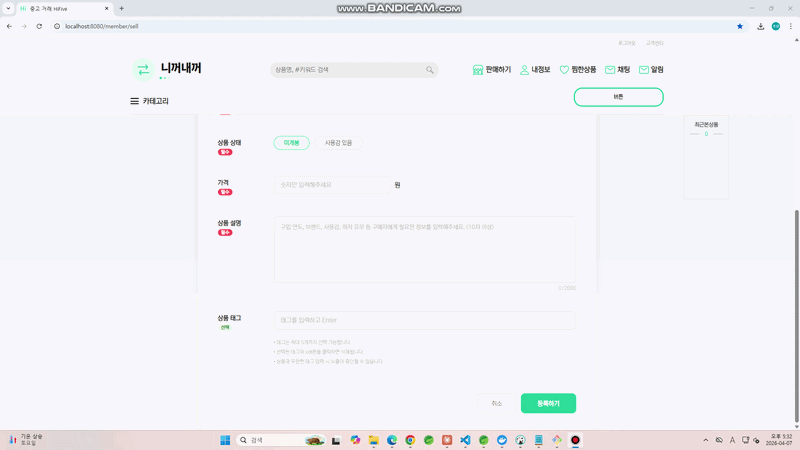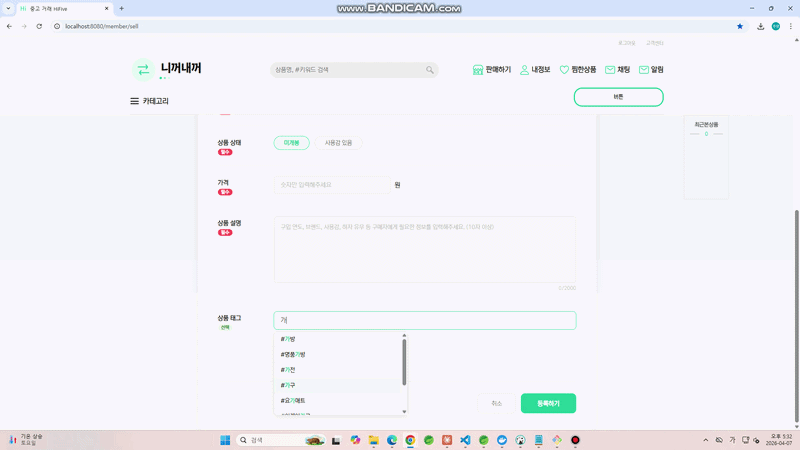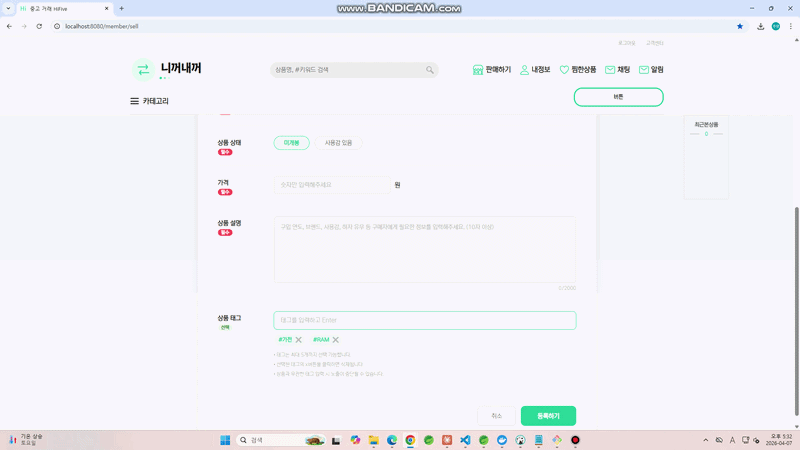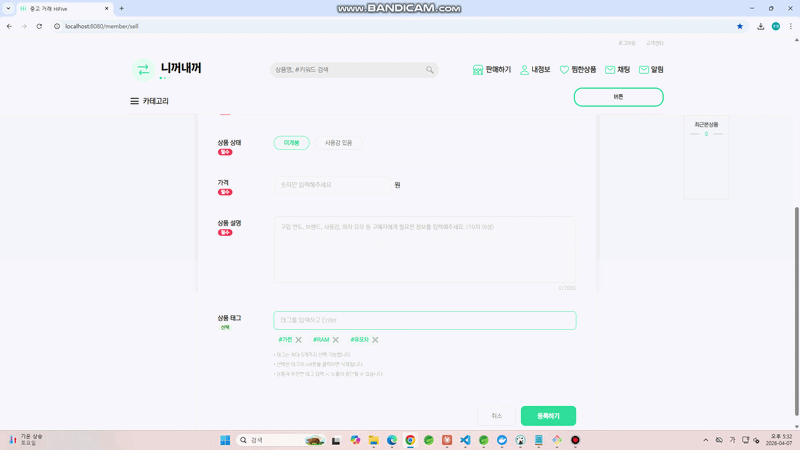
상품을 등록할 때 상품 태그를 선택해서 등록하는 기능이 있다.
