Sorting
- Bubble Sort (거품 정렬)
- Selection Sort (선택 정렬)
- Insertion Sort (삽입 정렬)
- Quick Sort (퀵 정렬)
- Merge Sort (병합 정렬)
- Heap Sort (힙 정렬)
- Radix Sort (기수 정렬)
- Counting Sort (계수 정렬)
Bubble Sort
- 거품 정렬은 바로 옆의 인접한 값과 크기 비교를 하여 조건에 맞춰 정렬을 하는 방식이다.
- 오름차순 정렬의 경우 첫 순환에서 가장 큰 값이 제일 뒤로 가게 되며 그 다음 순환부터는 제일 뒤의 값을 제외하고 크기 비교를 하면 된다.

Complexity
- 시간복잡도
- 최선 :
O(N²) - 평균 :
O(N²) - 최악 :
O(N²)
- 최선 :
- 정렬이 돼있던 안돼있던, 2개의 원소를 무조건 비교하기 때문에 최선, 평균, 최악의 경우 모두 시간복잡도가
O(N²)
Code
void bubbleSort(int[] arr) { // Ascending
int temp = 0;
for (int i = 0; i < arr.length; i++)
for (int j = 0; j < arr.length - i - 1; j++)
if(arr[j] > arr[j + 1])
swap(array, j, j + 1);
}Pros & Cons
- 구현이 매우 간단하고 소스코드가 직관적
- 추가적인 메모리 공간을 필요로 하지 않음
- 안정 정렬(Stable Sort)
- 시간복잡도가
O(N²)으로 비효율적
Selection Sort
- 선택 정렬은 해당 순서에 원소를 넣을 위치는 이미 정해져 있고, 어떤 원소를 넣을지 선택하는 알고리즘
- 주어진 배열 중의 최솟값을 찾아 맨앞의 위치값과 교체하고, 다음 순환에서 맨처음 위치를 뺀 나머지 배열을 같은 방법으로 교체

Complexity
- 시간복잡도
- 최선 :
O(N²) - 평균 :
O(N²) - 최악 :
O(N²)
- 최선 :
- 비교하는 것이 상수 시간에 이루어진다는 가정 아래, n개의 주어진 배열을 정렬하는데
O(N²)
Code
void selectionSort(int[] arr) {
int indexMin, temp;
for (int i = 0; i < arr.length - 1; i++) {
indexMin = i;
for (int j = i + 1; j < arr.length; j++)
if (arr[j] < arr[indexMin])
indexMin = j;
swap(arr[indexMin], arr[i]);
}
}Pros & Cons
- 구현이 매우 간단하고 소스코드가 직관적
- 정렬을 위한 비교 횟수는 많지만,
Bubble Sort에 비해 실제로 교환하는 횟수는 적기 때문에 많은 교환이 일어나야 하는 자료상태에서 비교적 효율적 - 추가적인 메모리 공간을 필요로 하지 않음
- 시간복잡도가
O(N²)으로 비효율적 - 불안정 정렬(Unstable Sort) : 중복된 값의 인덱스의 순서가 바뀐다
Insertion Sort
- 삽입 정렬은 2번째 원소부터 시작하여 그 앞(왼쪽)의 원소들과 비교하여 삽입할 위치를 지정한 후, 원소를 뒤로 옮기고 지정된 자리에 자료를 삽입 하여 정렬하는 알고리즘
- 최선의 경우 O(N)이라는 엄청나게 빠른 효율성을 가지고 있어, 다른 정렬 알고리즘의 일부로 사용될 만큼 좋은 정렬 알고리즘

Complexity
- 시간복잡도
- 최선 :
O(N) - 평균 :
O(N²) - 최악 :
O(N²)
- 최선 :
- 정렬이 돼있으면 최선의 경우로
O(N)의 시간복잡도를 갖게 됨
Code
void insertionSort(int[] arr)
{
for(int index = 1 ; index < arr.length ; index++){
int temp = arr[index];
int prev = index - 1;
while( (prev >= 0) && (arr[prev] > temp) ) {
arr[prev+1] = arr[prev];
prev--;
}
arr[prev + 1] = temp;
}
}
}Pros & Cons
- 알고리즘이 단순하다
- 대부분의 원소가 정렬되어 있는 경우 매우 효율적
- 안정 정렬(Stable Sort)
- 평균과 최악의 시간복잡도가
O(N²)으로 비효율적 - 배열의 길이가 길어질수록 비효율적
Quick Sort
- 퀵 소트는 분할 정복(Divide & Conquer) 방법 을 통해 주어진 배열을 정렬
- 불안정 정렬에 속하며, 다른 원소와의 비교만으로 정렬을 수행하는 비교 정렬
- 합병 정렬과 달리 퀵 소트는 배열을 비균등하게 분할
- 배열 가운데서 하나의 원소, 피벗(pivot)을 고른다
- 피벗 앞에는 피벗보다 값이 작은 모든 원소들이 오고, 피벗 뒤에는 피벗보다 값이 큰 모든 원소들이 오도록 피벗을 기준으로 배열을 둘로 나눈다.
