1B
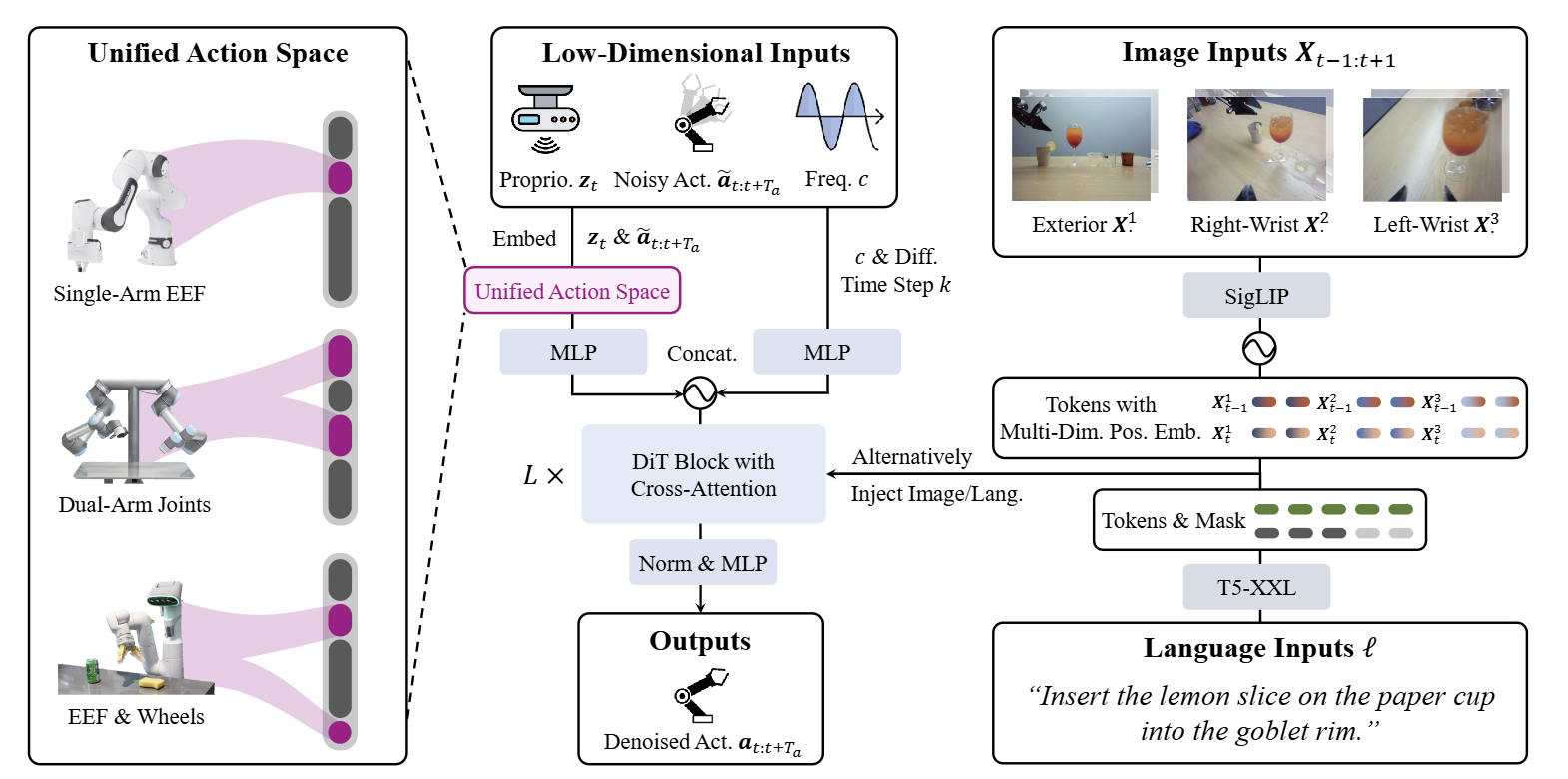
-
구조
RDT-1B는 1.2B 파라미터 규모의 로봇 조작을 위한 Diffusion Transformer(DiT) 기반 파운데이션 모델이다. Vision은 사전 학습된 SigLIP (3-view: 외부, 양쪽 손목)으로, Text는 T5-XXL로 인코딩하며, 두 모델의 가중치는 동결(Freeze)하여 사용한다. 백본인 DiT 구조가 노이즈에서 연속적인 Action Chunk를 디노이징하며, Action Chunk 크기는 64 스텝이다.기존 모델들처럼 특정 주파수에 고정되지 않고 각기 다른 데이터셋의 제어 주파수() 자체를 입력 토큰으로 수용하여 가변적으로 처리하는 것이 특징입니다. 가장 중요한 혁신은 '물리적으로 해석 가능한 통합 행동 공간 (Physically Interpretable Unified Action Space)'이다. 구조가 다른 로봇들의 양팔, 관절, 말단 장치(EEF), 바퀴 구동 등의 행동을 물리적 의미를 보존한 채 단일 128차원 벡터 공간에 매핑한다. 이를 통해 46개 데이터셋, 100만 개 이상의 에피소드로 사전 학습한 뒤, 자체 수집한 ALOHA 양팔 로봇 데이터셋(6K+ 에피소드)으로 파인튜닝된다.
-
설계 철학
RDT-1B의 철학은 시각/언어의 복잡한 표현은 이미 대규모 데이터로 학습된 인터넷 기반 파운데이션 모델(SigLIP, T5)에 맡기고, 로봇 제어를 위한 파라미터는 본질적으로 물리적인 '행동 모델링(Action Modeling)'의 스케일을 키우는 데 집중해야 한다는 것이다.양팔 로봇 제어가 지니는 다형성(Multi-modality)을 정확히 포착하기 위해 표현력이 뛰어난 Diffusion 모델을 채택했으며, 형태가 다른 다기종 로봇의 데이터를 낭비 없이 하나로 통합 학습하여 범용적인 물리 법칙을 깨우치게 하기 위해 통합 행동 공간을 고안했다.
시각 토큰이 언어 토큰보다 많아 지시어 정보를 잃어버리는 현상을 방지하기 위해, 각 cross-attention 레이어에 시각과 언어 토큰을 번갈아 주입하는 '교차 조건 주입(Alternating Condition Injection, ACI)' 방식을 사용하여 지시 수행 능력을 크게 향상시켰다.
또한 1.2B의 크기로 인한 추론 속도 문제를 극복하기 위해 가속화 샘플링 기법인 DPM-Solver++를 적용, 탑재된 RTX 4090 GPU 환경에서 확산 스텝을 1000에서 5단계로 줄임으로써 초당 6회의 action chunk 추론(평균 초당 381 액션)을 달성하여 실시간 제어가 가능하도록 만들었다.
-
성능 및 기여
실제 로봇 평가에서 ACT, OpenVLA, Octo 등의 최신 SOTA 모델들을 제치고 광범위한 작업에서 성공률을 56% 향상시켰다. 섬세한 양팔 조작(Dexterous bimanual)에서의 결정적 우위는 '비선형 MLP 디코더' 도입과 확산 모델링에서 비롯되며, 로봇 개 조이스틱 조종과 같은 고도의 비선형적이고 정밀한 작업도 성공적으로 수행합니다. 이 모델의 핵심 기여는 다음과 같다.(a) 매개변수를 1.2B로 확장한 현재까지 가장 큰 확산 기반 로봇 파운데이션 모델
(b) 처음 보는(Unseen) 객체와 환경, 지시어에 대해서도 강력한 Zero-shot 일반화 능력
(c) 1~5회의 시연만으로도 물건 건네주기, 옷 개기 등 완전히 새로운 기술을 배우는 강력한 Few-shot 학습 능력 증명
3.4. CoT-VLA
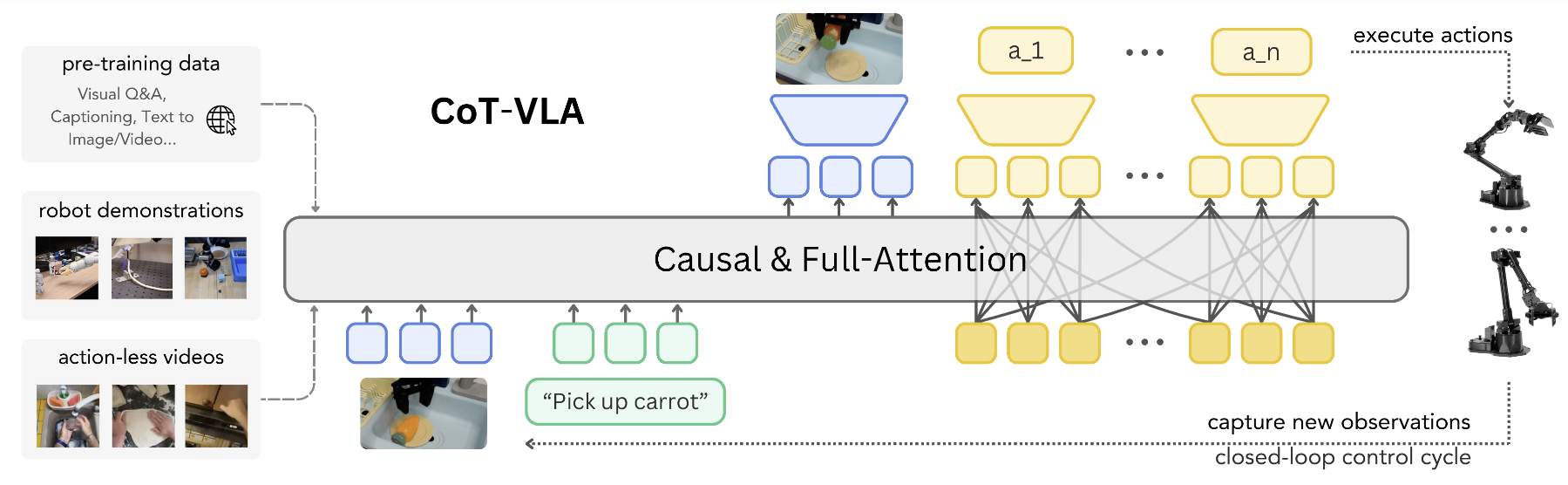
-
구조
CoT-VLA는 VILA-U 7B를 base로 하는 unified multimodal foundation model을 fine-tune한 모델이다. VILA-U는 text와 image 토큰을 모두 understand·generate 가능한 unified-tokenizer 모델로, 이를 활용해 CoT-VLA는 다음과 같은 출력 시퀀스를 생성한다: [language] → [current obs ] → [subgoal image : 256 image tokens, causal attention] → [action chunk: actions, full attention]즉 "행동 전에 미래 프레임을 먼저 그린 후 그것을 보고 행동"하는 hybrid attention 구조다. 학습 데이터는 (a) Open X-Embodiment robot demonstration, (b) action label 없는 인터넷 비디오(EPIC-KITCHEN-100, Something-Something)로, action-less video는 subgoal 생성 능력만 학습한다.