만약 키보드 를 입력했을 때, #기계식키보드 #무선키보드 #키보드 모두 나오게 하려면 어떻게 해야할까
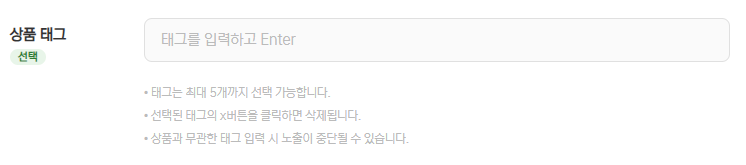
✅ 전체 구조
사용자 입력 → 서버 API → Elasticsearch 검색 → 결과 반환 → 자동완성 UI
조금 더 구체적으로 보면
[브라우저] "키보" 입력
↓ AJAX GET /product/tags?keyword=키보
[TagController]
↓
[TagService]
↓
[TagEsDao] → Elasticsearch "tags" 인덱스 검색
↓
["#키보드", "#기계식키보드", "#무선키보드"] 반환
↓ JSON
[브라우저] 드롭다운 표시 ✅✅ 디비를 사용하지 않고 왜 Elasticsearch 로 처리할까?
만약 디비에서 LIKE '%키보드%' 로 검색하면
대용량 데이터일 경우 너무 느리며, 부분 검색이 한계가 있고, 인덱스를 만들어도 소용이 없다
하지만 Elasticsearch 로 하면 텍스트를 잘게 쪼개 토큰으로 저장하여 초고속으로 검색할 수 있다
✅ 인덱스 설계
Elasticsearch 에서 텍스트를 잘게 쪼개서 토큰으로 저장할 때 Analyzer (분석기) 가 담당한다.
이 분석기는 총 3단계의 방법으로 처리하는데
char_filter (글자 전처리)
tokenizer (단어 분리)
filter (토큰 후처리)
-> 엘라스틱 서치 인덱스에 저장
로 동작한다.
우선 전체 코드를 보면
## tag-settings.json
## 이 json 파일로 분석기(Analyzer) 을 만듬
{
"index": {
"max_ngram_diff": 20
},
"analysis": {
"char_filter": {
"hash_remover": {
"type": "pattern_replace",
"pattern": "#",
"replacement": ""
},
"script_boundary": {
"type": "pattern_replace",
"pattern": "(?<=[가-힣])(?=[a-zA-Z0-9])|(?<=[a-zA-Z0-9])(?=[가-힣])",
"replacement": " "
}
},
"filter": {
"ngram_filter": {
"type": "ngram",
"min_gram": 1,
"max_gram": 20
}
},
"analyzer": {
"tag_index_analyzer": { ## 분석기 종류 1
"type": "custom",
"char_filter": ["hash_remover", "script_boundary"],
"tokenizer": "whitespace",
"filter": ["lowercase", "ngram_filter"]
},
"tag_search_analyzer": { ## 분석기 종류 2
"type": "custom",
"char_filter": ["hash_remover", "script_boundary"],
"tokenizer": "whitespace",
"filter": ["lowercase"]
}
}
}
}## tag-mapping.json
## 이 json 파일에 위에서 만든 json 파일을 연결해야 동작함
## ES에서 검색 OR 저장할 때 알아서 맞는 분석기랑 매칭해줌
{
"properties": {
"tagName": {
"type": "text",
"analyzer": "tag_index_analyzer", // 저장할때 해당 분석기 사용
"search_analyzer": "tag_search_analyzer", // 검색할때 해당 분석기 사용
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"useCount": {
"type": "integer"
}
}
}
우선 char_filter (전처리) 부터 확인하자.