- 이렇게 배열을 둘로 나누는 것을 분할(Divide) 이라고 한다
- 분할을 마친 뒤에 피벗은 더 이상 움직이지 않는다
- 분할된 두 개의 작은 배열에 대해 재귀(Recursion)적으로 이 과정을 반복
- 재귀 호출이 한번 진행될 때마다 최소한 하나의 원소는 최종적으로 위치가 정해지므로, 이 알고리즘은 반드시 끝난다는 것을 보장할 수 있다.

Complexity
- 시간복잡도
- 최선 :
O(Nlog₂N) - 평균 :
O(Nlog₂N) - 최악 :
O(N²)
- 최선 :
- 최선의 경우에 순환 호출의 깊이 * 각 순환 호출 단계의 비교 연산으로
O(Nlog₂N)가 된다- 배열의 크기가 n(n = 2³) 이면 2³ -> 2² -> 2¹ -> 2⁰ 으로 줄어들어 재귀 호출의 깊이가 3이 되고 일반화 하면 n = 2ᴷ인 경우 k = log₂n 임을 알 수 있다
- 최악의 경우 배열이 오름차순 정렬 또는 내림차순 정렬이 되어있는 경우인데 이때는 재귀호출의 깊이가 N이 되어 시간복잡도가
O(N²)이 된다
Code
public void quickSort(int[] array, int left, int right) {
if(left >= right) return;
// 분할
int pivot = partition();
// 피벗은 제외한 2개의 부분 배열을 대상으로 순환 호출
quickSort(array, left, pivot-1); // 정복(Conquer)
quickSort(array, pivot+1, right); // 정복(Conquer)
}
public int partition(int[] array, int left, int right) {
/**
// 최악의 경우, 개선 방법
int mid = (left + right) / 2;
swap(array, left, mid);
*/
int pivot = array[left]; // 가장 왼쪽값을 피벗으로 설정
int i = left, j = right;
while(i < j) {
while(pivot < array[j]) {
j--;
}
while(i < j && pivot >= array[i]){
i++;
}
swap(array, i, j);
}
array[left] = array[i];
array[i] = pivot;
return i;
}Pros & Cons
- 한 번 결정된 피벗들이 추후 연산에서 제외되는 특성 때문에, 시간 복잡도가
O(Nlog₂N)를 가지는 다른 정렬 알고리즘과 비교했을 때도 가장 빠름 - 다른 메모리 공간을 필요로 하지 않음
- 불안정 정렬(Unstable Sort)
- 정렬된 배열에 대해서는 Quick Sort의 불균형 분할에 의해 오히려 수행시간이 더 많이 걸림
JAVA에서Arrays.sort()내부적으로도 Dual Pivot Quick Sort로 구현되어 있을 정도로 효율적인 알고리즘- Dual Pivot Quick Sort
삽입 정렬(Insertion Sort)와Quick Sort를 합친 것- 피봇을 2개 사용함으로써 3개의 영역으로 나누는 것이 핵심
- 배열의 가장 왼쪽 항목은 lp로, 가장 오른쪽 항목은 rp로 설정
- lp> rp 인 경우 lp와 rp를 바꾸어준다
- lp와 rp를 이용하여 다시 세 개의 영역으로 분할
void DualPivotQuickSort(int arr[], int left, int right){
// lp : Left Pivot, rp : Right Pivot
// left > right인 경우는 배열상으로 성립이 되지 않는다.
if(left <= right){
int lp = arr[left]; // 분할의 가장 왼쪽 값
int rp = arr[right]; // 분할의 가장 오른쪽 값
// 양 끝의 값을 비교한다.
if(arr[lp] > arr[rp]){
swap(arr, lp, rp); // lp가 크면 lp와 rp의 위치를 바꾸어준다.
