SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
reading papers
Hugging Face, Sorbonne University 등이 저술한 SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics (2025)의 논문 내용 정리
🤗 SmolVLA
[paper]
[hugging face]
1. Introduction
1. 연구 배경: VLA 모델의 '비만'과 접근성 장벽
최근 OpenVLA나 RT-2와 같은 비전-언어-행동(VLA) 모델들이 로봇 제어 분야에서 눈부신 성과를 거두고 있다. 하지만 이들에게는 치명적인 단점이 존재한다.
-
높은 비용 (High Cost): 대부분 70억(7B) 개 이상의 파라미터를 가진 거대 모델이라서, 훈련과 추론을 위해 고가의 데이터센터급 GPU(H100, A100 등)가 필요하다.
-
높은 지연 시간 (High Latency): 덩치가 크다 보니 연산 속도가 느려서, 로봇이 실시간으로 빠르게 반응해야 하는 고주파 제어(High-frequency Control)에 부적합하다.
-
결과: 이러한 제약은 자금력이 부족한 연구실이나 개인 개발자(Hobbyists)가 로봇 AI 연구에 참여하는 것을 막는 진입 장벽(Barrier to Entry)이 되고 있다.
2. 동기: "작은 것이 아름답다 (Small is Beautiful)"
본 논문은 다음과 같은 질문에서 출발한다.
"정말로 로봇을 제어하는 데 수십억 개의 파라미터가 필요할까? 훨씬 작은 모델로도 똑똑하게 움직일 수 있지 않을까?"
저자들은 효율성(Efficiency)과 저렴함(Affordability)을 최우선 가치로 두었다. 누구나 집에 있는 게이밍 노트북이나 저렴한 로봇 팔(SO-100 등)로도 최신 AI 기술을 누릴 수 있어야 한다는 것이다.
3. 제안하는 모델: SmolVLA (Small VLA)
본 논문은 로봇 제어의 민주화를 위해 SmolVLA를 제안한다.
-
초경량 (Ultra-lightweight): 기존 모델 대비 약 1/15 크기인 4억 5천만(450M) 파라미터 규모다.
-
소비자 친화적 (Consumer-friendly): 고가의 서버 없이도, 일반적인 소비자용 GPU(NVIDIA RTX 30/40 시리즈)나 심지어 Apple Silicon(MacBook)에서도 원활하게 구동된다.
-
오픈 소스 생태계: Hugging Face의 LeRobot 팀과 협력하여, 3D 프린터로 만들 수 있는 저가형 로봇 팔과 오픈 데이터를 기반으로 개발되었다.
4. 핵심 기여 (Key Contributions)
이 논문이 제시하는 기술적 진보는 크게 세 가지로 요약된다.
-
구조적 혁신 (Architectural Efficiency): 최신 소형 언어 모델(SmolLM2)과 효율적인 비전 인코더(SigLIP)를 결합하고, 레이어 스킵(Layer Skipping)과 토큰 압축(Token Compression) 기술을 적용하여 연산량을 극단적으로 줄였다.
-
비동기 추론 (Asynchronous Inference): 로봇이 생각하느라 멈추지 않도록, '생각(Inference)'과 '행동(Action)'을 병렬로 처리하는 시스템을 도입하여 동작의 부드러움을 획기적으로 개선했다.
-
검증된 성능 (Proven Performance): 파라미터 수가 15배나 많은 OpenVLA(7B)와 비교했을 때, 시뮬레이션(LIBERO) 및 실제 환경에서 대등하거나 더 우수한 성공률을 보였다.
2. Related work
본 섹션은 기존 로봇 학습 연구를 세 가지 관점(모델 크기, 행동 생성 방식, 추론 속도)에서 분석하고, SmolVLA의 차별성을 부각한다.
1. 거대 VLA 모델: 성능과 비용의 trade-off
-
기존 접근 (Large-scale VLAs)
RT-2 1, OpenVLA 2와 같은 모델들은 인터넷 규모의 데이터로 학습된 거대 파운데이션 모델을 기반으로 하여 뛰어난 일반화(Generalization) 능력을 보여주었다. -
한계점
그러나 이들은 최소 70억(7B) 개 이상의 파라미터를 가지며, 추론 속도가 느려 실시간 제어가 어렵다. 또한, 구동을 위해 고가의 서버급 GPU가 필수적이어서 온디바이스(On-device) 로봇에 적용하기에는 현실적인 제약이 크다. -
SmolVLA의 전략
본 논문은 VLA의 강력한 추론 능력은 유지하되, 모델 크기를 450M(약 1/15) 수준으로 줄여 일반 소비자용 하드웨어에서도 구동 가능하게 만들었다.
2. 효율적인 정책 학습: 지능의 부재
-
기존 접근 (Specialized Policies)
Diffusion Policy나ACT(Action Chunking Transformer)와 같은 모델들은 로봇의 움직임(Action) 자체를 모방하는 데는 효율적이고 강력하다. -
한계점
하지만 이들은 언어 모델(LLM) 기반이 아니기 때문에, "파란색 컵을 치워줘"와 같은 언어 명령을 이해하거나 복잡한 상황을 추론하는 의미론적 지능(Semantic Understanding)이 부족하다. -
SmolVLA의 전략
SmolVLA는 SmolVLM이라는 언어-비전 백본을 사용하여 '언어 이해력'을 갖추고, 행동 생성 부분에는 경량화된 플로우 매칭(Flow Matching)을 적용하여 '운동 능력'까지 동시에 확보했다.
3. 추론 속도와 비동기 제어 (Inference Latency & Asynchronous Control)
-
기존 접근 (Synchronous)
대부분의 VLA 모델은 [관측 → 추론 → 행동]이 순차적으로 이루어지는 동기식(Synchronous) 방식을 사용한다. 모델이 생각(Inference)하는 동안 로봇이 멈춰 있어야 하므로 움직임이 뚝뚝 끊기는(Jittery) 현상이 발생하고, 제어 주파수(Hz)를 높이는 데 한계가 있었다. -
SmolVLA의 혁신
본 논문은 생각과 행동을 분리하는 비동기 추론(Asynchronous Inference) 파이프라인을 도입했다. 로봇이 행동하는 동안 백그라운드에서 다음 행동을 미리 계산함으로써, 지연 시간(Latency)을 은폐하고 훨씬 부드러운 움직임을 구현한다.
| 구분 | 거대 VLA (OpenVLA 등) | 기존 정책 모델 (Diffusion Policy) | SmolVLA (Proposed Method) |
|---|---|---|---|
| 장점 | 똑똑함 (언어/추론) | 빠르고 정교함 (운동신경) | 똑똑하고 빠름 |
| 단점 | 너무 무겁고 느림 | 언어 이해 능력 없음 | (상대적으로) 작은 지식 용량 |
| 실행 환경 | A100 등 고가 GPU | 일반 GPU | 노트북 / MacBook 가능 |
| 제어 방식 | 동기식 (Synchronous) | - | 비동기식 (Asynchronous) |
3. SmolVLA: small, efficient and capable
본 섹션에서는 SmolVLA의 설계 철학인 '효율성 중심(Efficiency-first)' 접근 방식을 설명한다. 목표는 일반 소비자용 GPU(Consumer GPU)에서 학습 및 추론이 가능한 모델을 만드는 것이다.