모든 키워드들은 앞에 # 이 붙어있는 데이터로 # 을 제거해주는 작업이 필요하다
추가로 한글과 영문을 분리하는 작업이 필요하다
| 이름 | 역할 | 예시 |
|---|---|---|
hash_remover | # 기호 제거 | #맥북 -> 맥북 |
script_boundary | 한글과 영문 경계에 공백 삽입 | M1맥북 -> M1 맥북 |
왜냐하면 M1맥북 이 데이터는 하나로 보기 때문에 "맥북" 이라 검색해도 데이터가 찾아지지 않는다.
두번째로 tokenizer (단어분리)
| 이름 | 역할 | 예시 |
|---|---|---|
Whitespace | 공백기준으로 분리 | M1 맥북 -> ["M1", "맥북"] |
마지막으로 filter (토큰 후 처리)
| 이름 | 역할 | 예시 |
|---|---|---|
lowercase | 대소문자 통일 | RTX -> rtx |
ngram_filter | 모든 위치에서 부분 문자열 생성 | ["맥", "맥북", "맥북프", ... "북", "북프", ... "프로"]- |
위에서 사용자정의 필터를 만들때 ngram_filter 타입을 ngram 으로 만들었는데
edge_ngram 과 ngram 두가지 선택지가 있었다.
둘의 차이점은 edge_ngram 은 앞에서만 잘라서 문자열을 만들고, ngram 은 모든 위치에서 자른다.
## edge_ngram -> "맥", "맥북", "맥북프", "맥북프로"
## ngram -> "맥", "맥북", "맥북프", "맥북프로","북", "북프", "북프로","프", "프로","로" ...개발할 때 키보드 를 입력하면 기계식 키보드 도 자동완성이 나오게 구현하고싶어서 ngram 으로 지정
✅ 동작과정 및 비즈니스 로직
DB에서 TAG 테이블에 있는 데이터를 추가하려고 하면
Elasticsearch 에서도 데이터를 추가해줘야 한다
즉 데이터 동기화 문제를 해결해야 한다.
대규모 서비스에서는 주로 Kafka 를 사용하여 이벤트를 발행해 Elasticsearch 에 데이터를 넣어준다
하지만 소규모 프로젝트에서는 Kafka 를 도입하는 것이 비용 및 시간적으로 부담이 되기때문에
애플리케이션 레벨에서 직접 소스코드로(비즈니스 로직) 동기화를 시켜준다.
- 서버 시작시
-> 서버 재시작이 ES 데이터를 건드리지 않고, 인덱스(테이블) 이 이미있으면 동작 X
| 클래스 | 역할 |
|---|---|
| ProductEsInitializer | products 인덱스 없으면 settings/mappings JSON으로 생성 |
| TagDataInitializer | tags 인덱스 없으면 settings/mappings JSON으로 생성 |
- 비즈니스 로직 - 실시간 동기화
| 기능 | 로직 |
|---|---|
| 상품등록 | (상품저장, 상품파일저장) DB 저장 후 + ElasticSearch 에 저장 |
| 상품 삭제 | (상품 사용여부 컬럼 N으로 업데이트, 위시 리스트 제거) + ElasticSearch에서 삭제 |
| 거래 상태 변경 | (DB tradeStatus 업데이트) + ElasticSearch에서 tradeStatus 필드만 부분 업데이트 |
| 태그 사용 | DB 저장 + ElasticSearch에서 useCount 필드만 부분 업데이트 |
- 관리자 수동 재동기화
ElasticSearch 에 있는 데이터들도 DB랑 틀어질 수 가 있다.