-
설계 철학
CoT-VLA가 던진 질문은 "LLM의 chain-of-thought에 해당하는 robotics CoT는 어떤 모달리티여야 하는가?"이다. Bbox나 keypoint 같은 abstract 표현 대신 subgoal image를 pixel-space에서 직접 생성하기로 결정한 이유는 다음 두 가지다:
(a) interpretable — 실패가 나면 subgoal 생성이 잘못된 건지 action 실행이 잘못된 건지 바로 진단 가능함
(b) action-less video를 자연스럽게 흡수 — 인터넷의 human video에는 action label이 없지만 subgoal 생성 학습에는 그대로 사용 가능함Hybrid attention(subgoal은 causal, action은 full)은 OpenVLA-OFT의 parallel decoding 통찰을 시퀀스의 한 부분에만 적용한 것으로, "예측은 sequential, 행동은 parallel"이라는 일반 패턴을 제시한다.
-
성능 및 기여
LIBERO 4 suite에서 발표 시점 SOTA, real-world Franka tabletop 6 task 평균 best — base VILA-U 직접 fine-tune 대비 +46.7% relative improvement. CoT-VLA의 진짜 기여는 정량 SOTA보다 세 가지 구조적 통찰이다.
첫째, "action-less video도 VLA 학습에 직접 기여 가능"이라는 데이터 활용 패러다임.
둘째, hybrid attention으로 video token 생성과 action 생성을 한 모델에서 분리.
셋째, unified multimodal foundation model(VILA-U 등)을 robotics에 fine-tune하는 표준 recipe 제시. 이 세 통찰은 이후 Gemini Robotics 1.5의 interleaved internal reasoning, π₀.₇의 visual subgoal conditioning에 직접 영향을 줬다.
3.5. Video Prediction Policy (VPP)
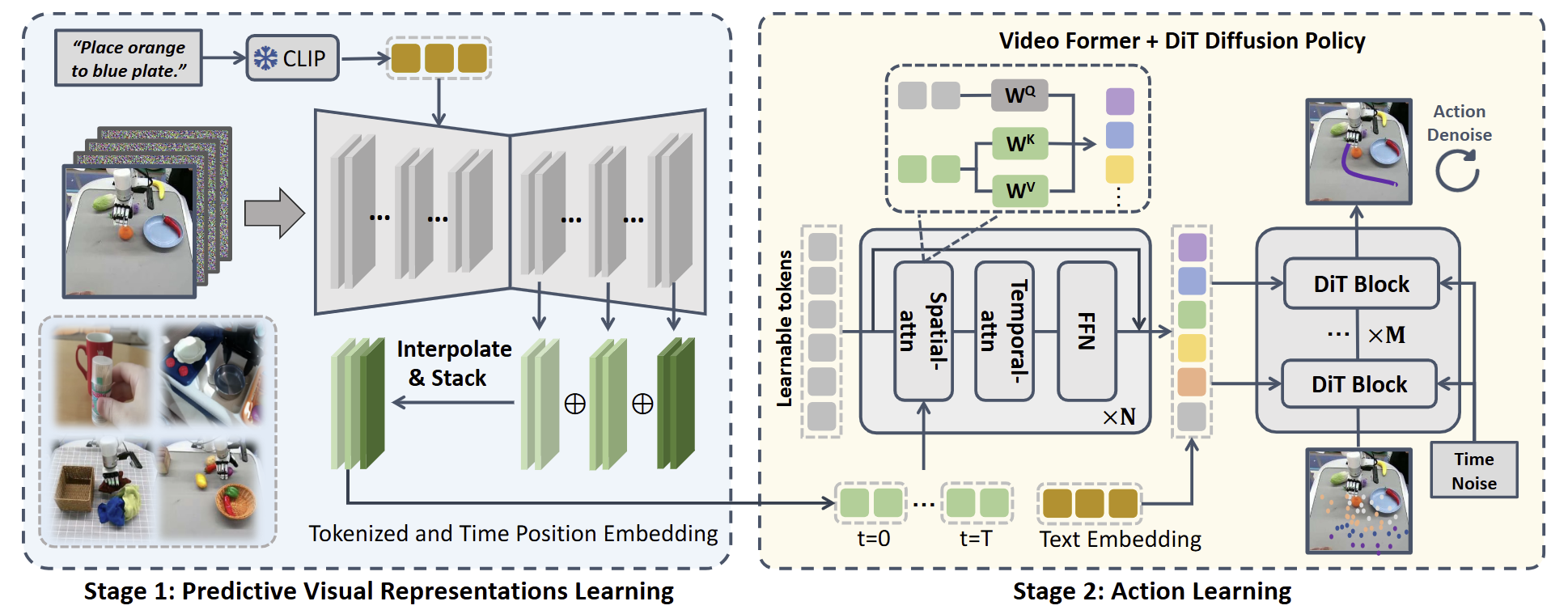
-
구조
VPP는 2-stage 학습 구조다. Stage 1에서 Stable Video Diffusion(SVD)를 robot manipulation 데이터(OXE 등) + 인터넷 인간 manipulation 영상(Something-Something v2)으로 fine-tune해 manipulation-specialized text-guided video prediction(TVP) 모델을 만든다. Stage 2에서 denoising을 끝까지 돌리지 않고, TVP의 단일 timestep forward pass에서 중간 layer feature(코드상Diffusion_feature_extractor의extract_layer_idx)를 추출 → Video Former 3D resampler → MDT(Masked Diffusion Transformer) policy에 condition으로 들어가 action chunk를 score matching loss로 학습한다. 즉 video model은 representation extractor로 격하되고 action은 별도 head가 출력한다. -
설계 철학
VPP의 핵심 가설은 "Video Diffusion Model의 internal representation은 본질적으로 현재 + 예측된 미래를 함께 인코딩하는 predictive visual representation이다"라는 것. 기존 vision encoder(MAE, CLIP, DINO, SigLIP)는 단일 이미지 또는 두 이미지 contrastive로 학습되어 static 정보 위주였고, embodied task에 결정적인 dynamics 정보가 없었다. VDM은 비디오 생성 학습 자체로 dynamics를 흡수했으므로, 굳이 비디오를 끝까지 생성하지 않고 internal feature만 뽑아도 dynamics-aware representation이 된다. 이 결정 하나가 video-based VLA의 실용성을 결정했다 — UniPi(2023)가 video를 끝까지 생성해 매우 느렸던 것과 정확히 반대 방향. -
성능 및 기여
CALVIN ABC→D 일반화 벤치마크에서 이전 SOTA 대비 18.6% relative improvement (v1) / 41.5% relative improvement (v2). Real-world XHand 5-finger dexterous platform에서 100+ task / 13 카테고리 / 4k trajectory 수집 후 단일 generalist policy로 평균 +31.6% 성공률 vs 강한 baseline. VPP의 기여는 (a) "video model을 정책 그 자체로 쓰지 말고 feature extractor로 쓰라"는 video-VLA 실용화의 결정적 recipe 제시, (b) Stable Video Diffusion 같은 오픈 video model로도 충분함을 보여 학계 진입 장벽 낮춤, (c) CoT-VLA와 정확히 정반대 방향(픽셀 vs feature)의 design space 제시로 후속 연구가 둘 사이에서 trade-off 탐색 가능하게 함.
3.6. X-VLA
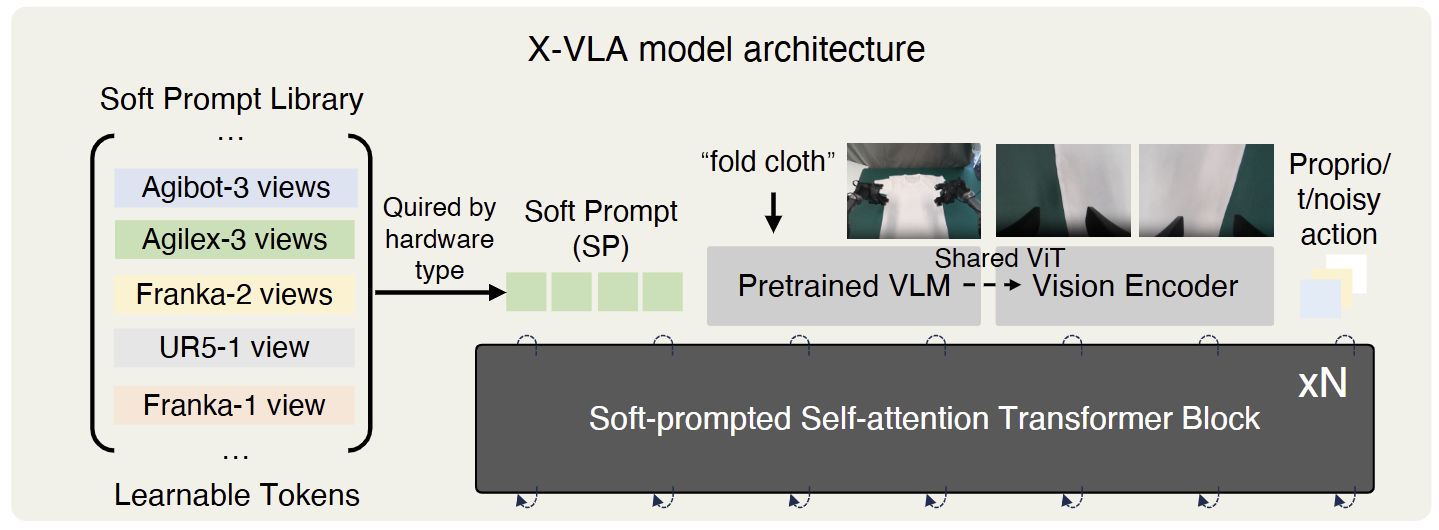
-
구조
X-VLA는 0.9B 파라미터의 cross-embodiment VLA로, Florence-Large vision encoder + 표준 transformer + flow matching action head 구조다. 가장 결정적인 혁신은 각 데이터 소스(embodiment)마다 별도의 soft prompt embedding 세트를 학습한다는 것 — 즉 UR5, Franka, ALOHA, WidowX 같은 다른 robot에 대해 각각 학습되는 작은 prompt vector 집합이 있고, 모델 자체는 공유된다. 학습 시 각 episode가 어느 embodiment에서 왔는지에 따라 해당 soft prompt가 prepend된다. -
설계 철학
X-VLA의 철학은 "cross-embodiment 학습의 본질은 모델 통합이 아니라 conditioning 분리"라는 것. RDT-1B의 unified action space가 robot 차이를 공유 표현 공간으로 흡수하려 한 반면, X-VLA는 차이를 soft prompt에 격리시켜 모델 본체는 robot-agnostic하게 유지한다. 이는 LLM의 prompt tuning에서 유래한 발상으로, 새로운 robot에 transfer할 때 (a) 모델 전체를 fine-tune할 필요 없이, (b) soft prompt만 학습하거나 기존 prompt를 부분적으로 frozen해도 초기 단계 transfer가 가능하다는 매우 실용적 이점이 있다. π₀.₇의 "metadata로 disambiguate"와 같은 정신의 다른 구현으로 볼 수 있다. -
성능 및 기여
6 simulation + 3 real platform에서 SOTA 보고. UR5에서 학습한 prompt를 WidowX에 부분적으로 frozen 사용해도 초기 단계 transfer 효과가 큼을 입증. X-VLA의 기여는 (a) "cross-embodiment를 학습할 때 soft prompt가 unified action space보다 단순하면서 효과적일 수 있다"는 새로운 design space 제시, (b) RDT-1B(통합)와 X-VLA(분리)라는 두 cross-embodiment 패러다임의 명시적 대비를 만든 것, (c) prompt-tuning 기법을 robotics fine-tuning에 정식 도입한 첫 사례 중 하나.