}
int l = left + 1;
int k = left + 1; // left+1의 원소부터 차례로 비교해준다.
int g = right - 1;
}
while(k <= g){ //서로 엇갈릴 때 까지
//arr[k]가 lp보다 작으면, lp보다 작은 (1)영역에 들어간다.
if(arr[k] < lp){
swap(arr, k, l);
l++;
}
// lp보다 큰 (2)영역, (3)영역
else{
//rp보다 큰 (3) 영역
if(arr[k] > rp){
while(arr[g] > rp && k < g){
g--;
}
swap(arr, k, g);
g--;
if(arr[k] < lp){
swap(arr, k, l);
l++;
}
}
}
k++; // k에 대한 비교가 끝
}
l--; g--;
swap(arr, left, l);
swap(arr, right, r);
DualPivotQuickSort(arr, left, l-1);
DualPivotQuickSort(arr, l+1, g-1);
DualPivotQuickSort(arr, g+1, right);
}Merge Sort
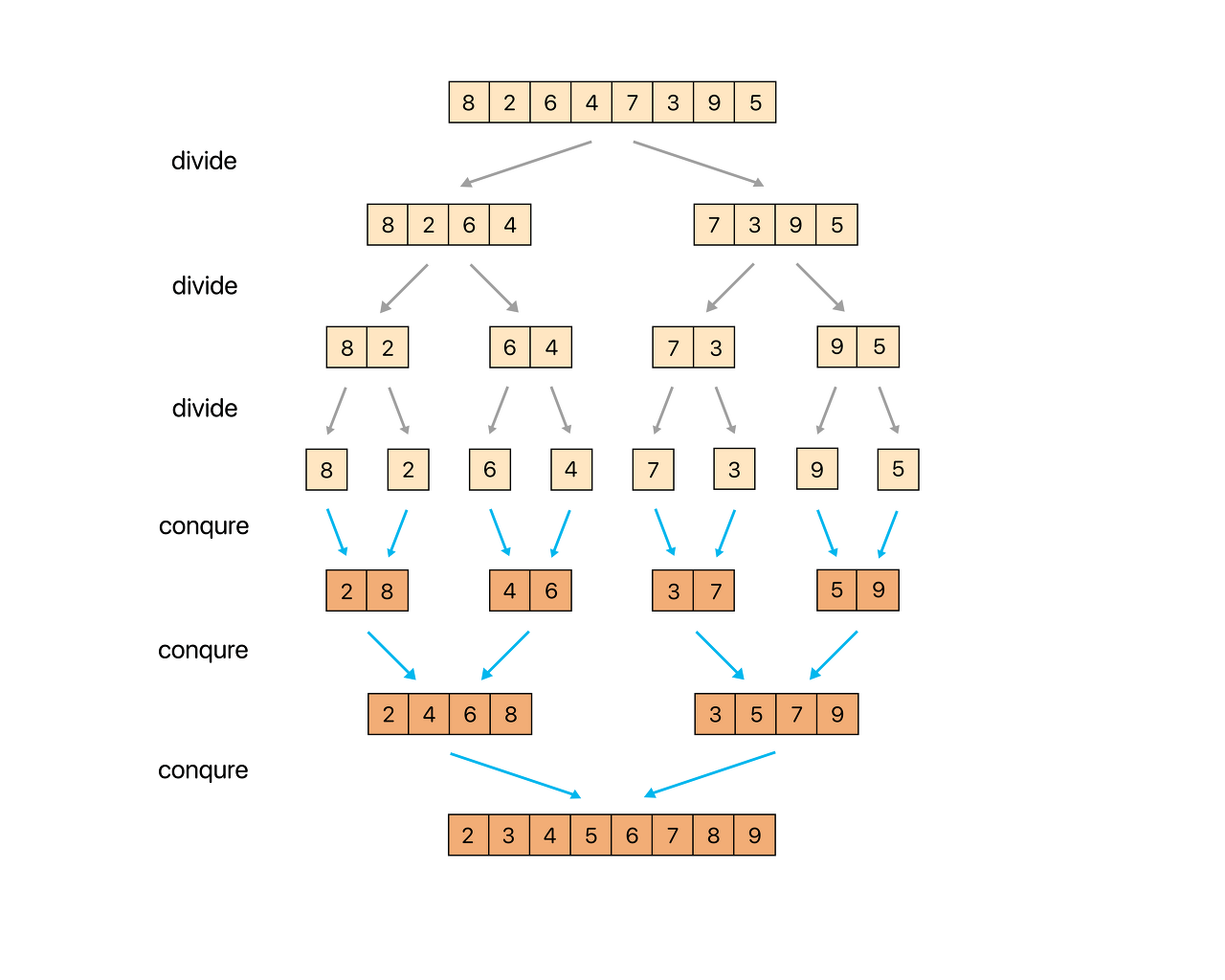
- 합병 정렬은 퀵 소트와 마찬가지로 분할 정복(Divide & Conquer) 방법 을 통해 주어진 배열을 정렬
- 퀵 소트와 반대로 안정 정렬에 속함
- 퀵 소트와의 차이점
- 퀵 소트 : 우선 피벗을 통해
정렬(partition)→영역을 쪼갬(quickSort) - 합병 정렬 : 영역을 쪼갤 수 있을 만큼
쪼갬(mergeSort)→정렬(merge)
- 퀵 소트 : 우선 피벗을 통해
- 주의할 점은 합병 정렬의 구현이 반드시 2개의 부분리스트로 나누어야 한다는 점은 아니다
- 어디까지나 가장 일반적으로 구현되는 방식이 절반으로 나누는 방식일 뿐이며, 보통 아래와 같이 두 개의 부분리스트로 나누는 방식을
two-way방식이라 함
Complexity
- 시간복잡도
- 최선 :
O(Nlog₂N) - 평균 :
O(Nlog₂N) - 최악 :
O(Nlog₂N)
- 최선 :
- 정렬이 돼있던 안돼있던, 2개의 원소를 무조건 비교하기 때문에 최선, 평균, 최악의 경우 모두 시간복잡도가
O(N²)
Code
