CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models (2025)
reading papers
Nvidia, Stanford, MIT CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models (CVPR 2025)의 논문 내용 정리
CoT-VLA
[paper]
[project page]
Abstract
Vision-Language-Action Models (VLA)은 일반화 가능한 감각 운동 제어(Sensorimotor Control)를 학습하기 위해 사전 학습된 Vision-Language Models(VLM)과 다양한 Robot Demonstrations을 활용하는 데 있어 잠재력을 보였다. 이러한 패러다임은 로봇 및 비로봇 소스(Source)의 대규모 데이터를 효과적으로 활용하지만, 현재의 VLA들은 주로 복잡한 Manipulation Tasks에 필수적인 중간 추론 단계가 결여된 채 직접적인 입력-출력 매핑(Input-Output Mappings)에 초점을 맞추고 있다. 그 결과, 기존 VLA들은 시간적 계획(Temporal Planning)이나 추론 능력(Reasoning Capabilities)이 부족하다.
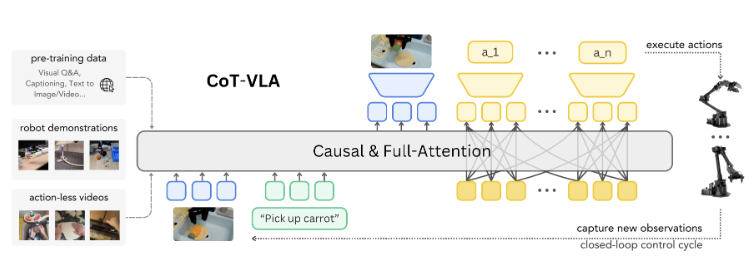
본 논문에서는 이러한 목표를 달성하기 위해 짧은 행동 시퀀스(Action Sequence)를 생성하기 전, 미래 이미지 프레임(Future Image Frames)을 시각적 목표로서 Autoregressive하게 예측함으로써 명시적인 Visual Chain-of-Thought(CoT) 추론을 VLA에 통합하는 방법을 소개한다.
본 논문은 시각 및 행동 토큰(Tokens)을 이해하고 생성할 수 있는 SOTA 7B 파라미터 규모의 VLA인 CoT-VLA를 소개한다. 본 논문의 실험 결과에 따르면, CoT-VLA는 Real-world Manipulation Tasks에서 17%, Simulation Benchmarks에서 6%의 성능 향상을 기록하며 기존 SOTA VLA 모델을 능가하는 강력한 성능을 달성함을 입증한다.
1. Introduction
로봇 학습 분야의 최근 발전은 다양한 작업과 환경 전반에서 작동할 수 있는 정책(Policy)을 훈련하는 데 있어 인상적인 진전을 보여주었다 [1, 3, 5, 12, 14, 18, 29, 36, 44, 45, 48, 54, 59, 63, 66, 70, 76, 78]. 유망한 연구 방향 중 하나는 비전-언어-행동(Vision-Language-Action, VLA) 모델로, 이는 사전 학습된 Vision-Language Models(VLMs)의 풍부한 이해 능력을 활용하여 자연어 지시와 시각적 관측을 로봇 행동으로 매핑한다 [12, 29, 48]. 로봇 데모(Robot Demonstrations) 데이터로 VLM을 학습시킴으로써, VLA는 다양한 장면, 객체, 자연어 지시를 이해하는 능력을 계승하게 되며, 이는 다운스트림 테스트 시나리오를 위해 파인튜닝되었을 때 더 우수한 일반화 능력으로 이어진다.
이러한 접근법들이 인상적인 결과를 보여주었으나, 일반적으로 해석 가능성(Interpretability)과 잠재적인 성능을 향상시킬 수 있는 명시적인 중간 추론 단계 없이 관측에서 행동으로 직접 매핑하는 방식을 취한다. 언어 도메인에서는 Chain-of-Thought(CoT) 프롬프팅이 단계별 사고를 유도함으로써 거대 언어 모델(Large Language Models, LLMs)의 추론 능력을 향상시키는 강력한 기법으로 부상했다 [62, 75].
이러한 개념을 로봇 공학에 적용하는 것은 텍스트, 시각적 관측, 물리적 행동에 추론을 그라운딩(Grounding)할 수 있는 흥미로운 기회를 제공한다. 최근 연구들은 언어적 설명, 키포인트(Keypoints), 또는 바운딩 박스와 같은 중간 추론 단계를 통합하며 이 방향으로의 진전을 이루었다 [15, 44, 45, 63]. 이러한 중간 표현들은 장면, 객체, 작업의 추상화된 상태를 포착하며, 추가적인 전처리 파이프라인을 필요로 한다.
본 논문은 행동 생성 이전의 중간 추론 단계로서 서브골 이미지(Subgoal Images)를 탐구한다. 이러한 이미지들은 모델의 추론 과정 상태를 포착하며, 로봇 데모 데이터셋 내에서 자연스럽게 확보할 수 있다.
선행 연구들이 Goal-Conditioned Imitation Learning을 탐구하였으나 [2, 11, 46, 55], 이러한 개념을 Chain-of-Thought 추론 단계로서 VLA와 통합한 것은 본 연구가 최초이다. 본 논문은 로봇 작업을 위한 생각의 사슬 추론의 한 형태로 서브골 이미지 생성을 활용하는 새로운 방법인 VLA를 위한 Visual Chain-of-Thought 추론을 제안한다.
