먼저 이 글은 자바를 처음 시작하거나 혹은 JVM에 관심이 많이 있으신 분들을 위한 글입니다.
그럼 이제부터 JVM을 파헤쳐 보도록 하겠습니다.
1. JVM이 탄생하게 된 배경(WORA)
Binary -> Assembly Language
맨 처음 컴퓨터가 탄생했을 때는 이것을 기계어인 이진수로 조작했어야 했습니다.
그런데 기계어로 컴퓨터를 조작하는 것은 매우 힘듭니다.
상상을 해보세요. printf("hi"); 라는 함수를 기계어인 2진수로 작성해야 하면 얼마나 힘들까요?
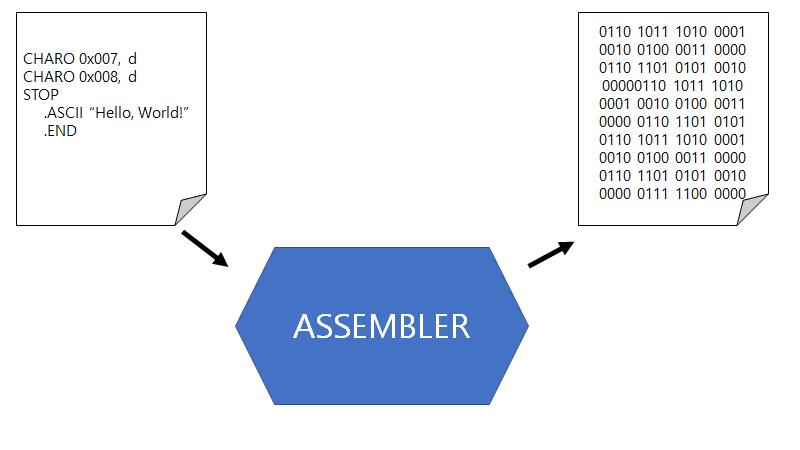
그래서 어셈블리어라는게 생겨납니다. 즉, 어셈블리어로 프로그램을 작성하면 어셈블러가 이것을 기계어로 변환해줘서 프로그래머가 기계어로 프로그래밍을 하지 않아도 되게 해줍니다.
그러나 기계어로의 해방이 아닌 또 다른 문제가 발생하게 됩니다. 그것은 기계마다 기계어가 다르다는 점입니다. 이는 배우는 입장에서 매우 골치 아픈 점입니다. 기계가 100 종류 있다면 언어를 100개 공부해야 하기 때문입니다. 그래서 나온 것이 c언어와 같은 프로그래밍 언어입니다.
Assembly Language -> WOCA
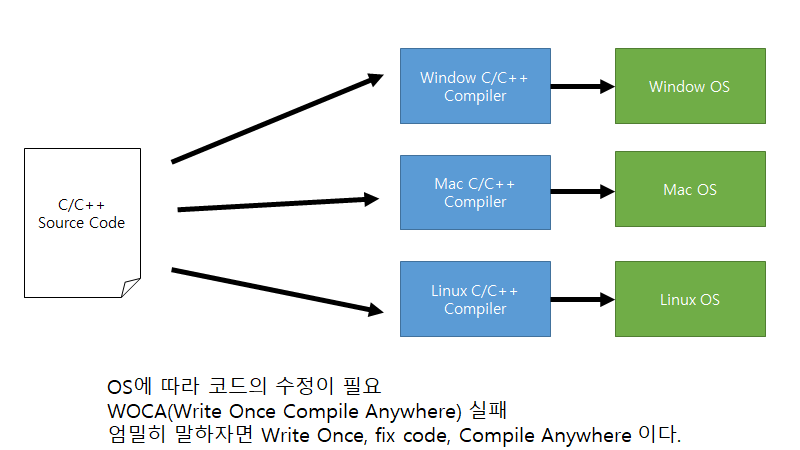
c언어로 프로그래밍 언어를 한 번 작성하면 기계에 맞게 컴파일할 수 있어서 기계마다 다른 소스코드를 작성하지 않아도 됩니다. 즉, 언어를 한 개만 배우면 끝이라는 것입니다. 그러면 컴파일러가 기계에 맞는 기계어를 만들어 줍니다. 즉 이번에는 기계마다 다른 문법을 배워야 하는 어셈블리어로부터 해방된 것입니다. 그래서 c언어가 이식성이 상대적으로 어셈블리어보다 좋다고 말합니다. 이런 특성을 바탕으로 c언어는 WOCA(Writre Once Compile Anywhere)의 특성을 갖추는 듯 했습니다.
