캐시의 등장
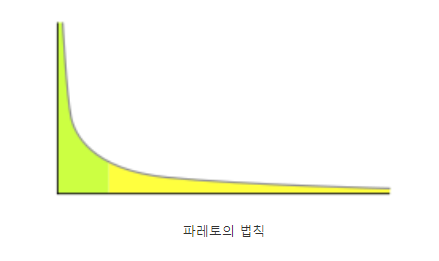
ex) 백화점의 20%의 VIP 고객 지출이 백화점 전체 매출의 80%를 차지한다.
상위 소득 20%의 국민이 국세 세금 전체의 80%를 차지한다.
이 처럼 20%의 사람이 80%를 차지하는 파레토의 법칙을 볼 수 있다.
마찬가지로 프로그래밍에서도 자주 반복해서 사용되는 데이터들이 존재한다.
이러한 데이터들을 빠르게 접근하여 사용할 수 있다면 프로그래밍 성능도 향상 될 것이 때문에 탄생한 것이 캐시이다.
캐시에는 어떤 데이터를 담아야할까?
그 전에 앞서 메모리 공간구조를 파악해야한다.
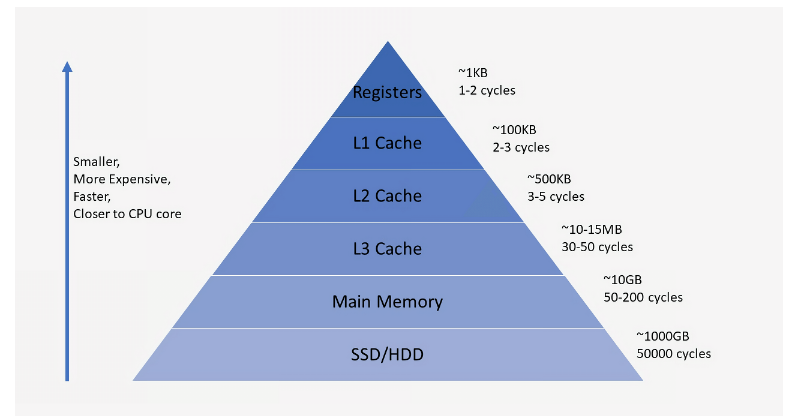
캐시 메모리는 RAM과 CPU사이의 버퍼역할을 하는 매우 빠른 메모리 타입이다.
좀 더 깊이 있는 지식과 캐시 영역
https://mingrammer.com/translation-the-hidden-components-of-web-caching/ 참고하면 좋을거 같다.
모든 데이터를 캐시에 담기에는 캐시 저장공간이 작기 때문에 데이터를 선별해야한다. 이때 사용되는 것이 지역성이다. 지역성의 종류는 시간 지역성, 공간 지역성, 순차 지역성으로 구성된다.

시간적 지역성
특정 데이터가 한번 접근되었을 경우, 가까운 미래에 또 한번 데이터에 접근할 가능성이 높은 것을 의미
ex) 메모리상의 같은 주소에 여러 차례 쓰기를 수행할 경우 상대적으로 작은 크기의 캐시를 사용해도 효율성을 볼수있다.
공간적 지역성
특정 데이터와 가까운 주소가 순서대로 접근되었을 경우 공간적 지역성.
(사용되었던 데이터의 인접데이터사 사용될 가능성을 가진것)
캐시나 디스크 캐시의 경우 한 메모리 주소에 접근 할때 그 주소와 함께 해당 블록 전부를 캐시에 가져온다. 이때 메모리 주소를 오름,내림 차순으로 접근하여 캐시에 이미 저장된 같은 블록의 데이터를 접근하게 되므로 효율성 증가.
순차 지역성
데이터가 순차적으로 접근 되었을 때 사용되면 효율성이 좋다.
for문을 예로 들 수있다.
시간 지역성은 for(int i~) 에서 이 i라는 변수는 for문이 끝날때까지 i를 쓸 확률이 높다
공간지역성 for문에서 배열에 접근 할 경우 배열은 이 포문이 끝날때 까지 계속해서 접근할 가능성이 높다.
순차 지역성 만약 arr[0],arr[1],arr[2] 에접근하였다면 다음 arr[3] 에접근할 확률이 높은걸 확인
추가
cache hit : 참조하려는 데이터가 캐시에 존재할 때 cache hit라 합니다.
cache miss : 참조하려는 데이터가 캐시에 존재 하지 않을 때 cache miss라 합니다.
cache hit ratio(캐시 히트율) : (cache hit 횟수)/(전체참조횟수) = (cache hit 횟수)/(cache hit 횟수 + cache miss 횟수)
cache miss가 발생하는 경우 실제 저장공간에서 데이터를 가져와야 하기 때문에 비효율성 발생. 캐시의 활용도를 높이기 위해선 캐시 히트율을 높이는 것이 중요
자주 참조 되며 수정이 잘 발생하지 않는 데이터들을 구성,ex) 상품카테고리 등등
Cache 사용 구조
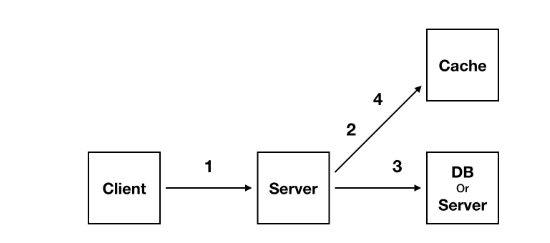
- client로 부터 요청을 받는다.
- Cache와 작업을 한다.
- 실제 DB와 작업한다.
- 다시 Cache와 작업한다.
캐시는 위와 같은 흐름으로 작용된다. 하지만 캐시를 어떻에 사용하냐에 따라 look aside cache, write back으로 나뉜다.
- look aside cache
- Cache에 Data 존재 유무확인
- Data가 있다면 Cache 의 Data 사용
- Data가 없다면 Cache의 실제 DB Data 사용
- DB에서 가져온 Data를 Cache에 저장
-
캐시를 한법 접근하여 데이터 유무에 따라 있으면 캐시 데이터를 사용하며 없다면 DB 혹은 API를 호출한다.
-
write back
- Data를 Cache에 저장
- Cache에 있는 Data를 일정 기간동안 Check
- 모여 있는 Data를 DB에 저장
- Cache에 있는 Data 삭제
- write back은 Cache를 다르게 이용하는 법. DB 접근 횟수가 적을수록 시스템은 효율적이다. 데이터를 쓰거나 많은 데이터를 읽게되면 DB에서 Disk를 접근하게 된다. 이렇게 되면 어플리케이션 속도 저하가 발생 하기에 write back은 데이터를 cache에 모으고 일정 주기 또는 크기가 된다면 한번에 처리하는 것이다.
단점: 캐시에 저장했다가 나중에 디비에 저장하는건데 프로그램이 꺼지면 캐시에 저장된 데이터가 날라가기에 위험함.
그래서 Redis캐시 같은걸 써서 막아줌 redis는 다음장에 공부하여 쓸것이다.
