[UPDATE 🔔]
- 현재 확인해 본 바로는 investing.com 에서 Request를 날려 데이터를 불러오는 방식을 막아 놓은 것으로 보입니다. 참고
- 기존 방식으로 주가 데이터를 크롤링하는것은 어려울것으로 보이네요..
데이터 소스
investing.com은 미국은 물론 전세계의 주식 정보를 제공해주는 사이트다. 한국어로도 서비스 하고 있다!
investpy와 FinanceDataReader 같은 패키지 들이 investing.com 으로 부터 주가 데이터를 불러와서 파이썬에서 간단하게 주가 데이터를 사용할 수 있게 해준다.
주가 데이터를 가져오기 위해선 위에서 언급한 좋은 패키지들이 있고 "Don't reinvent the wheel" 이라는 말이 있지만, 같은 wheel 에도 여러 디자인이 있는것 처럼 한번 직접 코딩 해 보는것도 재밌으니깐 ㅎㅎ
Let's Have A Look!
크롤링 하는 방법을 자세히 알아보자.
investing.com 에서 애플(AAPL)을 검색한 후 Historical Data 탭을 누르면 과거 주가 테이블이 나온다.
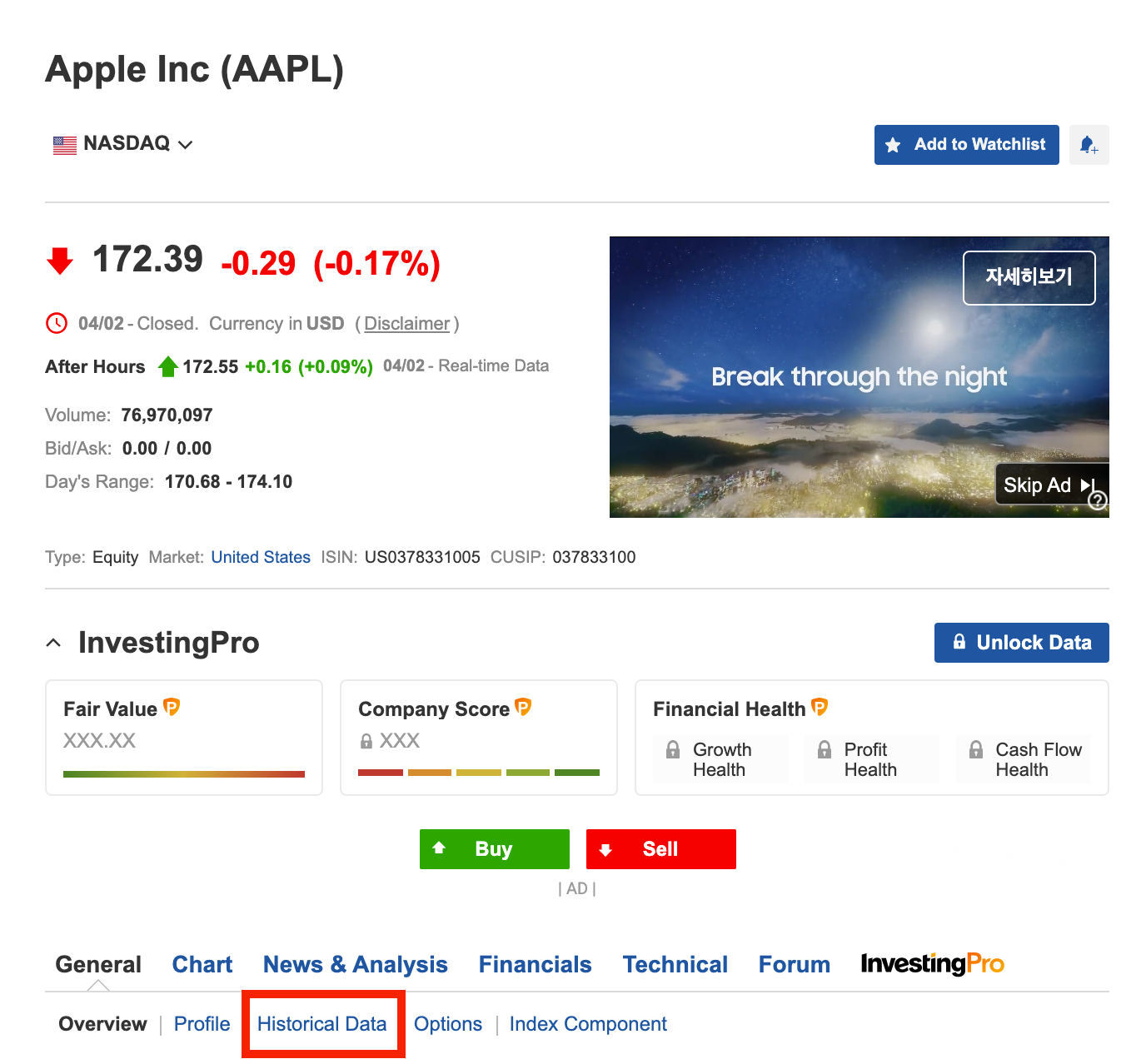
여기서 원하는 날짜 범위를 설정해줄 수 있다.