하지만 여기에도 아직 문제가 존재합니다. 아무리 컴파일러가 기계마다 그것에 맞는 기계어를 만들어 준다고 하더라도 기계의 특성에 맞게 소스파일에서 약간의 수정을 해야 하는 상황이 존재했기 때문입니다. 즉, 예를 들어서 어떤 컴퓨터에서는 int의 크기가 4바이트인 반면에 어떤 컴퓨터에서는 아니라는 점이죠. 그래서 엄밀히 말하자면 WOCA가 아닌 Write Once, fix code, Compile Anywhere이 되버렸죠. 즉, 이런 점 때문에 자바라는 언어가 탄생하게 됩니다.
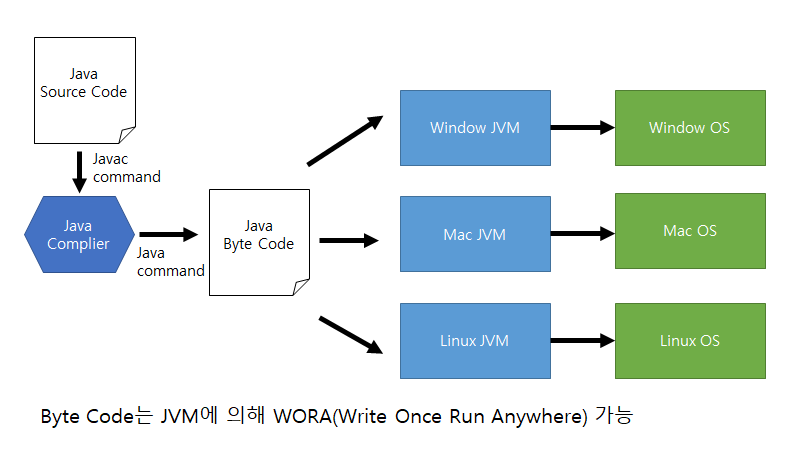
WOCA -> WORA
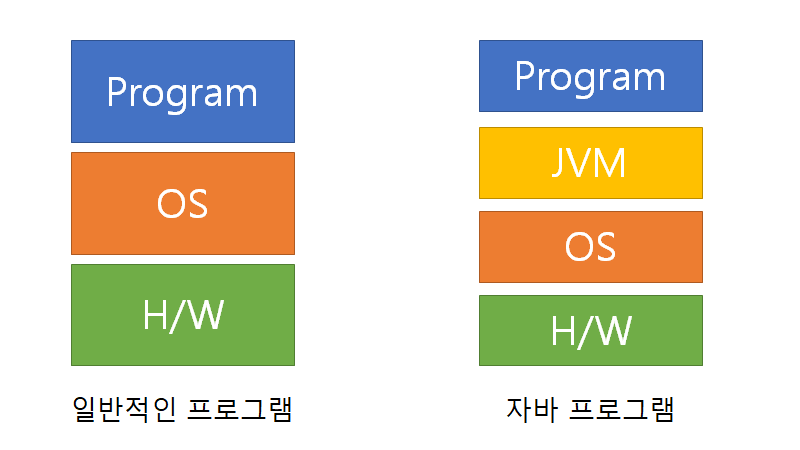
일반 프로그램은 컴파일러를 통해서 만들어낸 프로그램이 직접 os와 상호작용 했기 때문에 os에게 의존적이었습니다. 그렇기 때문에 하드웨어나 운영체제에 따라서 다르게 소스코드를 작성해야 했죠. 그러나 자바 언어로 작성한 소스파일은 jvm을 거쳐서 os와 상호작용을 합니다. 그래서 os로부터 독립적일 수 있었죠. 즉, JVM이 하드웨어나 OS마다 생기는 차이점까지 고려해서 프로그램을 만들어줍니다. 즉 이러한 자바의 특징을 WORA(Write Once Run Anywhere)라고 합니다. 이것을 아래의 그림으로 나타낼 수 있습니다.