EX) 서버 배포중 상품등록, 개발 중 인덱스를 날린 경우 등등 ..
이때 마다 서버를 재시작하거나 코드를 건드릴 수 없기 때문에, 관리자 페이지에서 버튼 하나로
DB 값을 기준으로 ES에 다시 밀어넣을수 있는 기능 (동기화) 을 할 수 있도록 만들었다.
아래 코드와 같이, 관리자용 동기화 버튼을 클릭하면
ProductEsDao.bulkIndex() TagEsDao.bulkIndex() 메소드 각각 호출된다.
/** 전체 상품 bulk 인덱싱 (관리자 수동 재동기화용) */
public int bulkIndex(List<ProductDocument> docs) {
if (docs.isEmpty()) return 0;
try {
List<BulkOperation> ops = docs.stream()
.map(doc -> BulkOperation.of(op -> op
.index(i -> i
.index(INDEX)
.id(String.valueOf(doc.getProductId()))
.document(doc)
)
))
.toList();
BulkResponse response = client.bulk(BulkRequest.of(b -> b.operations(ops)));
if (response.errors()) {
response.items().stream()
.filter(item -> item.error() != null)
.forEach(item -> log.error("bulk 실패 id={} reason={}", item.id(), item.error().reason()));
}
return docs.size();
} catch (Exception e) {
log.error("상품 ES bulk 인덱싱 실패: {}", e.getMessage());
return 0;
}
}/** 전체 태그 bulk 인덱싱 (관리자 수동 재동기화용) */
public int bulkIndex(List<TagDocument> tags) {
if (tags.isEmpty()) return 0;
try {
List<BulkOperation> operations = tags.stream()
.map(tag -> BulkOperation.of(op -> op
.index(i -> i
.index("tags")
.id(String.valueOf(tag.getId()))
.document(tag)
)
))
.toList();
BulkResponse response = client.bulk(BulkRequest.of(b -> b.operations(operations)));
if (response.errors()) {
response.items().stream()
.filter(item -> item.error() != null)
.forEach(item -> log.error("태그 bulk 실패 id={} reason={}", item.id(), item.error().reason()));
}
return tags.size();
} catch (Exception e) {
log.error("태그 ES bulk 인덱싱 실패: {}", e.getMessage());
return 0;
}
}💡 Bulk 인덱싱 이란 데이터를 하나씩이 아닌 한번에 여러개 묶어서 저장하는 것
이 방식을 사용하지 않으면 만약 250개의 태그를 하나씩 저장하면 250번의 HTTP 요청으로 인해 느리다.
Bulk 방식을 사용하면 1번의 요청으로 처리할 수 있어어 빠르다는 장점이 있음
✅ 태그 검색 API
ajax 방식으로 키 입력시 호출 -> match query 실행 (사용자 사용 기준 정렬 + 상위 10개 반환)
// 키워드로 태그 검색
public List<String> searchByKeyword(String keyword) {
try {
List<String> result = client.search(s -> s
.index("tags")
.query(q -> q // 쿼리 종류 설정 (match? term? range?)