행동을 직접 예측하는 대신, 본 방법론은 먼저 로봇의 계획된 상태를 픽셀 공간상에서 나타내는 서브골 이미지를 생성한 후, 현재의 관측과 생성된 서브골 이미지 모두를 조건(Condition)으로 하여 행동을 결정한다. 이러한 접근 방식은 모델이 행동하기 전에 과제를 수행하는 방법에 대해 "시각적으로 생각"할 수 있게 한다. 서브골 이미지를 중간 추론 단계로 사용함으로써, 본 논문은 최소한의 전처리만으로 로봇 조작 데이터에 이미 존재하는 정보를 활용한다.
또한, subgoal image 생성은 행동 주석(Action Annotations)을 필요로 하지 않으므로, 향상된 시각적 추론 및 이해를 위해 풍부한 비디오 데이터를 활용할 수 있는 잠재력을 열어준다.
본 논문은 텍스트와 이미지를 이해하고 생성할 수 있는 통합 멀티모달 파운데이션 모델(Multimodal Foundation Models)의 최근 발전 [39, 58, 61, 67, 69]을 기반으로 시각적 생각의 사슬 추론을 활용하는 CoT-VLA 시스템을 구축한다. 본 논문은 베이스 모델 [67]을 Open X-Embodiment 데이터셋 [48]과 행동 정보가 없는(Action-less) 비디오 데이터셋 [20, 27] 모두에서 학습시킨 후, 배포 및 평가에 사용되는 다운스트림 로봇 환경에서 수집된 작업 데모를 통해 모델을 파인튜닝한다.
본 논문은 CoT-VLA를 위한 Hybrid Attention Mechanism을 설계한다. 텍스트 및 이미지 생성에는 Next-token Prediction을 위한 Causal Attention을 사용하고, 모든 Action Dimensions을 한 번에 예측하기 위해서는 풀 어텐션(Full Attention)을 활용한다.
또한, 로봇 학습 분야의 최근 발전 [10, 17, 77]에서 영감을 받아, 매 타임스텝마다 단일 행동이 아닌 일련의 행동 시퀀스(Action Chunking)를 예측한다. 본 논문은 액션 청킹과 하이브리드 어텐션 메커니즘 모두가 모델의 성능을 향상시킨다는 점을 입증한다. 시뮬레이션 벤치마크 [37]와 실제 환경(Real-world) 실험 [48, 60]에서의 광범위한 실험을 통해, 본 논문은 시각적 생각의 사슬 추론이 기존 VLA 접근법 대비 정책 성능을 향상시키는 데 기여함을 입증한다.
본 논문의 주요 기여는 다음과 같다:
- 로봇 제어(Robotic Control)를 위한 중간 추론 단계로서 서브골 이미지 생성을 통한 시각적 생각의 사슬 추론 방법을 소개한다.
- 시각적 생각의 사슬 추론을 통합한 시스템인
CoT-VLA와, 픽셀 및 텍스트 생성을 위한 코잘 어텐션과 행동 예측을 위한 풀 어텐션을 결합한 하이브리드 어텐션 메커니즘을 소개한다. - 시뮬레이션과 실제 환경 모두에서 포괄적인 평가를 수행하여 시각적 생각의 사슬 추론이 VLA 성능을 향상시킴을 입증하며, 본 시스템이 다수의 로봇 플랫폼과 작업 전반에서 최고 수준의 성능(SOTA)을 달성함을 보인다.
2. Related Works
Chain-of-Thought (CoT) Reasoning
CoT 추론은 자연어 처리 분야에서 두각을 나타내고 있으며, 특히 문제 해결 과정을 순차적이고 설명 가능한 단계로 분해하여 모델이 복잡한 다단계 추론 과제를 수행할 수 있게 하는 데 있어 그 중요성이 커지고 있다. CoT 추론에 관한 초기 연구 [62]는 LLM이 최종 답변에 도달하기 전에 중간 추론 단계(Intermediate Reasoning Steps)를 생성하도록 프롬프팅하는 방식의 효과를 입증했다.
이러한 패러다임을 시각 도메인으로 확장하여, 연구자들은 멀티모달 생각의 사슬 방법론을 탐구해 왔다. 이 방법론에서는 바운딩 박스 생성 [53], Stable Diffusion [50]이나 표준 Python 패키지 [24]를 이용한 중간 이미지 인페인팅(Image Infillments), 또는 CLIP Embedding 생성 [22]을 포함하여, 미래의 결과나 상태를 추론하기 위해 시각 정보를 단계별로 반복 처리한다.
최근에는 Embodied Applications에서도 CoT 추론이 탐구되고 있다. 이는 다단계 실행을 위한 텍스트 계획 [44, 45]이나 포인트 궤적(Point Trajectories) [63]을 생성할 수 있고, 추가적인 관측(Observations)으로서 객체의 바운딩 박스와 그리퍼 위치(Gripper Positions)를 레이블링 [44]할 수 있으며, 오픈 루프(Open-loop) 추종을 위한 미래 이미지 궤적 생성 [35, 47]이나 강화학습(Reinforcement Learning)을 위한 세밀한 보상 가이드 [76]를 생성할 수도 있다.
본 논문은 로봇 조작(Robotic Manipulation)을 위한 Visual-CoT 추론을 소개하며, 여기서 예측된 서브골 이미지(Subgoal Images)는 폐루프(Closed-loop) 행동 생성을 위한 중간 추론 단계 역할을 한다. 이 접근 방식은 추가적인 annotation 없이도 데모 비디오를 자연스러운 중간 추론 상태로 활용한다.