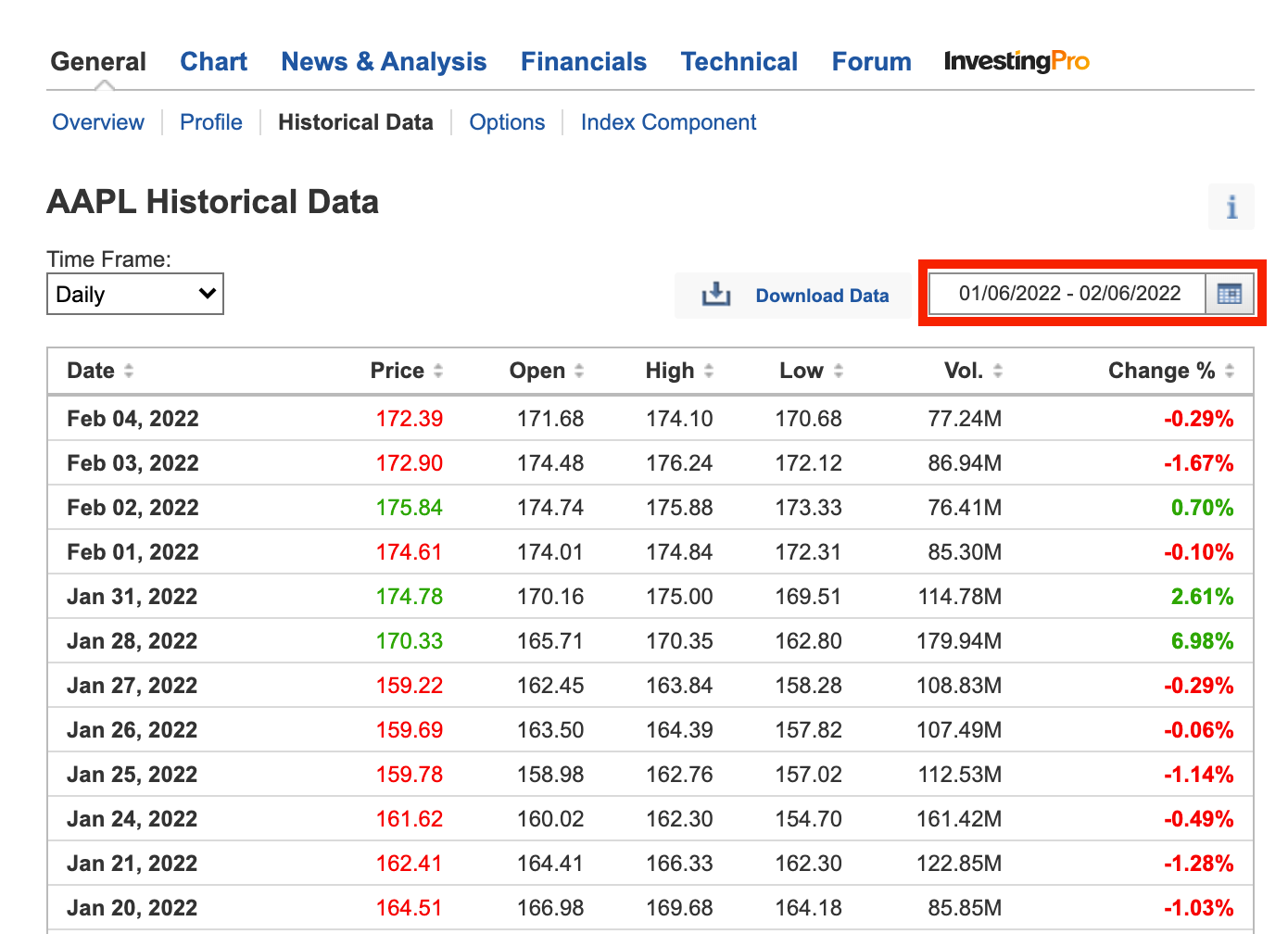
날짜 범위를 설정하기 전에 크롬 개발자 도구를 열고 Network 탭으로 이동해 놓고 날짜를 설정해 주자.
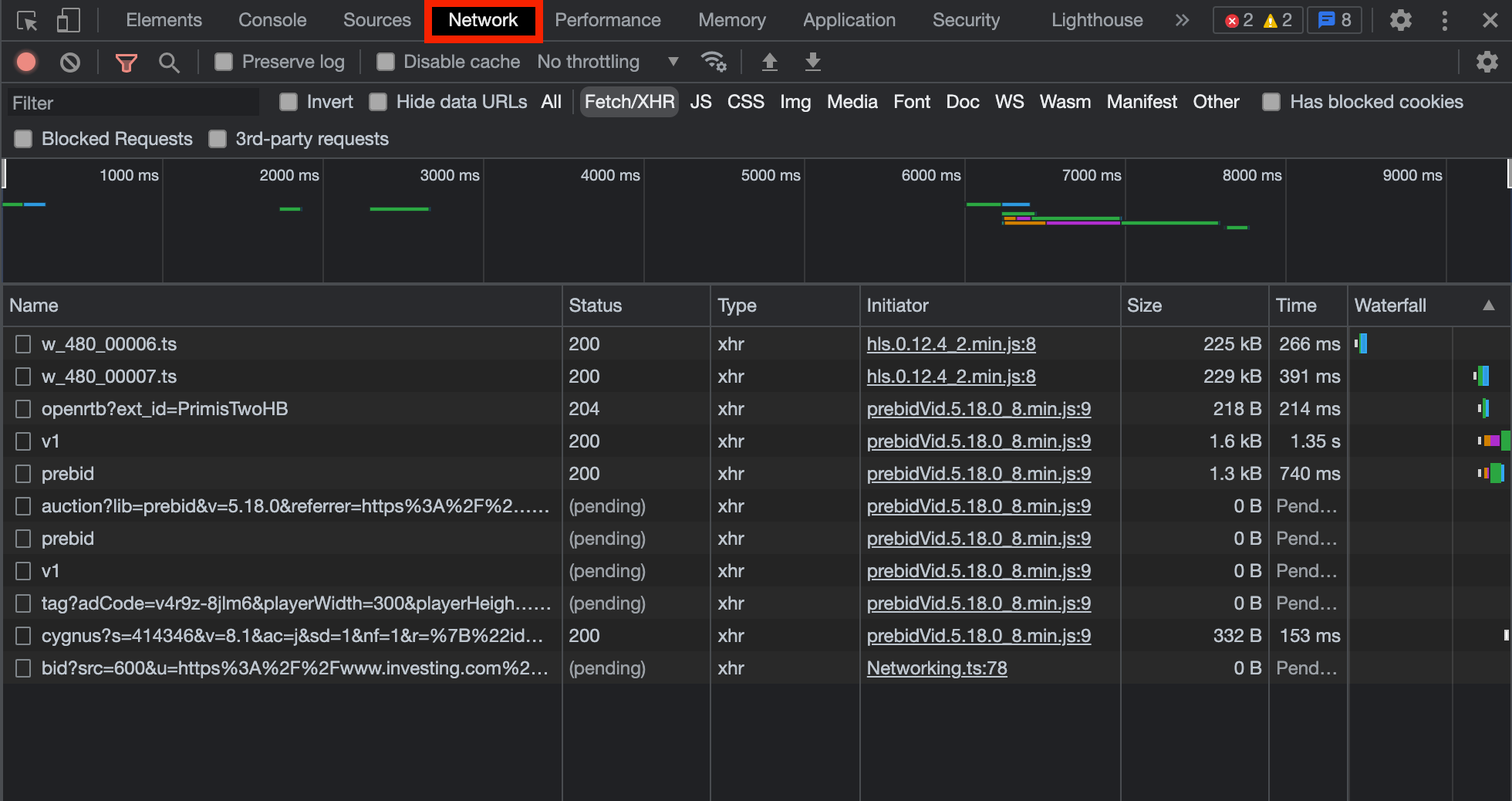
날짜를 설정하면 테이블이 리로딩 되면서 네트워크 탭에 HistoricalDataAjax 라는 이름의 request를 확인 할 수 있다.
