BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding(2018) 논문을 읽고 내용 요약 및 정리를 담았다.
1. Introduction
언어 모델을 사전학습시키는 것은 자연어 처리 태스크 성능 향상에 효과적이라는 것은 저명한 사실인데, 이러한 태스크에는 NER(개체명 인식), 질의응답(QA)와 같은 다양한 문장 수준의 태스크가 포함된다. 언어 모델 사전 학습에는 feature-based와 fine-tuning 두 가지 접근법이 있다.
ELMo(2018)은 feature-based 구조를, OpenAI GPT는 fine-tuning 접근법을 따른다. OpenAI GPT는 모든 토큰이 트랜스포머(Transformer)의 self-attention 층에 있는 이전 토큰만 처리할 수 있는 ‘left-to-right’ 구조를 사용한다. 이러한 구조는 양방향의 문맥을 이해해야 하는 질의응답(QA)와 같은 태스크에서 성능을 하락시킨다. 따라서 BERT(Bidirectional Encoder Representations from Transformers)는모든 레이어의 왼쪽과 오른쪽 문맥을 고려하도록 설계함으로써 OpenAI GPT의 단점을 보완하고 fine-tuning 기반의 사전학습 접근법을 발전시킨다.
- BERT는 단방향의 한계 극복을 위해
masked language model(MLM)방식으로 사전학습한다. MLM이란 INPUT 토큰의 일부를 무작위로 마스킹하고, 마스킹된 단어를 그 문맥에만 의존하여 원래 단어를 예측하게 하는 것이다. 또한next sentence prediction(다음 문장 예측)을 통해 텍스트 쌍을 공통으로 사전학습 할 수 있도록 한다. (이후 섹션에서 자세히 다룸)
2. Related Work
Generative language representation pre-training의 접근법 선행 연구에 대해 소개한다.
feature-based접근법
ELMo는 left-to-right, right-to-left에서 context-sensitive feature를 추출한다.
fine-tuning접근법
OpenAI GPT는 사전학습과 파인튜닝으로 학습할 파라미터 수를 줄여 GLUE benchmark의 문장 수준 태스크에서 SOTA를 달성한다.
3. BERT
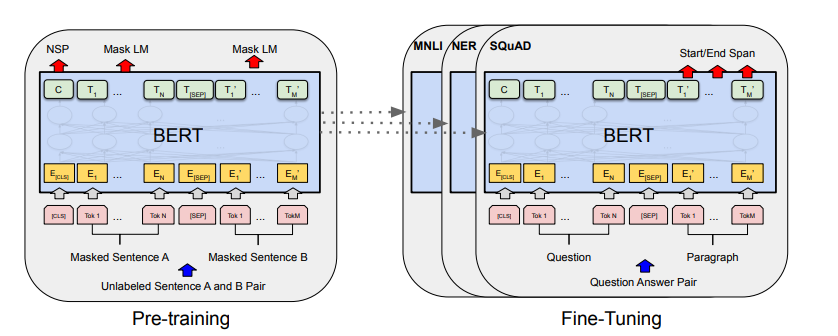
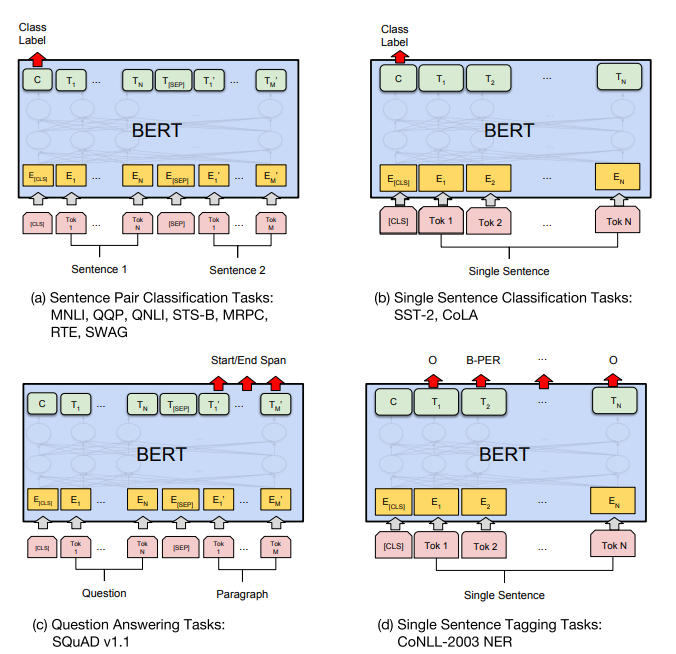