Overview.
SmolVLA는 기존 VLA의 비효율성을 제거하기 위해 바닥부터 새롭게 설계된 아키텍처를 가진다.
- 총 파라미터: 약 4억 5천만(450M) 개 (OpenVLA 7B 대비 약 15배 작음).
- 구성: 강력하지만 무거운 비전 인코더를 스마트하게 가지치기하고, 소형 언어 모델(SLM)과 결합한 뒤, 연속적인 행동 생성을 위한 경량 액션 헤드를 부착했다.
3.1 Model architecture
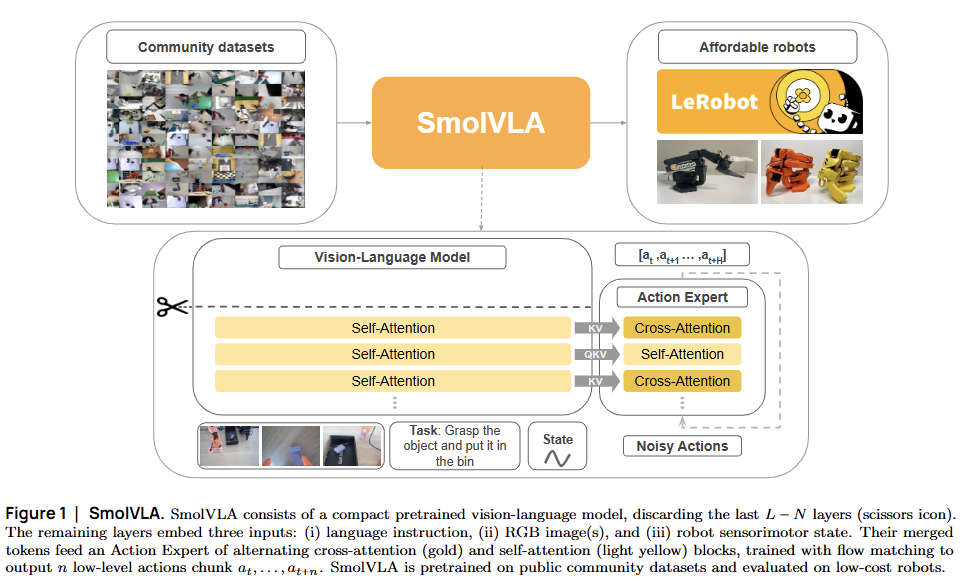
SmolVLA는 입력 데이터(이미지, 상태)를 처리하여 로봇의 행동을 출력하기 위해 다음 5가지 핵심 모듈이 순차적/유기적으로 작동한다.
1. 상태, 행동 및 특징 프로젝터 (State, Action, and Feature Projectors)
→ 서로 다른 언어를 사용하는 데이터들을 하나의 공통 언어(Embedding Space)로 번역해 주는 '통역사' 역할
-
역할: 로봇의 현재 관절 각도(State), 과거의 행동(Action), 그리고 이미지 특징(Feature)은 모두 데이터 형식이 다름 → 이들을 MLP 기반의 프로젝터(Projector)를 통과시켜, 언어 모델(VLM)이 이해할 수 있는 벡터 차원으로 변환
-
의의: 이를 통해 로봇의 물리적 상태 정보와 시각 정보가 자연어 처리 과정에 매끄럽게 통합됨
2. 시각 토큰 축소 (Visual Tokens Reduction)
→ 작은 모델이 체하지 않도록, 시각 정보의 핵심 정보만 추출
-
문제: 고해상도 이미지는 보통 1,000개 이상의 토큰을 생성하는데, 소형 모델(SmolLM)이 이를 전부 처리하기 어려움
-
해결: 공간 풀링(Spatial Pooling) 또는 C-Abstractor 기술을 사용하여, 이미지의 핵심 정보를 유지한 채 토큰 수를 단 64개로 대폭 압축
-
효과: 연산량을 획기적으로 줄여 추론 속도를 높임
3. 레이어 스키핑을 통한 빠른 추론 (Faster Inference through Layer Skipping)
→ "로봇 제어에 지나치게 철학적인 고민은 필요 없다"는 아이디어
• 원리: 비전 인코더(SigLIP)의 깊은 레이어(Deep Layers)는 '의미론적 추상화(이것은 의자라는 개념이다)'를 담당하고, 얕은 레이어(Early Layers)는 '기하학적 특징(모서리, 모양, 위치)'을 담당
• 적용: 로봇 조작에는 물체의 위치와 모양이 더 중요하므로, 인코더의 후반부 레이어를 과감히 건너뛰고(Skip), 앞부분의 특징만 사용하여 이미지 처리 속도를 2배 이상 가속화
4. 플로우 매칭 액션 전문가 (Flow Matching Action Expert)
→ 의 핵심 기술을 경량화하여 적용한, 로봇의 '운동 신경' 중추
-
구성: VLM 백본과는 별도로 존재하는, 행동 생성 전용 신경망
-
작동 원리: 언어 모델이 상황을 판단하면, 이 전문가 모듈이 넘겨받아 플로우 매칭(Flow Matching) 알고리즘을 수행
-
출력: 뚝뚝 끊어지는 이산적(discrete) 토큰이 아니라, 연속적인(Continuous) 행동 궤적을 생성. 노이즈로부터 최적의 행동 경로(Vector Field)를 직선에 가깝게 찾아내어, 적은 연산(Step)으로도 부드럽고 정교한 움직임을 생성
[Conditional Flow Matching (CFM)]
SmolVLA의 액션 전문가는 조건부 플로우 매칭(Conditional Flow Matching, CFM) 알고리즘을 사용한다. 이는 노이즈()를 로봇의 행동()으로 변환하는 속도(Velocity)를 학습하는 과정이다.
1) : “상황 설정 및 데이터 샘플링”
- (GT Action) : 현재 관측() 상황에서 로봇이 실제로 해야 할 정답 행동 덩어리(Action Chunk) (데이터셋에 있는 전문가의 행동)
- (Noisy Action) : 정답 행동()에 노이즈가 섞인 상태. Flow Matching에서는 시간 시점에서의 중간 위치를 의미.
- : 완전한 노이즈 (랜덤)
- : Ground Truth ()
- : 0~ 1 사이 어딘가에 있는 상태2) : "모델의 추측 (Prediction)”
- : 현재 위치
- : 현재 상황(이미지 토큰+언어 명령)
- : 현재 상황()를 보고 지금 위치()에서 취해야 할 Velocity Vector를 구함
3) : "정답 방향 (Target Velocity)”
- Flow Matching에서는 출발점(노이즈)에서 도착점(정답 행동 )으로 가는 가장 직선인 경로를 정답으로 침
- 수식으로는 보통 와 같이, 목적지를 향해 일직선으로 뻗은 벡터
4) : “오차 측정(MSE Loss)”
- 예측값()과 정답값()의 오차를 구함
- 오차 값이 0에 가까워지도록 파라미터를 학습
→ 모델()이 예측한 방향()이, 정답 방향()과 얼마나 다른지(오차)를 계산하는 수식
: 복잡한 확산 과정(Diffusion)을 배우는 대신 "노이즈에서 정답 행동으로 가는 직선의 기울기"만을 심플하게 학습
5. 크로스 어텐션 레이어와 코잘 셀프 어텐션 레이어의 교차 배치(Interleaved Cross and Causal Self-Attention Layers)
Action Expert의 내부가 어떻게 생겼는지를 설명하는 핵심 디테일이다. Action Expert는 두 가지 정보를 동시에 처리해야 한다.