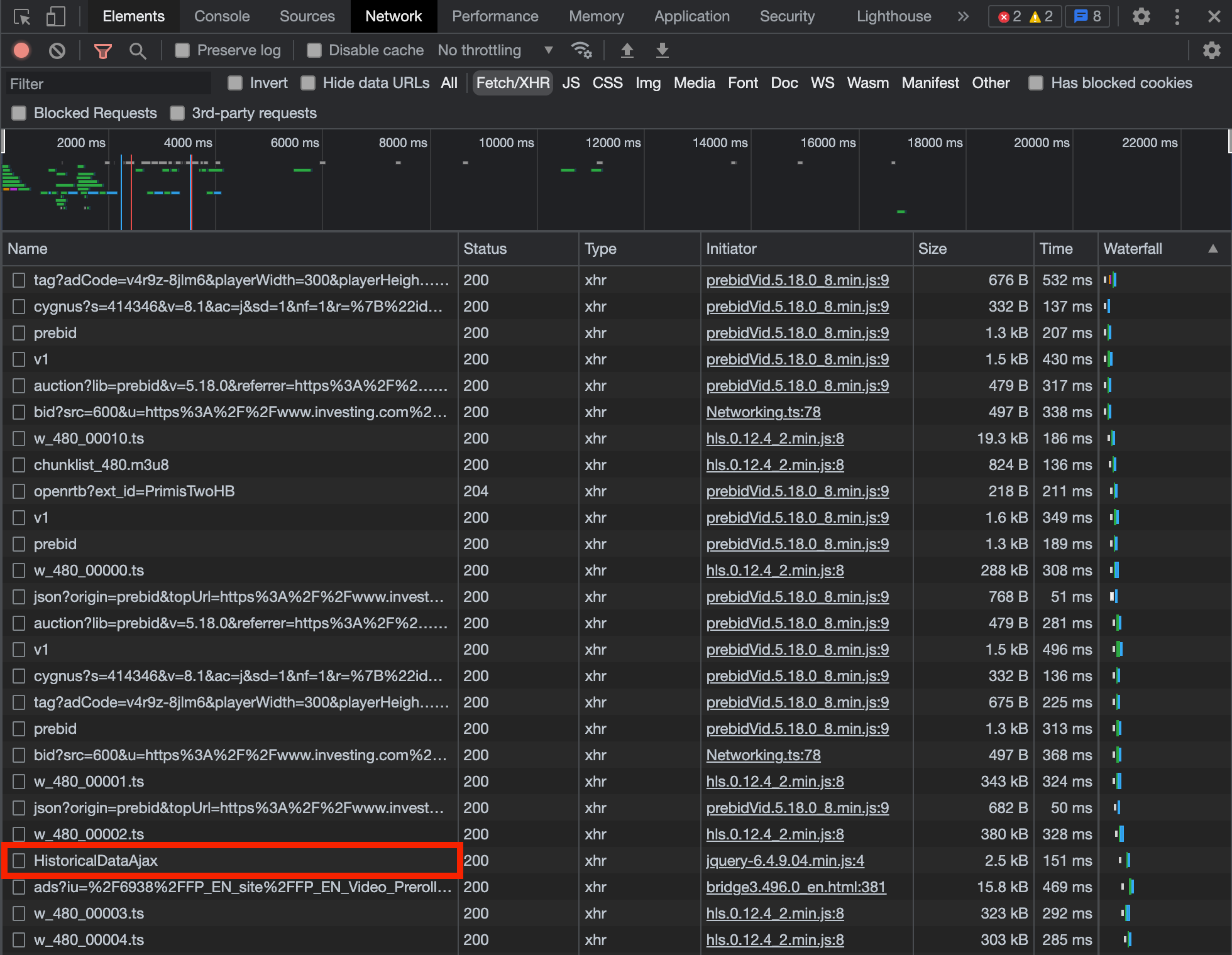
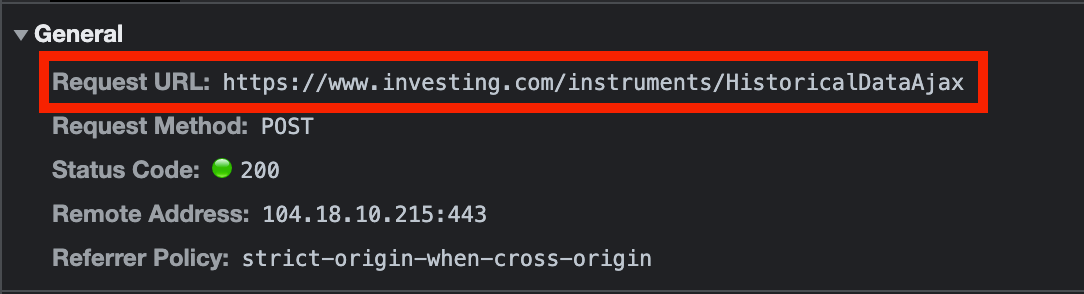
Request URL을 확인할 수 있다.