Figure 1. BERT의 전반적인 사전학습과 파인튜닝 절차이다. OUTPUT 층을 제외하면, 사전학습과 파인튜닝이 같은 구조이다. 동일한 사전학습 모델 파라미터는 다양한 후속 태스크에 초기화된다. 파인튜닝 절차를 거치는 동안, 모든 파라미터가 파인튜닝된다. [CLS]는 모든 INPUT의 앞에 붙는 special symbol이고, [SEP]은 special separator token이다. (e.g.질의, 응답 구분)
초기 BERT 모델은 파인튜닝을 위해 사전학습 된 파라미터로 초기화되고, 후속 태스크의 라벨링된 데이터를 사용하여 파인튜닝 된다. 동일한 사전학습 파라미터로 초기화 되어도 후속 태스크마다 별개의 파인튜닝 모델을 갖는다.
BERT의 독특한 특징은 다양한 태스크에 있어 그 구조가 단일화되어 있다는 것이다. 사전학습 구조와 최종 구조에는 차이가 거의 없다.
BERT의 모델 구조는 multi-layer bidirectional Transformer encoder로, tensor2tensor 라이브러리에 공개되었다. BERT의 종류는 모델 크기에 따라 2가지로 구분된다.
- BERT BASE
: L=12, H=768, A=12, Total Parameters=110M으로, OpenAI GPT와 성능 비교를 위해
동일한 하이퍼파라미터로 설계되었다.
- BERT LARGE
: L=24, H=1024, A=16, Total Parameters=340M으로 구성되었다.
(** L은 layer의 수, H는 hidden size, A는 self-attention heads의 수)
BERT는 WordPiece Embedding(Wu et al., 2016)을 사용한다. WordPiece는 서브워드 토크나이저(Subword Tokenizer)의 일종으로, 자주 등장하는 단어는 그대로 단어 집합에 추가하지만 자주 등장하지 않는 단어는 더 작은 단위인 ‘subword’로 분리하여 이 subword를 단어 집합에 추가한다.
- BERT의 input representation
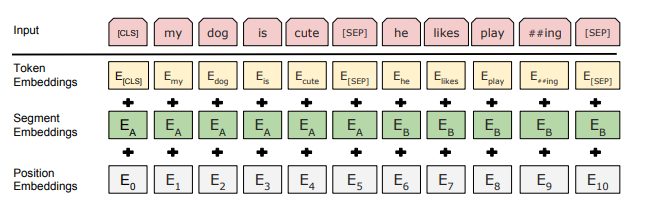
Figure 2. BERT input representation. INPUT 임베딩은 토큰 임베딩, 세그먼트 임베딩, 포지션 임베딩의 총합이다.
- BERT의 사전학습 방법
BERT는 전통적인 사전학습 방식인 left-to-right/right-to-left를 사용하지 않는다. 대신, 다음과 같은 비지도학습 태스크를 사용하여 BERT를 사전학습시킨다.
#Task 1 : Masked LM(MLM)
BERT는 input 토큰의 일정 %를 랜덤으로 마스킹(WordPiece 토큰의 15%)하고, 해당 마스킹 토큰을 예측한다. 마스킹 된 단어만을 예측하는 것은 bidirectional pre-trained model이 될 수 있도록 하지만, 사전학습과 파인튜닝 간의 부조화를 낳는다([MASK] 토큰이 파인튜닝 하는 동안 나타나지 않기 때문에).
