알고리즘
1.[JS] 프로그래머스 - 구명보트

놓쳤던 부분 처음부터 shift를 사용하면 효율성이 떨어진다는 것은 인지하고 있었다. 그렇기 때문에 최대한 그 횟수를 줄여보고자 오름차순 정렬을 하여 pop 메소드를 사용하였다. 그 결과 해결 배열의 원소를 빼지 않고 index의 크기를 조절함으로서 효율성테스트를 통과할 수 있었다.
2.[JS] 프로그래머스 - 실패율
업로드중..다른 사람들 풀이를 보니까 굳이 map 객체를 써서 풀지 않아도 됐던것 같다...단순하고 효율성이 있는 풀이를 생각하는 능력을 길러봐야지 !
3.[JS] 프로그래머스 - 짝지어 제거하기
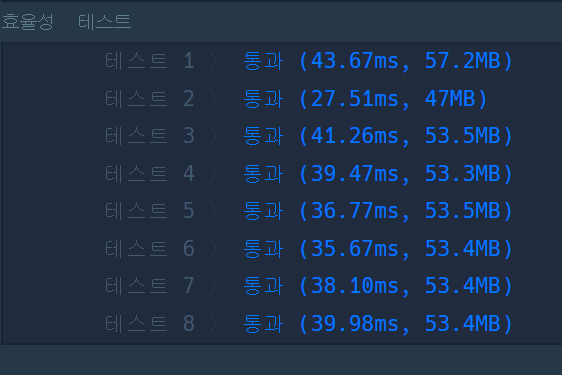
효율성이 관건이였던 이번문제. 처음에는 배열을 잘라가면서 중복을 제거해줬다 자신만만하게 '제출 후 채점하기'를 누르고 정확성에서 통과되는걸 보고 만족의 미소를 짓고 있던 찰나 효율성검사에서 실패가 주루룩 떳다. 무엇이 문제였을까. 바로 저 splice함수가 문제였다.
4.[JS] 프로그래머스 - 두 큐 합 같게 만들기
프로그래머스 - 두 큐 합 같게 만들기
5.[JS] 프로그래머스 - 캐시

프로그래머스 - 캐시
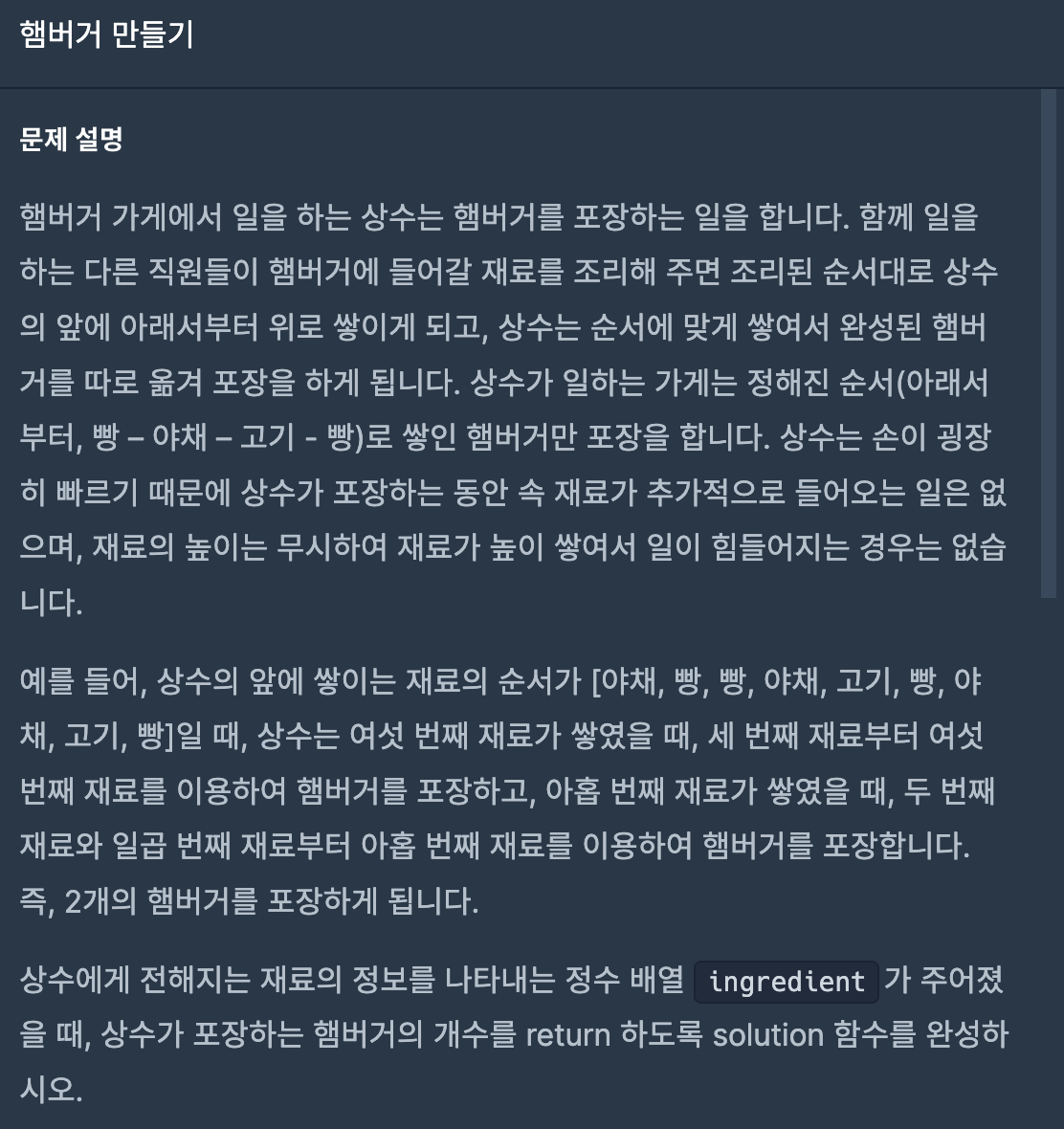
6.[JS] 프로그래머스 - 햄버거 만들기
7.[JS] 프로그래머스 - 택배 상자

8.[JS] 프로그래머스 - 할인 행사

9.[JS] 프로그래머스 - 롤케이크 자르기

처음에는 단순하게 slice로 배열을 자른다음 set객체를 이용하여 풀면되겠다는 생각을 하여 코드를 짯고 테스트케이스를 통과하였다. 그리고 자신만만하게 제출을 눌렀고 돌아오는건 (역시 ... 너무 쉽게 풀린다 했어...) 힌트를 찾아보니 일단 토핑의 길이가
10.[JS] 프로그래머스 - 파일명 정렬

match 함수 정규식과 일치하면 배열로 리턴한다. \D : 숫자가 아닌것들 (= ) '+' : 한번 이상 반복 \d : 숫자 ( = [0-9] ) aHead, bHead = 숫자가 아닌것들중에 숫자가 나타나기전 첫번째 문자(열) parseInt(a.match(/\d+/)[0]) = 숫자가 아닌게 나타나기전 첫번째 숫자로만 이루어진 문자(열). p...