-
구조: 액션 전문가 내부의 트랜스포머 레이어는 두 가지 어텐션 메커니즘이 교차(Interleaved)되어 있음
- Cross-Attention: VLM 백본이 생성한 문맥(이미지+언어 정보)에 주목 (현재 상황 파악)
- 예시: "현재 큐브 위치는 어디인가?", "목표물의 위치는?"
- Causal Self-Attention: 생성하고 있는 행동의 순서(Action sequence)에 주목 (Action token끼리 서로 참조, 과거 액션으로 다음 액션 결정)
- 예시: "이전에 팔을 뻗었으니 이제 그리퍼를 열어야지", "그리퍼를 열었으니 물체를 집어야지"
-
효과: 이 두 레이어가 번갈아 배치됨(상황 파악→행동 계획 과정을 반복)으로써, 로봇은 '현재 상황(VLM의 지능)'을 반영하면서도 '물리적으로 말이 되는 연속 동작(Action Expert의 운동능력)'을 생성할 수 있게 된다.
[전체 흐름 요약]
입력(이미지/상태) → ① Projectors → ② Visual Tokens Reduction → ③ Layer Skipping →VLM → ④ Flow Matching Action Expert (⑤ Interleaved Attention) → 출력(행동)
- SmolVLA 아키텍처 구성 요소
| 순서 | 구성 요소 (Component) | 핵심 기능 (Key Function) | 효과 및 특징 (Benefit & Feature) |
|---|---|---|---|
| 1 | Projectors | 로봇의 상태(State), 행동(Action), 이미지 특징(Feature)을 VLM이 이해하는 벡터로 변환 | • 이질적인 데이터(물리 정보+시각 정보)를 하나의 언어 공간으로 통합 |
| 2 | Visual Tokens Reduction | 고해상도 이미지의 수많은 토큰을 핵심 정보만 남겨 단 64개로 압축 (Spatial Pooling) | • 소형 모델(SmolLM)의 연산 부담을 획기적으로 줄임 • 추론 속도 대폭 향상 |
| 3 | Layer Skipping | 비전 인코더(SigLIP)의 후반부 레이어를 건너뛰고, 초/중반부 특징만 사용 | • 로봇 제어에 불필요한 고차원 추상화 연산 생략 • 2배 빠른 시각 인코딩 속도 확보 |
| 4 | Flow Matching Action Expert | VLM의 판단을 이어받아 연속적인 행동 궤적(Continuous Trajectory)을 생성 | • 뚝뚝 끊기는 이산 토큰 대신 부드러운 움직임 생성 • 직선 경로(Vector Field) 학습으로 효율적 추론 |
| 5 | Interleaved Attention | 액션 전문가 내부에서 '문맥 파악(Cross)'과 '경로 생성(Causal)'을 번갈아 수행 | • VLM의 지능(상황 인식)과 물리적 일관성(동작 연결)을 동시에 확보 • 정교한 핸드-아이 코디네이션 구현 |
3.2. Pretraining data collected by the community
본 논문은 로봇 학습의 고질적인 문제인 '데이터 부족'과 '파편화'를 해결하기 위해, Hugging Face LeRobot 커뮤니티의 데이터를 활용한 대규모 표준화 파이프라인을 구축했다.
1. 배경: "데이터의 섬(Data Islands)"을 연결하라
-
문제의 본질: 로봇 데이터는 인터넷의 텍스트/이미지와 달리, 로봇의 하드웨어(카메라 위치, 팔의 자유도 등)가 다르면 서로 호환되지 않는 이질성(Heterogeneity)이 매우 크고, 이로 인해 각 연구실의 데이터가 고립되는 '데이터 섬' 현상이 발생해 왔음
-
커뮤니티의 잠재력: 최근 저가형 로봇(Aloha, SO-100 등)의 보급으로 개인이 수집한 데이터가 폭증하고 있습니다. 본 연구는 이 '정제되지 않은 야생의 데이터(In-the-wild Data)'가 오히려 로봇의 일반화(Generalization) 능력을 키우는 핵심 열쇠라고 판단
2. 데이터 선별 및 규모 (Data Curation)

-
규모: Hugging Face에 호스팅된 데이터 중 품질이 검증된 481개의 데이터셋을 선별
-
다양성: 이 데이터셋은 22종 이상의 다양한 로봇 형태(Embodiment)를 포함하며, 전문 연구실의 통제된 환경뿐만 아니라 일반 가정집, 차고 등 다양한 조명과 배경을 포함하고 있어 시각적 견고성(Visual Robustness)을 높이는 데 기여
3. [표준화 1] VLM을 활용한 작업 주석 개선 (Semantic Relabeling)
커뮤니티 데이터는 사용자가 임의로 라벨링하여 모호하거나, 문법에 맞지 않는 경우가 많았다.
-
해결책 (Qwen2.5-VL): 텍스트만으로 수정하는 것이 아니라, 시각-언어 모델(VLM)인
Qwen2.5-VL-3B-Instruct를 활용 -
방법론:
- 에피소드의 초기, 중간, 마지막 프레임을 샘플링하여 VLM에 보여줌
- VLM에게 "이 로봇이 수행한 행동을 간결한 영어 명령어로 요약해줘"를 요청
- 이를 통해 "문이 열려있음(State)"과 같은 상태 묘사가 아닌, "문을 열어라(Instruction)"와 같은 행동 지향적(Action-oriented) 텍스트로 라벨을 통일
4. [표준화 2] 카메라 시점 정규화 (Camera View Normalization)
로봇마다 카메라 개수(1개~N개)와 설치 위치, 이름(cam_high, wrist_cam 등)이 제각각인 문제를 해결해야 함
- 우선순위 매핑 전략 (Priority Mapping): 모델의 입력 채널(
OBS_IMAGE_1,2,3)을 고정하고, 정보량이 높은 순서대로 우선순위를 두어 매핑- 전역 시점 (Global/Top View) →
OBS_IMAGE_1: 작업 공간 전체를 조망하여 상황을 파악하는 데 가장 중요하므로 1순위로 배정. - 손목 시점 (Wrist View) →
OBS_IMAGE_2: 정교한 조작(Insertion 등)에 필수적이므로 2순위. - 측면/기타 시점 (Side/Aux View) →
OBS_IMAGE_3: 추가적인 정보를 제공.
- 전역 시점 (Global/Top View) →
- 자동화의 한계: "images.laptop" 처럼 이름만으로 위치를 알 수 없는 경우가 많아, 이번 연구에서는 수작업 매핑을 수행했으나, 향후 VLM을 이용한 자동 분류 가능성을 열어 둠.
3.3. Asynchronous inference
SmolVLA는 저사양 하드웨어에서도 50Hz 이상의 고주파 제어를 실현하기 위해, 로봇의 생각(Inference)과 행동(Execution)을 시간적으로 분리하는 비동기 추론 파이프라인을 제안한다.