이러한 부조화를 방지하기 위해서, 해당 토큰들은 다음과 같은 규칙이 적용된다.
(1) 80%을 [MASK]로 변경
- 예 : My dog is hairy —> My dog is [MASK]
(2) 랜덤 토큰 10%을 임의 단어로 단어 변경
- 예 : My dog is hairy —> My dog is apple
(3) 10%을 동일하게 유지(이 절차의 목표는 실제 관측 단어가 representation에 편향을 갖도록 하기 위함)
- 예 : My dog is hairy —> My dog is hairy
#Task 2 : Next Sentence Prediction(NSP)
문장 관계를 이해하는 모델(QA나 NLI와 같은)을 학습하기 위해, BERT는 이진화된 “다음 문장 예측”태스크를 사전학습한다. 문장 A와 B가 있을 때, B의 50%는 A에 수반된 실제 다음 문장이고(isNext로 라벨링), 50%는 코퍼스 상의 랜덤 문장이다(NotNext로 라벨링).
- NSP 태스크의 예시
Input = [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]
Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
4. Experiments
11가지 NLP 태스크에 대한 BERT 모델의 파인튜닝 결과를 제시한다. (GLUE 태스크 9개 + SQuAD v1.1, SQuAD v 2.0)
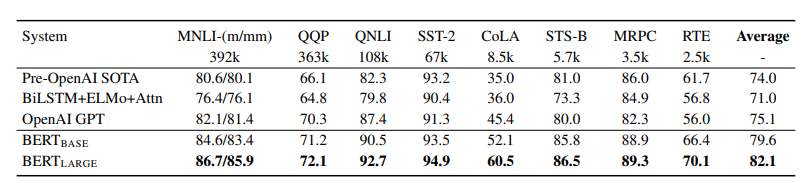
Table 1. 평가 서버의 GLUE TEST 결과이다. “Average” 컬럼은 공식 GLUE score와 약간 상이한데, WNLI set을 제외했기 때문이다.
- ** GLUE의 NLP 태스크에 대한 설명(Appendix 참고하여 작성)
-
MNLI(Multi-Genre Natural Language Inference)
Multi-Genre Natural Language Inference는 대규모 크라우드 소싱된 함의(entailment) 분류 태스크이다. 문장 한 쌍이 주어지면, 두번째 문장이 첫 문장에 대해 함의 문맥(entailment)인지, 대조(contradiction)인지, 또는 중립(neutral)인지를 예측하는 것이 목표이다. -
QQP(Quora Question Pairs)
Quora Question Pairs는 두 질의가 의미론적(semantically)으로 동등한지 판별하는 것을 목표로 하는 이진분류 태스크이다. -
QNLI(Question Natural Language Inference)
Question Natural Language Inference는 Stanford Question Answering Dataset의 버전 중 하나로, 이진 분류 태스크로 변경되었다. 긍정적인 예는 올바른 답을 포함한 (질문, 문장) 쌍이고, 부정적인 예는 답을 포함하지 않는 동일 문단의 (질문, 문장) 쌍이다. -
SST-2(The Stanford Sentiment Treebank)
The Stanford Sentiment Treebank는 인간의 감정에 대한 어노테이션을 포함한 영화 리뷰에서 추출된 문장들로 구성되어 있는 단일 문장 이진 분류 태스크이다. -
CoLA(The Corpus of Linguistic Acceptability)
The Corpus of Linguistic Acceptability는 영어 문장이 언어적으로 수용가능한(acceptable)지 아닌지를 예측하는 것을 목표로 하는 단일 문장 이진 분류 태스크이다. -
STS-B(The Semantic Textual Similarity Benchmark)
The Semantic Textual Similarity Benchmark는 뉴스 헤드라인이나 다른 자료에서 가져온 문자 쌍의 모음집이다. 문장 쌍은 1~5점으로 주석처리 되어 있으며, 이는 두 문장이 의미론적 관점에서 얼마나 유사한지 나타낸다. -
MRPC(Microsoft Research Paraphrase Corpus)
Microsoft Research Paraphrase Corpus는 온라인 뉴스 자료에서 자동으로 추출된 문장 쌍으로 의미론적으로 동등한지에 대한 어노테이션과 함께 구성되어 있다. -
RTE(Recognizing Textual Entailment)
Recognizing Textual Entailment는 MNLI와 유사한 이진 함의 태스크이나, 학습 데이터가 훨씬 더 적다. -
WNLI(Winograd NLI)
Winograd NLI는 작은 자연어 추론 데이터셋이다. GLUE 웹 페이지는 이 데이터셋이 구성에 문제가 있다는 것이 주목했고, GLUE에 제출된 모든 학습된 시스템이 다수 클래스를 예측하는 기준 정확도 65.1보다 낮은 성능을 냈다. 그래서 BERT에서는 OpenAI GPT와 마찬가지로 이 데이터셋을 제외한다.