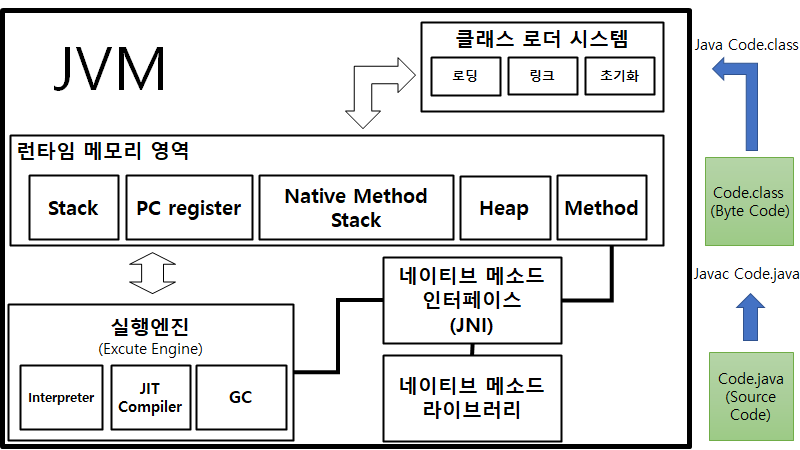
2. JVM의 구조
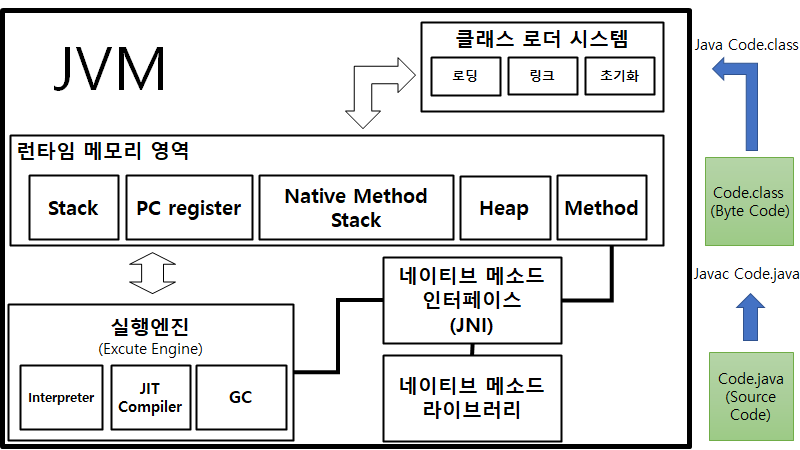
딱 봐도 내용이 많습니다. 그러나 특징적인 것만을 본다면 JVM은 클래스 로더, 런타임 메모리 영역, 실행 엔진으로 구성되어 있습니다. 이제부터 자바 소스파일을 작성해서 이것이 직접 실행되는 순서로 JVM을 설명해보겠습니다. 참고로 결론부터 말하자면, JVM은 바이트 코드를 읽어들여 JVM이 작동하고 있는 운영체제에 맞는 기계어를 CPU에 전달합니다.
3. 자바 컴파일러
먼저 IDE나 txt 파일을 통해서 프로그램의 내용을 기술하는 자바 소스 파일을 만듭니다. 구체적인 예를 들어서 example.java 파일을 만들었다고 해봅니다. IDE를 사용하면 상관 없지만 CLI 환경이라면 javac example.java 명령어를 통해서 example.class라는 파일을 만듭니다. 이것은 example.java의 바이트 코드입니다. 그리고 example.class 파일은 java example.class라는 명령어를 통해서 자바 가상 머신에 의해서 실행됩니다. 자바 가상 머신은 인터프리터 방식을 통해서 코드들을 바로 기계어로 변환하여 추가적인 파일을 생산하지 않고 곧바로 플랫폼에서 코드가 실행되도록 합니다.
여기서 바이트 코드의 정확한 의미는 실제 컴퓨터가 아닌 가상 머신에 의해서 처리되는 오브젝트 코드를 뜻합니다. 그리고 오브젝트 코드는 소스 코드가 컴파일 된 코드를 뜻합니다.
즉, 자바 소스 파일은 자바 컴파일러에 의해서 컴파일 되어 클래스 파일이 됩니다. 그리고 이 파일은 자바 가상 머신에 의해서 처리가 될 것입니다.
4. 클래스 로더
java example.class 라는 명령어를 실행하면 자바 가상 머신이 이 파일을 실행하게 됩니다. 이 과정을 구체적으로 살펴보겠습니다. 먼저 바이트 코드는 클래스 로더에 의해서 링크되어 런타임 메모리 영역으로 로드 됩니다.
여기서 링크란 소스 파일 간의 종속된 관계에 따라서 파일들을 연결하는 과정입니다.
5. 런타임 메모리 영역
런타임 메모리 영역은 크게 메소드 영역, 힙 영역, 스택 영역, pc 레지스터, 네이티브 메소드 영역으로 구성되어 있습니다. 각각의 영역은 영역마다 로드되는 데이터의 종류가 다릅니다. 힙 영역은 다른 언어와 마찬가지로 새로운 객체가 할당되는 공간입니다. 그렇기 때문에 가비지 컬렉션이 이루어지는 공간이기도 합니다. 가비지 컬렉션은 아래서 차차 설명하겠습니다.