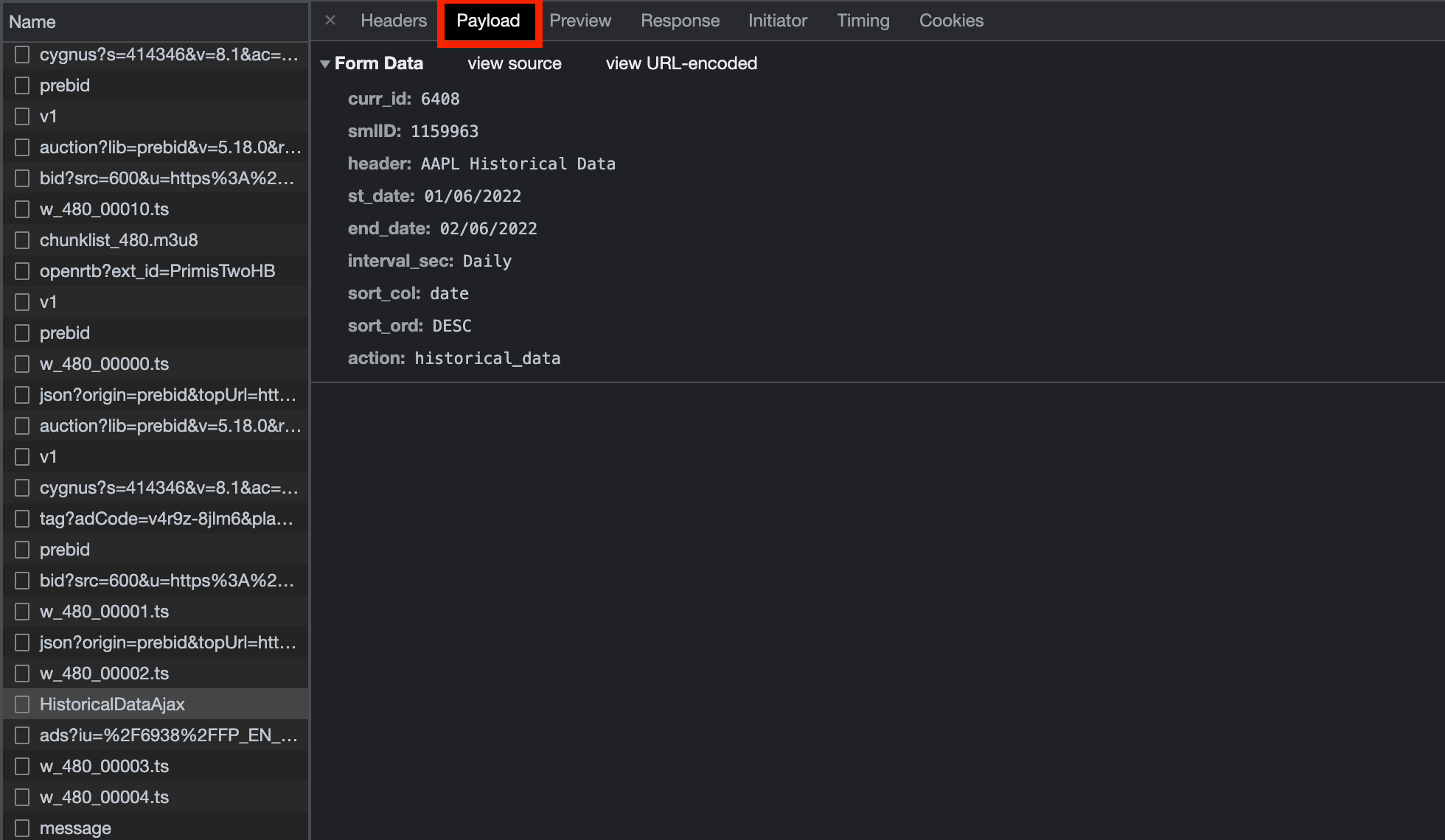
Payload 탭에서 어떤 파라미터 값이 request에 전달되었는지 보면 여러가지가 나오는데 여러 request를 보내봤을 때 필요한건 curr_id, st_date, end_date, interval_sec, action 정도 였다. 다른건 다 뭔지 알겠는데 curr_id가 무엇인지 정확히는 모르겠지만 아마 investing.com에서 종목 마다 부여한 고유번호인것 같다.
그럼 원하는 종목의 주가 데이터를 크롤링 하려면 해당 종목의 curr_id를 알아야 하는데 이건 검색을 통해 알아낼 수 있었다.