3.7. 모델 요약표
| 모델 (연도) | 기관 | 매개변수 | 행동 생성 방식 | 핵심 혁신 | 주요 한계 |
|---|---|---|---|---|---|
| Diffusion Policy (2023) | Columbia / TRI | ~80M | DDPM (100 steps) | Multimodal action distribution preservation | Slow inference (100 denoising steps) |
| Octo (2024) | UC Berkeley | 27M / 93M | Diffusion head (~5 steps) | Modular foundation model, readout token | Limited action head capacity |
| OpenVLA (2024) | Stanford / Berkeley | 7B | 256-bin discrete AR | Open-source VLA standard, LoRA fine-tuning | AR inference latency (~5 Hz), quantization error |
| OpenVLA-OFT (2025) | Stanford | 7B | Parallel L1 continuous (chunk 8/25) | Parallel decoding + L1 loss, 26× throughput | Per-task fine-tuning required |
| RDT-1B (2024) | Tsinghua | 1.2B | DiT flow matching (chunk 64) | Unified physical action space, bimanual specialization | High compute cost |
| CogACT (2024) | Microsoft | 7B+α | DiT diffusion action expert | Explicit cognition-action separation (DiT-B/L head) | Increased cost with larger head |
| SmolVLA (2025) | Hugging Face | 450M | Flow matching, async inference | Async inference 30% speedup, interleaved cross-attention | Limited zero-shot generalization |
| X-VLA (2025) | — | 0.9B | Flow matching (10 steps) | Soft prompt cross-embodiment adaptation, 1% param tuning | Max 30 robot configs supported |
| VPP (2024) | — | — | Predictive visual representation + DiT policy | Video diffusion internal latent as policy condition, 50 Hz (no full denoise) | High pretraining cost on video data |
| CoT-VLA (2025) | Stanford / NVIDIA | 7B | Hybrid (causal AR for image/text + full attention for action) | Visual chain-of-thought via autoregressive subgoal image generation | Subgoal image quality bottleneck |
4. 메인스트림 기업들의 VLA 설계 철학 비교
4.1. Physical Intelligence(PI) - OpenPI 시리즈
Physical Intelligence는 인터넷 규모의 거대 시각-언어 모델(VLM)이 지닌 풍부한 의미론적 지식을 물리적 모터 제어와 결합하는 데 엔지니어링 역량을 집중했다. 모델의 진화 단계마다 행동 출력 방식 — 연속적 플로우 매칭과 이산적 자기회귀 — 을 번갈아 실험하며 최적 아키텍처를 탐구한 것이 이 시리즈의 핵심 서사다. 그 결과물인 π₀ 시리즈는 2024년 하반기부터 2026년 4월까지 약 6개월 주기로 갱신되며 사실상 로보틱스 분야의 GPT 시리즈에 해당하는 계보를 구축하고 있다.
π₀: 고주파수 플로우 매칭의 기준점
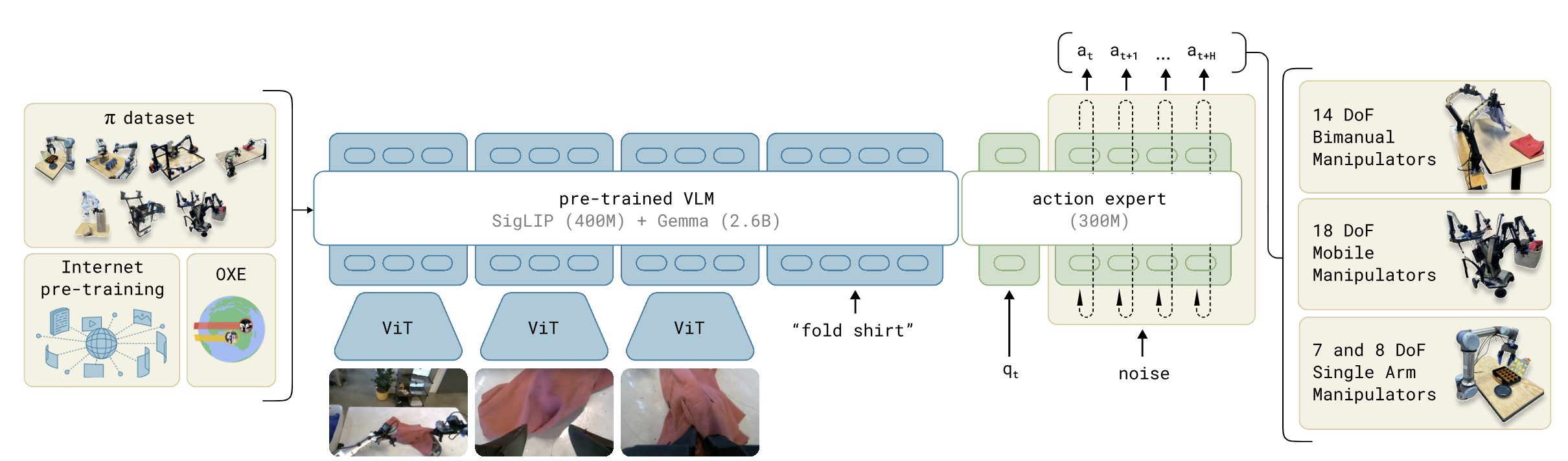
시리즈의 첫 번째 모델인 π₀는 사전 학습된 PaLiGemma 3B VLM 백본 위에 약 300M 매개변수 규모의 플로우 매칭 행동 전문가(Action expert)를 접목한 구조다. VLM이 이미지와 텍스트를 처리하는 동안, 행동 전문가는 고유 감각 정보(Proprioception)와 노이즈가 포함된 행동 청크를 입력으로 받아 조건부 플로우 매칭(Conditional Flow Matching, CFM)으로 50Hz 이상의 고주파수 연속 모터 명령을 출력한다.
Block-wise causal masking 덕분에 VLM 블록은 자기 자신에만, 상태는 자신과 VLM에, 행동은 모든 블록에 어텐션할 수 있어 KV 캐시 재활용이 가능하다. 훈련 시에는 플로우 매칭 타임스텝을 균일 분포 대신 초기 단계에 집중하는 베타 분포(β-distribution)로 샘플링하여 실용적인 가속을 구현했다. 빨래 개기, 상자 조립 등 수 분에 걸친 정밀 작업에서 OpenVLA와 Octo 대비 압도적인 성능을 보였으나, 대규모 훈련에 필요한 연산 비용이 매우 높다는 한계가 있었다.
π₀-FAST: DCT 기반 시계열 압축과 자기회귀적 효율성
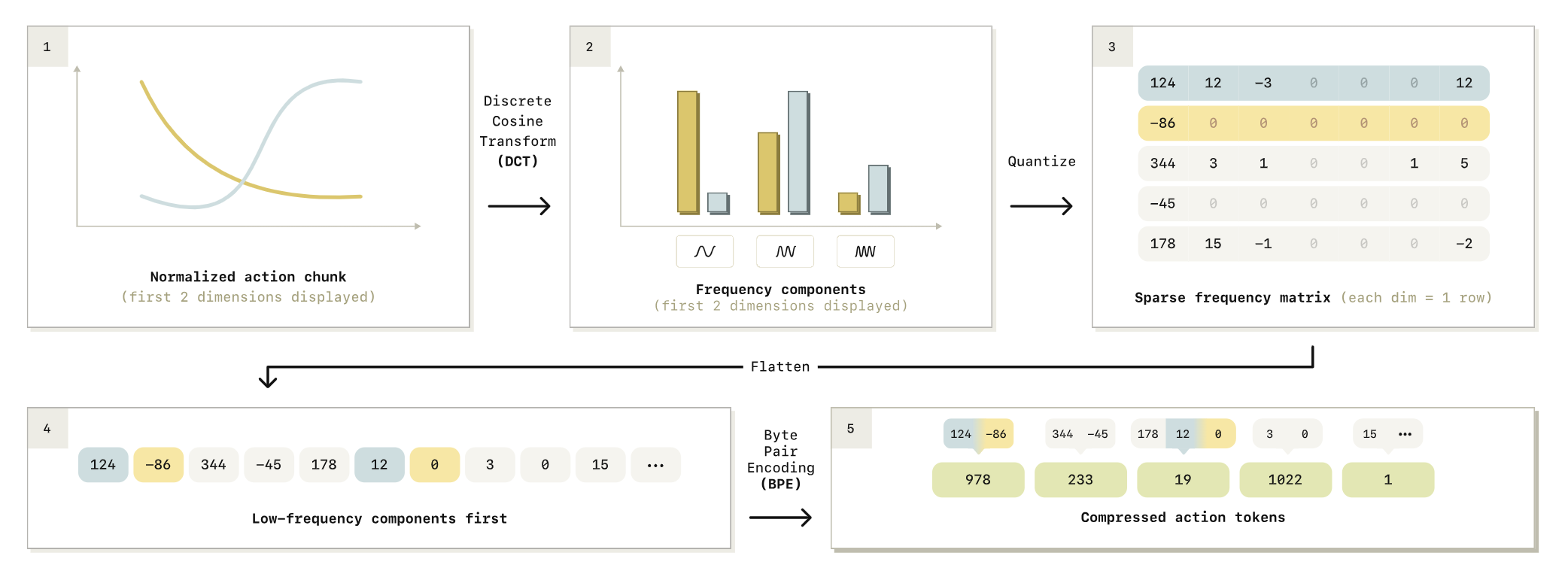
π₀ 훈련의 연산 병목을 해결하기 위해 도출된 π₀-FAST는 플로우 매칭을 완전히 제거하고, 혁신적인 FAST(Frequency-space Action Sequence Tokenization) 토크나이저를 도입하여 다시 자기회귀 기반으로 회귀했다.

FAST 토크나이저의 구현은 다음과 같다. 먼저 행동 청크에 이산 코사인 변환(DCT)을 적용하여 MP3·JPEG 압축과 동일한 원리로 저주파수와 고주파수 성분을 분리한다. 이후 양자화와 평탄화를 거친 다음, 바이트 페어 인코딩(BPE) 알고리즘으로 빈출 패턴을 단일 토큰으로 압축한다.