6. 실행 엔진
이때 코드가 실행되는 방식은 크게 두 가지입니다. 인터프리터 방식과 JIT 컴파일 방식입니다. 인터프리터 방식은 파이썬과 마찬가지로 한 줄씩 읽어서 해석한 뒤에 실행하는 방식입니다. 그렇기 때문에 실행 속도는 느립니다.
이런 점을 보완하기 위해 JIT 컴파일 방식도 혼용해서 사용합니다. JIT 컴파일러는 바이트 코드를 네이티브 코드로 바꾼 다음에 실행합니다. 여기서 네이티브 코드는 운영체제에 의해서 곧 바로 실행될 수 있는 코드를 말합니다.
7. 가비지 컬렉션
사실 JVM에서 가장 이해하기 어려운 부분입니다. C언어에서 동적으로 객체를 할당하게 되면 free라는 함수를 통해서 그 객체를 메모리에서 지워줘야 합니다. 그러나 자바에서는 할당만 해두면 자바 가상 머신이 알아서 할당을 해제합니다. 이런 기능을 가비지 컬렉션이라고 합니다. 이제 본격적으로 가비지 컬렉션을 살펴보겠습니다.
개요
컴퓨터과학자들은 효율적인 가비지 컬렉션을 위해서 먼저 각각의 객체들마다 수명이 어떤지 조사를 하였습니다. 그 결과 대부분의 객체들은 짧은 시간 내에 사용하지 않게 되고, 소수의 객체만이 오랫동안 사용하는 것으로 밝혀졌습니다. 이 결과를 바탕으로 효율적인 가비지 컬렉션을 위하여 두 종류의 객체마다 다른 알고리즘을 적용하기로 했습니다. 그러기 위해선 각각의 객체를 다른 메모리에 두고 관리할 필요가 있었죠. 그래서 힙 영역을 young 영역과 old 영역으로 구분하고 young 영역에선 minor gc라는 방법을 통해서 가비지 컬렉션을 했습니다. 그리고 old 영역에선 major gc라는 방법으로 가비지 컬렉션을 했습니다. 또한 가비지 컬렉션을 하게 되면 힙 메모리는 중간중간마다 해제가 되어서 구멍이 생기게 됩니다. 가비지 컬렉터는 이렇게 구분되어져 쪼개진 메모리 조각들을 모아서 메모리를 정리합니다. 이는 아래의 그림들을 통해서도 확인할 수 있습니다.
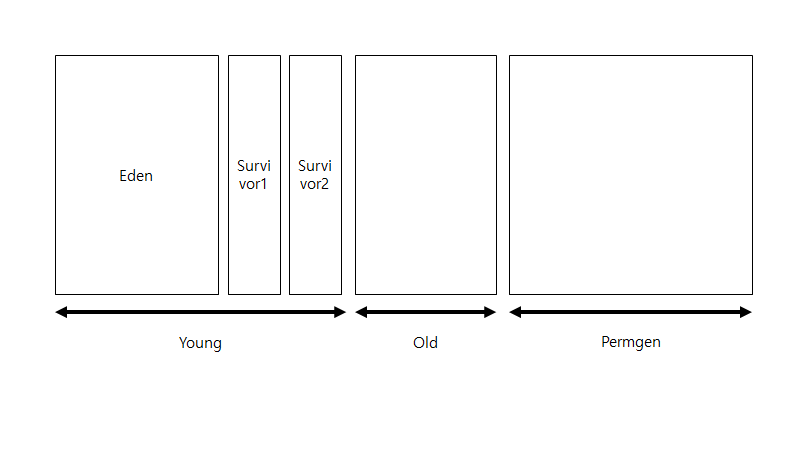
•메모리가 young영역과 old(tenured)으로 구분
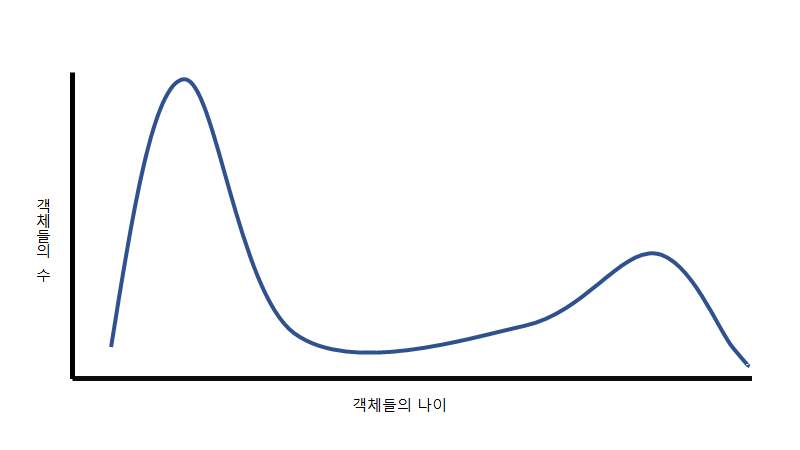
•객체의 수명을 나타내는 그래프
빨리 죽는 객체와 오래 사는 객체로 구분된다.