-
- GLUE(The General Language Understanding Evaluation)
GLUE는 다양한 자연어 이해 태스크의 모음집이다.
BERT는 32 batch size, 3 epochs로 파인튜닝 되었고, Dev set에서 최적의 파인튜닝 학습율을 선택했다(5e-5, 4e-5, 3e-5, 2e-5 중 선택). 파인튜닝이 가끔 적은 데이터셋에서 불안정하여, BERT LARGE의 경우 임의의 재시작을 몇 번 실행한다.
평가 결과는 Table 1에 명시되어 있는데, BERT BASE와 BERT LARGE 모두 각각 4.5%, 7.5%로 기존 SOTA의 평균 정확도를 향상시키며 모든 태스크 시스템을 능가한다. BERT LARGE는 모든 태스크, 특히 학습 데이터가 매우 적은 태스크에서 BERT BASE를 크게 능가한다.
- SQuAD(The Stanford Question Answering Dataset) v1.1
SQuAD v1.1은 크라우드 소싱된 질의응답 쌍의 모음집이다. 문제와 정답을 포함한 구문이 위키피디아에서 주어지면, 그 구문의 정답 구간을 예측하는 것이다.
BERT는 32 batch size, 3 epochs, 5e-5의 학습률로 파인튜닝 되었다.
SQuAD는 학습 시 공공데이터 사용을 허가하여, BERT에서는 SQuAD에 파인튜닝 하기 이전에 TriviaQA로 먼저 파인튜닝 함으로써 데이터를 보강했다.
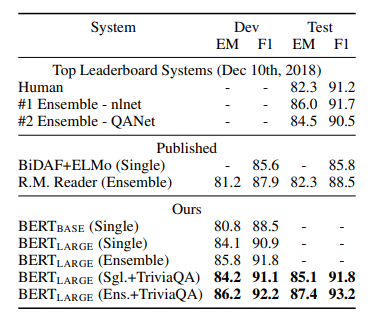
Table 2. SQuAD 1.1 결과이다.
Table 2는 SQuAD 1.1에 대한 리더보드이다. BERT는 Ensemble에서 F1 1.5, Single에서 F1 1.3만큼 리더보드 결과에 앞선다. TriviaQA 파인튜닝 데이터가 없더라도, 0.1-0.4 만큼의 F1만 소실되고 여전히 현존 모든 시스템의 결과를 능가한다.
- SQuAD(The Stanford Question Answering Dataset) v2.0
SQuAD v2.0 태스크는 정답이 없는 질문을 허용함으로써 문제를 더욱 현실성 있게 만들며 SQuAD 1.1의 문제를 확장한다.
BERT는 본 모델에는 TriviaQA 데이터셋을 사용하지 않았다. 48 batch size, 2 epochs, 5e-5의 학습율로 파인튜닝 되었다. 본 모델은 이전 SOTA에서 F1 5.1만큼 성능을 향상시킨다.