이 과정으로 원시 행동 데이터가 단 30~60개의 조밀한 토큰으로 변환되어 기존 균등 비닝 대비 10배 이상의 압축률을 달성했다. 그 결과 기존 플로우 기반 π₀ 대비 훈련 속도가 5배 빨라졌으며, 대규모 데이터셋에서는 3배 더 빠른 수렴과 더 나은 언어 지시 수행 능력을 보여주었다. 추론 시 자기회귀적 순차 디코딩으로 인해 플로우 매칭보다 지연이 발생한다는 점이 교환 조건으로 남았다.
KI-π₀와 π₀.₅: 지식 절연과 계층 구조의 완성
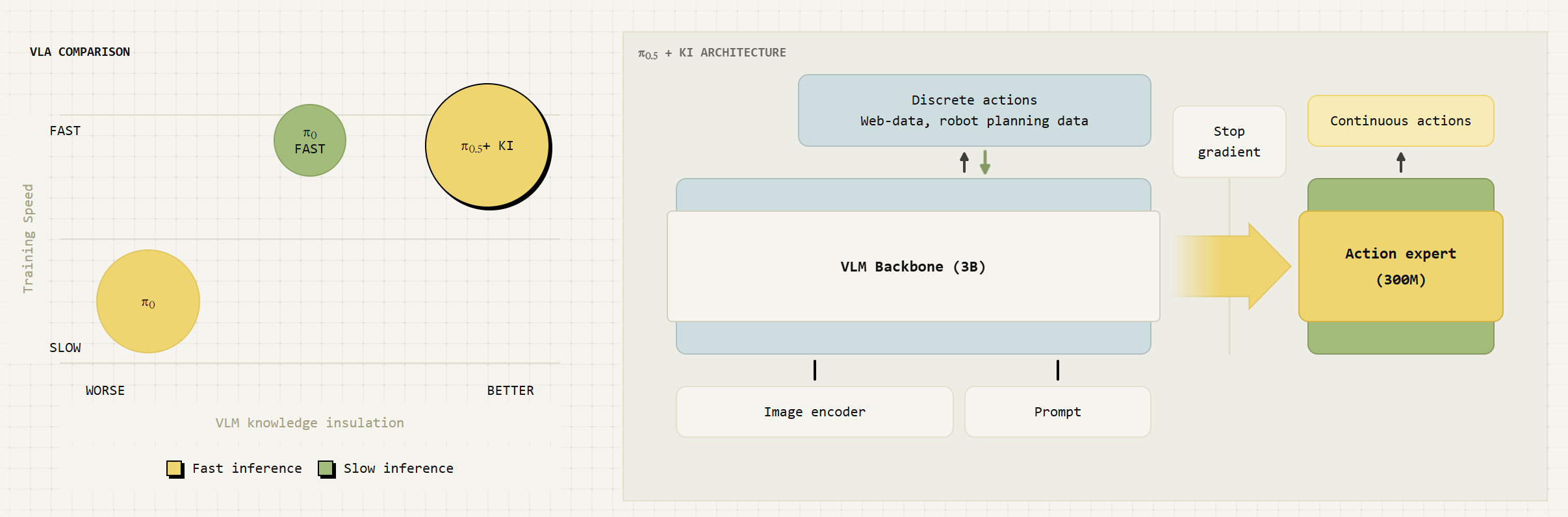
행동 전문가를 VLM 백본에 직접 연결하여 훈련하면, 회귀 방식 행동 생성 손실의 역전파 그래디언트가 VLM 내부의 언어적 의미 표현 공간을 교란하여 모델이 언어 이해 능력을 상실하는 '망각(Forgetfulness)' 현상이 발생한다. KI(Knowledge Insulation)-π₀는 이를 세 가지 메커니즘의 동시 적용으로 해결했다.
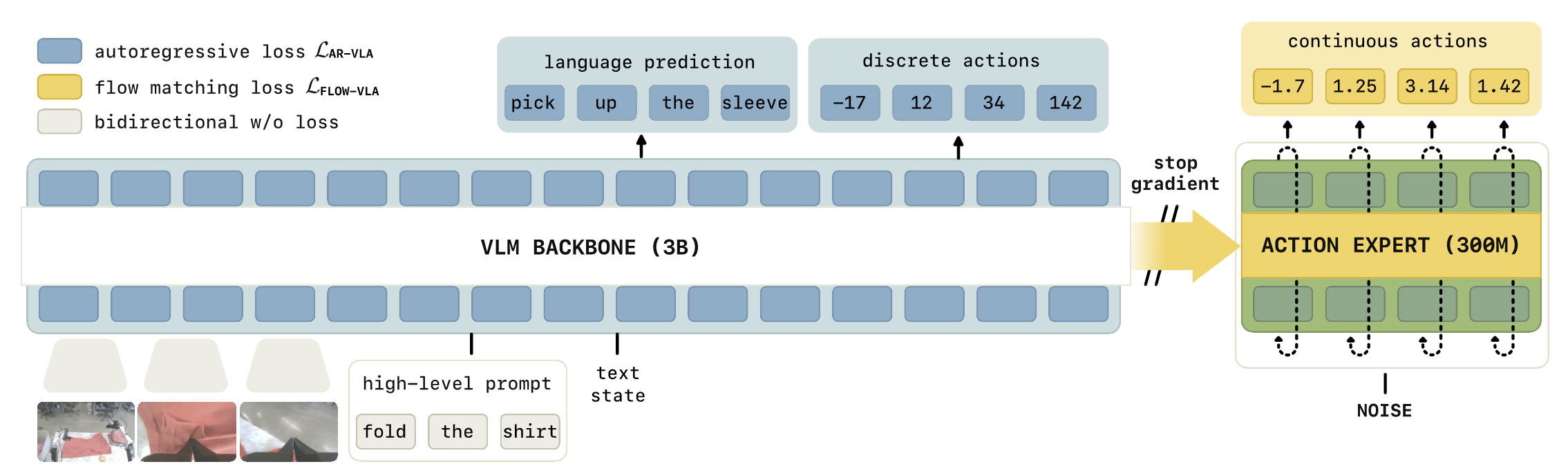
• 기울기 중단(Stop-gradient): 행동 전문가에서 발생한 그래디언트가 VLM 백본으로 흘러 들어가는 것을 강제 차단
• 이중 손실 공동 훈련(Joint discrete + continuous): 백본은 FAST 토큰화된 행동으로 교차 엔트로피 손실, 행동 전문가는 플로우 매칭으로 연속 출력 손실을 동시 학습
• VLM 데이터 공동 훈련(VLM data co-training): 일반 시각-언어 QA 데이터를 함께 학습하여 백본의 의미론적 표현 보존
추론 단계에서는 이산화된 토큰 경로가 버려지고 플로우 매칭 전문가만 활성화. 이 구조 덕분에 기존 π₀ 대비 7.5배 빠른 훈련 속도를 달성하면서 LIBERO-90, LIBERO-Spatial SOTA를 기록
π₀.₅: Hi Robot 계층 구조와 개방형 세계 일반화
π₀.₅는 KI-π₀의 지식 절연을 계승하면서 'Hi Robot' 이중 토폴로지 아키텍처를 완성했다. 저수준 정밀 제어를 위한 300M 행동 전문가의 플로우 매칭 경로(System 1), 고차원 의미 추론을 위한 자기회귀적 이산 텍스트 디코딩 경로(System 2)가 단일 모델 내에 공존한다.
이기종 다중 로봇, 웹 데이터, 고차원 의미 예측을 혼합 학습하여 실험실 외부의 일반 가정에서 처음 보는 환경의 식기 정리, 침대 정돈 등을 수행하는 최초의 엔드-투-엔드 학습 시스템으로 인정받았다.
π*₀.₆ + RECAP과 π₀.₇
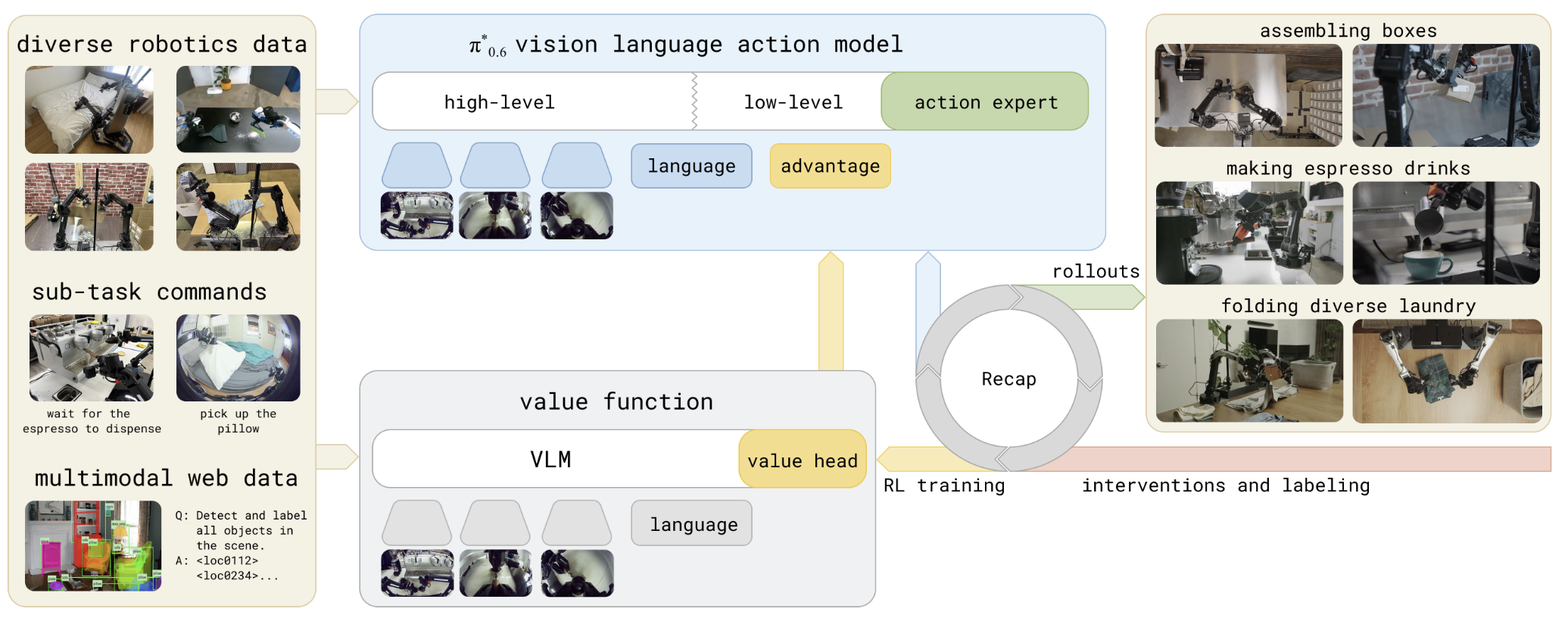
π*₀.₆은 Gemma 3 4B VLM 백본에 860M 규모의 행동 전문가(π₀의 약 3배)를 결합하고, RECAP(RL with Experience and Corrections via Advantage-conditioned Policies)이라는 새로운 RL 프레임워크를 도입했다.