아까와 동일하게 개발자 도구의 Network 탭을 열어놓은 상태에서 investing.com 검색창에 원하는 종목의 티커/심볼/종목코드 를 검색하면
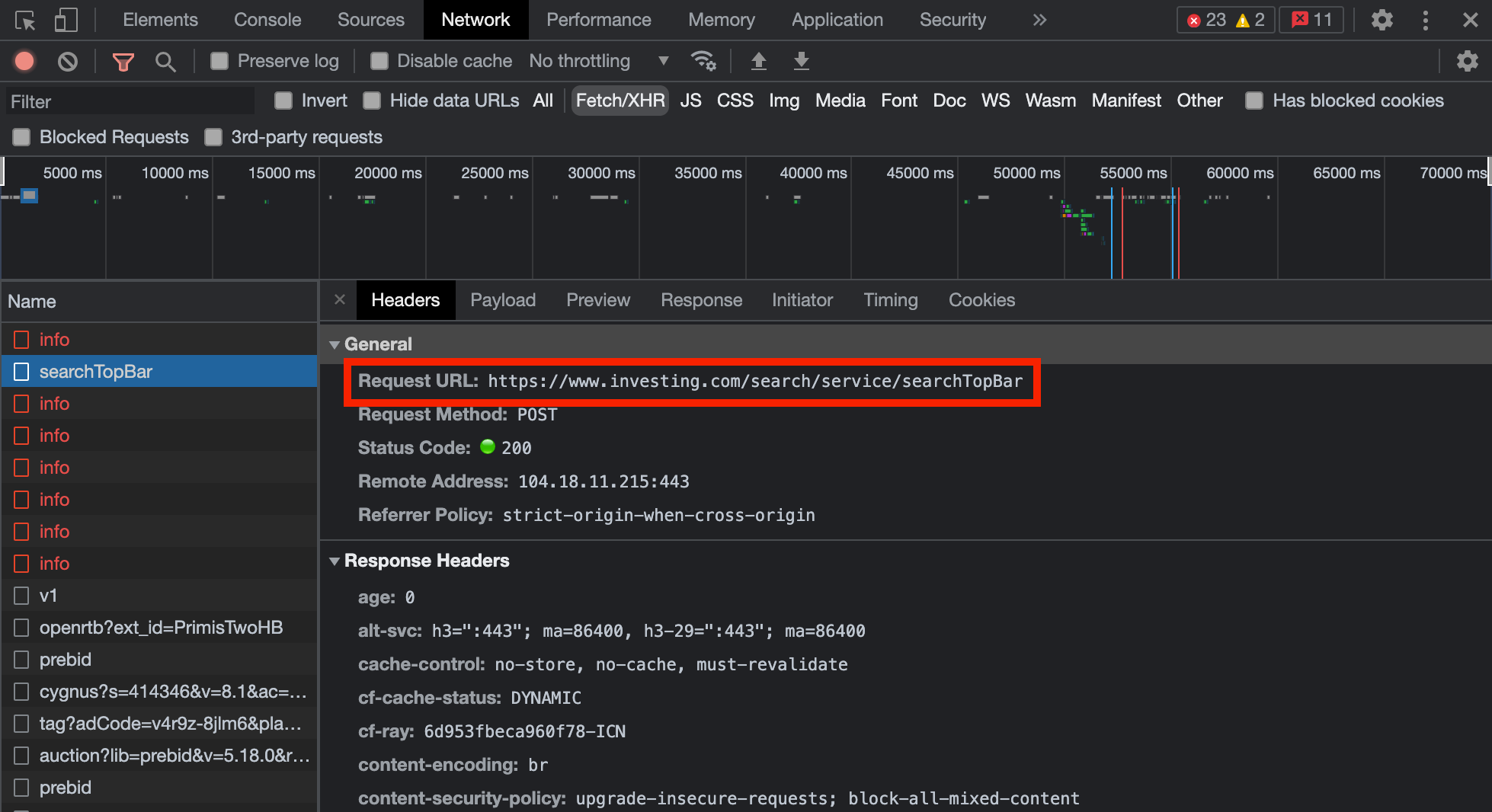
Network 탭에 SearchTopBar 이라는 request가 보인다. Request URL을 확인하고 Payload 탭에 내용을 확인하고
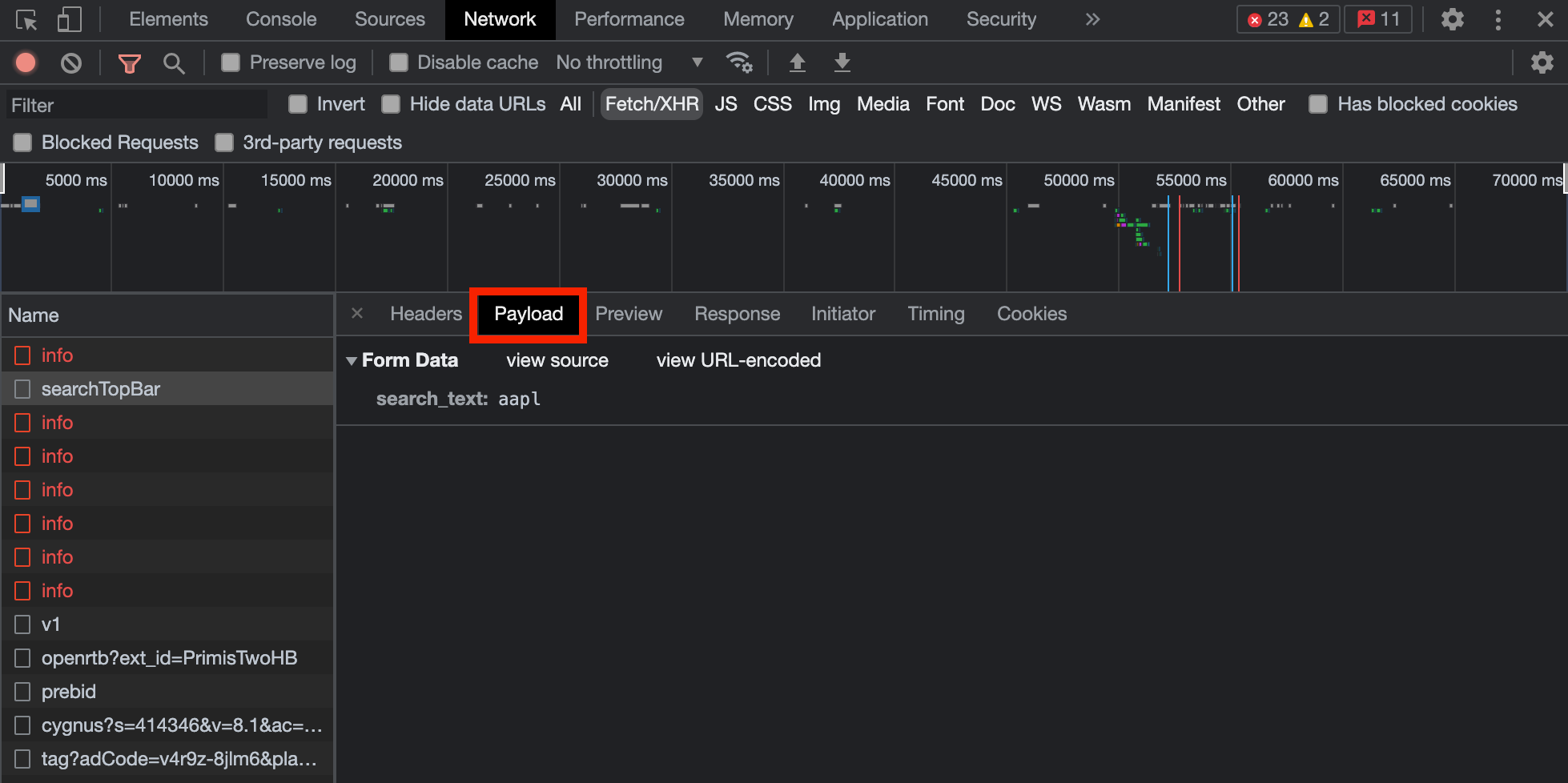
Preview 탭을 눌러보면 Response 받은 데이터를 확인해 볼 수 있다. 이게 검색창에 종목 코드를 검색 했을때 응답으로 받은 데이터인 것이다.
