그룹함수
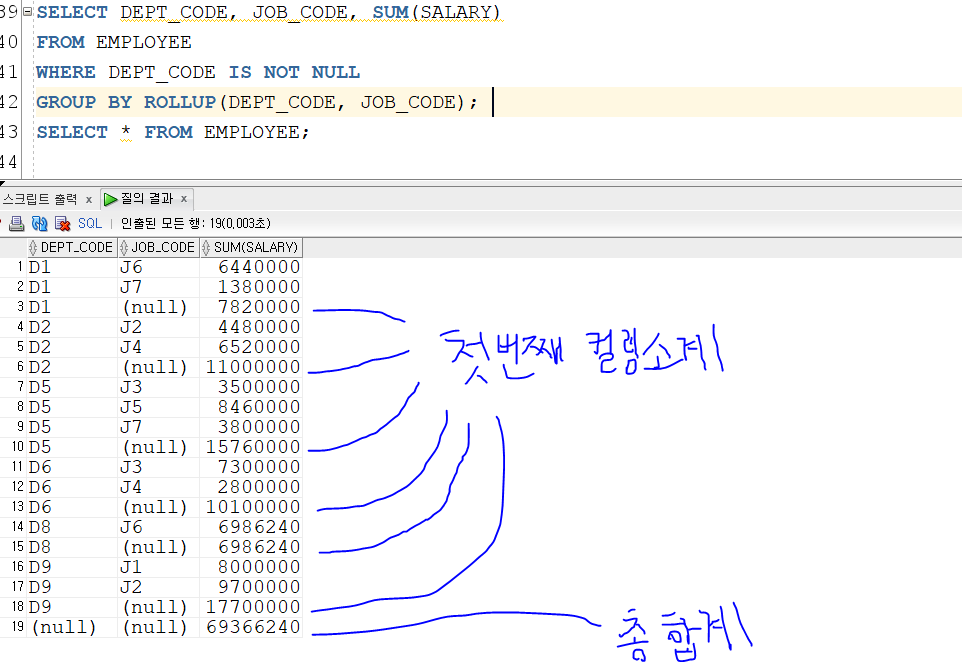
✅ ROLL UP
- 소그룹 간의 소계를 계산하는 함수
- GROUP BY ROLLUP(컬럼명)
위와 같이 첫 번째 컬럼의 집계와 총계가 나온다 (부서와 직업을 묶음)
✅ CUBE
- GROUP BY 항목들 간 모든 경우의 수로 그룹을 생성하여 집계를 낸다.
- CUBE는 ROLLUP보다 조금 더 상세한 결과를 낸다.
ROLL UP 과 다르게 두번째 소계까지 출력되는 것을 볼 수 있다
(첫번째 컬럼 소계 + 두번째 컬럼 소계 + 총 합계)
✅ GROUPING
- 집계한 결과에 대한 분기처리 가능
- GROUPING 함수를 실행하면, ROLLUP, CUBE로 집계된 총계1을 반환 아니면 총계0을 반환
- 1일때 null임 , 0일때 null 아님
SELECT COUNT(*),
CASE
WHEN GROUPING(DEPT_CODE)=0 AND GROUPING(JOB_CODE)=1 THEN '부서별인원'
WHEN GROUPING(DEPT_CODE)=1 AND GROUPING(JOB_CODE)=0 THEN '직책별인원'
WHEN GROUPING(DEPT_CODE)=0 AND GROUPING(JOB_CODE)=0 THEN '부서_직책인원'
WHEN GROUPING(DEPT_CODE)=1 AND GROUPING(JOB_CODE)=1 THEN '총인원'
END AS 결과
FROM EMPLOYEE
WHERE DEPT_CODE IS NOT NULL
GROUP BY CUBE(DEPT_CODE, JOB_CODE);✅ ORDER BY
- 정렬 기준이 되는 속성과 정렬 방식을 지정
-> ex)ORDER BY기준컬럼명정렬방식
-> ORDER BY first_name DESC; - 테이블에서 조회한 데이터 정렬
-- ORDER BY 구문을 사용함
-- SELECT 컬럼명....
-- FROM 테이블명
-- [WHERE 조건식]
-- [GROUP BY 컬럼명]
-- [HAVING 조건식]
-- [ORDER BY 컬럼명 정렬방식(DESC,ASC)] - DESC (내림차순), ASC(오름차순) ,생략시 ASC로 기본값임
SELECT * FROM EMPLOYEE // 부서 코드를 기준으로 오름차순 정렬하고 값이 같으면 월급으로 내림차순함
ORDER BY DEPT_CODE ASC, SALARY DESC;
// 정렬했을 때 NULL값에 대한 처리
// BONUS를 많이 받는 사원부터 출력하기
SELECT * FROM EMPLOYEE
// 옵션을 설정해서 NULL 값 출력위치를 변경할 수 있다.