1. 배경: 기존 방식들의 딜레마
현대의 로봇 정책은 하나의 관측()에서 Action Chunk, 를 한꺼번에 예측한다. 이를 실행하는 방식에는 크게 3가지가 있었으나 모두 한계가 명확했다.
-
전략 1: 개방형 루프 (Open-loop Execution)
◦ 방식: 행동 덩어리 전체(개)를 다 실행한 뒤에야, 멈춰서 다음 관측을 봄
◦ 문제: 스텝 동안 눈을 감고 움직이는 셈이라, 도중에 환경이 변해도 대처하지 못함 (반응성 부족). -
전략 2: 연속 추론 (Continuous Inference) + Temporal Ensembling
◦ 방식: 매 스텝마다 새로운 액션 청크를 예측하고, 겹치는 구간을 합침 (Sliding Window + Aggregation).
◦ 문제: 반응성은 좋지만, 매초 수십 번의 추론을 돌려야 하므로 고성능 GPU가 필수 요소. 엣지 디바이스에서 실행 불가능 -
전략 3: 동기식 추론 (Synchronous Inference)
◦ 방식: 액션 청크를 다 쓰면 멈추고, 다음 청크를 계산한 뒤 다시 움직임.
◦ 문제: 계산하는 동안 로봇이 멈춰있는 Blind Lag (멍하니 있는 시간)가 발생하여 움직임이 뚝뚝 끊김.
2. 제안: 비동기 추론 (Asynchronous Inference)
SmolVLA는 "생각하는 시간조차 아깝다, 움직이면서 생각하자"는 전략을 취한다.
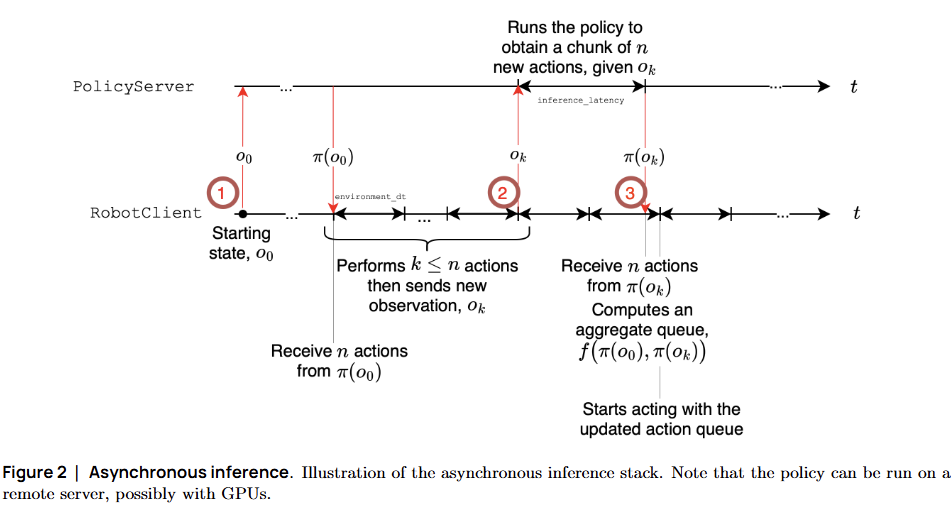
핵심 아이디어: 추론(Inference)과 실행(Execution)의 디커플링(Decoupling).
- Robot Client
: 현재 큐(Action Queue)에 쌓인 행동을 수행하는 데 집중. Queue가 비어가면 Policy Server에 새로운 관측 전송
- Policy Server
: 몸이 움직이는 동안 백그라운드에서 다음 행동(Action Chunk)을 미리 계산. 계산 완료 시 RobotClient로 결과 전송
- Non-blocking
: 계산 완료 시 큐에 자동 추가, 로봇은 계산 중에도 멈추지 않고 계속 움직임
3. 알고리즘 작동 원리 (Algorithm 1)

마치 ‘동영상 스트리밍 버퍼링’과 유사한 원리로 작동한다.
-
액션 큐 (Action Queue)
- 로봇이 수행할 행동들이 줄지어 대기하는 저장소.
- PopFront(): 큐에서 행동을 하나씩 꺼내 실행
-
임계값 트리거 (Threshold )
- 조건: (남은 액션 수 / chunk 크기 < 임계값)
- 큐에 남은 행동의 개수가 전체 크기의 일정 비율 밑으로 떨어지면 (예: chunk 크기가 10이고, 이면, 큐에 3개 미만 남았을 때 새 관측 캡처) 새로운 action chunk를 받기 위한 신호 전송
-
비차단 추론 (Non-blocking Inference)
- 신호를 받은 서버(PolicyServer)는 즉시 최신 관측()을 기반으로 다음 청크() 계산 시작
- 계산이 돌아가는 동안에도 로봇은 멈추지 않고 큐에 남아있는 잔여 행동을 계속 수행
-
병합 (Aggregation)
- 계산이 완료되면, 새로 나온 action chunk를 기존 큐의 남은 부분과 부드럽게 이어 붙임
- 새로운 action chunk 계산이 아직 끝나지 않은 경우(NOTCOMPLETED)에는 기존 큐를 그대로 유지
- 계산이 완료되면, 새로 나온 action chunk를 기존 큐의 남은 부분과 부드럽게 이어 붙임
4. Implementation Details
비동기 추론이 이론상 완벽하더라도, 실제 런타임에서 발생할 수 있는 중복 연산이나 큐 고갈(Starvation) 문제를 막기 위해 다음과 같은 안전장치를 마련했다.
1. 유사도 필터 (Similarity Filter)
로봇이 거의 움직이지 않았는데도 계속해서 똑같은 추론을 반복하는 것은 리소스 낭비다. 이를 방지하기 위한 거름망이다.
- 목적: 불필요한 서버 호출을 막고, 중복된 액션 청크로 인해 로봇이 제자리에서 떠는 현상을 방지한다.
- 작동 원리 (Joint-space Comparison):
- 무거운 이미지를 비교하는 대신, 가벼운 관절 공간(Joint-space) 데이터를 사용한다.
- 현재 관측과 이전 관측 사이의 거리가 임계값 미만이면, "상황이 변하지 않았다"고 판단하여 추론을 건너뛴다.
- 예외 처리 (Safety Override): 단, 액션 큐가 완전히 비어갈 위기라면, 상황이 변하지 않았더라도 강제로 추론을 수행하여 로봇이 멈추는 것을 최우선으로 막는다.
2. 지연 시간 분석 (Latency Analysis)
"로봇이 멈추지 않으려면, Action을 언제 미리 Inference해야 할까?"에 대한 수학적 증명이다.
- 전체 지연 시간 () 은 다음 세 가지 요소의 합이다.
(전체 지연 = : RobotClient → RobotServer 관측 전송 시간 + : PolicyServer 추론 시간 + PolicyServer → RobotClient 액션 전송 시간)
-
가정: 네트워크 전송 시간은 매우 짧으므로 무시하고, 추론 시간()을 핵심 변수로 본다. ()
-
큐 고갈 방지 조건 (Anti-Starvation Condition):
로봇이 멈추지 않으려면, "남은 Action Chunk의 양(Buffer)"이 "새 Action Chunk를 만드는 시간(Latency)"보다 커야 한다. 런타임에서 큐 고갈 방지 조건을 수식으로 정의하면 다음과 같다.