RECAP은 어드밴티지 레이블과 함께 오프라인 RL 사전 학습 → 목표 작업 시연으로 지도 학습 → 자율 롤아웃과 사람의 텔레오퍼레이션 개입을 어드밴티지 레이블과 함께 수집하는 온라인 RL의 3단계로 구성된다. 전통적인 PPO/SAC 대신 어드밴티지 조건화(Advantage conditioning)로 RL을 우회한 것은, 플로우 매칭 정책의 로그 확률이 수학적으로 정의되지 않는다는 근본 문제에 대한 영리한 해결책이다.
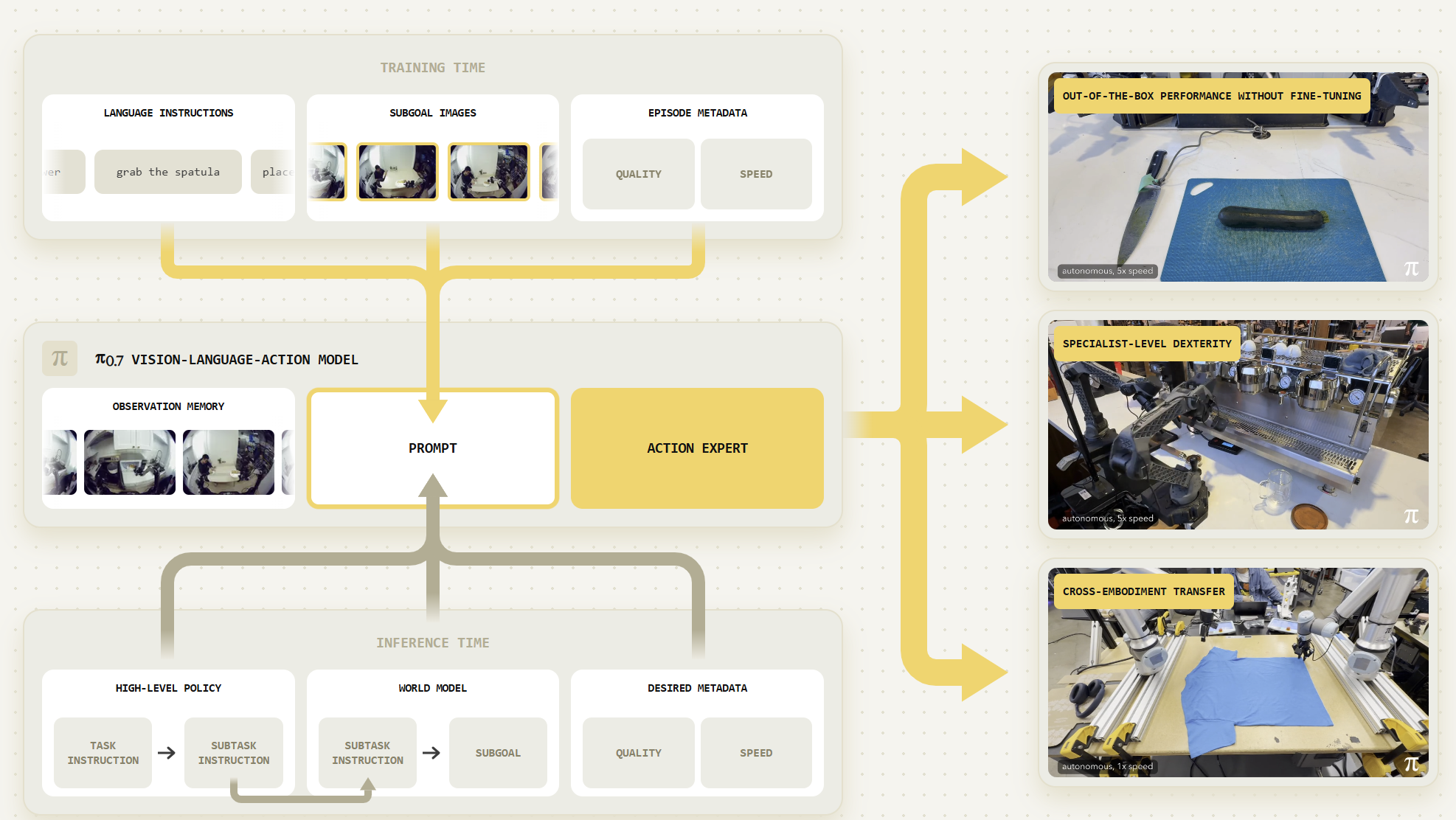
2026년 4월 발표된 π₀.₇은 멀티모달 프롬프팅을 통해 단일 제너럴리스트 모델이 조합적 일반화(Compositional generalization)를 달성한다는 점을 보여주었다. 다양한 언어 지시, 속도·품질 메타데이터, 제어 모달리티 레이블, 시각적 서브골 이미지의 4종 멀티모달 프롬프트로 이기종 데이터를 단일 모델이 흡수한다. 추론 시에는 상위 정책이 서브태스크 명령 시퀀스를 생성하고, 경량 월드 모델이 각 서브태스크에 대한 시각적 서브골 이미지를 합성하며, π₀.₇ VLA가 이를 받아 실제 행동을 출력하는 계층 구조로 동작한다.
다만 몇 가지 사항을 유의해야 한다. π₀.₇은 현재 학술 사전 인쇄 논문 없이 공식 블로그와 PDF만 공개된 상태이며, 모델 크기·백본 세부 사양이 미공개다. 에어 프라이어 실험에서 초기 성공률 5%가 30분간의 프롬프트 표현 개선으로 95%에 도달했다는 사실은, 진정한 제로샷이라기보다 프롬프트 엔지니어링의 역할이 결정적임을 시사한다.
4.2. Google DeepMind - Gemini Robotics
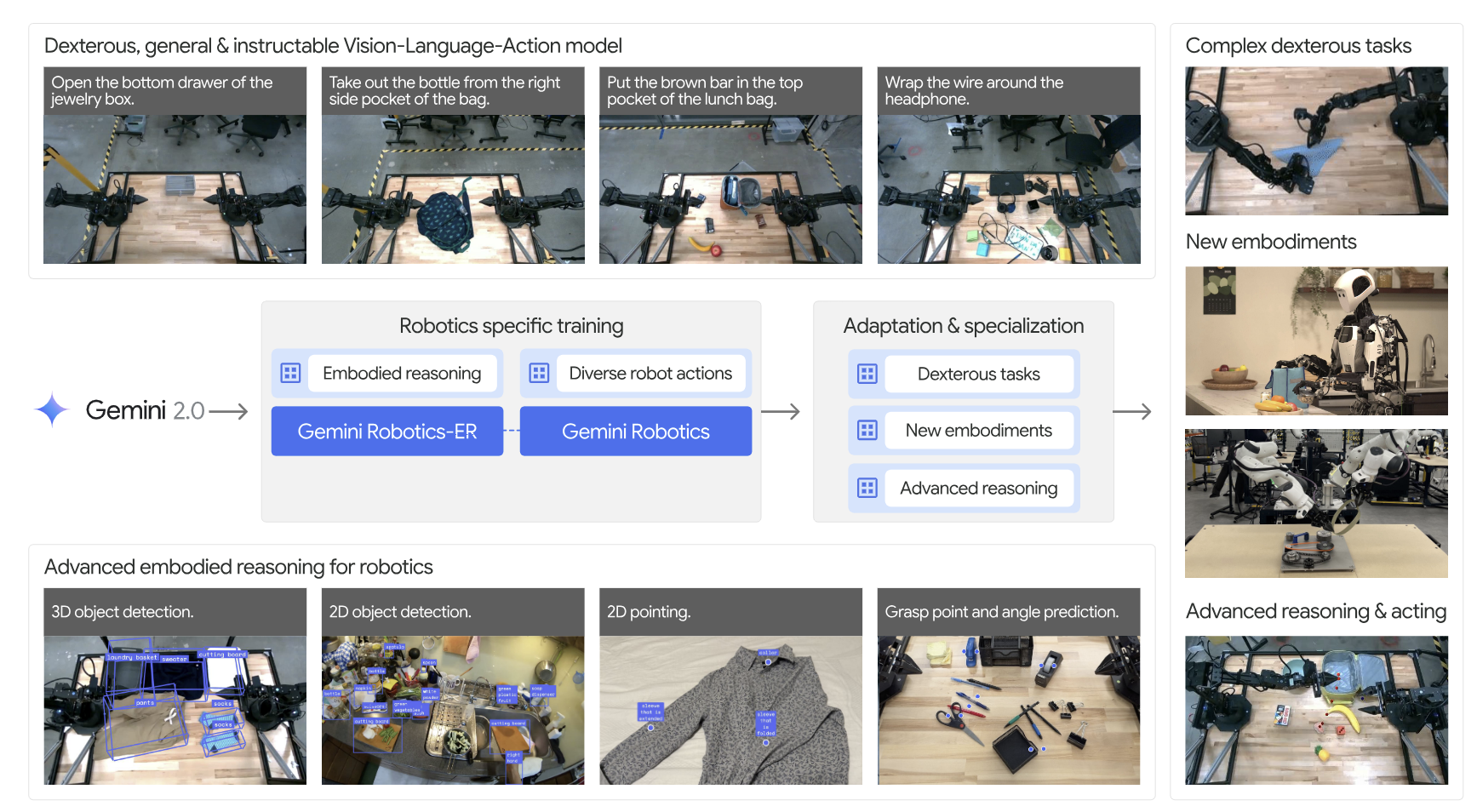
Google DeepMind가 발표한 Gemini Robotics 시리즈는 로봇을 단순한 명령 수행 기계가 아닌 자율적인 에이전트로 끌어올리는 데 중점을 둔다. 이 아키텍처의 본질적 설계 원칙은 고차원 오케스트레이터와 저수준 VLA 실행기의 완벽한 분업 체계다.