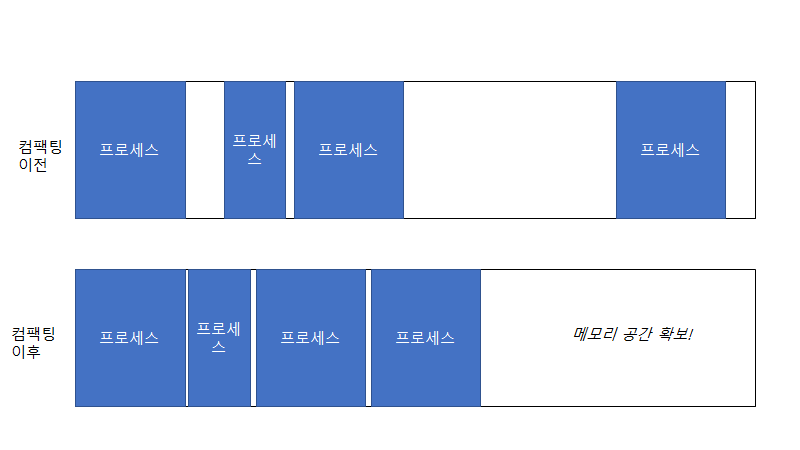
•Fragmenting and Compacting
메모리 조각을 가비지 컬렉션이 재정리
가비지 컬렉션 알고리즘(Reference Counting)
일단 본격적으로 가비지 컬렉션의 절차를 보기 전에 가비지 컬렉션이 어떤 방법으로 행해지는지 살펴보겠습니다.
단순하게 생각해보겠습니다. 가비지 컬렉션은 사용하지 않는 객체를 먼저 찾아야 합니다. 그렇다면 어떻게 찾아야할까요. Reference Counting 방법은 얼마나 그 객체가 참조되었는가를 통해서 객체가 사용되나 안 되나를 판단합니다. 그래서 참조되는 수가 0번인 경우에 그 객체가 사용되지 않다고 판단하고 그 객체를 삭제하는 방법입니다. 이는 아래의 그림을 통해서도 확인할 수 있습니다.
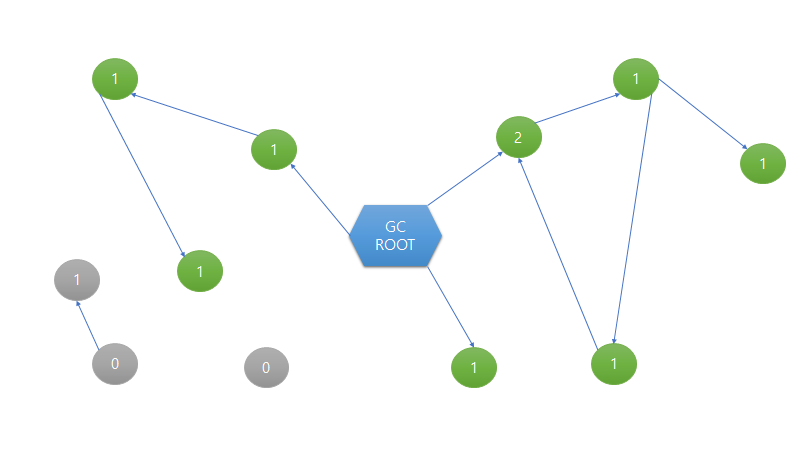
여기서 GC ROOTS는 프로그래머에 의해서 현재 사용 중인 프로그램을 나타냅니다.
그러나 이 방법에는 문제점이 있습니다. 그 객체를 실제로 사용하지 않음에도 객체가 참조되는 횟수가 0번인 아닌 경우가 발생합니다. Reference Counting은 이런 예외를 처리하지 못합니다. 따라서 다른 방법을 도입하여 이런 문제점을 보완합니다. 그 방법을 Mark and Sweap이라고 합니다.