Vision-Language-Action Models
대규모 사전 학습된 Vision-Language Models(VLMs) [9, 28, 38]은 로봇 학습을 위한 강력한 도구로 부상했으며, 최근 연구들은 이를 로봇 시스템에 통합하기 위한 다양한 접근법을 탐구해 왔다. 몇몇 연구들은 복잡한 작업을 분해 [21, 26, 34, 56]하거나, 객체를 감지 [19, 25]하거나, 또는 밀집 보상(Dense Rewards) [13, 40, 74]이나 목표(Goals) [2, 11, 15, 46, 47, 55, 71, 80]를 생성하기 위해, VLM의 강력한 시맨틱 이해(Semantic Understanding) 및 추론 능력을 활용하여 이를 인지(Perception)와 제어(Control)를 위한 중간 구성 요소로 활용한다.
일부 접근법들은 더 나은 Visuolanguage Representation을 위해 VLM을 사전 학습된 Backbone으로 사용하여, 이를 종단간 학습 가능한 정책(End-to-end Trainable Policies)에 통합한다 [4, 49, 64][12, 29, 41, 48, 59].
본 연구와 가장 관련이 깊은 것은 직접적인 행동 예측(Action Prediction)을 위해 로봇 데모 데이터에 대해 사전 학습된 VLM을 파인튜닝하는 최근의 접근 방식들이다 [12, 29, 48].
이러한 VLA들은 Internet-scale의 비전-언어 데이터셋에 대한 사전 학습을 통해 새로운 객체, 환경, 그리고 자연어 지시에 대해 향상된 일반화 성능을 보여주며, 시각 및 언어 지식을 로봇 제어 작업으로 전이하기 위한 방향을 제시한다.
그러나 기존의 대부분의 VLA들은 다양한 작업 전반에서 성능을 크게 향상시키는 것으로 입증된 [62] 거대 언어 모델의 단계별 추론 능력을 활용하지 못하고 있다. 과거에 연구자들은 로봇 공학을 위해 언어 지시나 중간 키포인트(Keypoints)/바운딩 박스에 대해 생각의 사슬 추론을 사용해 왔다 [6, 13, 45, 63].
본 논문은 행동 생성 이전의 중간 추론 단계로서 서브골 이미지를 사용하여, VLA 프레임워크에 시각적 생각의 사슬 추론을 도입한다.
3. CoT-VLA
본 섹션에서는 VLA(Vision-Language-Action)를 위한 본 논문의 Visual Chain-of-Thought 추론 프레임워크를 제시한다.
3.1. Visual Chain-of-Thought Reasoning
본 논문은 VLA 사전 학습(Pretraining)을 위해 두 가지 유형의 학습 데이터를 고려한다.
-
로봇 시연 데이터셋(Robot demonstrations dataset, )
: 로 표현된다. 여기서 은 자연어 지시문(Language instruction), 는 로봇 행동의 시퀀스, 는 이미지 시퀀스로 구성된 시각적 관측값(Visual observations)을 의미한다. -
행동 주석이 없는 비디오 데이터셋(Action-less videos dataset, )
: 로 구성되며, 언어 설명과 이미지는 포함되어 있지만 로봇의 행동 주석(Action annotations)은 없는 데이터이다. -
VLA vs. CoT-VLA
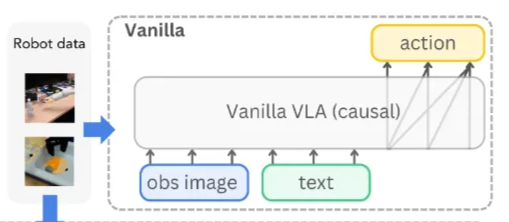
- Vanilla VLA
: 사전 학습된 VLM()을 로봇 시연 데이터()로 미세 조정하여, 현재 관측값()과 언어 지시문()으로부터 차기 행동()을 직접 예측하도록 학습한다.
(1)
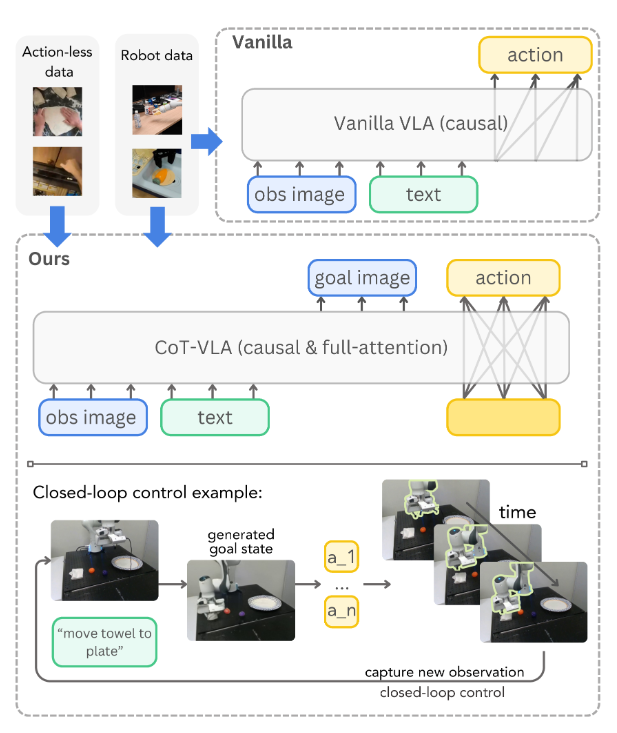
- CoT-VLA
: 본 논문의 핵심 통찰은 행동 생성 전에 명시적인 시각적 추론(Visual Reasoning) 과정을 포함하는 것이다. Figure 2에서 보듯, 본 논문의 접근 방식은 다음의 두 가지 순차적 단계로 작동한다.
- 중간 시각 추론(visual reasoning) 단계로서 프레임 이후의 하위 목표 이미지()를 먼저 예측한다. (’미래의 이미지’를 먼저 생성함으로써 “어떤 행동을 했을 때 세상이 어떻게 변하는가”에 대한 시각적 정보를 학습)
(2)
- 생성된 하위 목표 이미지()를 조건으로 하여 개의 행동 시퀀스를 생성한다.