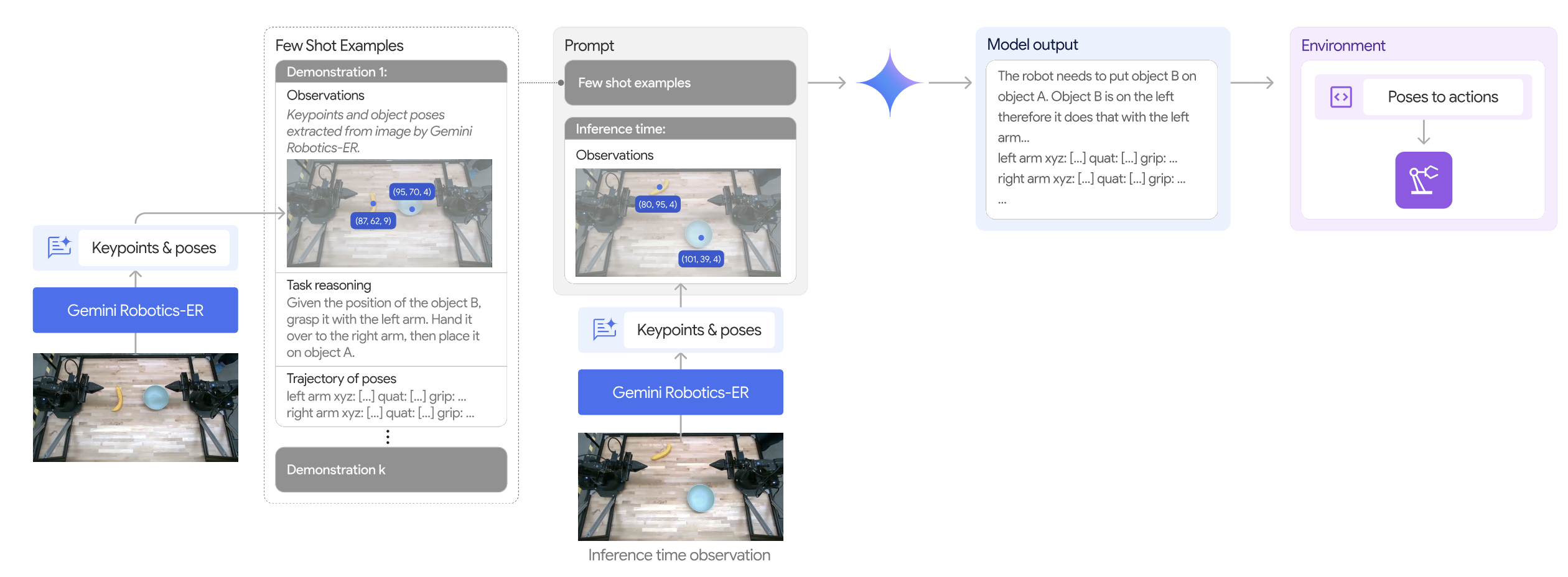
Gemini Robotics-ER: 구체화된 추론 특화 오케스트레이터
시스템 최상단에는 구체화된 추론(Embodied Reasoning, ER)에 특화된 Gemini Robotics-ER 모델이 오케스트레이터 역할을 수행한다. Gemini 2.0(1.5 버전에서는 3.0 Flash)을 백본으로 시공간적 이해력을 극대화한 이 모델은 3D 경계 상자(Bounding box) 예측, 2D 포인팅, 파지(Grasp) 자세 예측, 다중 뷰 대응성(Multi-view correspondence), 궤적 예측 등을 네이티브 출력으로 가지며, 공개한 ERQA 벤치마크에서 SOTA를 달성했다.
ER 1.5 모델의 강력한 무기는 고도의 작업 계획 수립 및 디지털 도구 사용 능력이다. 장기적인 다단계 문제(Long-horizon task)에 직면했을 때, 스스로 코드를 작성하여 로봇 API를 호출하거나 부족한 정보 수집을 위해 웹 검색 도구를 활용하는 고차원 에이전트 행동을 보여준다. 이는 기존 RT-H의 언어적 움직임 지시와 CoT-VLA의 시각적 연쇄 사고를 통합 발전시킨 것으로 볼 수 있다.
Gemini Robotics 1.5 VLA: 동작 전이와 사고하는 VLA
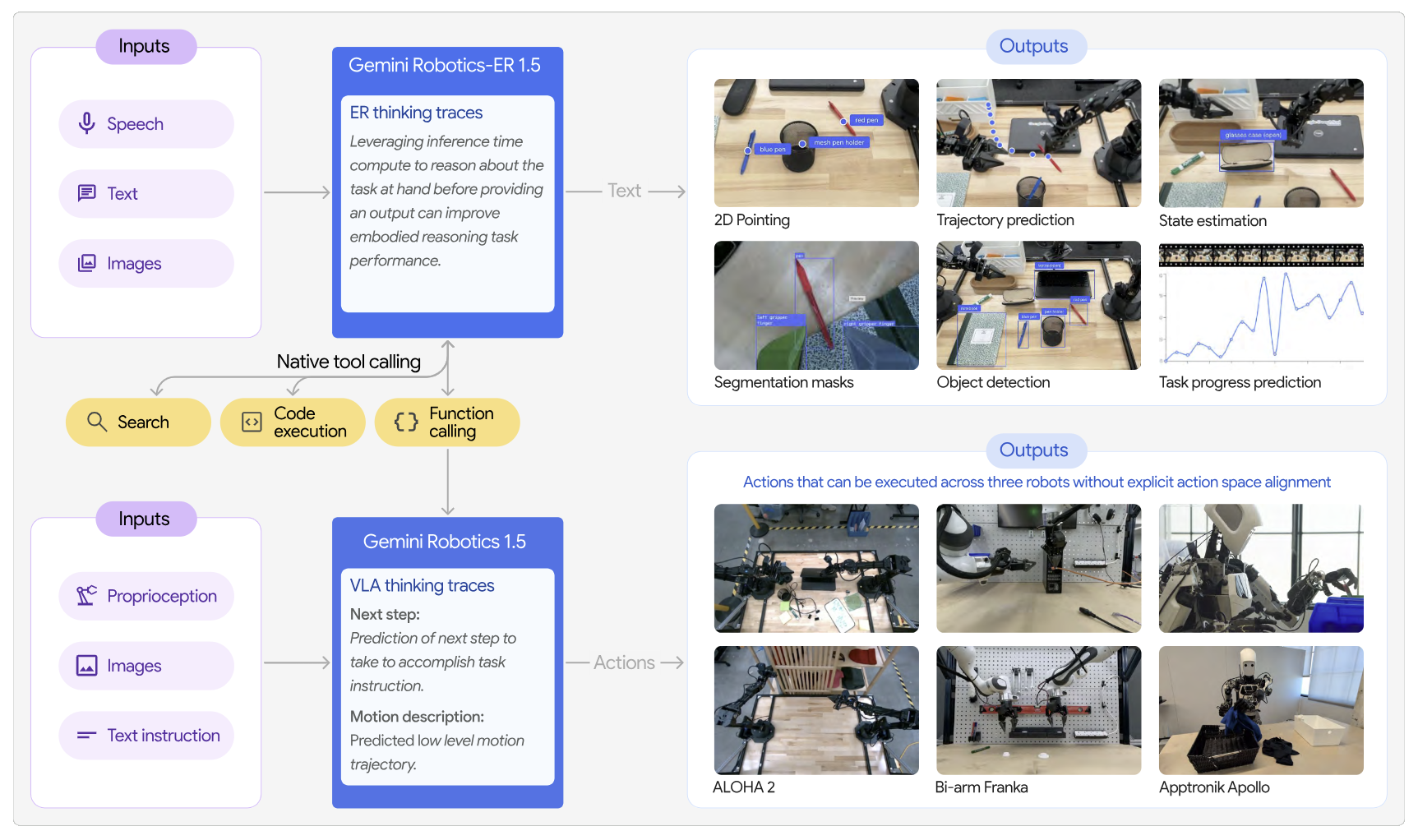
오케스트레이터가 수립한 의미론적 계획은 특화된 도구로 취급되는 Gemini Robotics 1.5 VLA에 의해 실제 움직임으로 번역된다. 이 VLA 아키텍처는 두 가지 핵심 혁신을 내장하고 있다.
첫째, 이기종 다중 형태 로봇 데이터를 일반화하는 동작 전이(Motion Transfer, MT) 메커니즘이다. 물리적 형태가 전혀 다른 로봇들의 움직임과 물리학을 공통된 추상 이해 공간으로 통일함으로써, 훈련 데이터에서 ALOHA 2 로봇 팔만 학습한 작업을 형태가 완전히 다른 휴머노이드 로봇 Apollo나 양팔 로봇 Franka에 추가 미세조정 없이 즉각 이식하는 제로샷 전이를 실현했다.
둘째, '사고하는 VLA(Thinking VLA)'의 구현이다. 행동을 출력하기 직전, 모델은 시각적 관측치와 지시문을 바탕으로 다단계의 연속적인 '생각의 흐름(Stream of thoughts)'을 자연어로 생성하여 컨텍스트 윈도우에 추가한다. 이로써 모델의 의사 결정 투명성이 극대화되었으며, 예기치 않은 방해나 오류를 스스로 감지하여 내부 언어 추론을 통한 즉각적인 복구 행동을 제안·실행하는 자율 회복성을 갖추게 됐다.
4.3. NVIDIA - Isaac GR00T
NVIDIA는 하드웨어 인프라 및 물리 시뮬레이션 분야의 절대적 우위를 바탕으로, 휴머노이드 로봇에 특화된 오픈 파운데이션 모델인 Isaac GR00T N1을 통해 VLA 패러다임에 독특한 접근법을 제시했다.
GR00T-N1, N1.5, N1.7
GR00T-N1은 명시적인 이중 시스템 구조를 채택했다. System 1은 DiT(Diffusion Transformer) 스타일의 플로우 매칭 행동 모듈이 담당하며, 추상 계획을 16단계 청크(약 63.9ms)로 정밀하게 번역한다. System 2는 NVIDIA Eagle-2 VLM(1.34B)이 담당하며, 환경의 시각적 맥락과 복잡한 다단계 지시를 분석하여 작업 계획을 수립한다(10Hz). 두 시스템은 Cross-attention으로 결합되어 end-to-end로 공동 훈련된다.