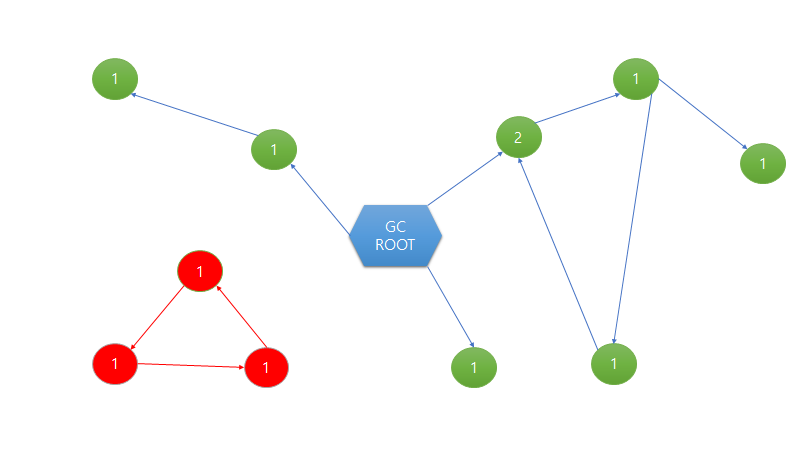
빨간색 그래프가 예외에 해당합니다.
가비지 컬렉션 알고리즘(Mark and Sweap)
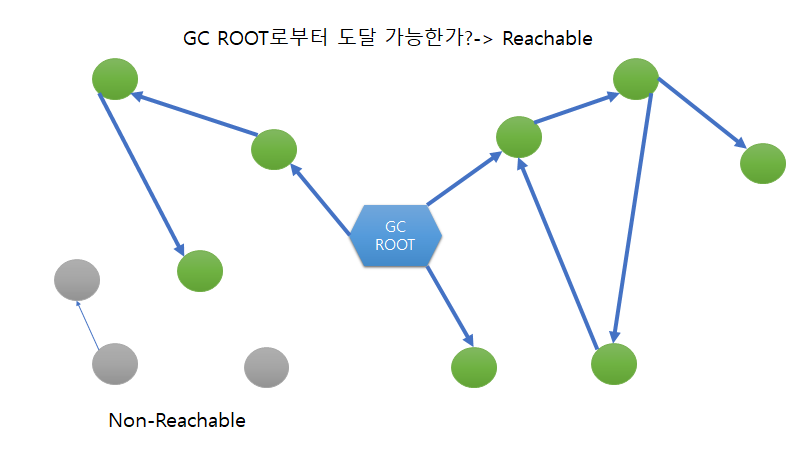
이 방법은 위에서 말한 예외를 처리하기 위해서 도입되었습니다. 이 방법은 gc root에 해당하는 프로그램에서부터 시작하여 그 프로그램과 연결된 객체를 연속하여 계속해서 체크(Mark)합니다. 그리하여 체크가 안된 객체들을 사용되지 않는 객체로 판단하여 삭제합니다(Sweap). 이때 gc root에서부터 도달 가능한 객체의 상태를 reachable하다고 말합니다.
Minor GC
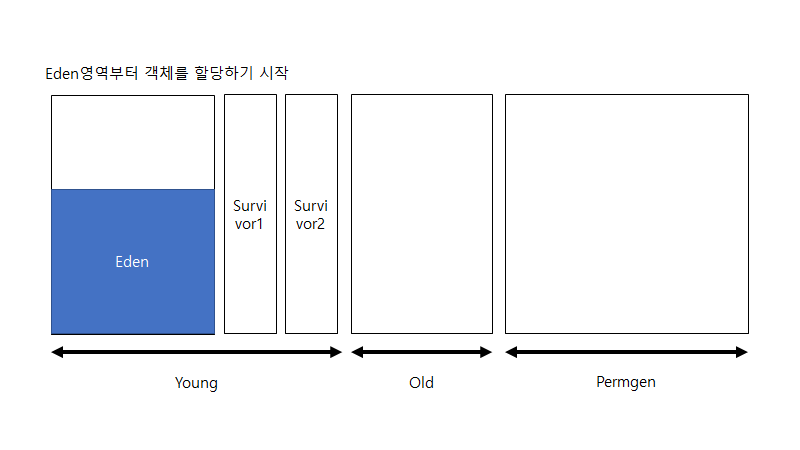
Minor GC는 힙 메모리 중에서 young 영역에서 행해지는 가비지 컬렉션을 말합니다. young 영역은 eden, survivor1, survivor2로 나뉘어집니다. 사실상 minor GC 과정은 old한 객체를 걸러내는 과정이라고도 할 수 있습니다. 이는 minor gc 과정을 이해하면 알 수 있습니다. 이제 구체적으로 minor gc를 살펴 보겠습니다.