.match(m -> m
.field("tagName")
.query(keyword) // 입력한 키워드로 검색
)
)
// useCount 필드 기준으로 많이 사용된 순으로 정렬
.sort(sort -> sort
.field(f -> f.field("useCount").order(SortOrder.Desc))
)
.size(10), // 최대 10개만 반환
TagDocument.class
).hits().hits().stream()
.map(Hit::source)
.map(TagDocument::getTagName)
.collect(Collectors.toList());
log.info("태그 검색 keyword={} 결과={}건", keyword, result.size());
return result;
} catch (Exception e) {
log.error("태그 ES 검색 실패 keyword={}", keyword, e);
return List.of();
}
}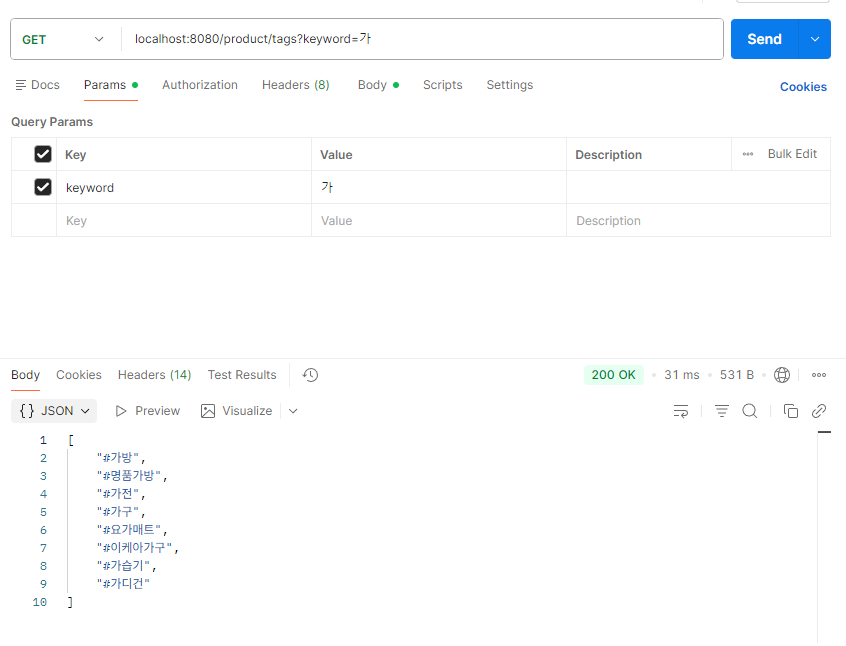
✅ 받은 데이터를 화면에서 자동완성으로 처리
💡 영어와 한글의 키보드 이벤트 흐름은 달라서 주의가 필요하다
영어 "a" 입력 : keydown -> input -> keyup 으로 단순하다
하지만 가 를 입력한다고 가정하면
"ㄱ" 입력 : keydown -> input -> keyup
"ㅏ" 입력 : keydown -> compositionupdate -> input -> keyup
compositionupdate : 현재 텍스트 조합세션 값이 변경된 경우 트리거
"아래화살표 ↓ 누르면" : keydown -> compositionend -> input -> keyup
compositionend : 현재 텍스트 조합 세션이 완료되거나 취소된 경우 트리거 됨즉 keyup 하나로만 처리하면 화살표키 눌렀을 때, 의도치 않게 재검색이 트리거돼서
드롭다운 하이라이트가 사라지는 버그가 생긴다.
// ① 방향키 / Enter / ESC 네비게이션 → keyup으로 처리
// keyup : 키보드에서 손 뗐을때 발생
$searchTag.addEventListener("keyup", (event) => {
switch (event.keyCode) {
case 38: // ↑
nowIndex = Math.max(nowIndex - 1, -1);
showList(matchDataList, $searchTag.value.trim(), nowIndex);
break;
case 40: // ↓
nowIndex = Math.min(nowIndex + 1, matchDataList.length - 1);
showList(matchDataList, $searchTag.value.trim(), nowIndex);
break;
case 13: // Enter
if (matchDataList.length === 0 || nowIndex < 0) return;
addTag(matchDataList[nowIndex]);
resetAutoComplete();
return;
case 27: // ESC
resetAutoComplete();
return;
}
});
// ② 실제 검색 → input 이벤트로 처리
// 화살표키가 한글 IME에서 input을 발생시킬 때 → lastSearchedValue로 중복 방지
$searchTag.addEventListener("input", () => {
const value = $searchTag.value.trim();
if (!value) {
matchDataList = [];
$autoComplete.innerHTML = "";
lastSearchedValue = "";
return;
}
if (value === lastSearchedValue) return; // 같은 값이면 재검색 안 함
lastSearchedValue = value;
clearTimeout(searchDebounceTimer);
searchDebounceTimer = setTimeout(() => { // 200ms debounce
$.ajax({
url: "/product/tags",
data: { keyword: value },
success: function(result) {
matchDataList = result;
nowIndex = 0;
showList(matchDataList, value, nowIndex);
},
error: function() {
matchDataList = [];
$autoComplete.innerHTML = "";
}
});
}, 200);
});