(3)
이를 통해 모델은 행동을 예측하기 전에 원하는 미래 상태를 명시적으로 추론함으로써 먼저 '시각적으로 생각'할 수 있게 된다.
시각적 추론 단계(Eq. 2)는 로봇 시연 데이터()와 행동 주석이 없는 비디오()에서 학습되고, 행동 생성 단계(Eq. 3)는 로봇 시연 데이터()에서만 학습된다.
3.2. The Base Vision-Language Model
식 (2)에서 설명한 시각적 추론 능력을 구현하기 위해, 이미지와 텍스트 토큰을 모두 이해하고 생성할 수 있는 통합 멀티 모달 기반 모델인 VILA-U [67]를 기반으로 base VL model을 구축한다.
-
통합 프레임워크: VILA-U는 자기회귀 차기 토큰 예측(Autoregressive next-token prediction) 프레임워크를 통해 비디오, 이미지, 언어 이해를 통합한다.
-
통합 비전 타워(Unified Vision Tower): 시각적 입력을 텍스트 정보와 정렬된 이산 토큰(Discrete tokens)으로 인코딩한다. 이는 자기회귀 방식의 이미지/비디오 생성을 가능하게 하며, 이산 시각 특징을 활용하는 VLM의 이해 능력을 크게 향상시킨다.
-
잔차 양자화(Residual Quantization): RQ-VAE [32]에서 도입된 뎁스 트랜스포머(Depth transformer)를 포함하여 잔차 토큰을 점진적으로 예측함으로써 이산 시각 특징의 표현 용량을 개선한다.
-
데이터 구성: 추출된 시각 특징은 프로젝터(Projector)를 거쳐 LLM 백본에서 처리된다. 기본 모델은 [이미지, 텍스트], [텍스트, 이미지], [비디오, 텍스트], [텍스트, 비디오] 쌍을 포함하는 다중 모달 데이터로 학습된다.
-
해상도 및 토큰 구조: 256 × 256 해상도 이미지를 사용하며, 각 이미지는 4의 잔차 깊이(Residual depth)를 가진 토큰으로 인코딩된다.
3.3 Training Procedures
본 논문은 로봇 시연 데이터()와 행동 주석이 없는 비디오()를 조합하여 7B-base VILA-U 모델을 사전 학습(Pretraining)한다. 학습 과정에서 비전 타워(Vision tower)는 고정(Fixed)된 상태로 유지하며, LLM 백본(LLM backbone), 프로젝터(Projector), 그리고 뎁스 트랜스포머(Depth transformer)라는 세 가지 구성 요소를 최적화한다. 학습 목표는 두 가지 핵심 요소로 구성된다. Causal attention을 이용한 하위 목표 이미지 생성(Eq. 2)과 Full attention을 이용한 행동 생성(Eq. 3)이다.
- Visual Tokens Prediction
하위 목표 이미지 생성을 위해 각 학습 시퀀스는 의 형태를 갖는다. 본 논문은 [67]에서 사용된 학습 목표를 따른다. 각 시각적 위치(Visual position) 에서 Depth Transformer 는 LLM이 생성한 코드 임베딩 를 기반으로 개의 잔차 토큰(Residual tokens) 을 자기회귀적으로 예측한다. 시각적 토큰에 대한 학습 목표는 다음과 같이 공식화된다.
(4)
여기서 는 시각적 토큰을 포함하는 위치의 인덱스이다.
- Action Tokens Prediction
행동 예측을 위해 각 학습 시퀀스는 의 형태를 취한다. 각 행동 는 7개의 토큰으로 표현되며, 각 행동 차원은 독립적으로 이산화(Discretized)된다.
OpenVLA[29]를 따라, 각 연속적인 행동 차원을 256개의 discrete bins으로 매핑하며, 빈의 너비는 학습 데이터 행동 분포의 1번째와 99번째 백분위수 사이의 구간을 균등하게 나누어 결정한다.텍스트 토크나이저 어휘 사전에서 가장 적게 사용되는 256개의 토큰을 행동 빈 토큰으로 재사용한다. 기존 연구들(Palm-e[12], OpenVLA[29], Open X-embodiement[48])과 달리, 본 논문은 action token을 처리하고 예측하는 데 Full attention을 채택하여 모든 action chunk가 서로 상호작용할 수 있도록 한다.
이 어텐션 메커니즘은 Figure 3(Hybrid Attention)에 예시되어 있다. 학습 시에는 행동 예측에 대한 Cross-entropy 손실을 최소화한다.
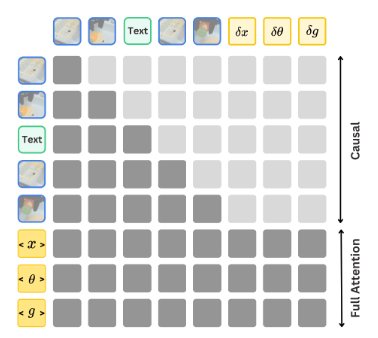
[Figure 3]
CoT-VLA의 Hybrid attention 메커니즘. 본 논문은 이미지 또는 텍스트 생성에는 Causal attention을 사용하고, Action generation에는 Full attention을 사용한다. , , 는 행동의 Parallel decoding을 위한 특수 토큰이다.
- Causal Attention vs Full Attention :
Causal은 앞 단어만 보고 다음 단어를 맞히는 방식이지만, Full Attention은 지시문(), 현재 상태(), 그리고 목표 상태()를 모두 펼쳐놓고 한꺼번에 참조한다. 목표 이미지()가 이미 주어져 있기 때문에, 모델은 "이 목표에 도달하려면 전체적으로 어떻게 움직여야 할지"를 훨씬 더 조화롭고 정확하게 계산할 수 있다.
