자바로 애플리케이션을 개발할 때, 트랜잭션을 쉽게 관리해주는 @Transactional 이라는 애너테이션이 있다.
@Transactional (AOP 설명하기 좋은 예, 치트키)
트랜잭션을 시작하고, 예외가 발생하지 않으면 커밋, 예외가 발생하면 롤백, 이 반복적인 코드를 AOP를 통해 해결해주는 것이 바로 @Transactional Annotation이다.
@Transactional의 동작방식
- 트랜잭션 시작
- 메서드 호출
- 트랜잭션 커밋 or 롤백
@Transactional 붙이고 터지면 롤백해주니 얼마나 편한지.. 뗄래야 뗄수가 없다.
하지만 개발자의 의도대로 동작하지 않는 상황이 발생할 때가 있을 수 있는데,
데이터를 DB 저장하면서 API도 쏘고 API에서는 콜백으로 처리 결과를 수신하여 데이터를 수정하는데 데이터가 없다거나, 기존 변경사항이 반영되어 있지 않다거나 발생할 수 있는 문제들이 있다.
이유는 엄청 간단하지만 개념이 잘 서있지 않는다면 헤맬 수 있는 부분이라 생각이 들어서 이 핵심만 알고 있으면 좋을 것 같다.
그 이유에 대해 코드를 살펴보면서 이야기 해보고자 한다.
샘플 코드
Model
@Getter
@Entity
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Item {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
public Item(String name) {
this.name = name;
}
}Service Layer
public class ItemService {
private final ItemRepository itemRepository;
public ItemService(ItemRepository itemRepository) {
this.itemRepository = itemRepository;
}
@Transactional
public void save(List<String> names) {
for (String name : names) {
itemRepository.save(new Item(name));
}
}
public long count() {
return itemRepository.count();
}
}ItemService의 save 메서드는 이름 목록을 받아 아이템을 저장하는 메서드이다.
테스트도 엄청 간단하다.
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.NONE)
class ItemServiceTests {
@Autowired
private ItemService itemService;
@Test
void t1() {
// given
Faker faker = new Faker(Locale.KOREA);
int numberOfItems = 10000;
List<String> names = IntStream.range(0, numberOfItems).mapToObj(it -> faker.book().title()).toList();
// when
itemService.save(names);
// then
Assertions.assertThat(itemService.count()).isEqualTo(numberOfItems);
}
}저장 된 후 카운트를 조회하면 저장된 갯수를 가져올 수 있다.
그렇다면 다른 스레드에서 처리중인 작업 결과가 순차적으로 반영되는가?
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.NONE)
class ItemServiceTests {
@Autowired
private ItemService itemService;
@Test
@DisplayName("다른 스레드에서 처리 중일 때, 신규 아이템 목록 정보를 가져올 수 있는가?")
void t2() {
// given
Faker faker = new Faker(Locale.KOREA);
int numberOfItems = 10000;
List<String> names = IntStream.range(0, numberOfItems).mapToObj(it -> faker.book().title()).toList();
// when
CompletableFuture<Void> async = CompletableFuture.runAsync(() -> itemService.save(names));
Assertions.assertThat(itemService.count()).isGreaterThan(0);
async.join();
// then
Assertions.assertThat(itemService.count()).isEqualTo(numberOfItems);
}
}@Transactional의 동작방식에 대해서 이해하고 있다면 테스트 케이스는 실패한다는 것을 예상할 수 있을 것이다.
그러면 왜 실패할까?
잠깐, 데이터베이스 이야기를 해야할 것 같다.
트랜잭션은 무엇인가?
트랜잭션은 여러 데이터베이스 작업을 하나의 논리적 작업 단위로 묶는 방법, 또는 단위
(데이터베이스마다 트랜잭션 격리수준이 다르지만 MariaDB 기준으로 REPEATABLE READ 이기 때문에 아래와 같은 상황이 재현된다.)
세션이 각기 다른 콘솔 2개를 가지고 확인해보겠다.