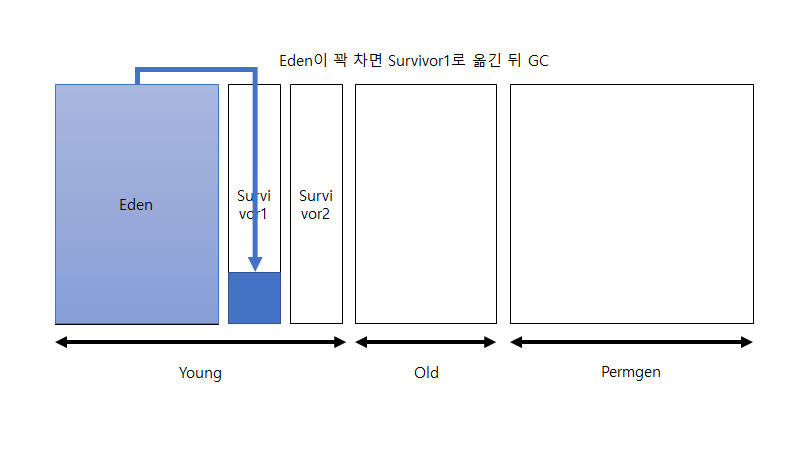
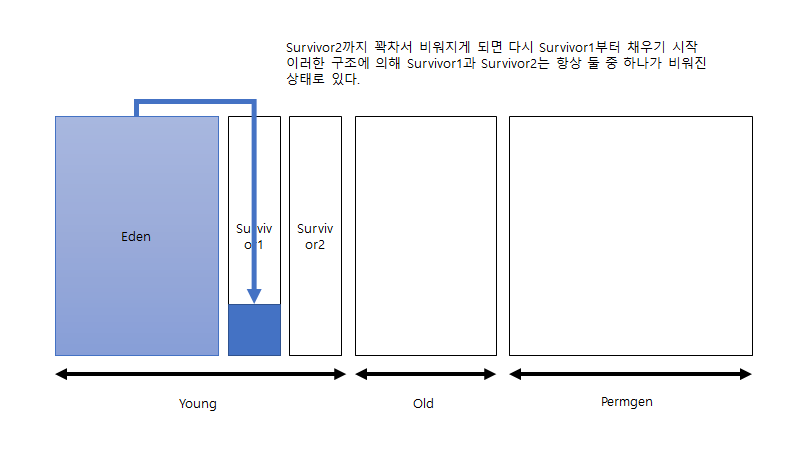
새로운 객체를 eden 영역에 할당하기 시작합니다. 그러다가 eden 영역이 꽉 차게 되면 survivor1 영역에 옮긴 뒤 eden영역을 비우고 survivor1 영역에서 사용하지 않는 객체를 삭제합니다(가비지 컬렉션). 그리고 다시 eden 영역에서부터 객체를 할당하기 시작합니다. 그리고 위의 과정을 반복합니다.
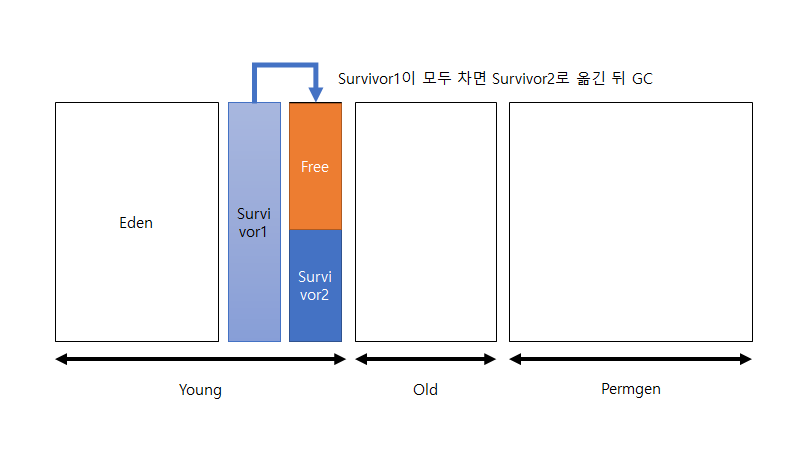
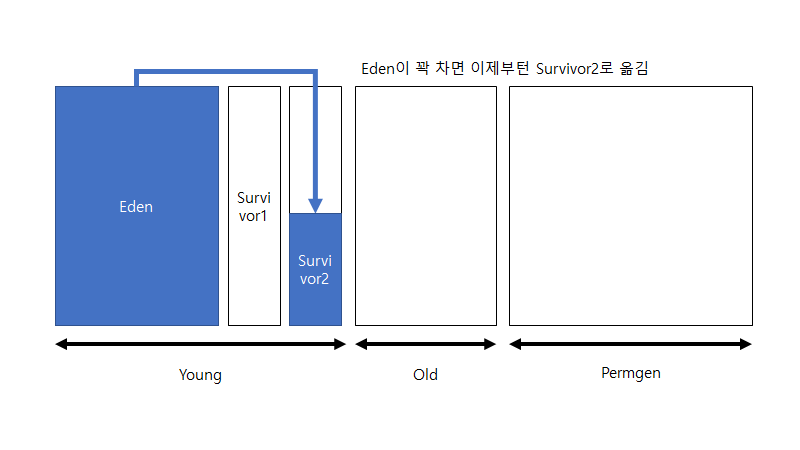
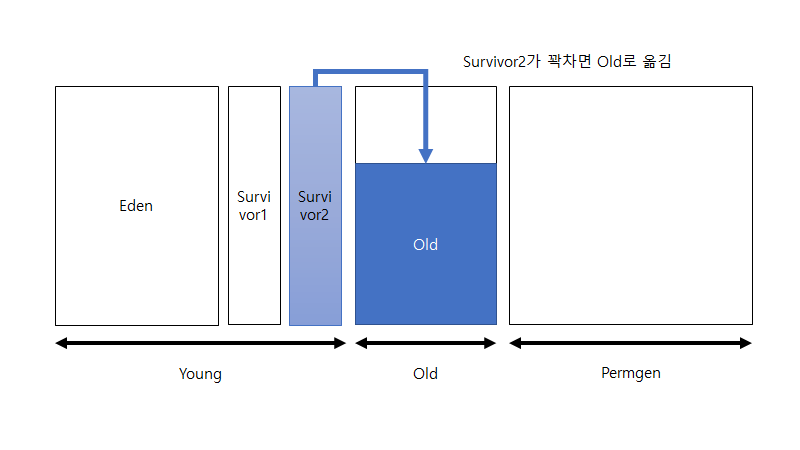
그러다가 survivor1 영역이 꽉 차게 되면 survivor2 영역에 이를 복사하여 옮긴 뒤 survivor1 영역을 비웁니다. 그리고 survivor2 영역에서 사용하지 않는 객체를 삭제합니다(가비지 컬렉션). 그리고 다시 eden 영역에서부터 객체를 할당합니다. 그리고 이번엔 eden 영역이 꽉 차게 되면 이를 survivor2 영역으로 옮긴 뒤 가비지 컬렉션을 합니다. 이때부턴 survivor2 영역이 꽉 차기 전까지 위의 과정을 반복합니다. 여기서 언급하고 싶은 것은 survivor1과 survivor2 영역은 항상 둘 중 한 영역은 비워진 상태로 존재하게 된다는 점 입니다.