// ORDER BY BONUS DESC NULLS LAST; -- NULL값을 마지막에다 처리할 수 있다.
// ORDER BY BONUS ASC NULLS FIRST; -- NULL값을 처음으로 처리할 수 있다.
// ORDER BY 절에서는 별칭을 사용할 수 있다
SELECT EMP_NAME, SALARY AS 월급, BONUS
FROM EMPLOYEE
ORDER BY 월급;
// SELECT 문을 이용해서 데이터를 조회하면 RESULT SET이 출력되는데
// RESULT SET에 출력되는 컬럼에는 자동으로 INDEX번호가 1부터 부여가 됨
SELECT *
FROM EMPLOYEE
ORDER BY 1; -- 만약 1이 아닌 2라면 테이블의 2번에있는 EMP_NAME으로 정렬해줌
// 아래 예시 그림을 보고 이해하자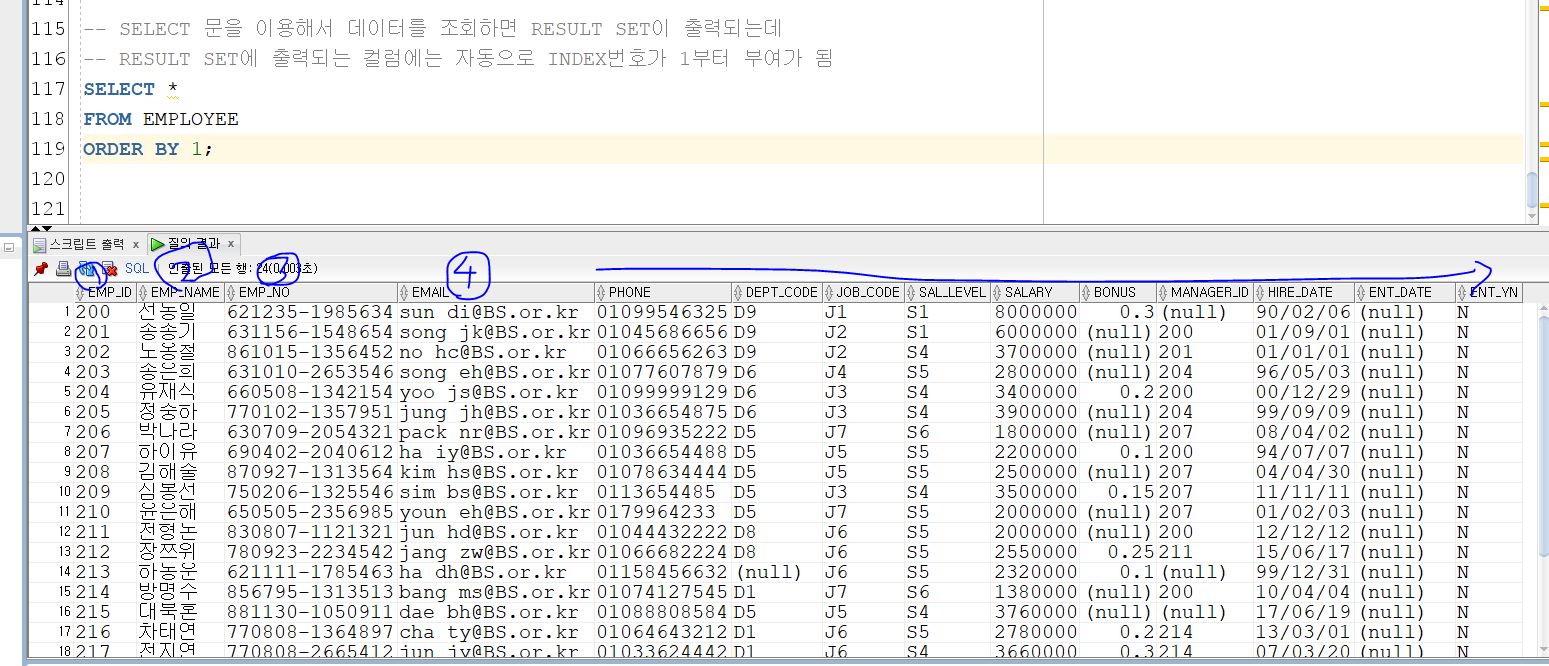
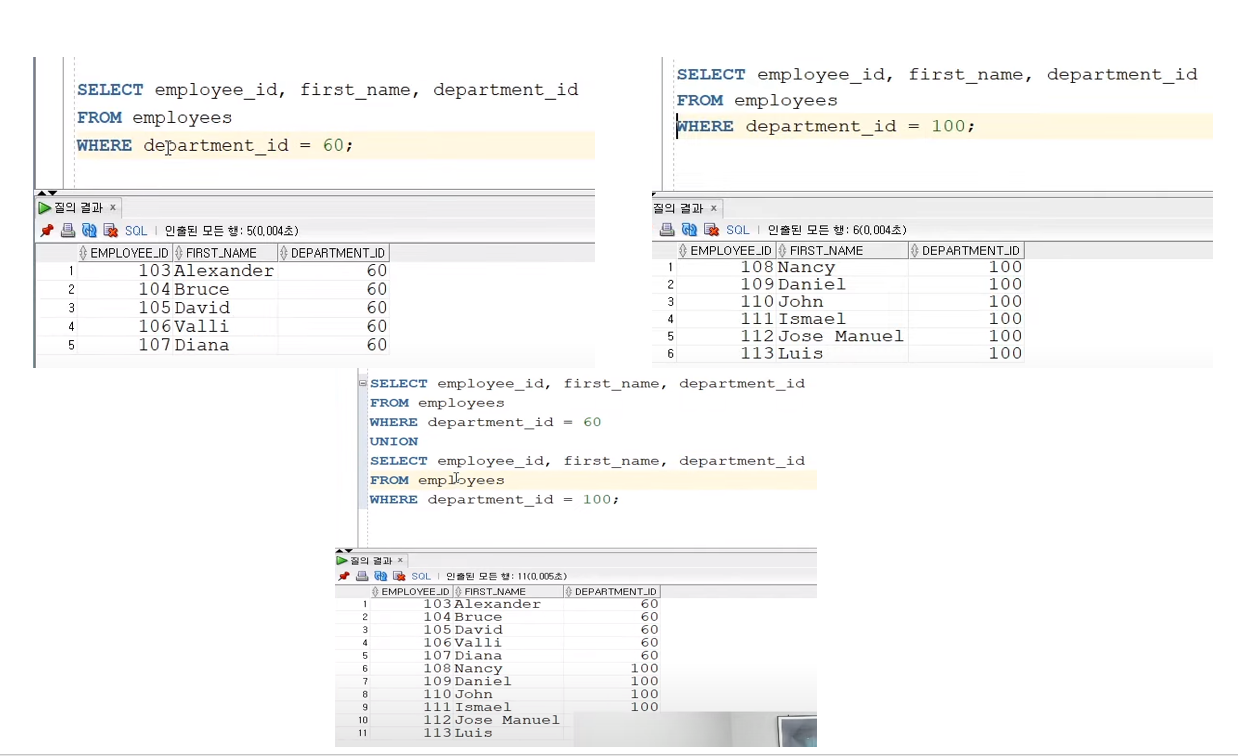
집합 연산자
- 기본 규칙 : 각 SELECT문의 컬럼수가 같아야하며, 데이터 타입도 같아야한다
✅ UNION
- 두개 이상의 SELECT 문을 합치는 연산자
- 합집합으로 중복을 제외함
- 합치려는 두 SELECT문의 조회 컬럼이 일치해야 한다
- SELECT문 UNION SELECT문 순으로 작성한다
✅ UNION ALL
UNION과 다르게 중복을 포함
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY // 컬럼수 4개 (각 컬럼별 타입도 동일)
FROM EMPLOYEE
WHERE DEPT_CODE = 'D5'
UNION // 중복값은 하나만 출력해줌