- : 임계값 비율 (0~1)
- : 추론 시간
- : 제어 주기 (예: 33ms)
- : 청크 크기 (한번에 생성하는 Action의 양
의미: 이 조건을 만족하도록 를 설정하면, 로봇은 절대 멈추지 않는다.
3. 처리 빈도 (Processing Frequency)
유사도 필터가 적용되었을 때 시스템이 얼마나 효율적으로 변하는지 보여준다.
- 필터 없을 때: (1) 관측 전송 주기 - 매 초마다 RobotClient가 PolicyServer 관측 전송 (2) 액션 청크 수신 주기 - 초마다 RobotClient가 PolicyServer로부터 새 액션 청크 수신
- 필터 적용 시: 상황이 변하지 않으면 호출을 건너뛰므로, 실질적인 처리 주기가 늘어난다. 즉, 큐가 줄어드는 속도보다 추론 주기가 길어져 시스템 리소스를 아끼면서도 큐가 마르지 않게 유지한다.
5. 임계값 에 따른 동작 시나리오
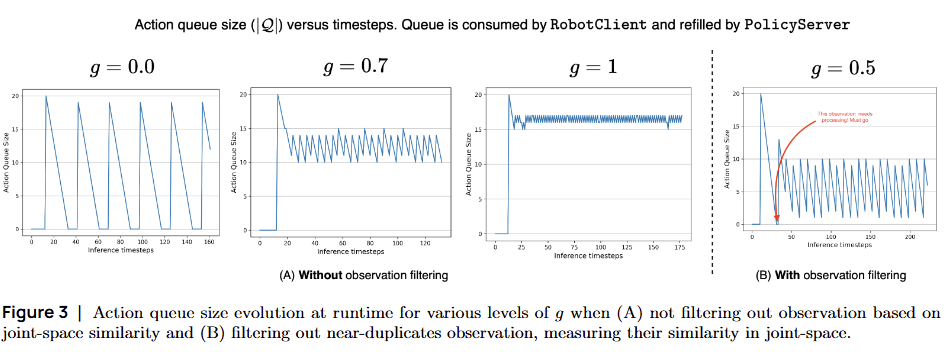
g = 0: 순차적 한계 (Sequential Limit)
동작:
- 클라이언트가 전체 청크를 완전히 소진한 후에만 새로운 관측 전송
- 다음 청크를 계산하는 왕복 지연시간 동안 큐가 완전히 비어있음
결과:
- 로봇이 행동할 수 없는 상태 발생
- 완전히 순차적인 배포 방식을 재현
- 평균 초의 유휴 시간 발생 (Blind Lag)
특징: 계산 효율적이지만 반응성 최악
g = 0.7: 비동기 추론 (Asynchronous Inference) - 권장
동작:
- 큐 의 약 30% ()를 소비한 후 새로운 액션 큐 추론 트리거
- 계산을 분산시키면서도 큐가 비는 것을 방지
결과:
- 연속적인 청크 간 겹침이 모델링 오류에 대한 버퍼 역할
- 의 계산 비용 없이 적절한 반응성 확보
- 업데이트된 큐 는 과 사이의 겹치는 타임스텝에서 집계(aggregation)
특징: 반응성과 계산 효율의 최적 균형점
g = 1: 계산 집약적 한계 (Compute-intensive Limit)
동작:
- 매 타임스텝마다 새로운 관측 전송
- 큐는 거의 항상 채워져 있음 ( 로 인한 약간의 톱니 모양만 존재)
결과:
- 최대한 반응적 (maximally reactive)
- 제어 틱당 하나의 forward pass 필요 → 제한된 하드웨어에서 엄청난 계산 부담
- 클라이언트가 액션을 소비하는 동안 서버가 계산하므로, 큐가 다시 완전히 채워지지는 않음
6. 주요 이점(Key Advantages)
- 지연 시간 제거 (Zero Perceived Latency):
- 추론 시간이 실행 시간보다 짧기만 하면, 로봇 입장에서는 끊김이 전혀 느껴지지 않음
- 계산 시간(Lag)이 실행 시간 뒤로 완벽하게 은폐(Hidden)됨
- 리소스 효율성 (Resource Efficiency):
- 매 스텝 계산할 필요 없이, 큐가 비어갈 때만 계산하면 되므로 연산량 크게 감소 →엣지 디바이스 구동의 핵심
- 유사도 필터(Similarity Filter)를 통해 불필요한 추론 방지 (
NEEDSPROCESSING)
- 높은 적응성 (Adaptability):
- Open-loop처럼 끝까지 기다리지 않고, 큐가 빌 때마다 수시로(Frequency) 관측을 업데이트하므로 돌발 상황에도 빠르게 대처 가능
- 임계값 선택 () 을 통해 리소스 예산 대비 반응성 사이 균형 조절 가능
7. 핵심 통찰 (Key Insight)
"계산 지연(Inference Latency)을 실행 시간(Execution Time) 뒤로 숨긴다"
비동기 추론의 핵심은 계산 시간을 없애는 것이 아니라, 로봇이 움직이는 동안 계산을 수행함으로써 지연을 체감할 수 없게 만드는 것.
트레이드오프 관리:
- 작은 값 : 유휴 기간 발생 (계산 효율적, 반응성 낮음)
- : 매우 정확한 모델 가정 필요, 상당한 계산 비용 (반응성 최고, 계산 집약적)
- 실용적 선택: 로 반응성과 리소스 효율 사이 균형 확보
이는 마치 동영상을 시청하면서 다음 장면을 미리 버퍼링하는 것과 같은 원리
4. Experiments
4.1 Experimental setup
1. 데이터 수집 및 학습 설정 (Data Collection & Training)
- 시뮬레이션: Meta-World 벤치마크를 위해 50개 작업당 50개의 시연(Demonstration)을 포함하는 새로운 데이터셋을 수집했다.
- 실제 환경
- SO-100 로봇 팔: 3개의 조작 작업 데이터셋 수집.
- SO-101 로봇 팔: 1개의 조작 작업 데이터셋 수집.
- 구성: 각 데이터셋은 5개의 서로 다른 시작 위치에서 10번씩 수행하여, 작업당 총 50개의 시연으로 구성
- 학습 모드: 별도의 명시가 없는 한, SmolVLA는 모든 작업을 동시에 배우는 멀티태스크(Multitask) 설정으로 학습됨
2. 평가 지표 (Evaluation Metrics)
평가 환경의 특성에 따라 성공 여부를 판단하는 방식을 다르게 적용했다.
- 시뮬레이션 (Binary): 작업 완료 여부만 판단. (성공=1, 실패=0)
- 실제 환경 (Fine-grained): 현실의 복잡성을 고려하여, 작업을 하위 단계(Subtask)로 쪼개어 부분 점수를 부여.
예시(Pick-and-Place): 물체를 집음(0.5점) + 목표에 놓음(0.5점) = 총 1.0점
3. 시뮬레이션 벤치마크 (Simulated Environments)
두 가지의 공신력 있는 멀티태스크 벤치마크를 사용했다.