1번 세션은 autocommit을 false로 지정하고 트랜잭션을 커밋하지 않은 상태
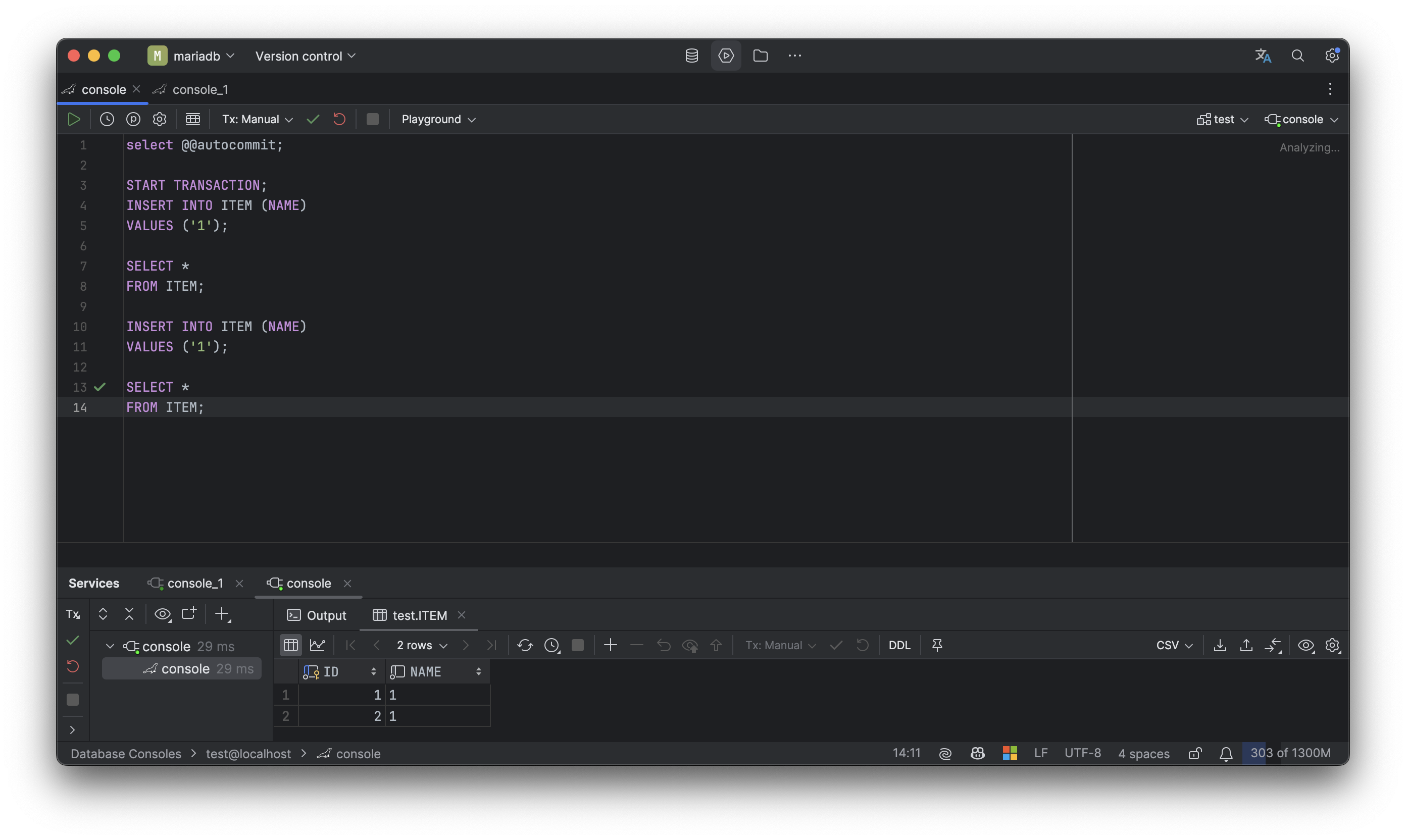
트랜잭션을 커밋하지는 않았지만 추가한 목록에 대한 것을 조회해볼 수 있다.
2번 세션에서는 아이템 목록을 조회했지만 결과가 나오지 않는다. 1번 트랜잭션이 커밋되지 않아서 그렇다.