(5)
입력 시퀀스 배치(Batch)가 주어졌을 때, 전체 학습 목표는 행동 및 시각적 손실을 결합한다.
(6)
- Pretraining Phase
본 논문은 섹션 3.1에서 기술한 바와 같이 로봇 시연 데이터()와 행동 주석이 없는 비디오()를 모두 사용하여 CoT-VLA를 사전 학습한다.
로봇 시연 데이터의 경우, Open X-Embodiment 데이터셋 (OpenX)의 하위 집합을 선별하여 사용한다. OpenVLA [29]에서 확립된 전처리 파이프라인을 따라, 3인칭 카메라 시점과 단일 팔 말단 작동기 제어(7-DoF)를 포함하는 데이터셋을 선택 및 처리한다.
행동 주석이 없는 비디오()로는 EPIC-KITCHENS [27]와 Something-Something V2 [20] 데이터셋을 통합한다. 모든 이미지는 256 × 256 해상도로 처리된다.
시각적 추론을 위해, 예측 범위의 하한과 상한을 정의하는 데이터셋별 범위 내에서 균등하게 샘플링된 미래 타임스텝 의 하위 목표 이미지(Subgoal images)를 사용한다.
Action chunk size는 10으로 설정한다. (상세 파라미터는 Appendix 참조)
- Adaptation Phase for Downstream Closed-Loop Deployment
폐루프 배포 (Closed-Loop Deployment): 다운스트림 작업에 적응하기 위해, 대상 로봇 설정에서 수집된 작업별 로봇 시연 데이터()를 사용하여 사전 학습된 모델을 미세 조정(Fine-tuning)한다.
이 단계에서는 사전 학습 단계와 동일한 설정을 유지하며 Vision tower를 고정(Frozen)한 채 LLM 백본, 프로젝터 및 뎁스 트랜스포머를 최적화한다. 결과 모델은 자연어 명령 을 기반으로 새로운 조작 작업을 수행할 수 있다. 알고리즘 1은 테스트 시 로봇 제어 절차를 설명한다.

[Algorithm 1]
- 입력 및 초기화 (Initialization)
- 학습된 모델 , 로봇의 초기 상태 , 작업 지시문 , 타임스텝
- 시각적 하위 목표 샘플링 (Visual Subgoal Sampling)
- : 현재 관측값()과 지시문()을 바탕으로, 모델이 미래의 목표 상태인 하위 목표 이미지()를 먼저 생성
- 행동 시퀀스 샘플링 (Action Sequence Sampling)
- : 앞서 생성한 하위 목표 이미지()를 참조하여, 그 상태에 도달하기 위한 개의 연속적인 행동()을 한꺼번에 생성
- 실행 (Execution)
- 생성된 개의 행동 시퀀스를 로봇이 순차적으로 실행
- 업데이트 및 폐루프 피드백 (Update & Observation)
- 타임스텝을 행동한 만큼 업데이트()
- 실행 후 로봇으로부터 새로운 시각 관측값()을 다시 받아오고, 받아온 값(새 이미지) 바탕으로 다시 루프를 반복하며 실시간으로 오차를 보정
4. Experiments
본 논문은 시뮬레이션 벤치마크와 실제 로봇 조작 작업을 아우르는 일련의 실험을 통해 제안된 시스템의 효과를 평가한다. 실험의 주요 목적은 다음의 질문들에 답하는 것이다.
[Research Questions]
- 성능 비교: 본 논문의 시스템이 다양한 벤치마크와 로봇 본체(Embodiment)에 걸쳐 최신(State-of-the-art) 베이스라인 모델들과 비교했을 때 어느 정도의 성능을 보이는가? (Section 4.2)
- 구성 요소의 영향: 사전 학습(Pretraining), 시각적 사고의 사슬(Visual Chain-of-Thought) 추론, 그리고 혼합 어텐션(Hybrid Attention)이 작업 수행 능력에 각각 어떤 영향을 미치는가? (Section 4.3)
- 일반화와 행동 예측의 상관관계: 시각적 추론 능력의 향상된 일반화(Generalization) 성능이 로봇의 행동 예측 능력을 어느 정도까지 강화할 수 있는가? (Section 4.4)
4.1. Experimental Setup
본 논문은 세 가지 상호 보완적인 환경에서 평가를 수행한다.
- LIBERO 벤치마크 [37]: 시뮬레이션 환경에서의 성능 평가를 위해 사용된다.
- Bridge-V2 플랫폼 [60]: 45,000개의 로봇 시연 데이터셋을 포함하는 플랫폼을 활용한다.
- Franka-Tabletop 설정: 테이블에 고정된 Franka Emika Panda 로봇을 사용하며, 각 테스트 시나리오당 10개에서 150개 사이의 제한된 로봇 시연 데이터를 사용한다.
LIBERO Simulation Benchmark [37]
로봇의 공간 이해(Spatial), 객체 상호작용(Object), 목표 달성(Goal), 장기 작업(Long) 능력을 평가하기 위한 4개의 작업 스위트로 구성된다. 각 작업당 50개의 사람 원격 조종 시연 데이터를 사용하며, 이미지는 256x256 해상도 표준화 및 180도 회전 등의 전처리를 거친다.
Bridge-V2 Real-Robot Experiments [60]
6자유도(6-DoF) WidowX 로봇 팔을 사용하며, 45,000개의 언어 주석이 달린 궤적 데이터를 활용한다. 시각적 강건성, 동작 일반화, 의미론적 일반화, 언어 접지(Language grounding) 능력을 평가하도록 설계된 4가지 작업을 수행한다.