public void mergeSort(int[] array, int left, int right) {
if(left < right) {
int mid = (left + right) / 2;
mergeSort(array, left, mid);
mergeSort(array, mid+1, right);
merge(array, left, mid, right);
}
}
public static void merge(int[] array, int left, int mid, int right) {
int[] L = Arrays.copyOfRange(array, left, mid + 1);
int[] R = Arrays.copyOfRange(array, mid + 1, right + 1);
int i = 0, j = 0, k = left;
int ll = L.length, rl = R.length;
while(i < ll && j < rl) {
if(L[i] <= R[j]) {
array[k] = L[i++];
}
else {
array[k] = R[j++];
}
k++;
}
// remain
while(i < ll) {
array[k++] = L[i++];
}
while(j < rl) {
array[k++] = R[j++];
}
}Pros & Cons
- 합병정렬은 순차적인 비교로 정렬을 진행하므로, LinkedList의 정렬이 필요할 때 사용하면 효율적이다
- LinkedList는 삽입, 삭제 연산에서 유용하지만 접근 연산에서는 비효율적
- 따라서 임의로 접근하는 퀵 소트를 활용하면 오버헤드 발생이 증가
- 배열의 클경우 원소들의 이동횟수가 많아 느림
Heap Sort
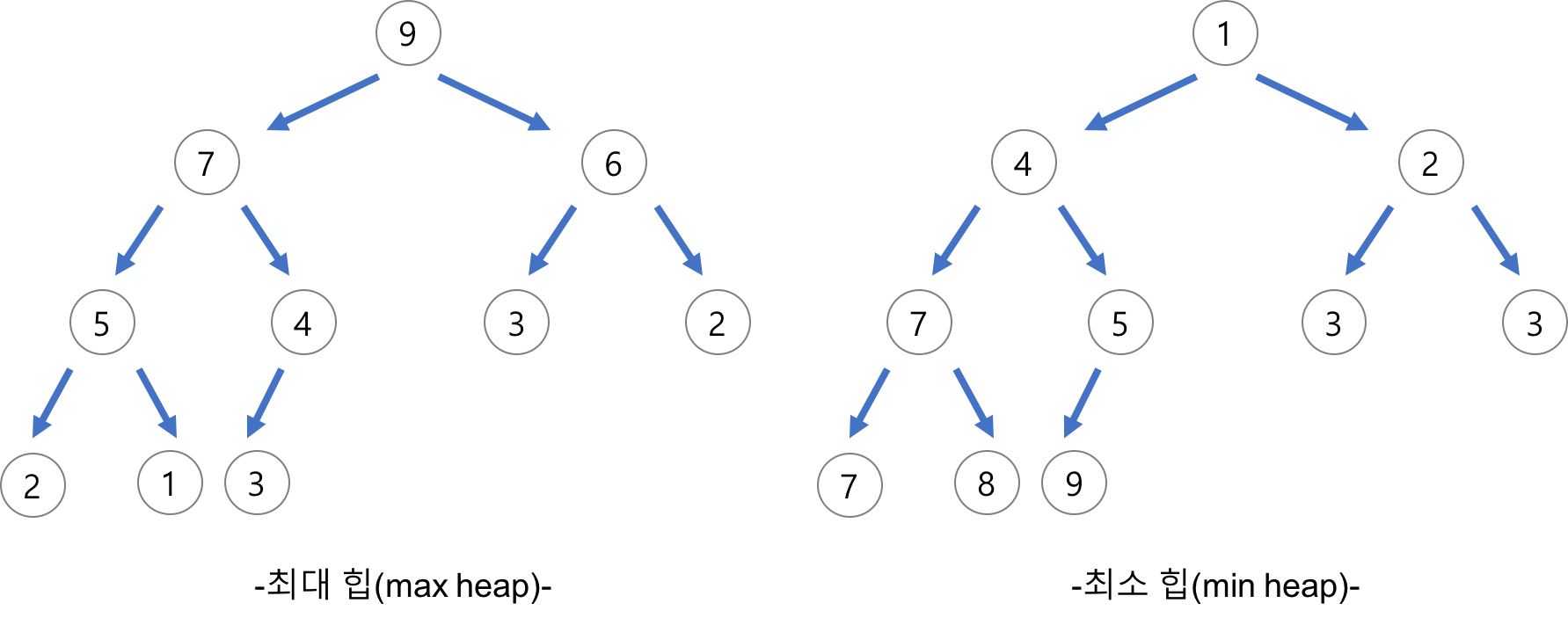
- 완전이진트리를 기본으로 하는 힙(Heap) 자료구조를 기반으로한 정렬 방식
- 완전이진트리 : 삽입할 때 왼쪽부터 차례대로 추가하는 이진 트리
- 힙(Heap)
- 완전이진트리의 일종으로 우선순위 큐를 위하여 만들어진 자료구조
- 여러 개의 값들 중에서 최댓값이나 최솟값을 빠르게 찾아내도록 만들어진 자료구조
- 부모 노드의 키 값이 자식 노드의 키 값보다 항상 큰(작은) 이진 트리
- 내림차순 정렬을 위해서는 최대 힙을 구성하고 오름차순 정렬을 위해서는 최소 힙을 구성하면 된다
Complexity
- 시간복잡도