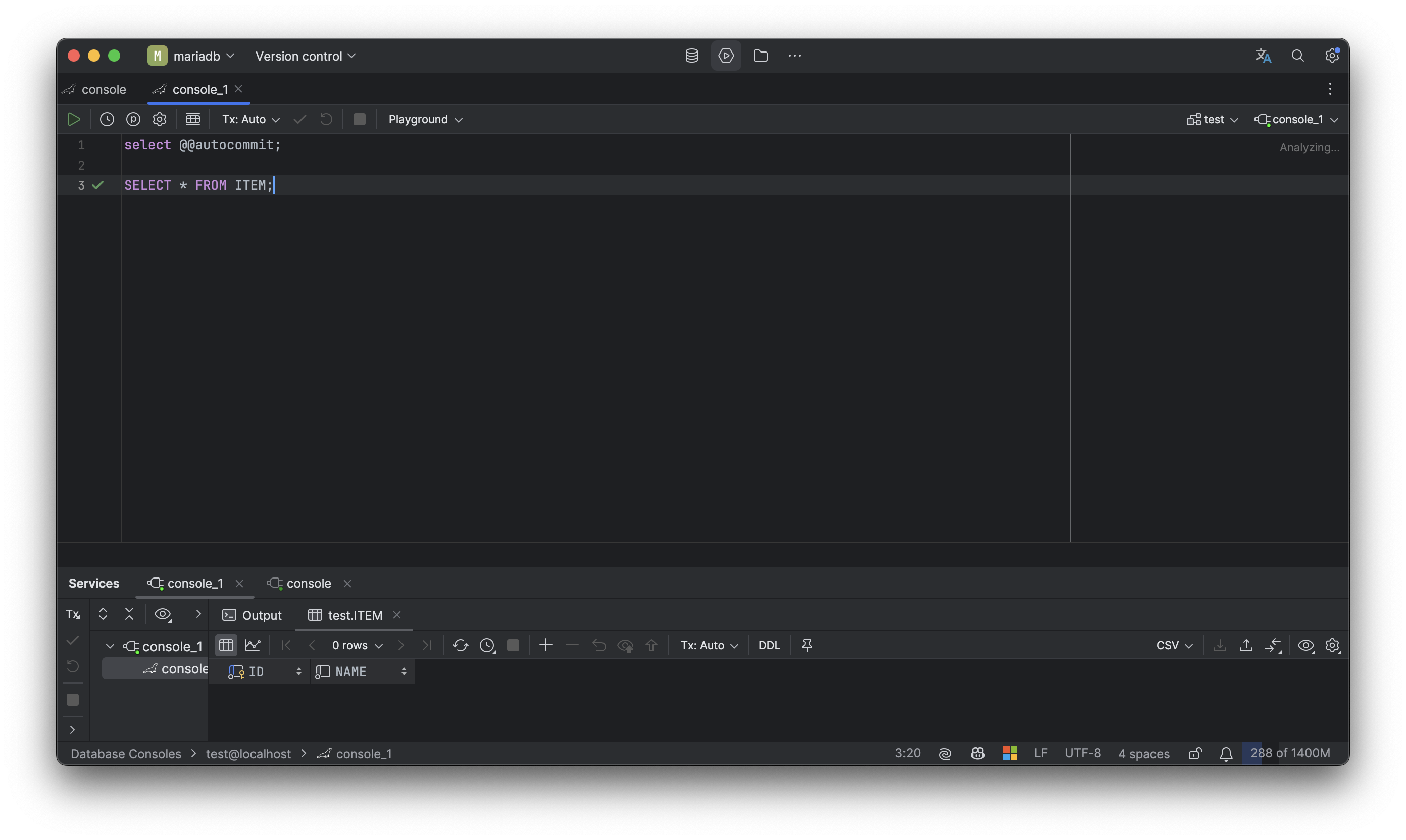
그러면 반대로 2번 세션에서 커밋이 나간 name = '2' 가 1번 세션에서 조회가 될까?