Franka-Tabletop Real-Robot Experiments
사전 학습 단계에서 노출되지 않은 새로운 환경으로, 7자유도(7-DoF) Franka Emika Panda 로봇을 사용한다. 소량의 데이터(10~150개 시연)만으로 새로운 환경에 얼마나 잘 적응하는지 평가하며, 단일 지시문 및 다중 지시문 기반의 6개 작업을 수행한다.
Baselines
본 논문은 제안하는 접근 방식의 성능을 검증하기 위해 네 가지 최신(State-of-the-art) 베이스라인 모델과 비교 평가를 수행한다.
-
Diffusion Policy [10]: 최신 Imitation Learning 알고리즘으로, LIBERO와 Franka-Tabletop의 각 테스트 시나리오에 대해 처음부터(From scratch) 학습된다. 이 구현체는 DistilBERT [52] 언어 임베딩을 조건으로 사용하며, Action chunking과 고유 수용 감각(Proprioception)을 통합하고 있다.
-
OpenVLA [29]: 사전 학습된 시각-언어 모델(VLM)을 OpenX 데이터셋으로 미세 조정하여 사용하는 오픈 소스 VLA 모델이다.
-
Octo [59]: VLM 초기화 없이 OpenX 데이터셋에서 사전 학습된 범용 모델(Generalist model)이다. OpenVLA와 Octo 모두 Bridge-V2 평가에는 공개된 체크포인트를 사용하였으며, LIBERO 및 Franka-Tabletop 실험을 위해서는 각 환경에 맞게 미세 조정을 거쳤다.
-
SUSIE [2]: 2단계 접근 방식을 사용하는 모델로, 지시문 가이드 이미지 편집(Instruction-guided image editing)을 통해 목표를 생성한 뒤, 목표 조건부 정책(Goal-conditioned policy)을 통해 행동을 생성한다. SUSIE는 Bridge-V2에서 공개된 체크포인트를 사용하여 평가되었다.
4.2. Evaluations Results

-
LIBERO

본 논문은 표 1에 정량적 결과를 제시하며, 각 방법은 작업 스위트당 3개의 무작위 시드(Random seeds)를 사용하여 총 500회의 평가를 거쳤다. 성공률은 평균과 표준 오차(Standard error)로 보고된다. 본 논문 방식의 추론 및 실행 궤적에 대한 정성적 예시는 Figure 5에 설명되어 있다.
결과는 CoT-VLA가 LIBERO 시뮬레이션 환경의 작업에 효과적으로 적응하며, 베이스라인 접근 방식들과 비교하여 최고 수준이거나 경쟁력 있는 성능을 달성함을 보여준다.
실패 사례의 롤아웃(Rollout) 비디오를 분석한 결과, 베이스라인 방법들이 언어 지시문을 무시한 채 시각적 단서에 가끔 과적합(Overfit)되는 것을 발견했다.
구체적으로, 서로 다른 작업 간에 초기 상태가 시각적으로 유사하게 보일 때(예: LIBERO-Spatial), 베이스라인 방법들은 일부 에피소드에서 명령된 작업과 다른 작업을 실행한다. CoT-VLA는 언어 접지형(Language-grounded) 하위 목표 생성을 통해 원하는 행동에 대해 먼저 시각적으로 추론한 다음, 목표 달성을 위한 관련 행동을 예측함으로써 더 나은 지시문 이행 능력을 보여준다.
-
Bridge-V2
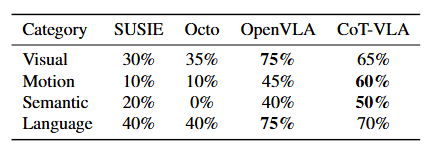
본 논문은 [29]에서 식별된 네 가지 일반화 범주에 대해 Bridge-V2 벤치마크에서 CoT-VLA와 베이스라인들을 평가한다. 해당 범주는 시각적 일반화(어지러운 환경에서 "가지(Eggplant)를 냄비에 넣기"), 동작 일반화(높이 변화가 있는 상태에서 "당근을 접시에 놓기"), 의미론적 일반화("냄비에서 보라색 포도를 꺼내기"), 그리고 언어 접지("가지 또는 빨간 병을 냄비에 넣기")이다. 정량적 결과는 표 2에 보고되며, 각 작업은 10회의 평가를 거쳤다.
SUSIE [2]는 확산 사전 학습(Diffusion prior)을 통해 시각적으로 더 높은 품질의 목표 이미지를 생성하지만(본 논문의 한계에 대한 자세한 논의는 Section 5 참조), 새로운 객체가 포함되거나 복잡한 언어 접지가 필요한 작업에서는 더 낮은 성공률을 기록했다.OpenVLA [29]와 비교했을 때, CoT-VLA는 시각적 추론의 오류보다는 Action chunking으로 인한 파지(Grasping) 실패(섹션 5 참조)로 인해 시각 및 언어 일반화 작업에서 약간 낮은 성공률을 보인다. 그러나 CoT-VLA는 전반적으로 네 가지 일반화 범주 모두에서 경쟁력 있는 성능을 입증하며, 베이스라인 접근 방식들과 비슷하거나 더 나은 결과를 달성했다.