- 최선 :
O(Nlog₂N) - 평균 :
O(Nlog₂N) - 최악 :
O(Nlog₂N)
- 최선 :
- heapify 함수의 시간복잡도가
log₂N이고 모든 노드마다 실행되면 전체의 시간복잡도는Nlog₂N이 된다
Code
public static void heapify(int array[], int n, int i) {
int p = i;
int l = i * 2 + 1;
int r = i * 2 + 2;
if (l < n && array[p] < array[l]) {
p = l;
}
if (r < n && array[p] < array[r]) {
p = r;
}
if (i != p) {
swap(array, p, i);
heapify(array, n, p);
}
}
public static void heapSort(int[] array) {
int n = array.length;
// init, max heap
for (int i = n / 2 - 1; i >= 0; i--) {
heapify(array, n, i);
}
// for extract max element from heap
for (int i = n - 1; i > 0; i--) {
swap(array, 0, i);
heapify(array, i, 0);
}
}Pros & Cons
- Heap Sort가 유용할 때
- 가장 크거나 가장 작은 값을 구할 때 (최소 힙 또는 최대 힙의 루트 값이기 때문에 한번의 힙 구성을 통해 구하는 것이 가능)
- 최대 k 만큼 떨어진 요소들을 정렬할 때 (삽입정렬보다 더욱 개선된 결과를 얻어낼 수 있음)
- 불안정 정렬(Unstable Sort) : 중복된 값의 인덱스의 순서가 바뀐다
Counting Sort
- 카운팅 정렬의 기본 매커니즘은 아주 단순하게 데이터의 값이 몇 번 나왔는지를 세어 주는 것이다
- 과정
- array 를 한 번 순회하면서 각 값이 나올 때마다 해당 값을 index 로 하는 새로운 배열(counting)의 값을 1 증가시킨다
- counting 배열 값들을 누적합으로 설정한다 (counting 배열의 각 값은 (시작점 - 1)을 알려준다)
- countin[i] 의 값에 1 을 빼준 뒤 해당 값이 새로운 배열의 인덱스 [해당값 - 1]에 위치하게 된다.