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY // 컬럼수 4개 (각 컬럼별 타입도 동일)
FROM EMPLOYEE
WHERE SALARY >= 3000000;
// 합치면 8개 나옴
// UNION : 중복값은 하나만 나옴
// UNION ALL : 중복값 생략하지 않고 모두 다 출력
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE DEPT_CODE = 'D5'
UNION ALL // 중복값들 다 출력해줌
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE SALARY >= 3000000;
// 다른 테이블에 있는 데이터 합치기
SELECT EMP_ID, EMP_NAME, SALARY
FROM EMPLOYEE
UNION
SELECT DEPT_ID, DEPT_TITLE, NULL // 각 SELECT문의 컬럼개수가 맞지 않기때문에 NULL로 맞춰줌
FROM DEPARTMENT;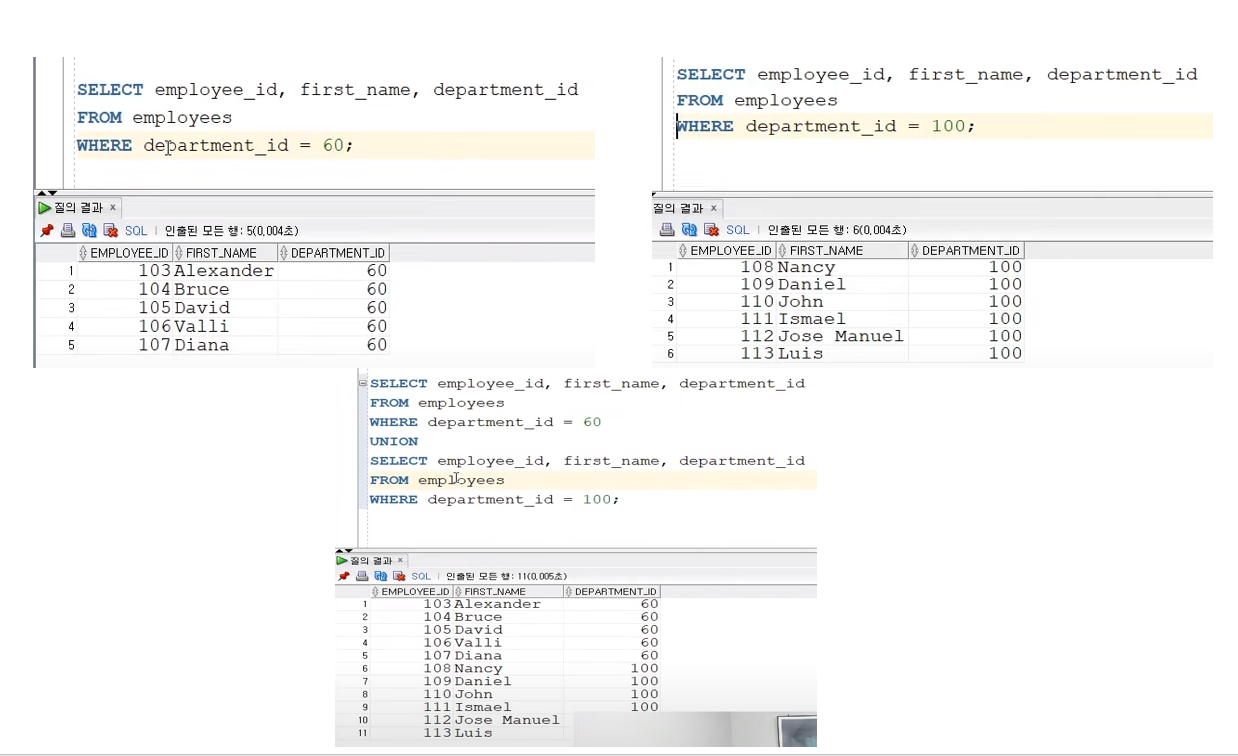
✅ MINUS
- 선행 SELECT 결과에서 다음 SELECT 결과와 겹치는 부분을 제외한 나머지 부분 추출 (차집합)
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY -- 컬럼수 4개
FROM EMPLOYEE
WHERE DEPT_CODE = 'D5'
MINUS // 차집합 공통된건 빼줌
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY -- 컬럼수 4개
FROM EMPLOYEE
WHERE SALARY >= 3000000;✅ INTERSECT