그리고 이제 survivor2 영역이 꽉 차게 되면 이를 old 영역으로 옮기고 맨 처음 과정에서부터 다시 시작합니다. 이 과정이 minor GC의 구체적인 과정입니다.
Major GC
Major GC는 Minor GC와는 다르게 소요되는 시간이 깁니다. 왜냐하면 Old 영역이 young 영역보다 크기가 더 크기 때문입니다. 그래서 minor gc에 비해서 소요되는 시간 10배 정도 됩니다. 그렇기 때문에 직접 명령어로 가비지 컬렉션을 직접 수행하지 않아야 합니다.
8. JNI와 NDK
자바에선 C와 C++라이브러리를 사용할 수 있습니다. 이런 라이브러리는 NDK라는 Native Development Kit에 포함되어 있습니다. 그러나 자바 가상머신을 이를 직접 사용하지 않고 JNI라는 Java Native Interface를 거쳐서 사용합니다.
여기까지가 제가 정리해본 JVM의 모든 것입니다. 비록 가비지 컬렉션에 강조를 두긴 했지만 읽어보시고 도움이 되시길 바랍니다. 틀린 부분이 있다면 언제든 지적해주세요. 피드백 환영합니다.
참고문헌
https://mangkyu.tistory.com/118
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=kbh3983&logNo=220967456151
https://jeong-pro.tistory.com/148
https://plumbr.io/handbook/garbage-collection-in-java
https://www.learncomputerscienceonline.com/java-programming-basics/