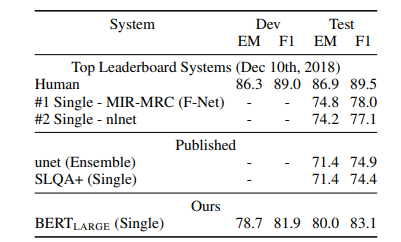
Table 3. SQuAD 2.0 결과이다.
- SWAG(The Situations With Adverserial Generations)
SWAG dataset은 11만 3천개의 문장 쌍으로 구성된다. 문장이 주어지면, 4개 선택지 중 가장 타당한 문장 연결을 선택한다.
BERT는 SWAG dataset을 파인튜닝 할 때, 4개의 input 시퀀스를 구축하는데, 여기에는 주어진 문장(문장 A)와 이어질 문장(문장 B)가 포함되어 있다. 16 batch size, 3 epochs, 2e-5의 학습률로 모델이 파인튜닝 된다.
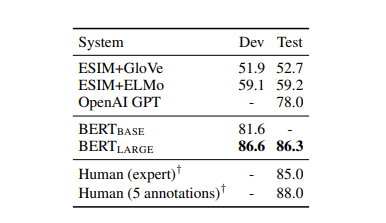
Table 4. SWAG Dev, Test 정확도이다.
BERT LARGE는 ESIM+ELMo를 27.1%, OpenAI GPT를 8.3%만큼 능가한다.
5. Ablation studies
BERT의 ablation study 수행 결과를 제시한다.
# Ablation study란?
모델이나 알고리즘의 feature를 제거하면서 성능에 어떤 영향을 주는지 그 인과관계를 연구하는 것#1. 사전학습 태스크의 영향
- NO NSP : MLM 만 사용하고 NSP 태스크가 제외된 채로 사전학습되었다.
- LTR & NO NSP : MLM이 아닌 left-to-right(LTR)로 학습된 left-context-only 모델. NSP 태스크도 제외되고 사전학습되었다.
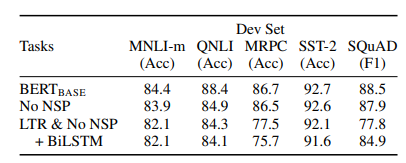
Table 5. BERT BASE 구조를 사용한 사전학습 태스크 Ablation 결과이다.
Table 5에서 NSP를 제거하는 것이 QNLI, MNLI, SQuAD 1.1의 성능을 크게 저하시키는 것을 알 수 있다. LTR 모델은 MRPC와 SQuAD에서 큰 성능 하락을 보이며, 모든 태스크에서 MLM모델보다 성능이 떨어진다.
#2. 모델 사이즈의 영향
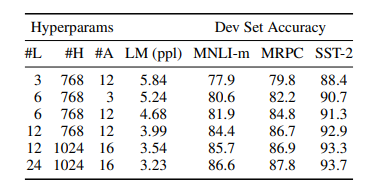
Table 6. BERT 모델 사이즈에 대한 Ablation 결과이다. (L은 layer 개수, H는 hidden size, LM(ppl)은 MLM의 perplexity이다.
# perplexity란?
perplexity(ppl)는 언어 모델 평가지표 중 하나로, 직역하면 '헷갈리는'이라는 의미이다.
이러한 맥락에서 perplexity가 낮을수록 좋은 모델이 되고, 높을수록 좋지 않은 모델이 된다.Table 6의 결과는 모델 크기를 늘리는 것이 태스크의 성능을 향상시킨다는 것을 입증한다. 모델이 후속 태스크에 직접 파인튜닝되고, 임의로 초기화된 적은 부가 파라미터를 사용하면, 후속 태스크 데이터가 아주 적을 때에도 태스크 명시적인(task-specific)한 모델에 잘 적용될 수 있다.