-
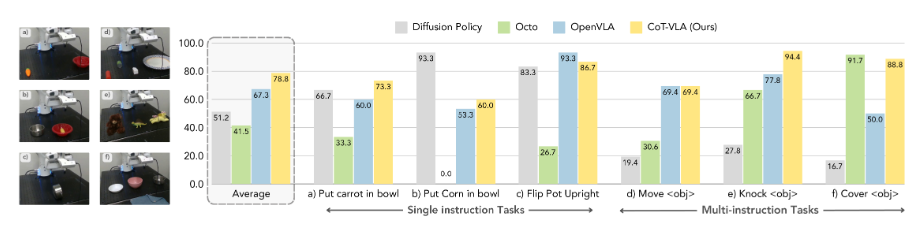
Franka-Tabletop
본 논문은 표 4에 정량적 결과를, Figure 5에 실행 궤적 예시를 제시한다. 이 실험에서 모델들은 비교적 적은 양의 시연 데이터셋으로 미세 조정된다. 디퓨전 정책(Diffusion Policy)은 단일 지시문 작업(예: "옥수수를 그릇에 넣기")에서 최고의 성능을 달성하지만, 다양한 객체와 복잡한 언어 지시문이 포함된 다중 지시문 작업에서는 성능이 저하된다. OpenX 데이터셋에서 사전 학습된 모델들인 Octo, OpenVLA, CoT-VLA는 언어 접지가 중요한 다중 지시문 작업에서 더 나은 적응력과 성능을 보여준다. 전반적으로 CoT-VLA는 베이스라인 접근 방식들과 비교하여 가장 높은 평균 성능을 달성했으며, 단일 및 다중 지시문 시나리오 모두에서 개선된 모습을 보였다.
4.3. Ablation Study
-
Visual CoT, Hybrid Attention, and Action Chunking
본 논문은 LIBERO-Spatial과 LIBERO-Goal이라는 두 가지 LIBERO 벤치마크 스위트(Benchmark suites)에서 Ablation study를 수행했다. 다음과 같은 네 가지 모델 변형을 평가했다.-
VLA: 표준 VLA 프레임워크[29]를 따르는 베이스라인(Baseline) 구현으로, 동일한 VILA-U 백본(Backbone)을 사용하지만 사고의 사슬(Chain-of-thought) 추론과 행동 청킹(Action chunking)은 제외한다.
-
+ action chunking: 일반적인 VLA를 확장하여 길이 의 행동 시퀀스(Action sequences)를 예측하도록 한다.
-
+ hybrid attention: 그림 3에 예시된 것처럼 행동 시퀀스 예측을 위해 풀 어텐션(Full attention) 메커니즘을 추가한다.
-
+ CoT(본 논문): hybrid attention 메커니즘과 (Visual chain-of-thought 추론이 결합된 본 논문의 완성된 접근 방식이다.
-
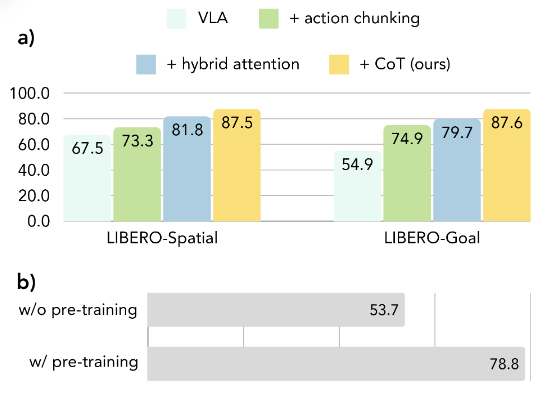
[Figure 6]
CoT-VLA 구성 요소에 대한 Ablation studies.
(a) LIBERO-Spatial 및 LIBERO-Goal 벤치마크 결과는 Action chunking, Hybrid attention, Visual chain-of-thought 추론이라는 세 가지 구성 요소의 유효성을 입증한다.
(b) Franka-Tabletop에서의 사전 학습 어블레이션 실험은 OpenX 및 행동 주석이 없는 비디오(Action-less video) 사전 학습 과정을 통한 성능 향상을 보여준다.
Fig 6에서 보듯, 두 벤치마크 스위트 모두에서 행동 시퀀스 예측이 단일 행동 예측(Single-action prediction)보다 일관되게 우수한 성능을 보였다. Hybrid attention 메커니즘의 추가는 성능을 더욱 향상시킨다. 본 논문의 CoT-VLA는 가장 우수한 결과를 달성하며 VLA 작업에서 시각적 사고의 사슬 추론의 유효성을 입증한다.
-
Pretraining
본 논문의 학습 파이프라인은 행동 주석이 없는 비디오 데이터(Action-less video data)가 추가된 OpenX 데이터셋으로 VILA-U를 사전 학습하는 단계(섹션 3.3)와, 로봇 시연 데이터(Robot demonstration data)로 수행하는 작업별 사후 학습(Post-training) 단계로 구성된다. 사전 학습 단계의 중요성을 평가하기 위해 Franka-Tabletop 환경에서 ablation study를 수행한다.
정량적 결과는 그림 6에 보고된다. 결과에 따르면, 본 논문의 사전 학습 단계를 거친 CoT-VLA는 기반 VILA-U 모델을 Franka-Tabletop 시연 데이터로 직접 미세 조정(Fine-tuning)한 경우 53.7%와 비교해 78.8%의 성공률을 기록하며 46.7%의 상대적 성능 향상을 달성했으며, 이는 더 나은 Downstream task adaptation을 보여준다.
4.4. Better Visual Reasoning Helps
훈련 시 로봇 시연 데이터()만을 사용하는 기존의 VLA(Vision-Language-Action) 모델들과 달리, CoT-VLA는 중간 단계인 Visual Chain-of-Thought 추론 단계를 통해 행동 주석이 없는 비디오 데이터()를 사전 학습에 활용한다. 이를 통해 로봇 시연 데이터보다 훨씬 풍부한 캡션이 달린 비디오만으로도 역학(Dynamics)과 지시문 이행(Instruction following)을 모두 학습할 수 있다.