티커/심볼/종목코드를 정확히 검색 하였다면 결과 리스트에 첫번째 항목이 찾고자 하는 종목일 것이다.
여기서 종목의 curr_id를 찾을 수 있는데, quotes 에 첫번째 item을 눌러보면 해당 검색결과의 간단한 정보가 담겨있고 pair_id라는 것이 담겨있는데 이것이 curr_id와 동일한 것이다. (왜 이름이 다른지는 모르겠지만 구글링을 통해 두개가 같은것 이라는 것을 확인함)
이제 어떻게 주가 데이터를 크롤링 해야할 지 알았으니 코드를 짜보자!
Let's Code!
애플(AAPL)의 주가 데이터를 크롤링 해보자!
우선 애플의 curr_id를 추출해야 한다. 위에서 언급한것 처럼 검색창을 통해 curr_id를 추출한다.
POST 방식으로 request를 보내주는데 request header에 User-Agent 와 X-Requested-With 을 설정해 주어야 한다. (X-Requested-With에 관한 것은 링크 참고)
import requests
import pandas as pd
ticker = 'AAPL'
url = 'https://www.investing.com/search/service/searchTopBar'
headers = {
'User-Agent': 'Mozilla',
'X-Requested-With': 'XMLHttpRequest',
}
form_data = {
'search_text': ticker,
}
res = requests.post(url, data=form_data, headers=headers)
data = res.json()
first_quote_result = data['quotes'][0]
curr_id = first_quote_result['pairId'] # curr_id = 6408자 이제 curr_id를 알았으니 주가 데이터를 크롤링 해보자.
날짜 형식이 %m/%d/%Y 이니깐 주의하자.
st_date = '01/06/2022'
end_date = '02/06/2022'
form_data = {
'curr_id': curr_id,
'st_date': st_date,
'end_date': end_date,
'interval_sec': 'Daily',
'action': 'historical_data',
}
url = 'https://www.investing.com/instruments/HistoricalDataAjax'
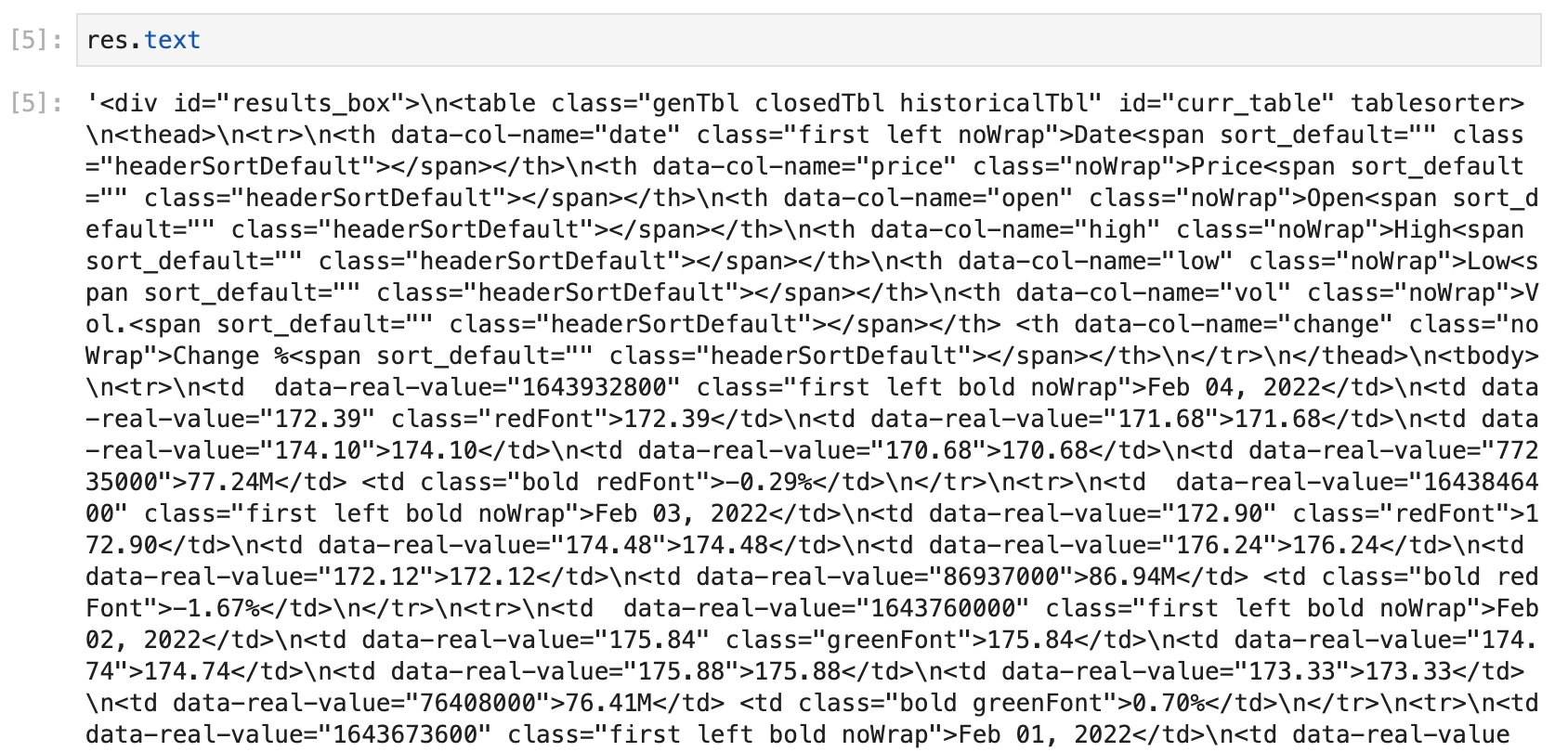
res = requests.post(url, data=form_data, headers=headers)응답 받은 데이터를 확인해보자.