#3. Feature-based 접근법
현재까지 제시된 BERT의 결과는 파인튜닝 접근법을 사용했는데, 단순한 분류 layer가 사전학습된 모델에 더해지고 모든 파라미터가 후속 태스크에서 공동으로 파인튜닝되는 방식이다. Feature-based 접근법은 사전 학습된 모델에서 고정된 feature가 추출되는데, 이러한 접근법에는 몇 가지 이점이 있다.
1) 모든 태스크가 Transformer encoder 구조에 의해 쉽게 드러나는 것이 아니므로, 태스크 명시적 모델 구조가 더해져야 한다.
2) 학습 데이터에서 비용이 많이 드는 representation을 사전에 컴퓨팅하고 난 다음 이 representation 상단에 비용이 덜 드는 모델로 다양한 실험을 수행하는 것이 효율적이다.
BERT를 Named Entity Recognition(NER)에 적용함으로써, feature-based와 파인튜닝 두 가지 접근법을 비교한다.
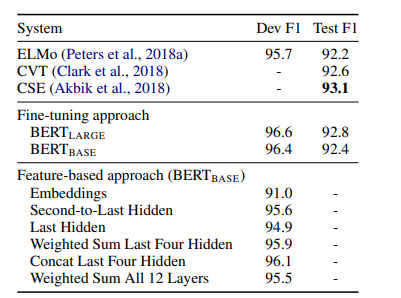
Table 7. CoNLL-2003 Named Entity Recognition 결과이다. 하이퍼파라미터는 Dev set을 사용하여 채택되었다. Dev 및 Test score는 해당 파라미터를 사용하여 임의의 재시작 5번 한 결과를 평균내어 측정되었다.
BERT LARGE는 SOTA 방식에 경쟁력있는 성능을 낸다. 최고 성능을 내는 방식은 사전학습된 Transformer의 4개 hidden layer에서 토큰 representation을 연결하는 것인데, 이 방법은 전체 모델 파인튜닝 방식에 비해 F1이 0.3밖에 뒤쳐지지 않는다. 이는 BERT가 파인튜닝과 Feature-based 접근법에 모두 효과적임을 입증한다.
Appendix
#A.2 Pre-training Procedure
사전학습의 input 시퀀스 생성을 위해, 코퍼스에서 2개의 텍스트 구간을 표본추출한다. 첫 문장은 A 임베딩을 전달받고, 두번째 문장은 B 임베딩을 전달받는다. B의 50%는 A에 수반된 실제 다음 문장이고, 나머지 50%은 NSP 태스크를 위한 임의의 문장이다. 이 문장은 512 토큰 이하의 길이로 표본 추출된다. MLM은 WordPiece 토큰화 이후, 15%로 마스킹된다.
사전학습은 256 batch size(256 시퀀스 * 512 토큰 = 각 배치 128,000 토큰), 1e-4의 학습률로 총 33억 단어의 코퍼스에 대해 40 epochs 학습한 1,000,000 스텝 동안 학습된다. 가중치 감소(Weight Decay)는 L2 Norm 0.01 적용된다. Optimizer는 Adam 을 적용했고, 모든 레이어에 dropout 0.1을 적용한다. 활성화 함수로는 geLU를 사용한다.