시각적 추론 능력이 로봇의 성능으로 어떻게 전이되는지 조사하기 위해, 본 논문은 학습되지 않은 두 개의 하위 작업이 결합된 새로운 Long-horizon tasks을 사용하여 Franka-Tabletop 설정에서 ablation study를 수행한다.
본 논문은 모델의 분포 외(Out-of-distribution) 일반화에 도전적인 두 가지 작업, 즉 (1) "녹색 파를 사과가 그려진 책으로 옮기기"와 (2) "녹색 콜리플라워를 곰이 그려진 책으로 옮기기"를 설계한다. 각 작업에 대해 하나의 시연 궤적을 수집하여 실측(Ground-truth) 목표 이미지를 확보한다. 각 작업은 두 가지 조건 하에 5회씩 평가된다: (1) 생성된 목표 이미지를 사용하는 CoT-VLA (2) 수집된 시연에서 얻은 실측 목표 이미지를 사용하는 CoT-VLA.

[Table 3]
더 나은 시각적 추론의 기여도. 분포 외(Out-of-distribution) 작업에서 생성된 목표 이미지와 실측(Ground-truth) 목표 이미지를 사용했을 때의 CoT-VLA 성공률 비교.
결과는 실측 목표 이미지로 시뮬레이션된 개선된 시각적 추론이 더 나은 작업 성능으로 이어진다는 것을 입증하며, 이는 목표 생성 기술의 발전이 곧 로봇의 행동 실행 능력 향상으로 직결될 수 있음을 시사한다.
Table 3에서 보듯, 실측 목표 이미지를 사용하면 두 작업 모두에서 절대 성공률이 40% 향상된다. 이러한 성능 향상은 시각적 추론 및 목표 이미지 생성 기술의 발전이 로봇의 작업 수행 능력 향상으로 직접 이어질 수 있음을 시사한다. 본 논문의 방식은 여전히 분포 외 하위 목표 생성에 어려움을 겪고 있지만, 대규모 비디오 및 이미지 모델의 최근 발전은 스케일링을 통해 시각적 추론 능력을 개선할 수 있는 유망한 방향을 보여준다.
5. Conclusion, Limitations and Future Work
본 논문은 중간 시각적 목표를 명시적인 추론 단계로 도입하여 시각-언어-행동(Vision-Language-Action) 모델과 사고의 사슬(Chain-of-Thought) 추론을 결합한 CoT-VLA를 제안하였다. 바운딩 박스(Bounding boxes)나 핵심 포인트(Keypoints)와 같은 추상적인 표현 대신, 비디오에서 샘플링된 하위 목표 이미지(Subgoal images)를 해석 가능하고 효과적인 중간 표현으로 사용할 것을 제안하였다. 본 시스템은 VILA-U를 기반으로 구축되었으며, 다양한 로봇 조작 작업에서 강력한 성능을 입증하였다.
본 논문의 접근 방식은 효과적이지만 몇 가지 한계점이 존재한다.
주요 한계점 및 향후 과제
-
추론 속도 저하: 추론 과정에서 중간 이미지 토큰을 생성하는 것은 직접적인 행동 생성 방식에 비해 상당한 Computational overhead를 발생시킨다.
action chunk 크기가 10일 때, action chunk 이전에 256개의 이미지 토큰을 생성해야 하므로 평균적으로 약 7배의 속도 저하가 발생한다. -
시각적 품질의 한계: 본 논문의 자기회귀(Autoregressive) 이미지 생성 방식은 최신 확산 기반 모델(Diffusion-based models)에 비해 시각적 품질이 낮다. 이는 향후 통합 다중 모달 모델의 발전을 통해 개선될 수 있는 부분이다.
-
행동의 불연속성: 사용된 행동 청킹(Action chunking) 방식은 청크 사이의 불연속적인 행동을 유발할 수 있으며, 실행 중 고주파 피드백(High-frequency feedback)이 부족하다는 단점이 있다. 이는 시간적 평활화(Temporal smoothing) 기술 등을 통해 해결될 수 있다.
-
일반화 능력의 제약: 현재의 계산 자원 제약으로 인해 완전히 새로운 작업에 대한 시각적 추론 일반화 능력을 달성하는 데 한계가 있다.
6. Appendix (Implementation Details)
6.1. Data Detail
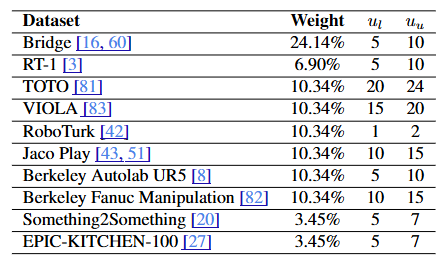
본 논문은 로봇 시연 사전 학습 데이터로 Open X-Embodiment 데이터셋 [48]의 일부를 선택하였으며, 행동 주석이 없는 비디오 데이터(Action-less video data)로는 Something-Something V2 [20]와 EPIC-KITCHEN-100 [27]을 사용했다.
하위 목표 예측 범위(Subgoal horizon)의 상한()과 하한()은 각 데이터셋의 특성에 맞춰 수동으로 설정되었다.
6.2. Hyperparameters
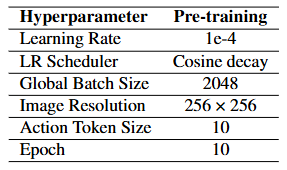
모델의 사전 학습 및 사후 학습(Post-training) 단계에서 사용된 주요 하이퍼파라미터
6.3. Training
각각 8개의 GPU가 탑재된 12개의 NVIDIA A100 GPU 노드에서 학습 수행

또 읽으셨네요...