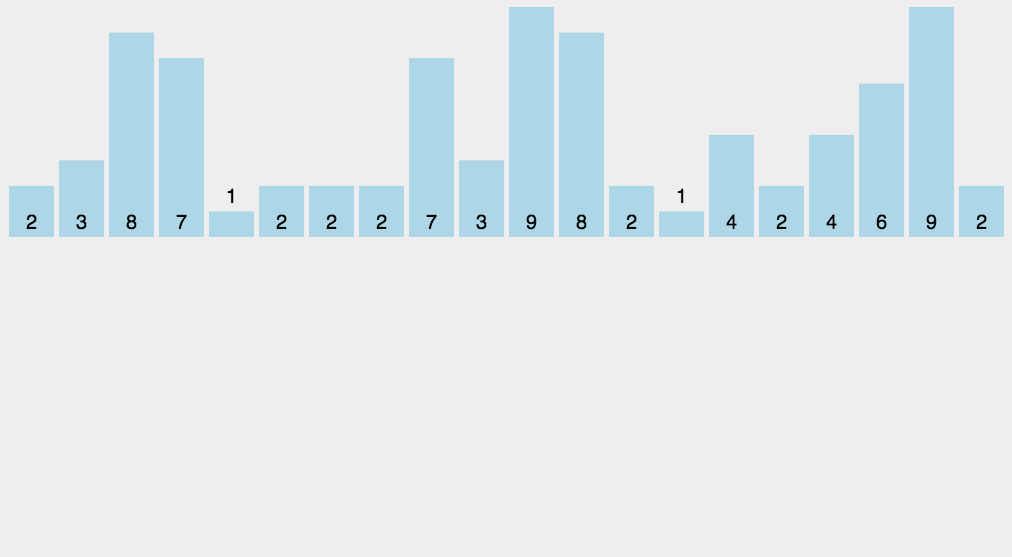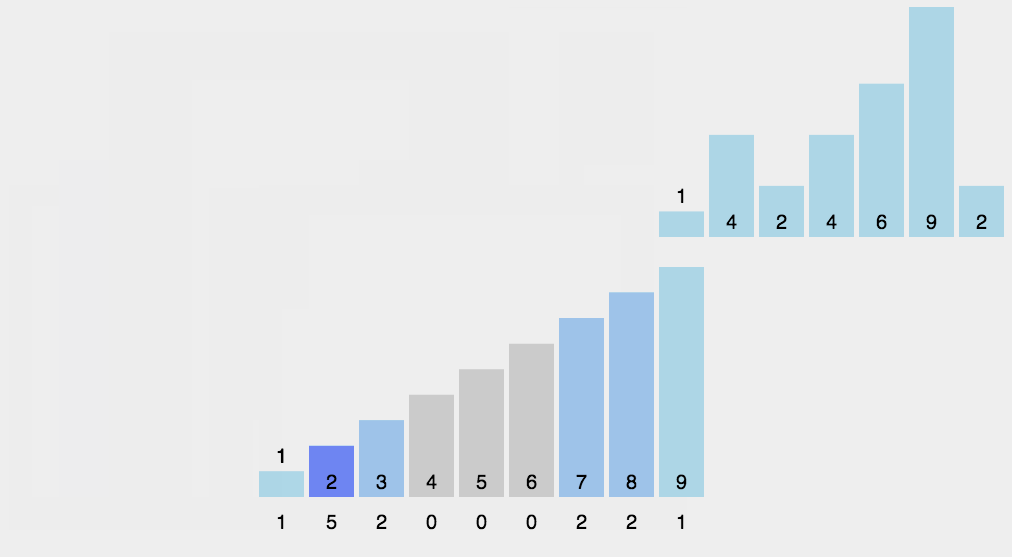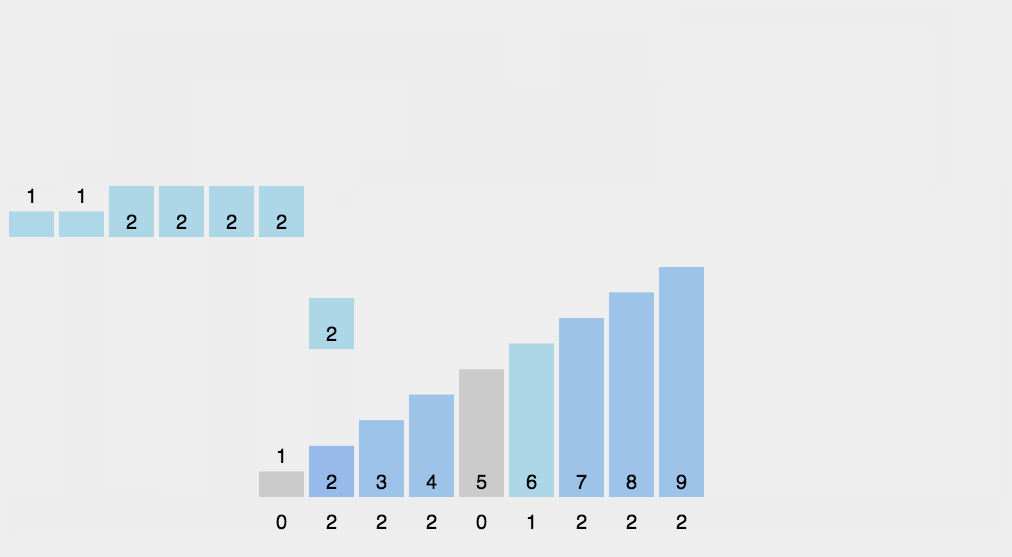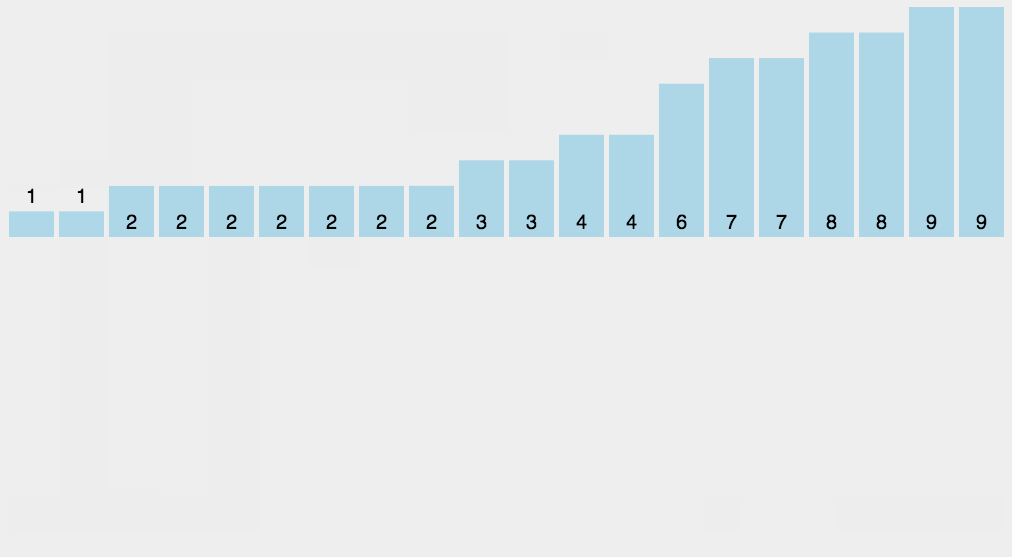
Complexity
- 시간복잡도
- 최선 :
O(N + K) - 평균 :
O(N + K) - 최악 :
O(N + K)
- 최선 :
- K는 배열에서 등장하는 최댓값
- 데이터를 직접 비교하는 알고리즘이 아니기 때문에 O(N) 의 시간 복잡도
Code
int arr[5]; // [5, 4, 3, 2, 1]
int sorted_arr[5];
// 과정 1 - counting 배열의 사이즈를 최대값 5가 담기도록 크게 잡기
int counting[6]; // 단점 : counting 배열의 사이즈의 범위를 가능한 값의 범위만큼 크게 잡아야 하므로, 비효율적이 됨.
// 과정 2 - counting 배열의 값을 증가해주기.
for (int i = 0; i < arr.length; i++) {
counting[arr[i]]++;
}
// 과정 3 - counting 배열을 누적합으로 만들어주기.
for (int i = 1; i < arr.length; i++) {
counting[i] += counting[i - 1];
}
// 과정 4 - 뒤에서부터 배열을 돌면서, 해당하는 값의 인덱스에 값을 넣어주기.