- (1) LIBERO: 로봇의 다양한 능력을 4가지 카테고리로 평가
- 구성: Spatial(공간), Object(객체), Goal(목표), Long(장기 작업) 등 총 40개 작업
- 데이터: 1,693개 에피소드 사용
- (2) Meta-World: 작업의 난이도별 일반화 성능을 평가
- 구성: Easy부터 Very Hard까지 50개 작업
- 데이터: 2,500개 에피소드 사용
4. 실제 환경 작업 (Real-world Tasks)
Hugging Face에 전면 공개된 4개의 데이터셋을 사용해 평가를 진행
핵심 포인트: Task 4에 사용된 SO-101 로봇 데이터는 사전 학습(Pre-training) 단계에서 모델이 단 한 번도 본 적이 없다. 모델의 진정한 일반화(Generalization) 능력을 테스트하기 위함

4.2 Robots
다양한 플랫폼을 사용하여 실험함으로써 SmolVLA의 로봇 구현체 간 일반화 능력(cross-embodiment generalization)을 검증한다.
실제 환경: 접근성과 비용 효율성
- SO-100/SO-101: 저비용 오픈소스 플랫폼으로 연구 접근성 향상
- 3D 프린팅 가능하여 누구나 복제 가능
- 중요: SmolVLA는 SO-101에 대한 사전학습 없이도 일반화 능력 입증
시뮬레이션: 다양성과 정밀도
- Panda (LIBERO): 정밀한 토크 제어로 복잡한 조작 학습
- Sawyer (Meta-World): 다양한 난이도의 50개 작업으로 일반화 평가
| 로봇 | 자유도 | 제어 방식 | 환경 | 특징 |
|---|---|---|---|---|
| SO-100 | 6 DOF | 위치 제어 | 실제 환경 | 저비용, 3D 프린팅, 오픈소스 |
| SO-101 | 6 DOF | 위치 제어 | 실제 환경 | SO-100 개선, 더 부드럽고 정밀 |
| Panda | 7 DOF | 토크 제어 | LIBERO 시뮬레이션 | 고정밀, 컴플라이언트 제어 |
| Sawyer | 4 DOF | 위치 제어 | Meta-World 시뮬레이션 | 그리퍼 상태 제어 |
4.3 Implementation details
본 섹션에서는 SmolVLA를 재현하거나 학습시키는 데 필요한 구체적인 학습 레시피, 하드웨어 설정, 그리고 최적화 기법을 상세히 기술한다.
1. 실험 프레임워크 (Framework)
- 라이브러리: LeRobot (Cadene et al., 2024)
Hugging Face 팀이 주도하는 PyTorch 기반의 오픈소스 로보틱스 라이브러리로, 데이터 로딩부터 학습, 로봇 제어까지 통합된 환경을 제공
2. 모델 아키텍처 세부 설정 (Model Specifics)
전체 450M 파라미터 중, 실제로 학습되는 부분은 극히 일부(약 22%)에 불과하다.
-
VLM 백본 (Frozen)
- 모델: SmolVLM-2 (Marafioti et al., 2025)
- 설정: 가중치를 동결(Frozen)하여 학습하지 않음. 또한, 경량화를 위해 LLM의 처음 16개 레이어만 사용
- 입력: 이미지 크기를 512×512로 리사이즈하여 사용
-
Action Expert (Trainable)
◦ 역할: Flow Matching을 통해 개의 액션 청크를 생성
◦ 설정: 오직 이 모듈(약 1억 개 파라미터)만 학습
◦ 추론: 실제 동작 시에는 10 Step의 고정된 스텝으로 적분
3. 학습 설정 (Training Configuration)
학습은 크게 사전 학습(Pre-training)과 파인튜닝(Fine-tuning)으로 나뉘며, 효율적인 학습을 위해 검증된 하이퍼파라미터를 사용한다.
| 구분 | 사전 학습 (Pre-training) | 파인튜닝 (Fine-tuning) |
|---|---|---|
| 데이터 | 모든 커뮤니티 데이터셋 | 시뮬레이션 / 실제 작업 데이터 |
| 학습 스텝 | 200,000 Steps | 100,000 ~ 200,000 Steps |
| 배치 크기 | 256 (Global) | 64 |
| GPU | 4 GPUs (큰 배치 수용) | 단일 GPU 가능 |
- (참고) 실제로는 20만 스텝보다 훨씬 적게 학습해도 성능 저하 없이 충분함이 관찰됨
- 옵티마이저 : AdamW ()
- 학습률 스케줄 : Cosine Schedule (Warmup 100 steps, 시작 최소 )
4. 효율화 최적화 기법 (Efficiency Optimizations)
컴팩트한 모델 크기에 더해, 4가지 기법을 추가 적용하여 학습 속도를 극한으로 끌어올렸다.
(1) 정밀도 (Precision): bfloat16을 사용하여 메모리 사용량을 줄이고 연산 속도 향상
(2) 컴파일 (Compilation): torch.compile()을 통해 PyTorch 코드를 최적화된 커널로 JIT 컴파일하여 실행 속도 향상
(3) 데이터 호환성: 고정된 시퀀스 길이와 배치 크기를 유지하며, 배치를 꽉 채우지 못하는 자투리 프레임은 과감히 폐기(Drop)하여 연산 효율성 보장
(4) 분산 학습: Hugging Face Accelerate 라이브러리를 통해 멀티 GPU/노드 학습 및 혼합 정밀도(Mixed Precision)를 손쉽게 적용
5. 추론 모드 (Inference Mode)
실험 환경에 따라 추론 방식을 다르게 적용했다.
- 시뮬레이션: 비동기식 추론(Asynchronous) 적용 (매 스텝 관측 샘플링 및 예측)
- 실제 환경: 동기식 추론(Synchronous) 적용 (안정성을 위해 액션 청크를 모두 실행한 후 다음 관측 샘플링)
6. 비용 및 철학 (Cost & Philosophy)
- 총 계산 비용: 프로젝트 전체에 약 30,000 GPU hours가 소요되었다.
- 설계 철학:
- 효율성(Efficiency): 450M의 작은 크기와 최소한의 토큰
- 실용성(Practicality): 단일 GPU로도 학습 가능한 가벼움
- 확장성(Scalability): 분산 학습 지원 및 메모리 효율성 극대화
4.4 Baselines
SmolVLA의 성능을 검증하기 위해, 현재 로봇 학습 분야를 대표하는 두 가지 상반된 성격의 강력한 모델, (Pi-Zero)와 ACT를 비교 대상으로 선정했다.
1. (Pi-Zero):
- 최신 트렌드인 VLA (Vision-Language-Action) 모델
- 스펙:
- 기반: 구글의 PaliGemma (3B) 모델 베이스
- 크기: 약 33억 개(3.3B) 파라미터 (SmolVLA보다 7배 이상 큼)
- 학습: 10,000시간 분량의 고품질 로봇 데이터를 사용하여 대규모 사전 학습
- 특징:
◦ SmolVLA와 마찬가지로 Flow Matching을 사용하여 액션을 생성
◦ 3개의 이미지, 로봇 상태, 언어 지시를 모두 이해하는 강력한 일반화 능력- SmolVLA의 목표: "이 거대한 모델의 성능을 1/7 크기로 얼마나 따라잡을 수 있는가?"