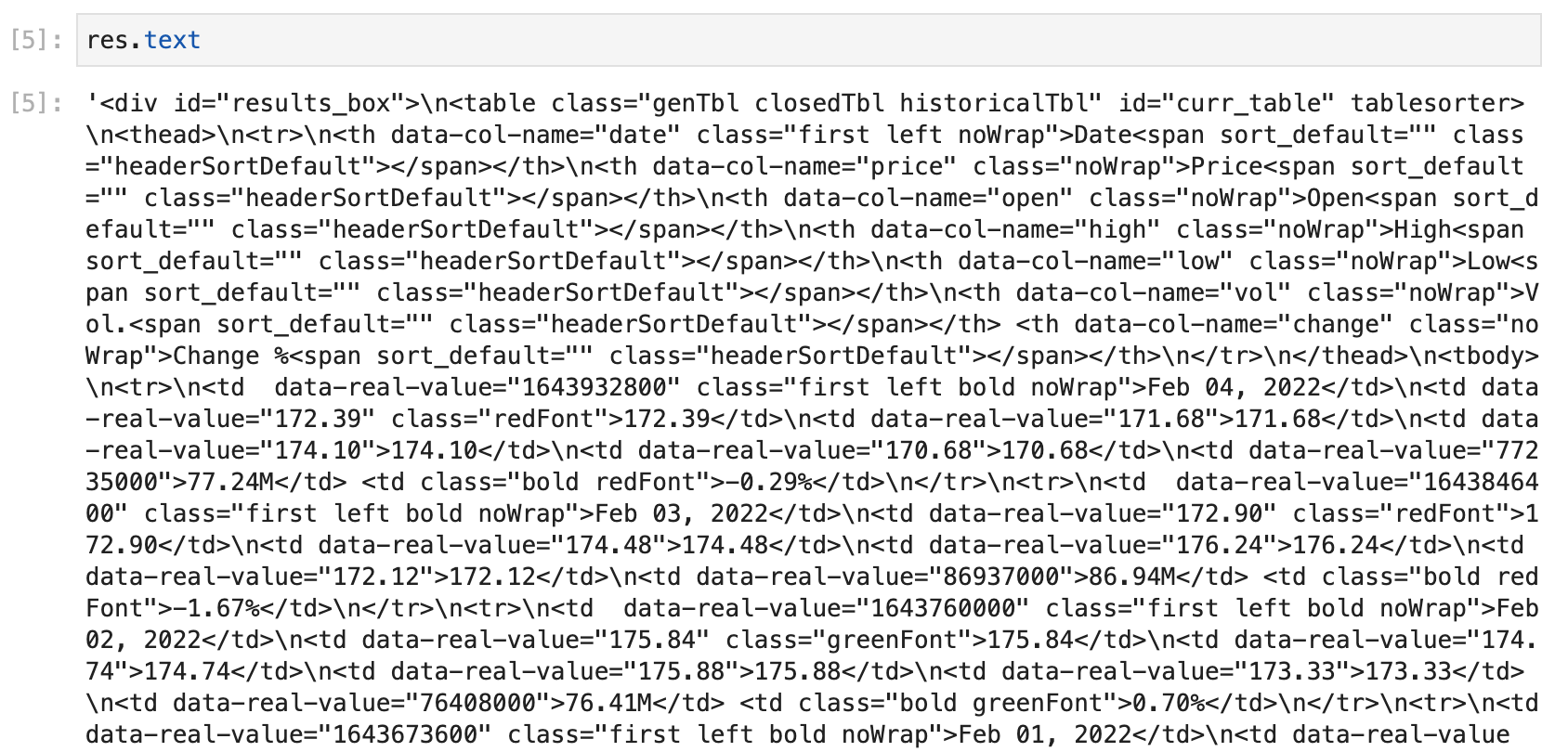
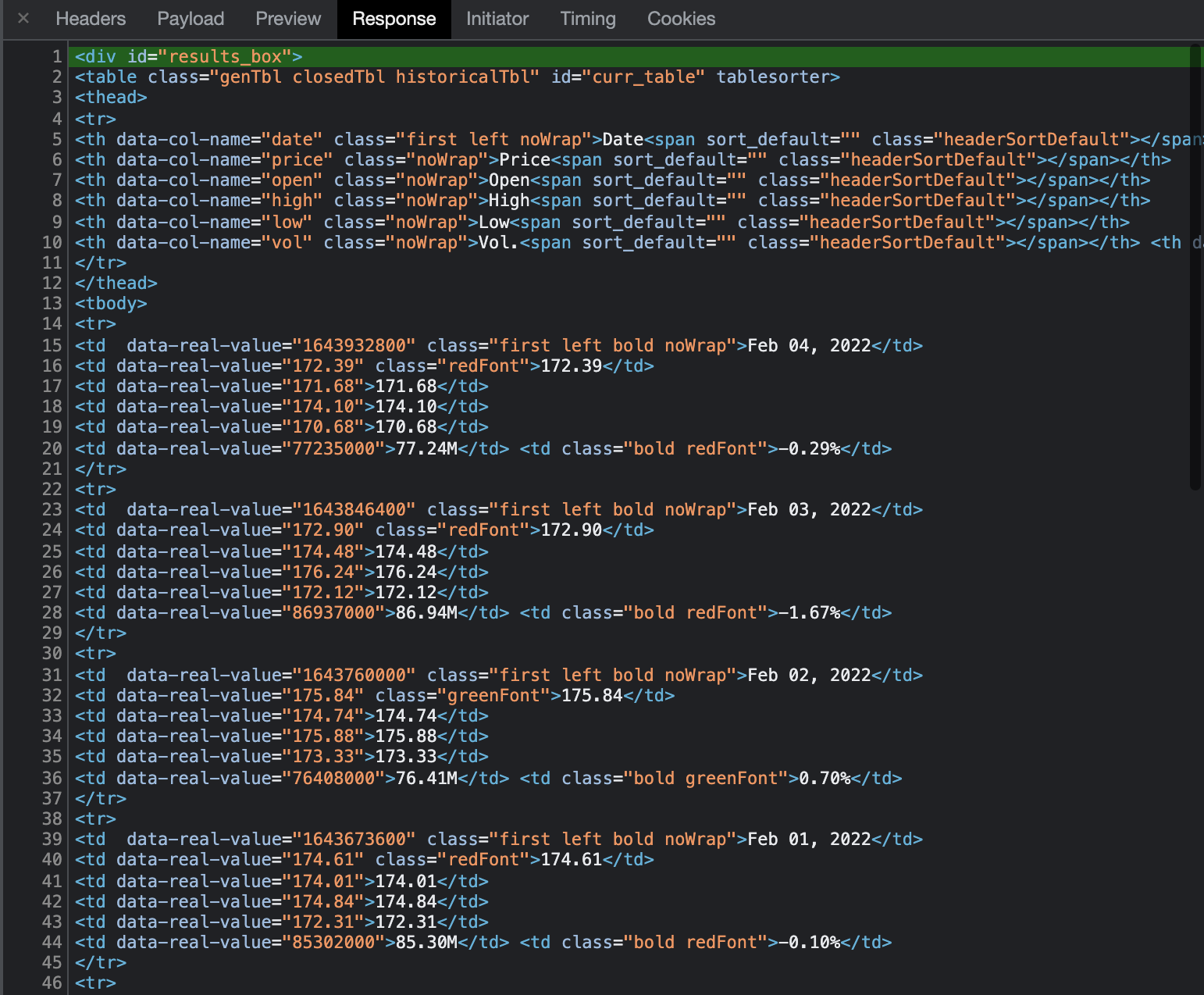
HTML 코드다.
실제로 개발자 도구에서 Response 를 보면 HTML 이고 <table> 태그를 확인할 수 있다.
파이썬에선 HTML 코드에서 데이터를 추출하는 대표적인 방법으론 BeautifulSoup 와 pandas 가 있다.
여기선 pandas를 사용할 것인데 왜냐하면 pandas.read_html 을 사용하면 간단하게 HTML 테이블을 pandas.DataFrame 으로 바꿀 수 있기 때문이다! (그저 빛✨)
이어서 코드를 짜보자.
pd.read_html 은 HTML에 있는 모든 \<table> element를 추출하기 때문에 리스트를 반환한다.
반환값을 확인해 보았을 때 인덱스 0 에 들어 있는 값이 주가 데이터 값 이었다.
data = res.text