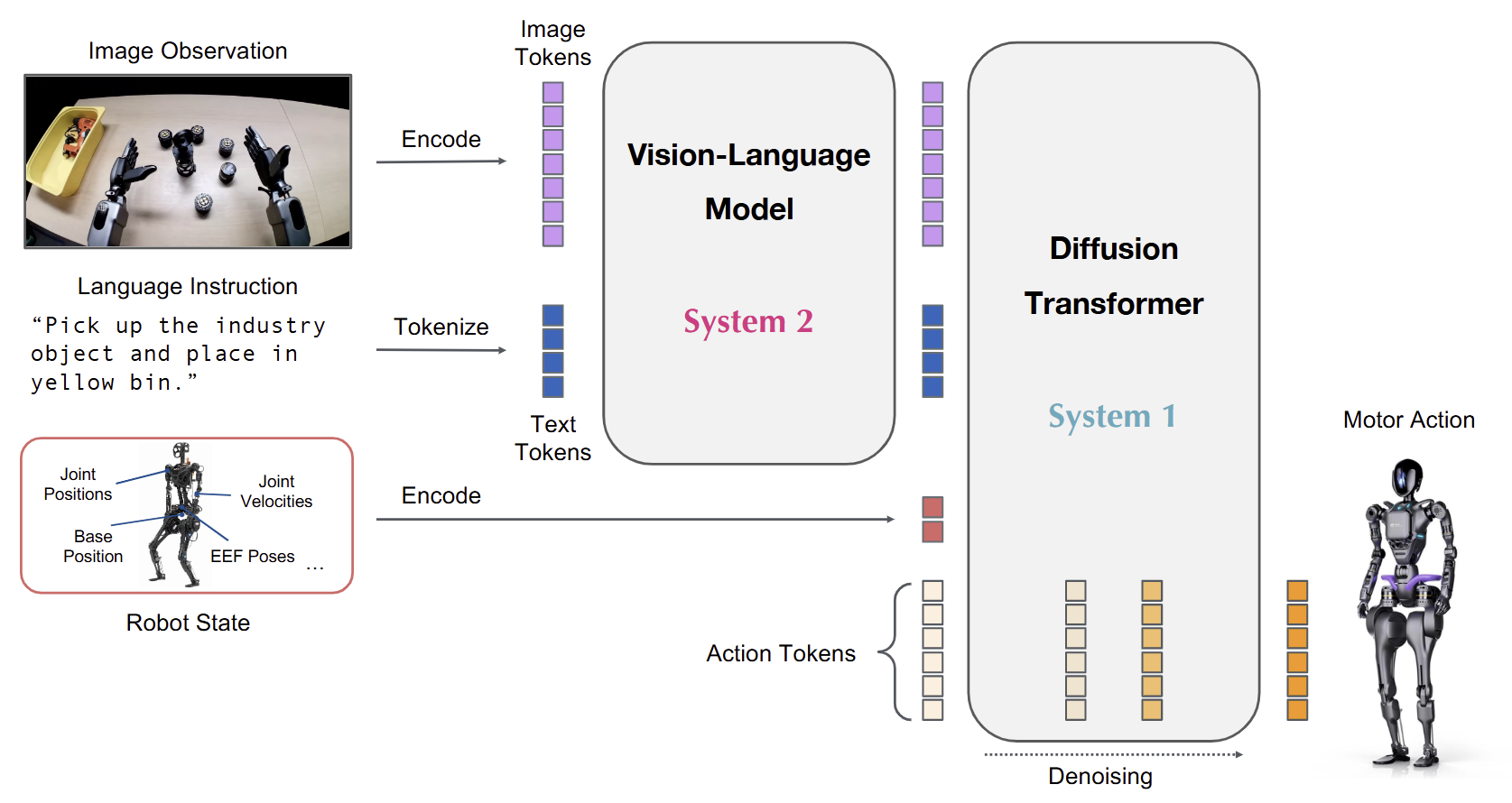
버전별 주요 변화를 살펴보면, N1.5(3B)에서는 Eagle-2 백본이 SigLIP2+T5로 교체되고 월드 모델링 공동 목적 함수가 추가됐다. N1.7(2026)에서는 백본이 Cosmos-Reason2-2B(Qwen3-VL 아키텍처)로 교체되고, 절대 좌표 대신 현재 자세 기준 델타를 사용하는 Relative EEF action space가 도입됐다.
이는 로봇·인간 데이터 간의 전이를 가능케 하는 핵심 설계 선택이다. 또한 20,000시간 분량의 EgoScale 인간 비디오 사전 학습이 추가됐다.
NVIDIA 방법론의 본질적 차별점은 훈련 데이터 조달 방식에 있다. Isaac GR00T Blueprint를 통해 Omniverse 플랫폼과 Newton 물리 엔진을 결합하여 대규모 합성 동작 궤적을 생성하는 플라이휠을 구축했다. 단 11시간 만에 78만 개의 합성 궤적을 생성했는데, 이는 인간이 쉬지 않고 시연할 경우 약 9개월(6,500시간)이 걸리는 분량이다.
DexMimicGen으로 수십 개의 실제 시연에서 54만 개의 합성 시연을 생성하는 파이프라인, 자체 GR-1 데이터셋에 미세조정된 이미지-비디오 모델로 추가 궤적을 합성하는 뉴럴 생성 궤적 파이프라인, 그리고 실제 텔레오퍼레이션 데이터를 혼합하는 방식이 결합된다. 합성 데이터와 실제 데이터의 혼합 결과 실제 데이터만 사용했을 때 대비 성능이 40% 향상됐다.
| 버전 | N1 | N1.5 | N1.7 |
|---|---|---|---|
| VLM 백본 | Eagle-2 | Eagle-2.5 | Cosmos-Reason2-2B (Qwen3-VL) |
| 액션 모듈 | DiT + Flow Matching | DiT + Flow Matching + FLARE | DiT + Flow Matching (상대 EEF) |
| 합성 데이터 | GR00T-Mimic | DreamGen | Isaac Lab + EgoScale |
| 인간 비디오 | 일부 활용 | FLARE로 활용 확대 | 20,854시간 EgoScale |
| 주요 개선 | 최초 오픈 VLA | 언어 지시 따르기 2배↑ | 스케일링 법칙 발견 |
4.4. Generalist AI - Gen
2026년 주류 기업들의 VLA 아키텍처 중 가장 이질적이고 근본주의적인 접근을 취하는 곳은 Generalist AI다. 이들은 LLM 백본에 로봇 행동 헤드를 덧붙이는 산업계의 지배적 트렌드를 거부하고, 처음부터 오직 물리적 상호작용만을 위해 파운데이션 모델을 바닥부터 훈련하는 독자 노선을 개척했다.
'VLA' 및 '세계 모델' 방법론에 대한 철학적 거부
Generalist AI의 설계 철학은 목표 주도형(Goal-driven) 연구에 뿌리를 두고 있다. 이들은 자사 파운데이션 모델을 'VLA'나 '세계 모델(World Model)'로 부르는 것을 의도적으로 기피한다. 기존 VLA는 텍스트 위주로 학습된 VLM에 로봇 동작을 억지로 끼워 맞춘 형태에 불과하며, 세계 모델에 대한 학계의 열광은 물리적 폐루프 제어(Closed-loop control)라는 본질적 목표에서 벗어난 일시적 유행에 가깝다고 비판한다. 이들의 철학은 확고하다 — 충분한 데이터와 컴퓨팅 자원이 확보된다면, 인간의 텍스트 편향을 배제하고 오직 물리적 센서-모터 상호작용 데이터만으로 밑바닥부터 훈련하는 것이 물리적 지능 달성의 가장 강력한 방법이라는 것이다.
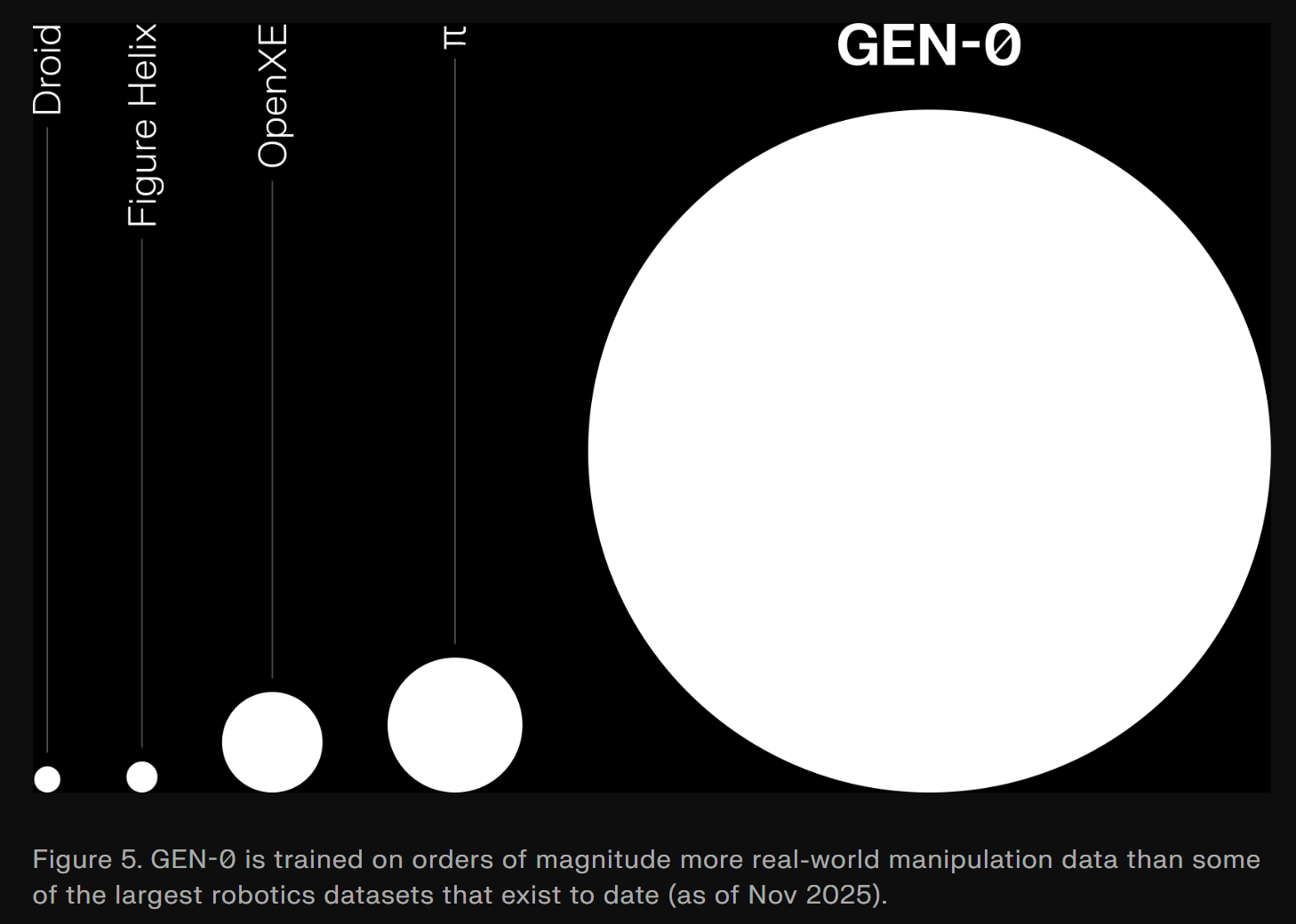
Gen0: Scaling Laws 증명과 Harmonic Reasoning
2025년 11월 발표된 Gen0는 27만 시간 이상의 고품질 실제 로봇 상호작용 데이터로 훈련됐다. 로봇 공학에서도 언어 모델과 마찬가지로 강력한 확장 법칙(Scaling Laws)이 존재함을 최초로 규명했다는 점에서 역사적 의의가 있다.