2. ACT (Action Chunking with Transformers):
- 언어 능력 없이 오직 '행동 복제'에 집중한 CVAE (Conditional Variational Autoencoder) 기반 모델
- 스펙:
- 구조:
ResNet(비전)+Transformer(인코더-디코더)조합- 크기: 약 8천만 개(80M) 파라미터 (SmolVLA보다 5.6배 작음)
- 학습: ImageNet으로 사전 학습된 비전 인코더 외에는, 로봇 작업을 위해 바닥부터(From scratch) 학습
- 특징:
- 언어 이해 불가능: 오직 시각 정보(RGB)와 로봇 상태만으로 작동
- 단순하고 효율적인 구조로 특정 작업(Specialized Task)에서 높은 성능
- SmolVLA의 목표: "이 모델보다 훨씬 똑똑하면서(언어 이해), 멀티태스킹도 잘할 수 있는가?"
베이스라인 비교 요약
| 특성 | SmolVLA (본 논문) | π₀ (Pi-Zero) | ACT |
|---|---|---|---|
| 파라미터 수 | 450M (중형) | 3.3B (대형) | 80M (초소형) |
| 모델 유형 | VLA (VLM+Action) | VLA | CVAE Policy |
| 입력 데이터 | RGB + 상태 + 언어 | 3 RGB + 상태 + 언어 | RGB + 상태 (언어 ✗) |
| 액션 생성 | Flow Matching | Flow Matching | CVAE (Regression) |
| 학습 방식 | Action Expert만 학습 (VLM 동결) | 전체 모델 학습 | 전체 모델 학습 |
| 사전학습 데이터 | 481개 커뮤니티 데이터 (저비용/고효율) | 10,000시간 로봇 데이터 (고비용/고품질) | ImageNet (Vision only) (작업별 별도 학습) |
4.5 Main results
1. 시뮬레이션 평가 (Simulation Evaluation)
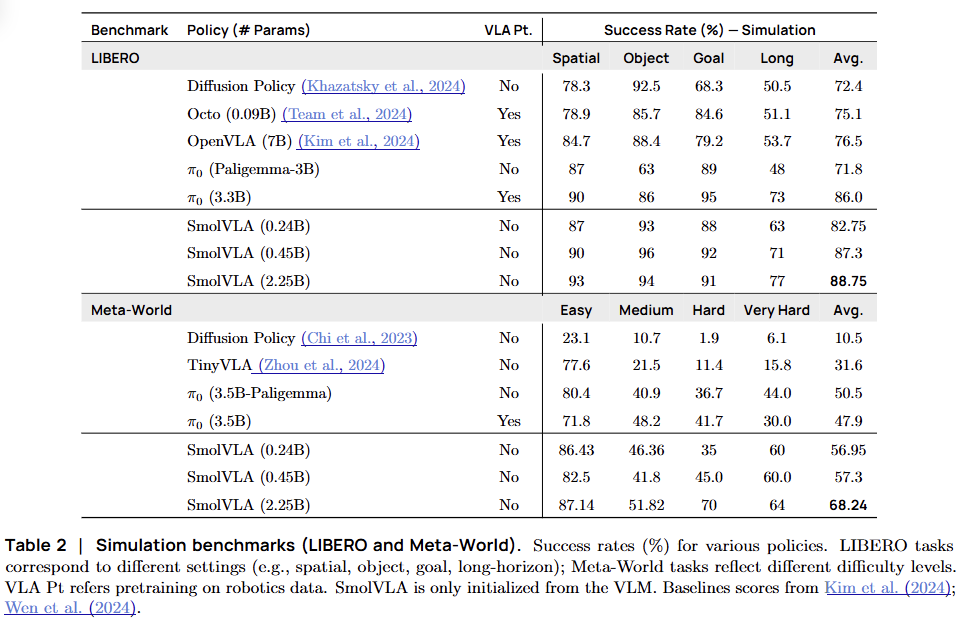
LIBERO(40개 작업)와 Meta-World(50개 작업) 벤치마크에서 평가를 진행
- VS. 기존 VLA 모델들:
- 모든 벤치마크에서 Octo, OpenVLA, Diffusion Policy 등 쟁쟁한 베이스라인들을 능가
- VS. (Pi-Zero):
- 초기화 버전 (-VLM-init): 로봇 데이터 사전 학습 없이 VLM 가중치만 가져온 를 압도
- 사전 학습 버전 (-Robotics-pretrained): 대규모 로봇 데이터로 사전 학습된 와 비교해도 대등한 수준(Comparable)의 성능
[효율성 비교: SmolVLA vs. ]
| 구분 | SmolVLA (450M) | π0 (3.3B) | 결과 |
|---|---|---|---|
| 학습 속도 | 빠름 🚀 | 느림 | SmolVLA가 40% 더 빠름 |
| 메모리 | 적음 📉 | 많음 | SmolVLA가 6배 적게 사용 |
2. 실제 환경 평가 (Real-World Evaluation)
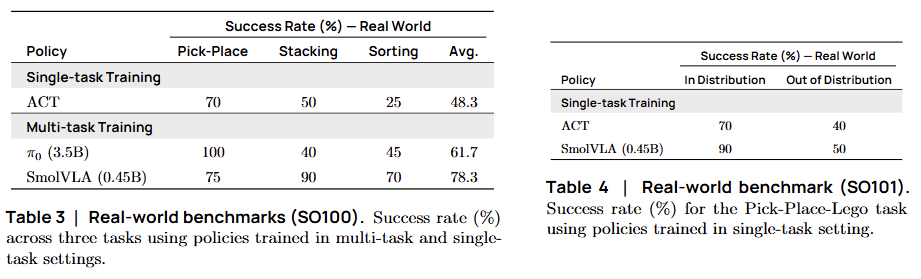
A. SO-100 벤치마크 (표준 성능 테스트)
4가지 조작 작업을 수행하며 3개 데이터셋으로 학습
- VS. ACT: 작업마다 따로따로 학습시킨(Specialist) ACT보다, 멀티태스킹으로 학습된 SmolVLA가 더 우수함
- VS. : 파라미터가 7배나 많은 보다 더 높은 성공률을 기록
B. SO-101 벤치마크 (일반화 테스트)
SmolVLA가 한 번도 본 적 없는 로봇(SO-101)과 낯선 환경(OOD)에서 테스트
- In-Distribution (ID): 학습 환경과 유사한 조건에서도 ACT를 능가
- Out-of-Distribution (OOD): 레고 블록을 엉뚱한 위치에 두는 등 변수를 주었을 때, ACT는 무너졌지만 SmolVLA는 견고하게 작업을 수행
3. 성공 요인 분석 (Ablation Study)
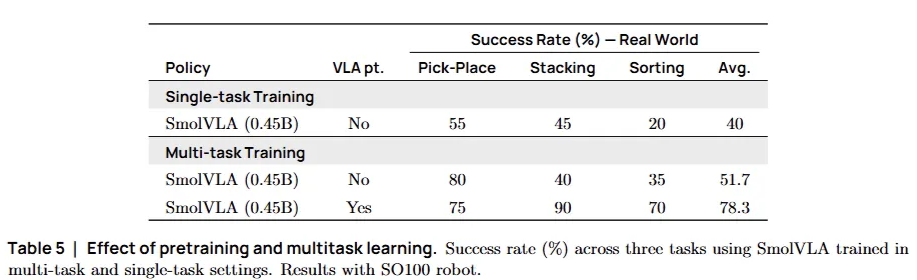
-
커뮤니티 데이터의 힘: "인터넷에 널린 잡다한 로봇 데이터"라고 무시했던 커뮤니티 데이터가, 실제로는 성능을 1.5배 높여 주는 핵심 비결
-
멀티태스크 효과: 여러 작업을 동시에 배우는 과정에서 지식 전이(Knowledge Transfer)가 일어나, 단일 작업을 배울 때보다 성능이 더 좋아짐
4.6 Asynchronous inference
두가지 추론 모드(동기vs비동기)를 비교 평가
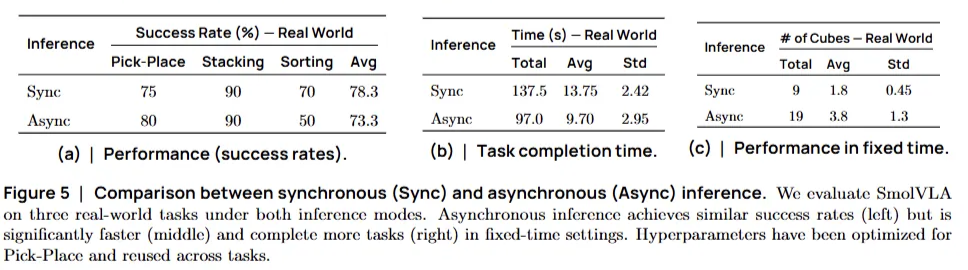
평가 방법 (Evaluation Methodology)
실제 로봇(Pick-Place 과제)을 사용하여 다음 세 가지 지표를 측정했다.