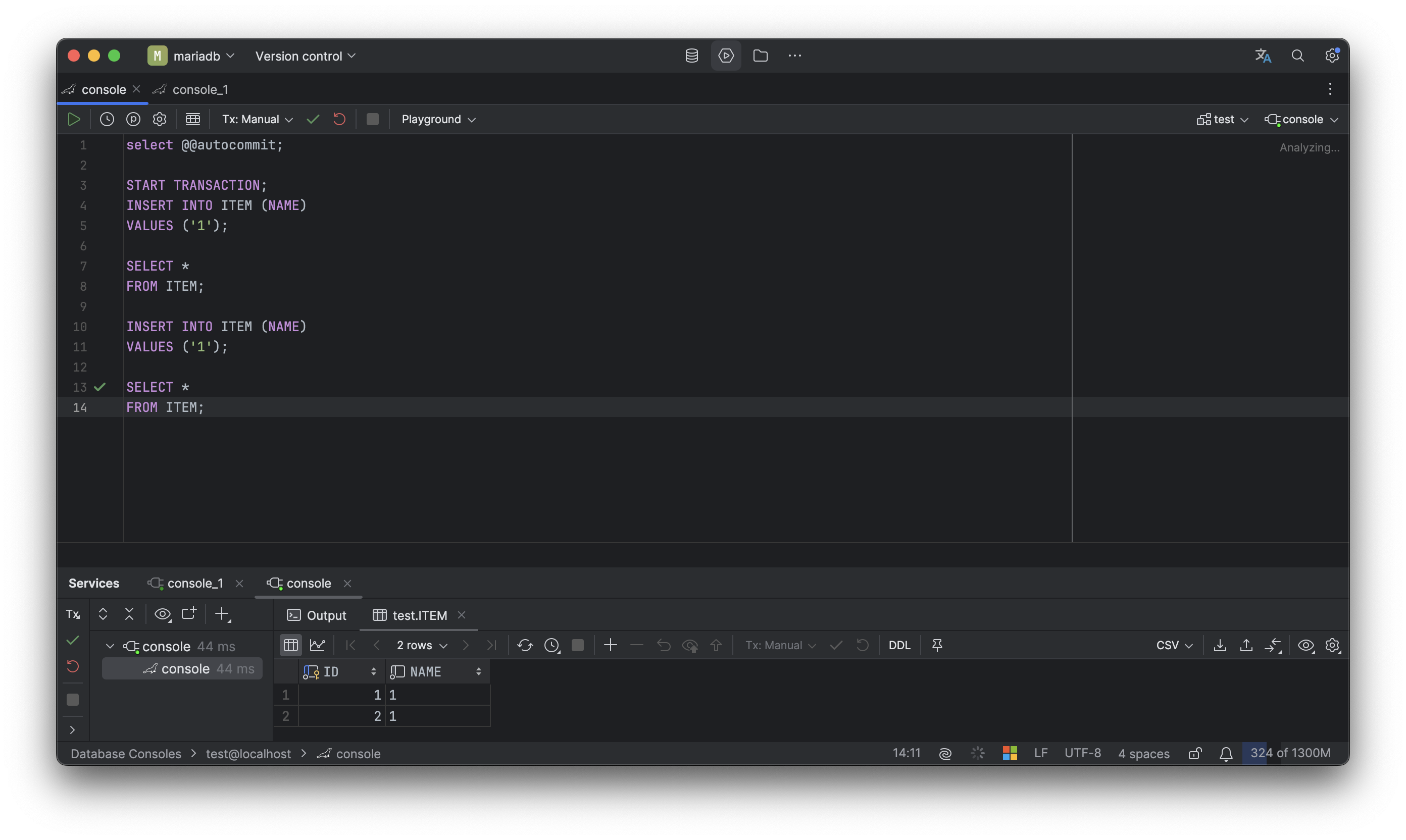
트랜잭션을 획득한 시점이 다르기 때문에 당연히 안된다.
COMMIT이 이뤄지고 나면 1번 세션과 2번 세션 모두 목록을 조회할 수 있다.
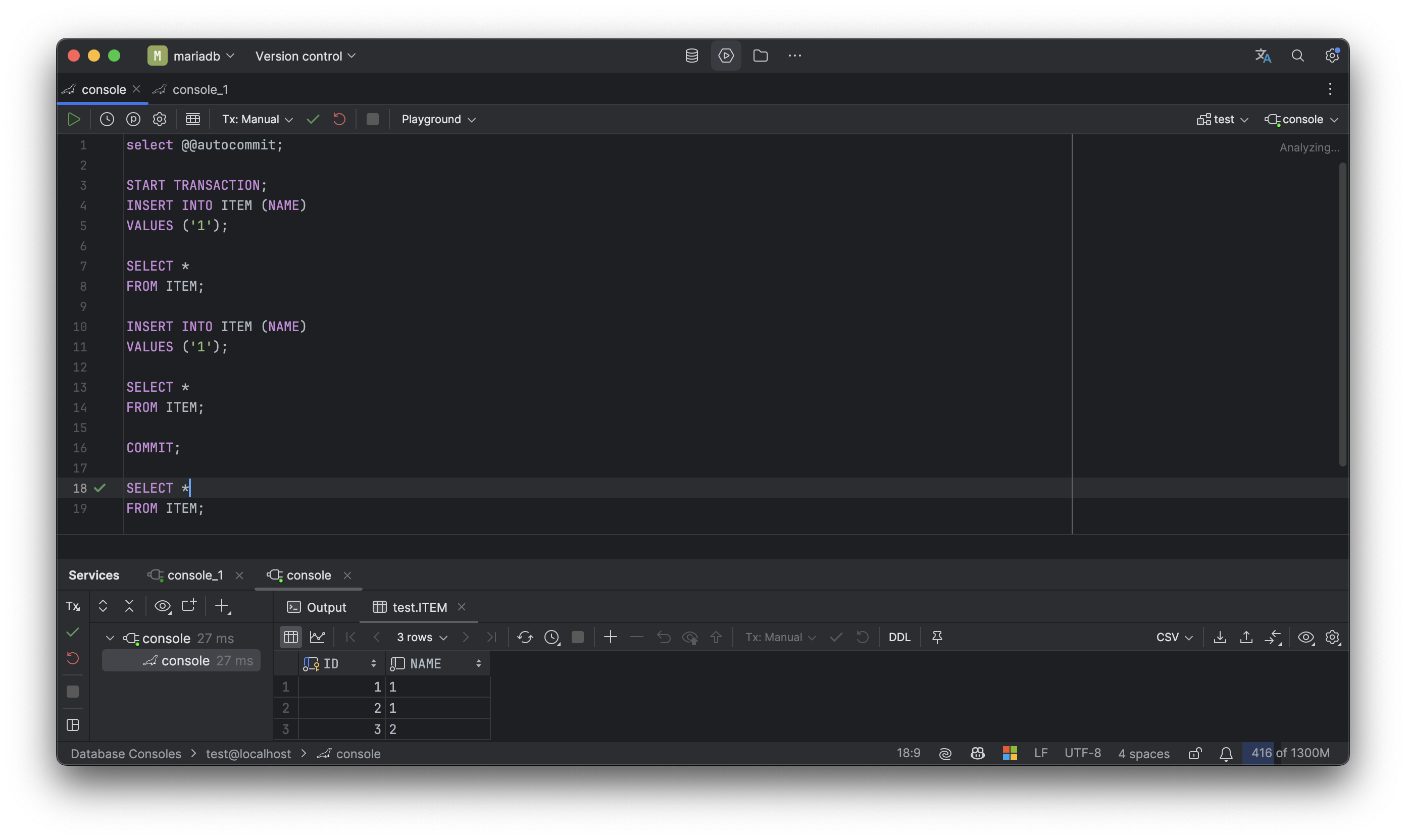
다시 위의 코드를 살펴보면
@Transactional
public void save(List<String> names) {
for (String name : names) {
itemRepository.save(new Item(name));
}
}save 메서드는
START TRANSACTION
INSERT INTO ITEM (NAME) VALUES ('$1')
INSERT INTO ITEM (NAME) VALUES ('$1')
INSERT INTO ITEM (NAME) VALUES ('$1')
..
..
COMMIT와 같은 코드라고 해석할 수 있다.
즉, 커밋이 나가기 전에는 당연히 '다른 작업'에서는 알 수가 없다. (같은 트랜잭션 안에서는 알 수 있다.)
START TRANSACTION
INSERT INTO ITEM (NAME) VALUES ('$1');
INSERT INTO ITEM (NAME) VALUES ('$1');
INSERT INTO ITEM (NAME) VALUES ('$1');
..
..
SELECT * FROM ITEM;
COMMIT@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;위와 같은 옵션을 사용하면 채번 전략을 데이터베이스에게 위임하기 때문에 쓰기 지연이 동작하지 못하고 즉시 flush가 되어 insert 구문이 동작하는 것을 볼 수 있을 것이다.
하지만, insert sql이 내 눈에 보인다고 해서 DB에 반영되는 것은 아니다.
데이터베이스는 무조건 'COMMIT'이 있어야 데이터가 반영된다.
커밋이 빨리 쳐지는게 상태반영에 이점을 가져갈테지만, 롤백에 대한 부담도 생기기 마련이고,
트랜잭션 단위가 너무 작다보면 트랜잭션을 생성하는 비용이 커질 수도 있다.
트랜잭션 작업의 단위가 너무 크게 묶이는건 아닌지 의심하고 트랜잭션의 단위에 대해 고민하면서 코드를 해보면 좋을 것 같다.
내가 의도한대로 동작하게끔 작성하려면 이 가장 기본적인 커밋에 대한 부분을 알면 좋을 것 같아서 작성해보았다.
그럼 20000
