
2021-06-01
막상 무엇에 대해 기술블로그를 시작해야할지 정하지 못해 이것저것 기웃거리다가 역시 뭐든 시작은 가장 근본부터 해야하지 않는가 라는 생각에 Data structure부터 찾아보자 생각했다. 물론 data structure에 대한 글이 나의 블로그에 있지만, reset하고 다시 시작한다는 마음으로 글을 적어본다.
1. Data Structure

Data Structure란 대량데이터를 효율적으로 관리하는 매커니즘 이라고 간단히 말할 수 있겠다. 수많은 사람들이 사용하고, 쌓이는 데이터들은 상상도 할 수 없이 많을 것이다. 이 데이터들을 어디에 어떻게 활용할 것인지, 저장은 어떻게 해야하고 관리는 어떻게 해야할까? 그래서 천재적인 조상님들이 진작 이런고민을 하고, 만들게 된 것이 이 data structure가 아닐까. 데이터가 워낙 방대하고 넘쳐나니 이것들을 효율적으로 관리해야했고, 이런 관리의 원리구조를 나누어 정리해놓은 것이 자료구조라고 생각한다.
이 자료구조를 조금 더 세분화 시켜보면, 순차적으로 나열되는 것(선형구조)와 그렇지 않은 것(비선형구조)로 나누어볼 수 있다. 위 그림에서 보다시피, 크게 두가지로 나누어 볼 수 있으며, 오늘은 선형구조에서 리스트, 스택, 큐까지 적어보려한다.
2. List
리스트는 데이터를 순서대로 나열한 자료구조를 뜻한다.
2-1. Linear List
그림에서 보면 List가 크게 선형과 연결 두가지로 나뉘어있는데, 선형은 연속되는 기억장소에 빈틈없이 저장되는 리스트라고 보면 된다. Array를 생각해보자.
어느 언어에서나 Array를 쉽게 접할 수 있다. Array를 사용해본다면 접근이 매우 용이하다는 것은 누구나 잘알 수 있다. 하지만, 추가나 삭제는 용이하지 않다. 빈틈없이 나열이 되어있는 형태이므로 가운데에 무언가 추가하려면, 맨끝에 새로운 공간을 추가하고, 한칸씩 옆으로 이동시킨 후, 해당 칸에 요소를 추가해야하는 번거로움이 생긴다.
여기서 잠깐! 그렇다면, Array가 Linear List와 같다는 뜻일까? 그렇지 않다. 여러가지 구글링은 해본 결과, Linear List의 종류 중 하나가 Array이며, Array List도 그중 하나이다. (Array와 Array List는 다른 것이다. 말그대로 Array List는 리스트이므로, array처럼 순차적이지만, array와 다르게 중간에 빈공간이 생기는 경우는 없다.)
2-2. Linked List
그렇다면, linked list는 무엇이 다를까? Array와 마찬가지로 데이터가 일직선으로 나열되어 있는 형태로 되어 있다. 하지만, Array와는 다르게 연속된 위치가 아닌 떨어진 영역에 저장된다는 점이다. linked list의 노드(요소)들은 Pointer라는 개념을 가지고 있어, 다음 메모리의 위치를 가리키고 있다. 각 노드는 데이터와 포인터로 이루어져있기 때문에 Random Access가 불가능하다. 즉, Array처럼 index access가 불가능하다는 말이다. 반드시 pointer로 연결된 노드를 통해서만 접근이 가능하며, 순차적으로 접근해야만 한다. 아래그림으로 조금 더 쉽게 이해할 수 있다.
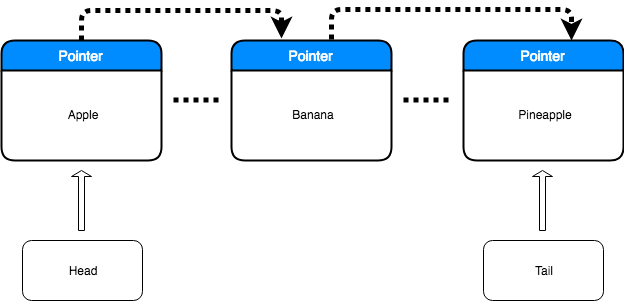
* 추상자료형?
자료구조를 찾아보며, Array와 List에 대해 찾아보니 추상자료형이라는 단어가 보여 찾아보게되면서 stack, queue와 array,list와의 관계가 조금 더 쉽게 이해할 수 있게 되었다. 추상자료형은 ADT라고도 하는데 Abstract Data Type의 줄임말로써,자료형에 대한 수학적 모델을 지칭한다. 쉽게 말해, 행동만 정의하는 것이다. 실제 구현방법은 보여주지 않는다.