- 선행 SELECT 결과에서 다음 SELECT 결과와 공통된 부분만 출력
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE DEPT_CODE = 'D5'
INTERSECT // 공통된 부분만 출력
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE SALARY >= 3000000;✅ GROUPING SET
- GROUP BY 절이 있는 구문을 하나로 작성하게 해주는 기능
// 부서, 직책별, 매니저별 급여 평균
SELECT DEPT_CODE, JOB_CODE, MANAGER_ID, AVG(SALARY)
FROM EMPLOYEE
GROUP BY DEPT_CODE, JOB_CODE, MANAGER_ID;
// 부서, 직책별 급여평균
SELECT DEPT_CODE, JOB_CODE, AVG(SALARY)
FROM EMPLOYEE
GROUP BY DEPT_CODE, JOB_CODE;
// 부서, 매니저별 급여평균
SELECT DEPT_CODE, MANAGER_ID, AVG(SALARY)
FROM EMPLOYEE
GROUP BY DEPT_CODE, MANAGER_ID;
// 위 3가지를 하나로 묶어서 표현
SELECT DEPT_CODE, JOB_CODE, MANAGER_ID, AVG(SALARY)
FROM EMPLOYEE
GROUP BY GROUPING
SETS((DEPT_CODE, JOB_CODE, MANAGER_ID),(DEPT_CODE, JOB_CODE), (DEPT_CODE,MANAGER_ID));
우측 상단 햇님모양 클릭하셔서 무조건 야간모드로 봐주세요!!