- 성공률 (Success Rate): 작업을 얼마나 잘 완수하는가?
- 작업 속도 (Completion Time): 한 번 성공하는 데 몇 초가 걸리는가?
- 처리량 (Throughput): 제한 시간(60초) 내에 몇 번이나 성공하는가?
실험 결과: 압도적인 속도 차이 (Quantitative Results)
(a) 성공률: 동등한 성능 (Tie)
- 결과: 두 모드 모두 유사한 성공률을 기록했습니다 (Figure 5a)
- 의미: 비동기 모드가 빠르다고 해서 대충 하는 것이 아니라, 정확도는 그대로 유지됨을 증명
(b) 작업 완료 시간: 30% 더 빠름 (Speed)
- 동기 모드: 평균 13.75초 소요
- 비동기 모드: 평균 9.7초 소요
- 결과: 멍하니 기다리는 시간(Lag)이 사라져 전체 작업 속도가 약 30% 단축
(c) 시간 내 처리량: 2배 이상 (Throughput)
- 실험: 60초 동안 큐브를 얼마나 많이 옮기는지 테스트
- 동기 모드: 9회 성공
- 비동기 모드: 19회 성공
- 결과: 연속적인 움직임 덕분에 동일 시간 내에 2배 이상의 작업을 수행
정성적 관찰: 더 똑똑한 적응력 (Qualitative Observations)
숫자로 보이는 속도 외에도, 로봇의 행동 패턴에서 질적인 차이가 발견되었다.
- 빠른 반응성 (Faster Reactions): 동기 모드는 액션 청크를 다 쓸 때까지 눈을 감고 있는 셈(Blind)이지만, 비동기 모드는 끊임없이 관측을 업데이트
- 높은 적응성 (Better Adaptability): 작업 도중에 사람이 물체를 툭 건드리거나(External Disturbances) 위치를 바꿔도, 비동기 모드는 즉각적으로 경로를 수정하여 유연하게 대처
- 결론: 단순한 속도 향상을 넘어, 예측 불가능한 동적 환경(Dynamic Environment)에서의 생존 능력이 향상
5 Discussion
본 논문은 일반 소비자급 하드웨어에서도 구동 가능하며, 거대 모델들과 대등하게 경쟁할 수 있는 '작지만 강력한(Small but Mighty)' 로봇 모델, SmolVLA를 제안했다.
1. 주요 기여 (Key Contributions)
SmolVLA가 로봇 학계와 커뮤니티에 남긴 핵심 발자취는 다음과 같다.
- 효율적 아키텍처: 성능(성공률)을 희생하지 않으면서도, 누구나 학습시키고 돌릴 수 있는 가벼운 구조
- 비동기 추론 스택 (Asynchronous Inference): 로봇이 생각하느라 멈추지 않게 하는 범용 기술을 제안. 이는 SmolVLA뿐만 아니라 어떤 정책(Policy) 모델에도 적용 가능한(Model-agnostic) 기술
- 철저한 분석: 맹목적인 모델링이 아니라, 소거 연구(Ablation Study)를 통해 각 부품이 왜 필요한지 실무자들에게 가이드라인을 제공
- 완전한 재현성 (Reproducibility): 모델 가중치뿐만 아니라 코드, 데이터, 심지어 로봇 하드웨어 설계도까지 전부 오픈소스로 공개
2. 한계점 및 향후 연구 방향 (Limitations & Future Directions)
저자들은 SmolVLA의 현재 한계를 7가지 측면에서 명확히 하고, 이를 해결하기 위한 구체적인 미래 연구 방향을 제시했다.
① 데이터의 한계 (Diversity & Scale)
- 주로 단일 로봇(SO-100) 데이터와 약 23,000개의 적은 궤적만 사용했다. (OpenVLA는 100만 개)
- 다양한 로봇 형태(Cross-Embodiment) 데이터를 통합하고 데이터 규모를 늘려, 더 범용적인 일반화 능력을 확보해야 한다.
② 모델 백본의 적합성 (VLM Backbone)
- 사용된 SmolVLM-2는 주로 문서 판독(OCR)용으로 학습된 모델이다.
- 로봇의 물리적 상호작용에 특화된 '로봇 전용 VLM 백본'을 개발하거나 탐색할 필요가 있다.
③ 멀티모달 학습의 부재 (Multimodal Co-training)
- 로봇 데이터만 편식해서 학습했다.
- 인터넷상의 광범위한 비전-언어 데이터를 로봇 데이터와 함께 학습(Joint Training)시켜, 로봇의 시각적 이해력과 지시 이행 능력을 강화해야 한다.
④ 작업 복잡도의 한계 (Long Horizon)
- "큐브 집기" 같은 짧은 호흡의 작업에는 강하다.
- "주방 청소하고 설거지해" 같은 장기 과제(Long-horizon Tasks)를 수행하기 위해, 작업을 잘게 쪼개 관리하는 계층적 정책(Hierarchical Policies)이나 계획(Planning) 모듈이 필요하다.
⑤ 학습 방법론의 확장 (Imitation vs. RL)
- 전문가의 행동을 흉내 내는 모방 학습(Imitation Learning)에 의존한다. 이는 스승(데이터)보다 잘할 수 없다는 한계가 있다.
- 시행착오를 통해 스스로 깨우치는 강화 학습(Reinforcement Learning, RL)을 도입하여, 데이터에 없는 상황에서도 적응하는 능력을 길러야 한다.
⑥ 하드웨어 효율성과 성능의 trade-off
- 5억 개 미만(<0.5B)의 파라미터로 효율성을 극대화했다.
- 효율성을 유지하면서도 더 복잡한 문제를 풀기 위해 아키텍처를 조금 더 확장하는 최적의 균형점(Trade-off)을 계속 찾아야 한다.