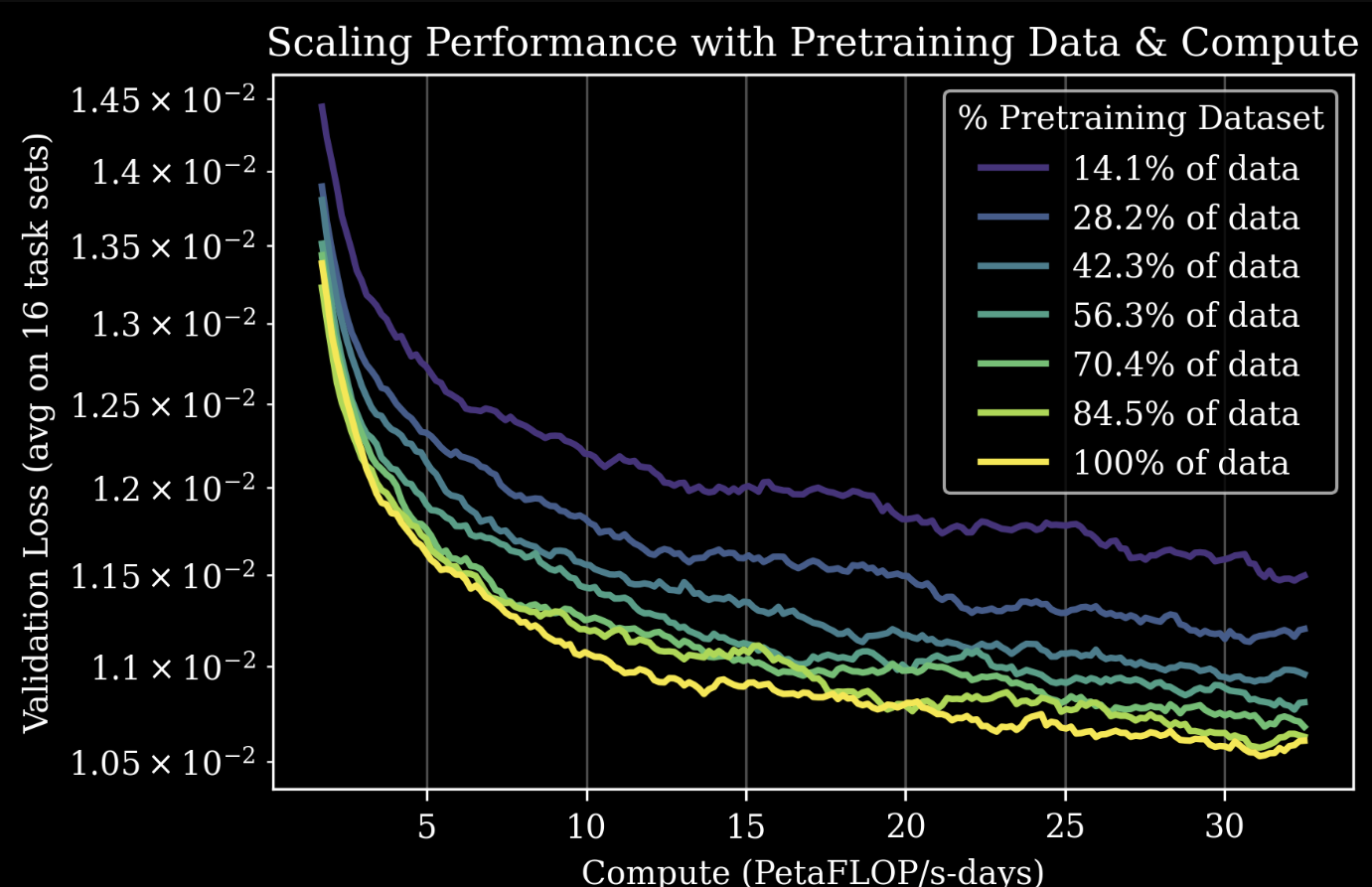
10B 매개변수 이하의 작은 모델들은 데이터가 너무 많아질 경우 새로운 정보를 통합하지 못하고 경직되는 '골화 현상(Ossification)'을 겪는 반면, 10B 이상의 모델은 방대한 물리적 상호작용 데이터를 완벽히 흡수하며 암묵적인 '물리적 상식(Physical commonsense)'을 발현하기 시작한다는 '상전이(Phase transition)' 현상이 관찰됐다.
Gen0의 가장 혁신적인 구조적 차별점은 조화 추론(Harmonic Reasoning) 아키텍처다. 기존 최첨단 시스템들이 인지 모델(System 2)이 생각할 시간을 확보한 뒤 행동 모델(System 1)에 명령을 하달하는 계층 구조를 취하는 반면, Generalist AI는 현실 세계의 물리학은 로봇이 생각할 때까지 기다려주지 않는다고 주장한다.
조화 추론은 센싱 토큰(감각)과 액팅 토큰(행동)의 비동기적이고 연속적인 시간 스트림 사이의 조화로운 상호작용을 모델 훈련 단계부터 근본적으로 통합하여, 별도의 하위 제어기나 이중 시스템 분리 구조 없이도 단일 모델 내에서 인지와 행동을 실시간 동시 수행한다.
Gen1: 웨어러블 데이터와 숙달 임계점 돌파
2026년 4월에 출시된 Gen1은 기초적인 단순 물리 작업에서 99%의 성공률을 돌파하며 로봇 제어의 '숙달(Mastery)' 임계점을 넘어섰다. 기존 최첨단 모델들이 달성했던 64%의 성공률을 압도했을 뿐 아니라, 상자 조립 벤치마크에서 기존 34초 걸리던 작업을 12.1초 만에 완료하여 약 3배 빠른 실행 속도를 보였다.
Gen1의 가장 파격적인 특징은 사전 학습 데이터에 실제 로봇 제어 데이터가 단 하나도 포함되어 있지 않다는 점이다. 대신 사람에게 저비용 웨어러블 디바이스를 착용시켜 수집한 수백만 가지의 빠르고 자연스러운 일상 활동 데이터를 기반으로 훈련됐다. 이는 로봇이 특정 작업에 처음 투입될 때, 작업의 역학뿐만 아니라 해당 로봇의 하드웨어 특성에 대해서도 동시에 적응하며 즉각적인 제어 능력을 발휘한다는 것을 의미한다. 단 1시간 분량의 작업별 미세조정 데이터만으로 숙달 수준에 도달하는 압도적인 데이터 효율성을 보여준다.
아키텍처 면에서는 Gen0의 조화 추론을 심화시키면서 장기적 물리 상호작용을 지연 없이 실시간 처리하기 위해 맞춤형 컴퓨팅 커널과 로봇 공학에 최적화된 새로운 형태의 Paged attention 기술을 도입했다.
5. Outro
2022년부터 2026년까지의 VLA 패러다임 전환을 정리하면 다음과 같다.
| 시기 | 핵심 기술 | 대표 모델 | 비고 |
|---|---|---|---|
| 2022–2023 | Discretized Action Token + Autoregressive | RT-1, RT-2, OpenVLA | 256-bin 비닝, 텍스트 토큰 매핑. 오늘날 신규 설계에서는 FAST처럼 훈련 효율을 위한 보조 경로로만 활용 |
| 2024 상반기 | Diffusion action head 분리 | Diffusion Policy, Octo, RDT-1B, CogACT | multimodal distribution 보존. 다만 20–50 step 샘플링이 실시간성의 걸림돌 |
| 2024 하반기 | Flow Matching | π₀ | VLM + 플로우 전문가 결합으로 50Hz 달성. 세대 2 아키텍처의 정점. 이후 GR00T N1·Helix·Gemini On-Device의 청사진 |
| 2025 상반기 | 이중 시스템 + FAST 토크나이저 + Knowledge Insulation | GR00T N1, Helix, KI-π₀, Gemini Robotics, OpenVLA-OFT | 세 요소의 조합 표준화. OFT는 "단순 L1도 확산과 동등"이라는 반례 제시 |
| 2025 후반–2026 | RL 기반 자기개선 + 온디바이스 배포 + 월드 모델 결합 + 인간 비디오 사전학습 | π*₀.₆, π₀.₇, GR00T N1.7, Gemini Robotics On-Device, Gen1 | 조합적 일반화, EgoScale 20K h 사전학습, 엣지 배포, 웨어러블 데이터 From scratch(Gen1) 모두 현재 진행형 |
References
- Brohan, A. et al. (2022). RT-1: Robotics Transformer for Real-World Control at Scale. arXiv:2212.06817. RSS 2023.
- Brohan, A., Zitkovich, B. et al. (2023). RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control. arXiv:2307.15818. CoRL 2023.
- Padalkar, A. et al. (2023). Open X-Embodiment: Robotic Learning Datasets and RT-X Models. arXiv:2310.08864.
- Belkhale, S. et al. (2024). RT-H: Action Hierarchies Using Language. arXiv:2403.01823. RSS 2024.
- Kim, M. J. et al. (2024). OpenVLA: An Open-Source Vision-Language-Action Model. arXiv:2406.09246.
- Chi, C. et al. (2023). Diffusion Policy: Visuomotor Policy Learning via Action Diffusion. arXiv:2303.04137. RSS 2023 / IJRR 2024.
- Team, O. et al. (2024). Octo: An Open-Source Generalist Robot Policy. arXiv:2405.12213. RSS 2024.
- Kim, M. J., Finn, C. & Liang, P. (2025). Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success. arXiv:2502.19645. (OpenVLA-OFT)
- Liu, S. et al. (2024). RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation. arXiv:2410.07864. ICLR 2025.
- Li, Q. et al. (2024). CogACT: A Foundational Vision-Language-Action Model for Synergizing Cognition and Action in Robotic Manipulation. arXiv:2411.19650.
- Shukor, M. et al. (2025). SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics. arXiv:2506.01844.
- Zhao, Z. et al. (2025). CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models. arXiv:2503.22020. CVPR 2025.
- Zheng, Z. et al. (2025). X-VLA: Learning a Cross-Embodiment Visual Language Action Model from Demonstrations and World Models. arXiv:2510.10274. ICLR 2026.
- Black, K. et al. (2024). π₀: A Vision-Language-Action Flow Model for General Robot Control. arXiv:2410.24164.
- Pertsch, K. et al. (2025). FAST: Efficient Action Tokenization for Vision-Language-Action Models. arXiv:2501.09747.
- Physical Intelligence (2025). π₀.₅: Open-World Generalization. arXiv:2504.16054.
- Shi, L. et al. (2025). Hi Robot: Open-Ended Instruction Following with Hierarchical Vision-Language-Action Models. arXiv:2502.19417.
- Driess, D. et al. (2025). Knowledge Insulation for Vision-Language-Action Models. arXiv:2505.23705. NeurIPS 2025.
- Physical Intelligence (2025). π*₀.₆ + RECAP: RL with Experience and Corrections via Advantage-conditioned Policies. arXiv:2511.14759.
- Physical Intelligence (2026). π₀.₇: Steerable Generalist Robot Policy. pi.website/blog/pi07.
- Gemini Robotics Team (2025). Gemini Robotics: Bringing AI into the Physical World. arXiv:2503.20020.
- Gemini Robotics Team (2025). Gemini Robotics 1.5. arXiv:2510.03342.
- Bjorck, J. et al. (2025). GR00T N1: An Open Foundation Model for Generalist Humanoid Robots. arXiv:2503.14734.
- Nvidia (2025). GR00T N1.5: An Improved Open Foundation Model for Generalist Humanoid Robots (article)
- Nvidia (2026). Isaac GR00T N1.7: Open Reasoning VLA Model for Humanoid Robots
- Generalist AI (2025). Gen0: Scaling Laws for Physical Intelligence.
- Generalist AI (2026). Gen1: Scaling Embodied Foundation Models to Mastery.

(박수)