for (int i = arr.length - 1; i >= 0; i--) {
sorted_arr[counting[arr[i]]] = arr[i];
counting[arr[i]]--;
}Pros & Cons
- 두 데이터를 비교하는 과정이 없기 때문에 굉장히 짧은 시간복잡도를 가진다
- 하지만 수열의 길이보다 수의 범위가 굉장히 커지면 그 범위만큼의 배열을 생성해야하기 때문에 메모리가 매우 낭비된다
Radix Sort
- 계수 정렬(Counting Sort)과 마찬가지로 비교연산을 수행하지 않아 조건이 맞는 상황에서 빠른 정렬 속도를 보장하는 알고리즘
- 데이터의 각 자릿수를 낮은 자리수에서부터 가장 큰 자리수까지 올라가면서 정렬을 수행하는 것
- 자릿수가 존재하지 않는 데이터를 기수정렬로 정렬하는 것은 불가능
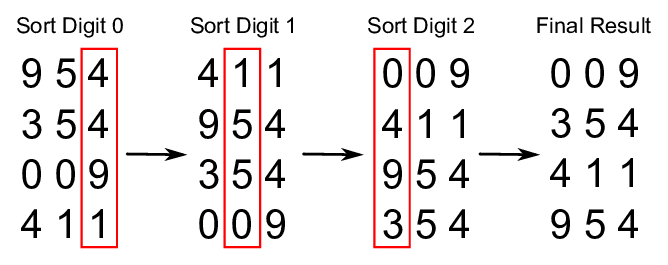
- 과정 (가장 큰 자리수가 100의 자리일 때)
- 각 데이터들의 1의 자리를 비교해서 같은 데이터끼리 모은다 (1의 자리가 작은 데이터들이 앞에 위치하게 되고 큰 숫자들이 뒤에 위치하게 된다) (오름차순 기준)
- 이때 같은 자릿수에 여러 데이터가 있을 경우에는 입력된 순서(나열된 순서)로 데이터를 모은다
- 2번까지 과정을 마치면 1의 자리가 가장 작은 숫자부터 가장 큰 숫자 순으로 데이터들이 정렬된다.
- 이번에는 10의 자리가 같은 데이터끼리 오름차순으로 나열한다.
- 10보다 작은 숫자들은 배열에 위치했던 순서대로 새로운 정렬의 제일 앞에 위치하게 된다.
- 이번에는 100의 자리가 같은 데이터끼리 오름차순으로 나열한다.
- 100보다 작은 숫자들은 배열의 제일 앞에서부터 순서대로 채운다.
- 데이터들의 최대 자릿수가 100의 자리이기 때문에 더 이상 진행하지 않고 종료한다.
Complexity
- 시간복잡도
- 최선 :
O(N + K) - 평균 :
O(N + K) - 최악 :
O(N + K)
- 최선 :
- K는 배열에서 등장하는 가장 큰 기수
Code
void countSort(int arr[], int n, int exp) {
int buffer[n];
int i, count[10] = {0};
// exp의 자릿수에 해당하는 count 증가
for (i = 0; i < n; i++){
count[(arr[i] / exp) % 10]++;
}
// 누적합 구하기
for (i = 1; i < 10; i++) {
count[i] += count[i - 1];
}
// 일반적인 Counting sort 과정
for (i = n - 1; i >= 0; i--) {
buffer[count[(arr[i]/exp) % 10] - 1] = arr[i];
count[(arr[i] / exp) % 10]--;
}
for (i = 0; i < n; i++){
arr[i] = buffer[i];
}
}
void radixsort(int arr[], int n) {
// 최댓값 자리만큼 돌기
int m = getMax(arr, n);
// 최댓값을 나눴을 때, 0이 나오면 모든 숫자가 exp의 아래
for (int exp = 1; m / exp > 0; exp *= 10) {
countSort(arr, n, exp);
}
}Pros & Cons
- MSD (Most-Significant-Digit) 과 LSD (Least-Significant-Digit)
- MSD는 가장 큰 자리수부터 Counting sort 하는 것을 의미하고, LSD는 가장 낮은 자리수부터 Counting sort 하는 것을 의미
- LSD의 경우 Digit의 갯수만큼 따져야하는 단점이 있지만 그에 반해 MSD는 마지막 자리수까지 확인해 볼 필요가 없이 중간에 결과를 알 수 있다
- 따라서 MSD를 사용하면 시간을 줄일 수 있으나 정렬이 되었는지 확인하는 과정이 필요하고, 이 때문에 메모리를 더 사용하게 된다
- LSD는 알고리즘이 일관됨 (Branch Free algorithm) 그러나 MSD는 일관되지 못함
--> 따라서 Radix sort는 주로 LSD를 언급함 - LSD는 자릿수가 정해진 경우 좀 더 빠를 수 있다
참조 : https://hanhyx.tistory.com/35, https://gyoogle.dev/blog/algorithm/Bubble%20Sort.html, https://cs-vegemeal.tistory.com/53, https://st-lab.tistory.com/233?category=892973

New, Strange, Want to try