# geLU(Gaussian Error Linear Unit)
ReLU는 입력 x의 부호에 따라 1이나 0은 deterministic하게 곱하고,
dropout은 1이나 0을 stochatic하게 곱한다.geLU에서는 이 개념을 합쳐, x를 0 또는 1로
이루어진 마스크를 stochastic하게 곱하면서도 stochasticity를 x의 부호가 아닌 값에
의해 정하고자 한다.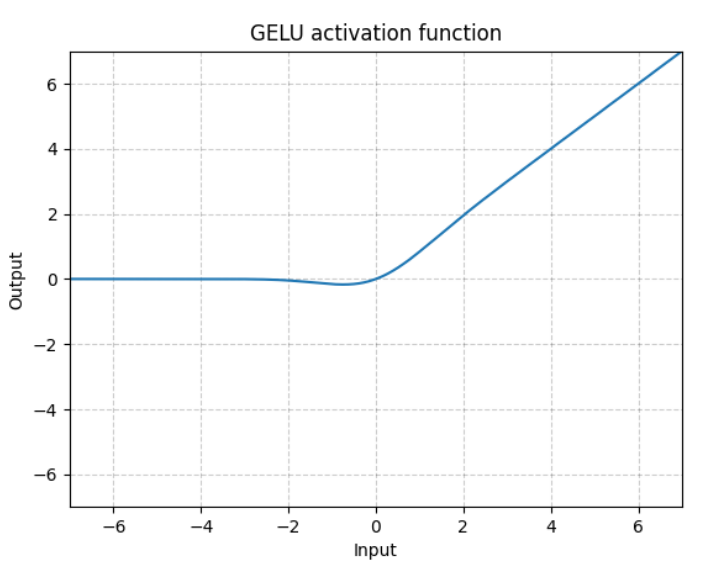
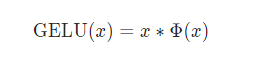
#A.3 Fine-tuning Procedure
파인튜닝 하이퍼파라미터는 배치 사이즈, 학습률, epochs를 제외한 대부분이 동일하다.
모든 태스크에 걸쳐 잘 작용할 수 있는 하이퍼파라미터의 범위 값은 다음과 같다.
- batch size : 16, 32
- learning rate(Adam) : 5e-5, 3e-5, 2e-5
- epochs : 2, 3, 4
#A.4 Comparison of BERT, ELMo, OpenAI GPT
최신 모델인 ELMo, OpenAI GPT와 BERT의 차이점에 대해 설명한다.
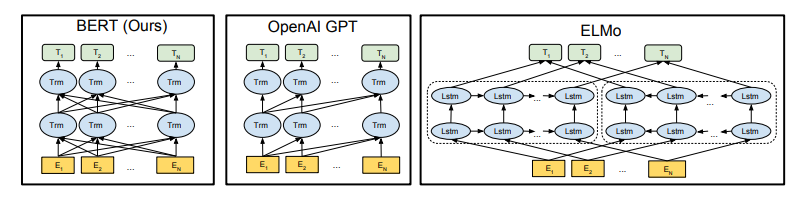
Figure 3. 사전학습 모델 구조의 차이점을 보여준다. BERT는 양방향 트랜스포머를 사용한다. OpenAI GPT는 left-to-right 트랜스포머를 사용한다. ELMo는 독립적으로 학습된 left-to-right, right-to-left LSTM의 결합을 사용한다. 3개의 모델에서, BERT만 모든 layer에서 양쪽 문맥을 공동으로 컨디셔닝한다. 모델 구조적인 차이와 더불어, BERT와 OpenAI GPT는 파인튜닝 접근법을 사용하고, ELMo는 feature-based 접근법을 사용한다.
BERT와 가장 비교될 만한 현존 사전학습 방법론은 OpenAI GPT인데, 대형 텍스트 코퍼스에서 left-to-right Transformer LM을 학습시키는 모델이다. BERT와 GPT는 학습되는 방식에 일부 차이가 있다.
- GPT 는 BooksCorpus(8 억 단어)로 학습된다; BERT 는 BooksCorpus(8 억 단어)와 Wikipedia
(25 억 단어)로 학습된다. - GPT 는 문장 구분자([SEP])과 분류 토큰([CLS])을 사용하는데, 이는 파인튜닝 당시에만 적용된다.
BERT 는 [SEP], [CLS]와 문장 A/B 임베딩을 사전학습동안 학습한다. - GPT 는 32,000 개 단어의 배치 사이즈 100 만 스텝동안 학습된다. BERT 는 128,000 단어의 배치
사이즈 100 만 스텝 동안 학습된다. - GPT 는 모든 파인튜닝 실험에 동일하게 5e-5 의 학습률을 사용한다; BERT 는 development set 에서 가장 성능이 뛰어난 태스크 명시적인 파인튜닝 학습률을 선택한다.