tables = pd.read_html(data)
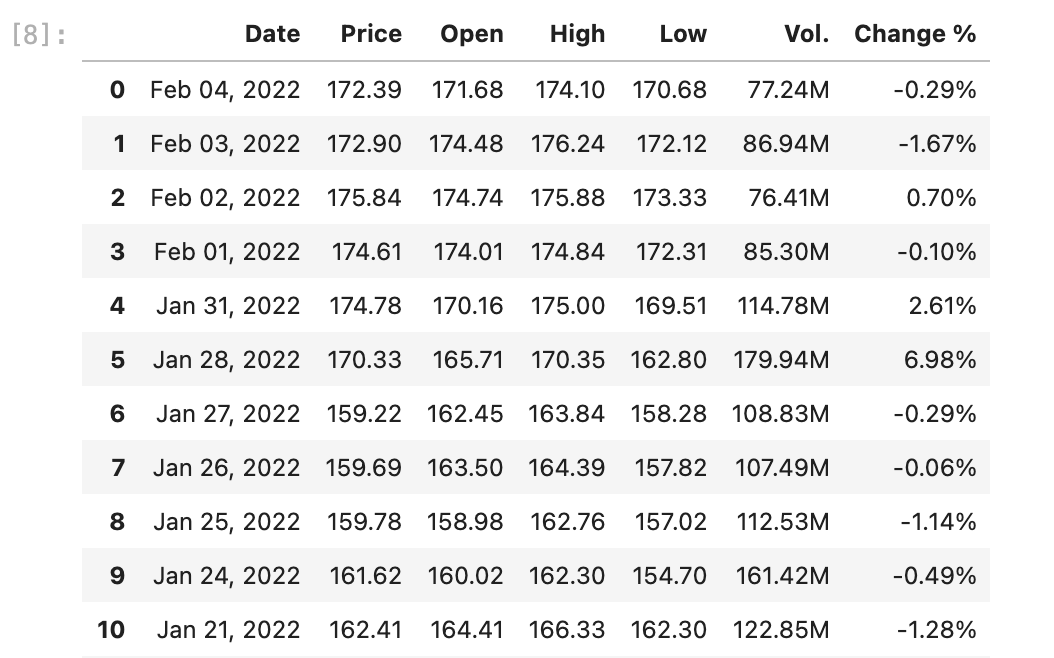
historicl_price = tables[0]Result
historical_price 에 과거 주가 데이터가 잘 담겨있다.
Closing Words
이 코드를 클래스나 함수로 만들면 여러 종목을 검색할 때 코드 재사용율을 높일 수 있다. 여기선 패스..

3개의 댓글

좋은 내용 감사합니다 멋지네요! 저도 금융 개발 공부하는 중인데, https://quantpro.co.kr/ 해당 사이트 퀀트 내용 어떤지 의견주시면 감사하겠습니다!
안녕하세요. 글 잘 봤습니다.
네트워크에서 엄청 많은 정보 중 HistoricalDataAjax 와 같은 내가 알고 싶은 정보를 쉽게 찾는 방법은 없을까요?
뭐가 뭔지 모르는 자료들이 수없이 많은데 그중에서 어떻게 HistoricalDataAjax를 찾았는지 궁급합니다.