Stack과 Queue는 자료형의 연산, 그 행동만 정의돼 있고, 구현 방법은 정의되어 있지 않은 추상 자료형이다. 하지만 Array와 Linked List는 연속적으로 저장되어 있거나 다음 데이터의 위치를 저장하는 방식이어야 하는 자료구조다. 추상 자료형은 정해진 것이 아니라, 많이 사용되는 것이 정해져있으나 구현목적에 따라 달라질 수 있다.
3. Stack & Queue
Stack
1. Stack이란?
메모리안에 있는 데이터를 효율적으로 처리하기 위해 만들어진 처리방식 중 하나로, LIFO(Last In First Out) 또는 FILO(First In Last Out) 로 기억하면 되겠다.
아래 그림을 보자.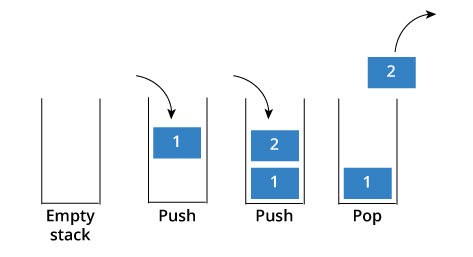
다음과 같은 4가지 작업이 수행된다.
Push : 스택에 추가.스택이 가득 차면 Overflow conditiond이라고 한다.
Pop : 스택에서 제거. 항목은 역순으로 표시된다. 스택이 비어 있으면 Underflow condition 이라고 한다.
Peek 또는 Top : 스택의 최상위 요소를 반환한다.
isEmpty : 스택이 비어 있으면 true, 그렇지 않으면 false를 반환.
2. stack의 실생활예제
stack의 시간복잡도는 O(1)이며, 실생활에서는 쌓여있는 접시, 프링글스를 생각해보면 쉽게 이해할 수 있다. 또한, 포토샵같이 같은 위치에서 다시 실행 취소 기능, 웹 브라우저의 앞으로 및 뒤로가기 기능, 트리 순회 같은 많은 알고리즘에서 사용되며, N-Queen 문제 같은 역추적 문제에서도 이전상태로 돌아와 다른 길로 들어갈때, 이전상태를 저장하는 부분에서 stack이 필요하기도 하며, 메모리 기본관리로 stack을 사용하기도 한다.
Queue
1. Queue란?
선형 리스트의 한쪽에서는 삽입, 다른 한쪽에서는 삭제 작업이 이루어지도록 구성한 자료구조이며, FIFO(First in First Out)를 기억하자. 정해진 한 곳(top)을 통해서 삽입, 삭제가 이루어지는 스택과는 달리 한쪽 끝에서 삽입 작업이, 다른 쪽 끝에서 삭제 작업이 이루어진다. 이때 삭제만 수행되는 곳을 front나 head, 삽입만 이루어지는 곳을 rear나 tail이라 부른다.
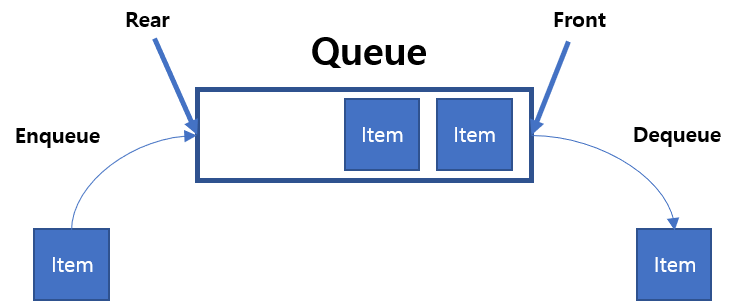
Queue는 다음과 같은 작업이 실행된다.
Enqueue: 대기열에 항목을 추가. 대기열이 가득 차면 Overflow condition이라고한다.
Dequeue: 대기열에서 항목을 제거. 항목은 push된 순서대로 pop. 대기열이 비어 있으면 Underflow condtion이라 한다.
Front: 대기열에서 전면 항목을 가져온다.
Rear: 대기열에서 마지막 항목을 가져온다.
2.Queue의 실생활예제
Queue의 시간복잡도는 O(N)이며, 흔히 차를 타고 여행을 갈 때, 지나가는 톨게이트를 생각하면 쉽다. 먼저 도착한 차가 먼저 지나갈 수 있는 모습을 생각하자. Queue는 프로세스 관리, 너비 우선 탐색(BFS, Breadth-First Search) 구현이나 캐시(Cache) 구현에 활용될 수 있다.
블로그를 적으면서도, 많이 부족하다는 것을 느꼈다. '깊이있게' 공부하는 건 언제나 어려운 것 같다. 사실 이번 글도 그렇게 깊이 있는지는 모르겠다.. 조금 더 노력하자!
